来聊聊字符和编码
原文出处:来聊聊字符和编码
什么是字符/字符集?
字符,文字和符号,是一种抽象的概念。人类早在远古时期,大脑就具有了识别和输出特定文字和符号的能力,即「阅读」和「书写」。
人脑在识别字符的时候,会将抽象的字符,从复杂的图案分解成简单的描述数据。
比如,「汉」这个简体汉字,特征大体是:左边「三点水」,右边一个「又」。「三点水」则是三个不同的「点」……

符号也是类似的,比如标点符号。
字符与具体字体无关。不管是楷书还是宋体,「汉」都是同一个字符。与旋律和音色的关系有点相似。
n 个字符组成的集合就是字符集,通常字符集中,n 是有限的。比如所有的英文小写字母可以认为是一个字符集。字符集是无序的,{a,b,c} 和 {b,c,a} 是同一个字符集。
在各种自然语言中,字符集都是组成这种语言的文字的一个必备要素。可以说字符和语言息息相关。
例如「中文」是一种语言,「简体汉字」是一种中文的「字符集」。
计算机如何表示字符?
计算机发明的初衷是为了让机器在有限步骤内自动完成复杂的数字运算。计算机本身的理论模型和数字进制没有关系,但是为了方便实现,采用了二进制的方式存储。这样可以用电子元件通电/不通电两种状态表示某一位(bit)是 1 还是 0。
我们都知道,现代计算机使用 8 bit 为一个内存寻址单元(硬件制造相关),即一个字节Byte。大家知道这是为什么吗?为什么不是更少或者更多呢?要回答这个问题,就不得不说说计算机和字符的那些事儿。
最初计算机只能用于数字的计算。后来计算机有了存储(如内存、硬盘)。这时聪明的人们就开始思考,既然数字可以存储,那其他的东西,比如字符、图片、音频……是不是也可以存储呢?于是,针对字符,就有了「编码字符集」的概念。
上面我们提到字符集本身是无序的,但是经过把字符和编码做一个映射之后,每个字符就有了一个序号。就是「编码字符集」,编码后的字符集。这里可以简单理解为,每一个字符的编码,就是一个码点(code point)
注意这里说的「编码字符集」和后面要说的「字符编码方式」是两回事。
计算机起源于西方世界,他们的语言中,字符数量比较少。把英文中的字符、数字、标点,以及一些常用的系统保留控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等,还有通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等,建立一一映射关系,大约需要 100 个左右的编码。
由于 2^6 = 64,不足以存储上面说的字符数,因此早期的 1Byte = 6bit 的方案才终于被淘汰掉。此时可以用 2^7 = 128 来作为1Byte 的存储空间。这样每一个英文里面的字符都可以使用一个 1Byte 来进行存储。后来基于多种考虑,比如考虑简单的扩展等,定下 1Byte = 8bit 的方案。
由于一个存储单元往往对应一个不可切割的硬件单元,字节内的位太多也会造成一定的存储单元上面的浪费,所以更多的字节方案比如 1Byte = 9bit 乃至 48bit 的方案最终也都被淘汰掉了。
按照特定编码字符集的编码规则去解析一串数字,就可以得到这串数字对应的字符。这样计算机就可以把这些字符用数字存储起来了。
对于一个常规的文本文件来说,我们使用特定的应用程序,以特定编码规则解析,则可以呈现一个能被读懂的文件,使用二进制方式在输出设备中输出,则会得到一串二进制数字。
至于这个字符如何呈现到屏幕上面,字符的字形、字体,点阵等等一些知识,则是编码与 UI 绘制相关的另一个话题了。这里就暂时不做过多讨论。
ASCII 和其他编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是比较早的一种编码字符集,里面包含了 128 种字符,囊括了英文中常用的字母、数字、标点符号。另外还考虑了一些计算机的特定行为,比如响铃等等。
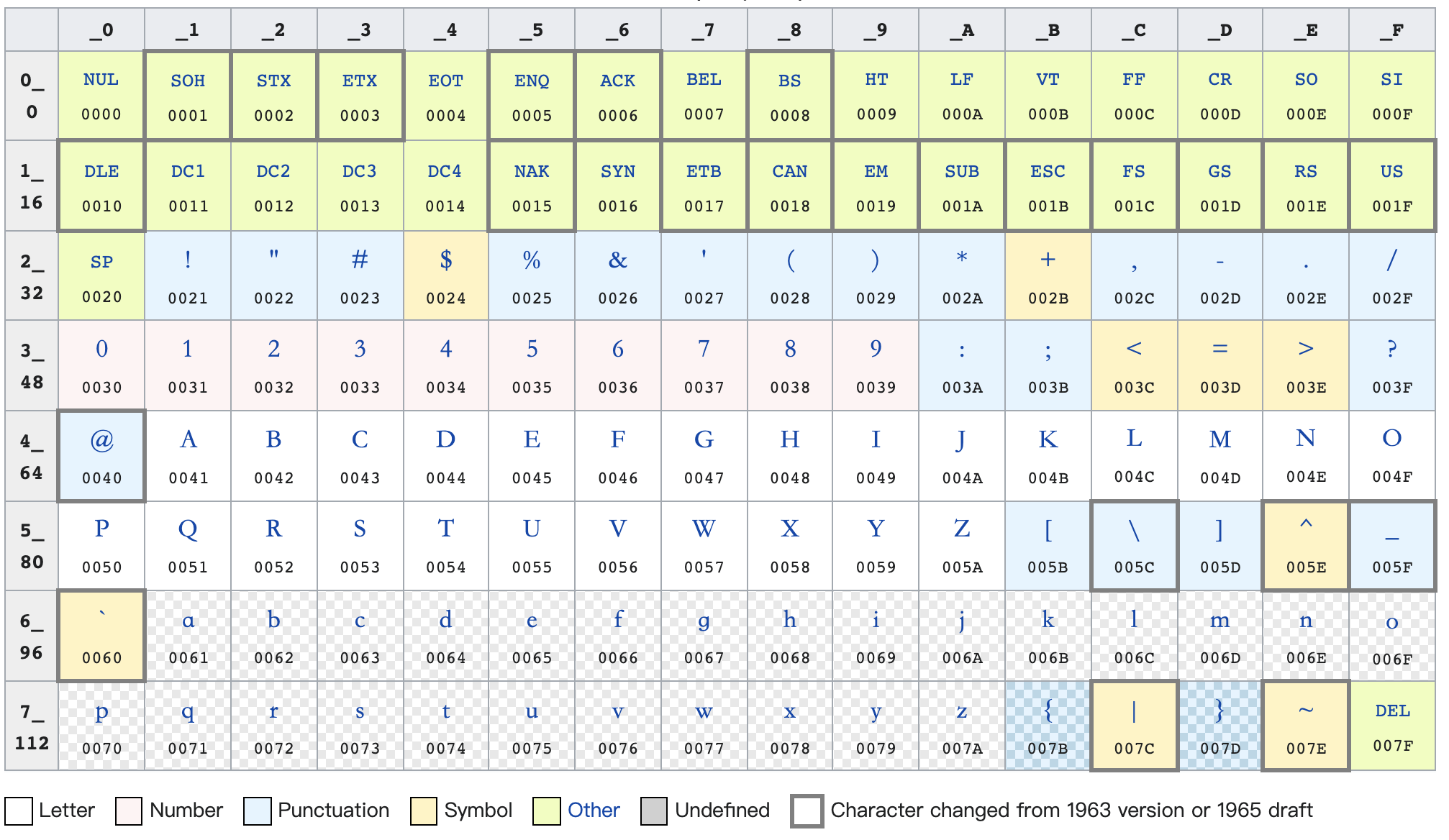
ASCII 码无情地把 2^7 中的 128 个编码全部占领了,并没有为其他字符保留任何一个空间。但计算机并不是美国可以独占的财富。后来一些西欧国家发现,使用 ASCII 字符集虽然无法为他们特有的文字进行扩充,但是所幸 1Byte = 8bit,有 2^8 = 256 种不同的组合,他们纷纷打起了剩下的那一个 bit 的主意。他们可以表示的字符数有 2^8 = 256 种。但是 ASCII 都被作为一种事实上的工业标准被这些编码字符集所兼容。他们的编码字符集中,0-127 号的字符跟 ASCII 中的字符一模一样。
从第 128 (即 1000 0000) 号开始,就是各种扩展字符集中特有的字符。西欧、东欧、南欧、斯拉夫、希腊等等不同语系都在 ASCII 的基础上添加 1bit 扩充字符,并且有不同的规则。比如,130 在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג)。我们见过的 Latin-1,Latin-2,Latin-3 等等,就是这种方案的产物。这里已经有了一些转换上面的麻烦。
这种情况到了东亚国家的文字中就变的更加明显。
汉字字符集和编码的一些知识
常用汉字大约有 6000 多个,远远超过 2^8 = 256。因此一个 8bit 字节不可能对汉字进行编码。这时,要么汉字使用者使用其他的 Byte 位数方案,要么只能用多个 Byte 来存储一个汉字了。答案很明显,从各种情况考虑,多个字节存储一个汉字的方案成本更小。
最早对汉字进行编码的编码字符集是 1978 年由日本工业规格协会制定的 JIS 字符集。作为汉字的发源国家,我们国家紧随其后,于 1981年制定了汉字国标(GB)码,GB2312,成为了中华人民共和国和新加坡等地的汉字编码标准,后来多次做了修改和扩展,变为常用的 GBK 编码规范。GB 编码标准中主要考虑的是简体汉字。而港澳台等地区,使用了大五码即 BIG 5 的标准,里面收录的字符大多是繁体汉字。
这些编码字符集的共同特点就是,使用 2 Byte 表示一个汉字,两个字节理论上可以表示的字符数则是 2^16 = 65536。同时 GBK 也兼容了 ASCII 的标准,使用相同的 1 Byte 兼容原有的 ASCII 的字符。因此,GBK 等字符集,一个字符所占的 Byte 数为 1 或者 2。很多同学会认为「汉字占两个字节」,往往就是有一些在 GBK 编码体系下的经验和使用场景。
1 个 Byte 对应的字符,被认为「半角字符」,2 个 Byte 对应的则是「全角字符」,这都是在 GBK 编码中特有的概念。值得一说的是,像逗号等等原本 ASCII 中包含的字符,GBK 中也有一个对应的 2 Byte 编码,并在字形上面跟半角字形有所区别。这也是一个被标准化的东西,广泛应用于一些中文书写规范中。
支持不同语言的操作系统,往往会内置或者按照很多的编码字符集,被叫做代码页(code page,简称 CP)。例如常用的 windows 操作系统中,GBK 对应的是 CP936。windows 会根据内置语言、用户选择的系统语言和地区等等,设置当前系统代码页。在系统内置的 cmd 终端、记事本等等,往往会根据当前代码页来存储和解析字符,这就是 windows 里面所谓 「ANSI」的默认方式。
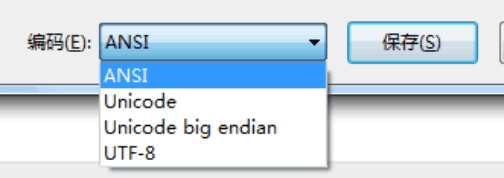
为什么 windows 上面保存的文本文件、excel 文档,甚至中文文件名,直接放到 Linux 或者 MacOS 中经常会变成乱码呢?原因正是因为,早期 windows,GBK 就是默认的内置汉字编码代码页,而 Linux 和 MacOS 的编码方式都是 utf-8. 二者自然是不能兼容的。
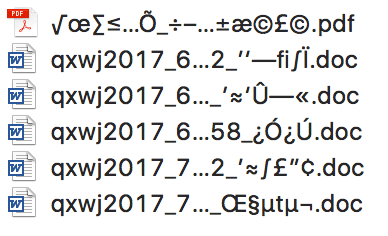
另外一个小知识是关于「烫烫烫」的。新手编程经常会无意之间在 windows 终端中发现莫名其妙的「烫烫烫」、「屯屯屯」等等。所谓
手持两把锟斤拷,口中疾呼烫烫烫
脚踏千朵屯屯屯,笑看万物锘锘锘

这就跟 cmd 终端的 cp 有关系。烫的 GBK 编码十六进制是 0xCCCC,而未被初始化的 1Byte 的栈内存会被写入 0xCC,当多个 0xCC 放到一起,就是 0xCCCCCCCCCCCC,不就是烫烫烫么?这时候你硬要把这段未初始化的内存输出出来,就会被 cmd 这样显示了。同理,屯(0xCDCD)跟未初始化的堆内存(0xCD)有关系。
「锟斤拷」跟 utf-8 有关系。utf-8 中遇到不认识的字符会用 � 来替换和占位,在 utf-8 中使用 3 个 Byte 存储:0xEFBFBD。两个 0xEFBFBD 是 0xEFBFBDEFBFBD,用 GBK 编码就是 锟(0xEFBF)斤(0xBDEF)拷(0xBFBD)。因此锟斤拷经常会在有机会混用 GBK 和 utf-8 的场景下出现。
万国码 — Unicode
互联网的出现让世界的电脑彼此连接了起来,这时候编码规则的不同就引起了很多麻烦。
比如:JIS、GBK、BIG5 等等,对同一个汉字字符的编码并不相同。同样一个汉字比如「元」,在不同的字符集中有截然不同的编码。同样,同一个编码当然在不同的编码字符集中代表的也不是同一个字符。
如何同时兼容多种语言的不同字符集呢?其实在 80 年代末就出现了一个叫做 Unicode 联盟(The Unicode Consortium)的组织,意图搞一个收录地球上所有语言所有字符的编码字符集。同时 IOS (国际标准化组织)也在做同样的事情,搞了一个 UCS 项目。后来两家都发现了对方的存在,并友好地兼容、合并了。这一次总算有了一个唯一的统一标准。现在 unicode 的官网是:https://home.unicode.org
Unicode 雄心壮志地想包含人类的所有字符,那么它的容量有多大呢?
Unicode 字符集的容量其实是在不断扩充中的。它规定,一个 16 位即 2Byte 的空间为一个平面(plane),一个平面的容量就是 2^16 = 65536。目前 Unicode 已经定义了 17 个平面,即 17 * 65536 大约 100 万这么多容量。如果不够还可以继续扩充至 18平面、19平面 ……
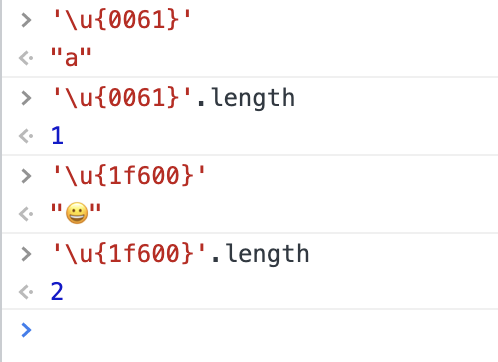
Unicode 的编码一般使用十六进制表示,前面加一个 U+,比如「汉」的 Unicode 编码是 U+6C49, a 的 Unicode 编码是U+0061. 补充前面两个 0 是一种通常的记法。
在 JavaScript 中,可以用转义字符的方式使用 Unicode 编码:

上面两种方式都可以,大小写不敏感。但是超过 2Byte 范围的只能使用后者,原因后面再说。
2Byte 范围内的第 0 个平面尽量收录了大多数常用的字符,被称作基本多语言平面 BMP(Basic Multilingual Plane)
在Unicode中, 还有三个私人使用区,指由合作用户之间的私人协议决定其用途的一系列码位。Unicode定义了三个私人使用区:一个在 BMP 的(U+E000-U+F8FF)中,另外两个几乎包含了整个第 15 和第 16 平面(分别为U+F0000-U+FFFFD,U+100000-U+10FFFD)。比如:
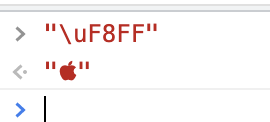
U+F8FF 在苹果公司相关产品中都能展示为苹果公司 logo. 在 Android 操作系统中则展示为

其实目前的 100 万个 Unicode 容量还远远没有用完,但它其实已经尽量收录了各种不同意义的字符。比如:
- 未统一汉字列表:
比如「天」这个汉字。中文汉字和日文汉字的意思是一模一样的。但却有两个不同的 Unicode 编码


「简体汉字」和「日语汉字」里面有很多「未统一汉字列表」,可以在这里面找到:https://zh.wikipedia.org/wiki/%E6%9C%AA%E7%B5%B1%E4%B8%80%E6%BC%A2%E5%AD%97%E5%88%97%E8%A1%A8
- 幽灵字符:
比如台湾「内政部」提交过数量极多的台湾人名用字,其中少数是独立的汉字,但基本上大部分都是已存在的汉字的讹变,据推测是当年登记户籍时,未受教育的人误写了自己的名字,登记员原样收录,电子化的时候依原样为此造字,最后又提交到 Unicode,进入世界的计算机里。

日本还有一些连读音和来源都不知道幽灵汉字被收录到 Unicode 中,有一个著名的就是「彁」。https://www.zhihu.com/question/35811498/answer/1120499902
- emoji
还有一种特殊而常用的字符 emoji,起源于日本,被 Unicode 收录。 我们将在后面讨论 emoji 的一些知识。

抽象字、编码字、组合字
下面我们先来看一个跟汉语拼音有关的问题。
我们知道汉语拼音里面有声母和韵母之分。有一组声母可能是部分地区同学的噩梦。
跟我读:zh ch sh / z c s
思考一下这里的 「sh」算作一个字还是两个字呢?
如果按照一个字符是一个字的话,sh 应该是两个字。
但 sh 实际是一个不可分割的整体。这个 sh 的形可以替换成其他的形式比如「 ∫」。但是其抽象的意思是不变的。
再来看,如果把 [zh sh] 两个声母的序列倒序一下,应该是[sh zh] 而不是 [hs hz] 吧。
所以其实汉语拼音里面的 sh 应该是一个字。
在现代字符编码模型中,每个本身是不可分割的字被叫做「抽象字」。多数抽象字由一个字符组成,但是有的抽象字可能是多个字符组成的,斯洛伐克 (Slovak)语中的「ch」,赛萨拉 (Sisaala) 语中的「ky」,就都是这种情况。能组成抽象字的每个字符叫做「编码字」。
Unicode 字符集中,每个字符都是「编码字」。由单个编码字组成的抽象字叫做「字素」,而由多个编码字组成的抽象字叫做「字素簇」。字素簇由多个unicode 字符组合而成。
但有时候一个抽象字既可以是单个字素,也可能是字素簇。比如拉丁语系里面会有重音音调等概念。 「é」 可以用单个 unicode表示:U+00e9。但其实它可以看作是「e」 和声调 「 ́」 组合而来的字素簇。Unicode 支持这种表示方式,并给「 ́」这类附加在其他字符上面的特殊字符单独编码。这种字符叫做「组合字」。所以「é」也可以这样表示:U+0065 U+0301
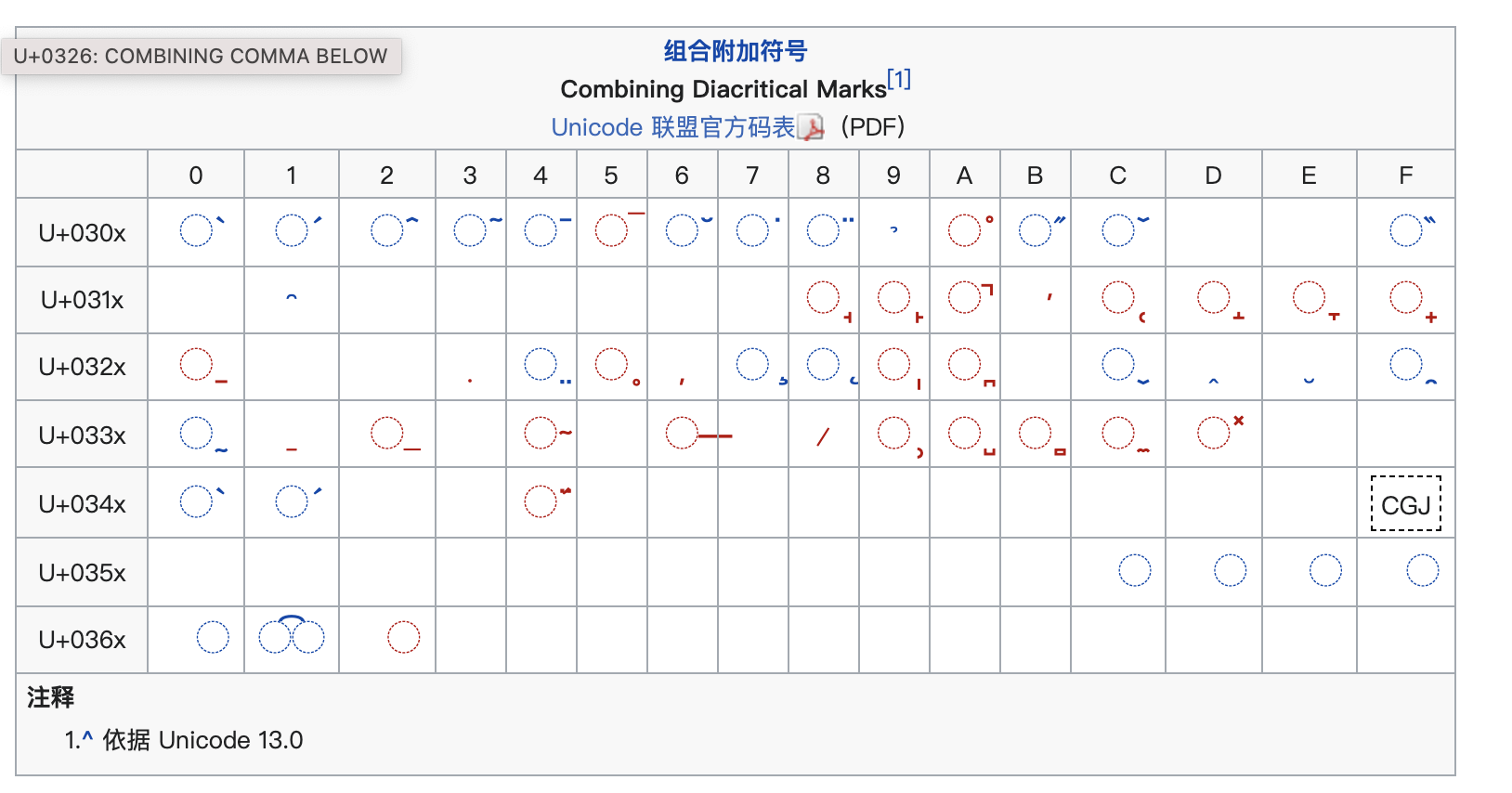
用于附加修饰的组合字可以有多个,并且不需要按照顺序:
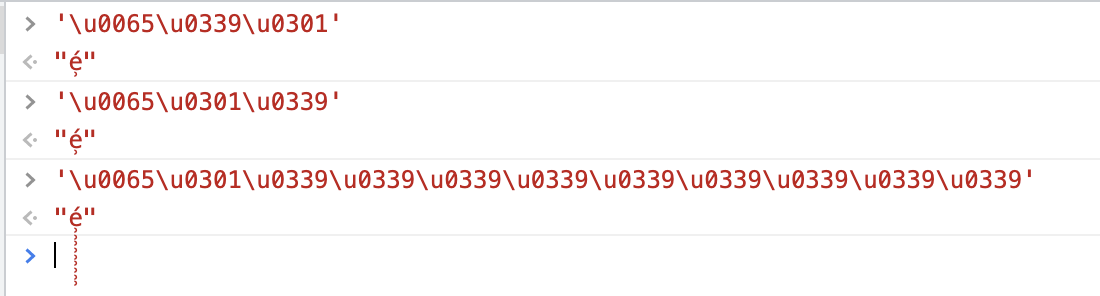
利用这个特点可以玩出一些「颜文字」、「越界字」等等。
上面我们知道,同样一个抽象字,却可能对应了多种 Unicode 编码,这就需要注意两个问题:
- 倒序的问题。如 JavaScript 这种做法显然是不符合预期的。但有的语言可以比较好的处理字素簇的问题,比如 Swift
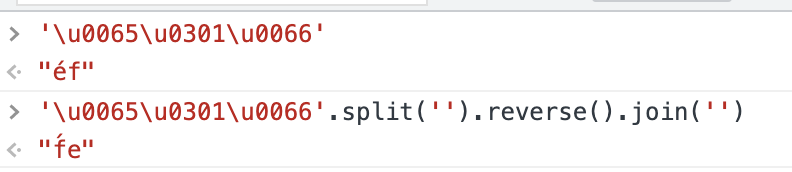
- 字符个数的问题。「éf」 的 Unicode 字符个数不能确定,有可能是 2 也可能是 3。有时候会带来一些问题。同样,能处理字素簇的语言也可以解决这类问题。
无法处理字素簇的语言往往是由于历史原因,设计之初没有考虑这种情况导致的。但年轻的语言比如 Swift、Rust 等均考虑了这类问题。
emoij 和 Unicode
emoji 起源于日本的绘文字(絵文字/えもじ emoji), 九十年代末出现。
Unicode 早期收录了一部分 emoji 在 BMP 中,但后来大部分的 emoji 都在 BMP 之后的平面。

比如
⭐️ : U+2B50
🆒 : U+1F192
所以说,emoji 的编码都超过了 2Byte 范围吗?不一定的。
另外 emoij 抽象字也可以由多个编码字组成,下面看一下:
- emoji 与组合字:
Unicode 的 emoji 规范中,人类相关的 emoji 都可以附加一个肤色。一个人类相关的 emoji 加一个肤色 emoji,可以得到带肤色的人类emoji:
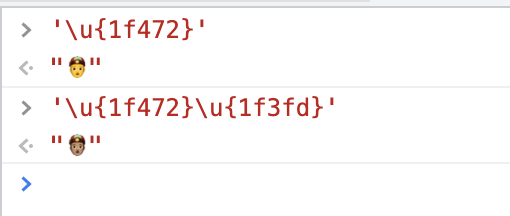
可以认为肤色就是一个「组合字」,emoji 中有一些组合字被称为「零件」

emoij 还支持单色/彩色的变换,用于一些简单的设备
怎么做呢?规则就是在普通的 emoji 码点之后,紧跟一个用来表示颜色版本的「变幻符」,这个变幻符有两个取值:VS15(U+FE0E)和VS16(U+FE0F)。其中 VS15 表示强制使用单色版,而 VS16 则表示强制使用彩色版。如果没有变幻符呢,每个 emoji 可以使用自己默认的展示。
举个例子来说,U+26A0这个emoji可以有两种样子:
⚠︎ (U+26A0 + U+FE0E)
⚠️ (U+26A0 + U+FE0F)
emoij 与零宽字符
可以使用零宽字符ZWJ(U+200D)将两个emoji连起来,使其看起来像是一个emoji。(不支持的系统会忽略零宽连字)
例如 👨:U+1F468 、ZWJ:U+200D 、👩:U+1F469、ZWJ:U+200D、👧:U+1F467,在系统支持的情况下会显示为一个男人一个女人和一个女孩组成的家庭emoji:👨👩👧,而不支持的系统则会顺序显示这三个emoji(👨👩👧)。
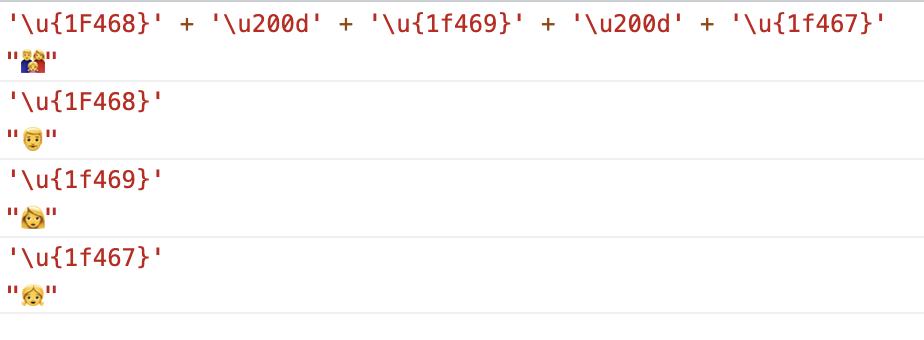
有的系统还支持将肤色、零宽字符组合起来用,创造出类似「一个黑肤色男人和一个白皮肤男人加一个黄皮肤小孩」的家庭。
emoji 和兼容性
比较早的 iPhone 中内置的 emoji 编码,位于 Unicode 的私有编码区,因此可能存在老版本 iOS 下打出的 emoji 在其他系统中无法显示的问题。
Unicode 和编码方式
有的同学可能会问了,不在 BMP 中的编码字符,编码值超过了 2Byte 的范围,是不是就变成 3Byte 表示一个字符了呢?
在存储的时候如何知道一个字符从哪里开始呢?比如 U+20077,也可以认为是 U+0002 和 U+0077 呢?

有这个疑问是对的。下面来研究一下。
前面提到了一个「编码字符集」的概念,指的是使用码点对无序字符集中每一个字符进行编号。在早期的编码字符集中,如ASCII,都是存储器里面直接放入编码字符集的对应编码,字符的编号是什么,就直接用这个编号作为存储中的编码。这在 ASCII 这样字符集中是没问题的。
但是 Unicode 就会有上面的问题。因为 Unicode 有 17 个编码空间,17 超过了 2^4 = 16,实际上用到了 2^5的容量,再加上每个平面都是 2^16,其实一共是 5 + 16 = 21 位。在 1Byte = 8 bit 的硬件设备中,要使用定长的方式表示Unicode,就会用到 3Byte。这样英文字符所占的空间就会 ASCII 情况下多三倍。
如果使用变长的方式去存储,就需要有一个识别变长的能力。如上面 U+20077 的问题。
前面提到的 GBK 编码,全角和半角字节数不同,其实就是用了变长的方式。国标码的策略比较简单,全角字符占两个字节,第一个字节必须是 1 开头的。这样找到 1开头的字节时,就知道接下来的两个字节共同表示一个字符了。如此一来,会有一些编码是用不到的,比如 0x0101。因为 0x0101 不知道是 0x0101作为整体还是两个 0x01。
而 Unicode 作为一种现代字符编码规则,用了一种截然的不同的策略。那就是把每一个字符的编码,用一种特殊的规则映射到编码之上。这样的策略过程就是「编码方式」(charset encoding)。
可以这么认为,ASCII 字符集的字符,其字符编码的编码方式就是一个常函数映射,即 f(x) = x
Unicode 的编码方式自然不是常函数,而且它有很多不同的编码方式,目前应用广泛。这就是我们常见的 UTF-8 和 UTF-16。
UTF-16
不要以为数字越大出现的越晚。实际上 Unicode 编码方式发展历史中,UTF-16 的起源要比 UTF-8 要更早。
前面提过,ISO 国际标准化组织当年也想搞类似的统一编码,搞了一套叫做 「UCS-2」 的编码方式。当时收录的字符没有超过 BMP 平面,因此 USC-2 使用两个字节表示一个字符。所以说,其实 UCS-2 是一种定长的字符编码方式!
UTF-16 则继承了 UCS-2 的编码方式,声称它是 UCS-2 的超集。UTF-16 的扩展在于解决「如何对超过 2Byte 容量的字符进行编码」的问题,把定长字符编码方式变成了变长。UTF-16 中,BMP 中字符使用 2Byte 编码,而其他平面需要对字符的编号进行转化,然后使用 4Byte 进行表示。
但是 UTF-16 是在 1996 才发布的,很多语言就没有赶上车,比如 Java / JavaScript。他们使用 Unicode 字符集表示字符串中的字符,却至今依然在用 UCS-2 的编码方式中 「1个字符的长度 = 2Byte」的计算方法。
这就是为什么 JavaScript 会有这样的 bug:
事实上,花括号的写法也是 ES6 之后才出现的。在此之前超过 BMP 的字符都需要使用两个 \uxxxx 表示(使用 UTF-16 的编码方式,马上讲)。这也解释了前面说的两种在 JavaScript 里面表示 Unicode 的方式。
UTF-16 对于 BMP 之外的字符,是如何编码映射的呢?
为了支持 UTF-16 的编码方式,Unicode 直接开辟了一个码段 U+D800 ~ U+DFFF,叫做 Surrogate,这个码段不存储任何字符,专门交给 UTF-16 去折腾。然后 UTF-16 又把这个区间分成两部分,U+D800 ~ U+DBFF 和 U+DC00 ~ U+DFFF,他们分别有多大呢?
U+D800 ~ U+DBFF,低位是一个完整字节 00 ~ FF,2^8,高位是 8~B 有 4 种,2^2,一共就是 2^10 个
同理,U+DC00 ~ U+DFFF 也是 2^10 个
想一下,如果 4Byte 中,前面 2Byte 都落到 U+D800 ~ U+DBFF 中,后面 2Byte 都落到 U+DC00 ~ U+DFFF 中,组合起来是不是就有 2^20 个啦?这已经大体可以与当前 Unicode 整体空间 2^21 一致。(但这也意味着,当前空间下,U+FFFFF(20bit)之后的字符无法映射。)
所以说 Surrogate 的给的空间可以满足 UTF-16 对 Unicode 进行编码映射了。
有了足够空间,现在就需要一个具体规则。
把上面 U+D800 ~ U+DBFF 用二进制的表示一下:
D800 1101100000000000
DBFF 1101101111111111
这个范围其实就是前面的 「110110」不变,后面的 10bit 从「10 个 0」变成「10 个 1 」
同样我们看下 U+DC00 ~ U+DFFF
DC00 1101110000000000
DFFF 1101111111111111
这个则是前面的 「110111」不变,后面的 10bit 从「10 个 0」变成「10 个 1 」
对于一个 U+0 ~ U+FFFFF 范围内的 Unicode 转换成 UTF-16 的方式就是:
把该码点二进制减去 0x10000,再补齐成 20 位
把前 10 位前面加上 110110,则会落到 D800 ~ DBFF 范围内
把后 10 位前面加上 110111,则会落到 DC00 ~ DFFF 范围内
上面的前 10 + 6 = 16 位,和后面的 10 + 6 = 16 位合到一起,则有了一个前 2Byte 在 D800 ~ DBFF 范围,后 2Byte 在 DC00 ~ DFFF 范围的 4Byte 编码。
举一个例子:
😀 Unicode 是 U+1F600,减去0x10000, 二进制是: 1111011000000000
补齐为 20 位: 0000 1111 0110 0000 0000
前 10 位是 0000 1111 01,前面补上 110110,则是 1101 1000 0011 1101,十六进制就是:D83D
后 10 位是 10 0000 0000,前面补上 110111,则是 1101 1110 0000 0000,十六进制就是:DE00
所以 😀 的 UTF-16 的编码应该是 D83D DE00
验证一下:

UTF-16 至少使用两个字节表示一个字符,这对东方文字来说没问题。但是对西方世界的语言文字就不太友好了。使用 UTF-16编码方式存储的英文字符,所占的空间要比 ASCII 编码大一倍,所以它推广起来也受到了一定的阻力。
另外,上面也分析了,U+FFFFF 之后的字符无法使用 UTF-16 表示。
但由于 UTF-16 出现较早,windows、Java、JavaScript 等平台和语言都一定程度上采用这种编码方式。
UTF-8
UTF-8 应该是目前最常接触到的编码方式。广泛应用于网页、电子邮件等等互联网相关的场景。Linux 和 MacOS 中采用了 UTF-8。浏览器解析 HTML 时,也默认使用 UTF-8 的方式。
跟 UTF-16 编码方式思路类似,但是它的编码方式更加灵活。具体是:
遇到 11110 开头字节,要跟后面三个字节共同编码一个字符,共 4Byte。
遇到 1110 开头字节,要跟后面两个字节共同编码一个字符,共 3Byte。
遇到 110 开头字节,要跟后面一个共同编码一个字符,共 2Byte。
遇到 0 开头字节,独立一个字节编码一个字符,这部分跟 ASCII 完全兼容。
遇到 10 开头字节,一定是 1、2、3 编码中非开头的字节。
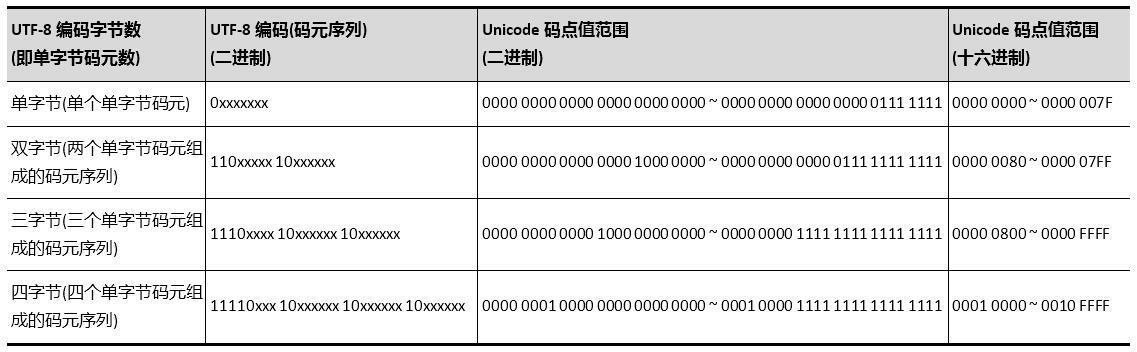
单字节可编码的 Unicode 码点值范围十六进制为0x0000 ~ 0x007F,十进制为0 ~ 127;
双字节可编码的 Unicode 码点值范围十六进制为0x0080 ~ 0x07FF,十进制为128 ~ 2047;
三字节可编码的 Unicode 码点值范围十六进制为0x0800 ~ 0xFFFF,十进制为2048 ~ 65535;
四字节可编码的 Unicode 码点值范围十六进制为0x10000 ~ 0x1FFFFF,十进制为65536 ~ 2097151;
如果需要扩展,如 U+1FFFFF 之后字符,则按照上面规则,继续添加 111110 开头即可。
这里可以参考 UTF-16 的内容,想一下它们的范围为什么是这样的。
由于 UTF-8 和 ASCII 对英文的编码是一模一样的,所以得到了英文世界的广泛使用。但是汉字的码点范围已经大于 U+07FF,按照上面的列表,在UTF-8 中,一个汉字编码要占三个字节,反而要比 UTF-16 要大。
与 UTF-8 相关的场景(偏前端开发):
encodeURI / encodeComponentURI 与 UTF-8
在前端开发中,我们经常遇到需要使用 encodeURI / encodeComponentURI 的情况,这两个函数会把除了 0-9a-zA-Z以及一些特定字符之外,其他字符全部变成 UTF-8 的十六进制表示,并在每个字节前面加上一个 %,比如:
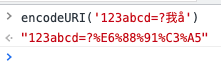
(encodeURI 和 encodeComponentURI 的区别在于哪些「特定字符」不会转成 UTF-8 的形式,不清楚的同学可以自行 Google一下。)
为什么要这么做呢?因为 URI 相关标准规定,URI 中的字符集,必须在 ASCII 字符集范围内,其他不支持。我们经常在浏览器中看到带汉字的URL,那是因为浏览器为了方便用户,在地址栏的显示中对 URL 做了一定的解码处理。比如说:

看一下网络请求的话,其实会变成这样:

复制一下地址栏的链接,把它拷到控制台中也是这样:

那既然浏览器会自己处理,为什么还需要手动调用 encodeURI 呢?因为在历史上有一个坑点,URI 的 path 部分,浏览器一般都是默认使用 UTF-8对非 ASCII 的字符进行编码,但是对于查询字符串(也就是 ? 后面的字符)和 Ajax 请求中的 query 部分,则不一定。
比如有些网站手动设置了 charset=gbk,此时查询字符串中就会使用 GBK 进行编码。较早版本的百度网站正是这样…
还有一些没有设置 charset 的网站,早期的浏览器会使用系统默认代码页进行编码。我们知道较早的 windows 中文系统使用的代码页正是CP936,也就是使用 GBK 编码。
这就会造成一些麻烦,后端在解析链接、请求等等的时候,需要考虑很多种情况。但使用 encodeURI 就可以解决这个问题,因为它会统一使用 UTF-8进行处理。
最后问两个发散性的问题:
在前端输入一段字符串,使用 .length 打印出来是 10,屏幕中可能实际显示了多少个字符?为什么?
输入法在编辑器中打字,为什么通常不会乱码?需要解决哪些问题?