音视频常见问题分析与SDP标准
原文出处:音视频常见问题分析和解决:延时和抖动
问题背景:
在上一篇文章讲了音视频一些疑难问题的排查,其中一个比较重要的原则就是要将音视频作为一个系统来看待,问题有可能只是表现在播放端,但是根因有可能在编码端,也有可能发生在传输过程中。其实对于音视频有些问题的优化,有时也要整体优化,比如延时这种问题。
下面我将会分析延迟的概念,延迟的产生和类型、延迟的优化三大部分的内容,最后再通过一两个小例子分享下我在解决延迟问题的优化实践。你可以根据自己的需要,选择性阅读。
延迟抖动:
延迟:是网络传输中的一个重要指标,测量了数据从一个端点到另外一个端点所需的时间。一般我们用毫秒作为其单位。通常我们也把延迟叫做延时,但是延时有时还会表示数据包发送端到接受端的往返时间。这个往返时间我们可以通过网络监控工具测量,测量数据包的发送时间点和接受到确认的时间点,两者之差就是延时。单向时间就是延迟。
抖动:由于数据包的大小,网络路由的路径选择等众多因素,我们无法保证数据包的延迟时间是一致的,数据包和数据包延迟的差异我们称为抖动。也就是说因为数据包的延时值忽大忽小的现象我们称为是抖动。
可以看出延迟会造成抖动,但是抖动并不完全等价于延迟,所以有时我们分析实际问题时还是要加以区分。
大学经常看直播球赛,记得舍友用笔记本看,球都进了,我这边用手机过了一会才看到刚才球进的画面。这就是典型延时场景,其中各个行业对延时的容忍度不一样,像K歌合唱 就对低延时要求非常高。如果歌伴都唱完了上半句,你由于没有及时听到,下半句还没唱出来,对方是非常疑惑的。
但是我们也不能一味的追求低延时,低延时是好,但是会带来成本的上升。在实时传输领域有一个著名的三角理论。
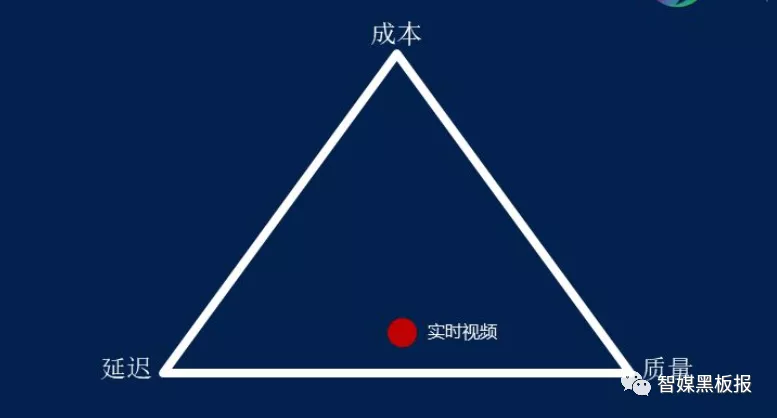
成本我们可以理解为购买服务器需要的硬件成本、软件开发的人力成本和通讯带宽的租赁费用;延时就是上面理解的数据包端到端之间的时间差,质量可以理解为视频的清晰度和细节,音频的高保真以及数据的完备性。任何行业完成实时数据交互,都要受这三方面的因素的限制。如果过分追求低延时,要么我们要付出比较高的成本要么我们得下降我们的音视频质量。所以我们针对不同行业,选择一个用户能接受和不影响体验的延时即可。
关于视频的实时性归纳为三个等级:
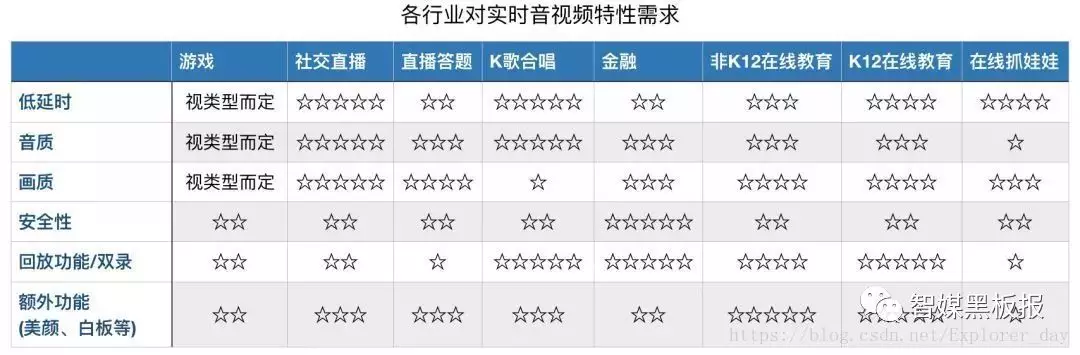
伪实时:视频消费延迟超过 3 秒,单向观看实时,通用架构是 CDN + RTMP + HLS,现在基本上所有的直播都是这类技术;准实时: 视频消费延迟 1 ~ 3 秒,能进行双方互动但互动有障碍。有些直播网站通过 TCP/UDP + FLV 已经实现了这类技术,YY 直播属于这类技术;真实时:视频消费延迟 < 1秒,平均 500 毫秒。这类技术是真正的实时技术,人和人交谈没有明显延迟感。QQ、微信、Skype 和 WebRTC 等都已经实现了这类技术。对于严格的音频通话,当延时低于200ms时,就会影响到用户体验。达到400ms对方用户就容易感知出来,1s以上的延迟对于交互式实时直播就不能接受了。下面有一个表格基本列举了不同业务对于低延时的大致要求,当然即使是同一个业务,应用在不同的场景下对于低延时要求也经常不一样,这就导致我们解决问题的技术手段也是不一样的。在视频监控业务下这种差异更大,对于一些司法、监狱和博物馆,实时性要求很高,希望出现问题后立即能进行报警和进行查看,但是对于一些景区直播和学校社区实时性的要求就低很多。
延迟产生:
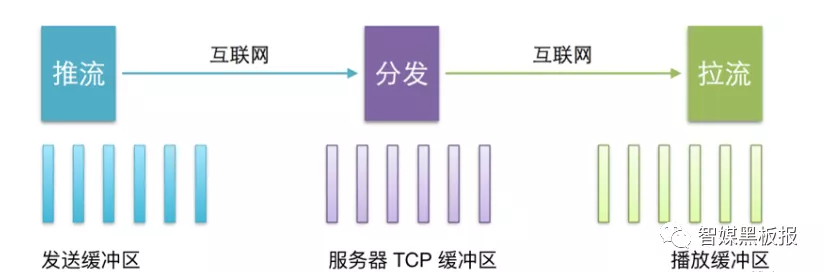
我们继续看下一个完整直播系统的示意图:

音视频从生产到消费的各个环节都需要花费时间来处理,这些时间之和就造成了视频观看方看的视频是视频产生方几秒之前产生的视频。我们对这些延时进行区分,会总结出以下四种类型的延时:
处理延时:一般就是路由器要分析数据包头决定这个数据包要送到下一站花费的时间;
排队延时:数据包从进入到路由器的发送队列到被发送之间经过的时间,路由排队算法和网络都会影响这部分延时。
传输延时:将数据包传入到线路花费的时间,跟数据包的大小和带宽有关系。
传播延时:是指数据包第一个bit位从发送端到接收端的时间,其和传输距离和传播速度有关系。
其实对于音视频系统,我们可以将上面讲述的三种延时归纳为下面几种:
设备端的延时:包括数据的采集、前处理、编码、解码、渲染等处理阶段花费的时间。也就是A1和A5花费的时间。
音频部分:
音频从采集后,会经过模数转换,将传统的模拟信号转换成数字信号就会产生延时,一般在10ms级别;采集后,进行编码,采用不同的音频编码器也会产生不同的延时,以Opus为例,延时也在2.5ms-60ms级别,可以参考上篇文章分析。发送前还需要进行3A算法(AEC、ANS、AGC)的处理,又需要十几ms.
视频部分:
从自然采光到成像,取决于CCD和CMOS的成像效率,不过一般也需要几十ms.对采集的RGB数据要进行YUV转换和编码,如果还有B帧会产生比较大的编码延时,紧接着播放端的渲染也是需要一定时间的。
无论音频还是视频,为了防止抖动我们一般会在播放端加上jitter buffer缓存,数据从进入到缓存到出缓存以及当发生丢包时,进行的一些传输算法处理也是需要一定的时间,大概会在几十毫秒到几百毫秒之间。
设备端和服务器的延时:也就是俗称的第一公里和最后一公里的延时,包括了A1到A2推流产生的延时和A5向A4拉流的延时。这里的延时跟设备端距离服务器的物理距离,服务器和设备端的网络运营商,设备的网速和带宽,设备端自己的负载都有密切关系。
服务器之间的延时:包含了音视频数据在网络上进行再次转码、切片、转封装和协议以及分发CDN等花费的时间,包含了A2到A4整个阶段花费的时间。这里要看设备的推流端和播放端是不是在同一个边缘节点,如果属于同一个边缘节点,那延时能小点。国内城市之间的传播延时也在几十毫秒,如果跨洲延时会达到百毫秒以上。
所以单就降低实时音视频系统延时一项内容,都不是靠只优化一个节点或者一个阶段就能达到你想要的预期效果,必须站在音视频整个系统来看待。
延迟测量:
测试方法1:
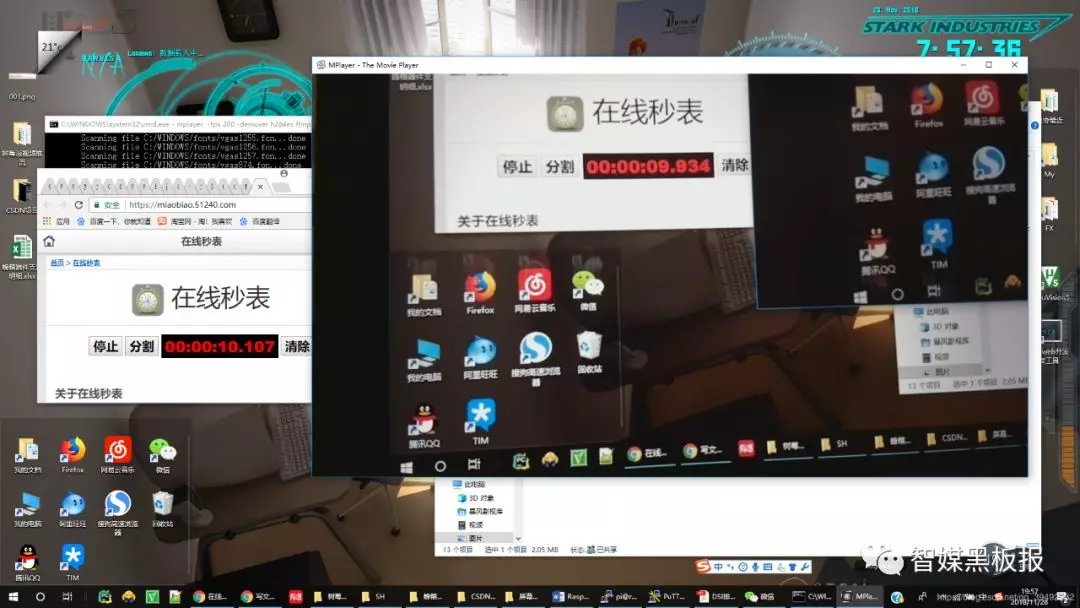
实际最简单的做法就是:我们让推流端也就是主播端比如手机或者IPC摄像头对着一个在线秒表,然后同时我们用手机或者桌面播放器播放该路视频,然后得到了在线秒表显示的时间,等稳定一段时间后我们将在实际线秒表的时间减去播放器显示的该时间,二者的差值就是当前的系统的延时。然后这种测试方法,每隔一段时间,测试多组,求其平均值 就得到了当前负载下的音视频延时。
测试方法2:
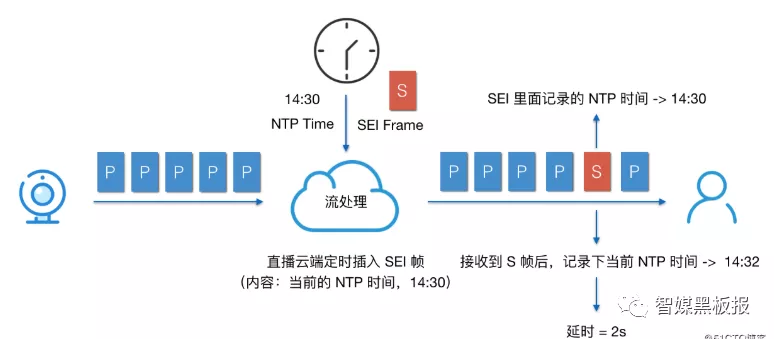
我们也可以在编码端的视频帧前面加上SEI帧,SEI的全称是补充增强信息(Supplemental Enhancement Infomation),提供了一种向视频码流中增加额外私有信息的方法。我们可以隔一段时间就在I帧前面的SPS PPS后面增加SEI帧,私有信息就是这时我们编码器的NTP标准时间,当该SEI帧信息到达播放器端,我们再计算下本地的NTP时间。这样本地的值减去SEI的NTP时间,就是当前系统的延时。前提条件,编码器和播放器进行过NTP校时,保证毫秒级别的时间信息要一致。
注:对于有些播放器如果增加SEI信息,可能会导致播放失败,所以解码前我们可以将使用过的SEI帧丢掉。
延迟优化:
经过以上的分析,我们就分析出延时产生的阶段和节点,这样优化延时就有了方法。延时会产生在:
音视频数据的前处理;
音视频数据的编解码;
音视频数据的网络传输;
为了防止抖动业务代码中的缓冲区,包括推流服务、转码服务、播放器的缓存等;
音视频的渲染播放;
当然上面会产生延时的地方对于最终的延时影响权重是不一样的,其中数据的前处理、编解码、渲染对于延时影响比较小,而网络传输和业务代码的缓存对于延时影响非常大。所以优化也要结合你的业务有重点进行。
优化思路1:调整推流端和播放端的缓冲区大小,对于25fps的视频流,如果我们缓存25帧的数据,就会在播放时产生1s的延时。所以我们要动态调整我们的缓冲区,对于推流上行区我们如果带宽不够就会产生网络阻塞,这时发送端的数据就会积累,最终延时不断累加,导致延时变大。我们此时就需要有一套机制来能够预测带宽,降低发送码率,减低当前发送数据量,减少网络阻塞,等网络好的时候再继续增大数据发送量,增大码率。
上面说的这些算法有很多,其中WebRTC方案就采用了GCC算法,还有一些类似BBR的算法来实现上述想法。
对于播放端的缓存,当网络不好产生的延时比较大时,我们需要通过丢帧和加速播放方式快速消耗掉播放缓冲区的数据,从而消除累计的延时。
优化思路2:优化网络传输,如果实时性要求很高的场景,你如果选用基于TCP承载的网络传输协议,无论你怎么优化,也很难降低延时。因为TCP会进行三次握手,而且它会对每一次发送的数据进行确认,还要对丢包进行重传,所以这些限制很不适合降低延时。我们要优化传输协议,我们可以将基于TCP的RTMP、HLS协议切换到基于UDP的RTP、QUIC协议上,或者自己开发基于UDP的私有协议栈,这样我们就可以对一些TCP延时大的功能进行裁剪和修改,对于一些不关重要的数据进行丢弃,优先保障重要数据的传输。其中国内B站、虎牙直播,在线k12教育等都进行了类似的处理;
优化思路3:选择优质的CDN加速服务,保障传输的线路带宽和线路资源,一般都会提供测速选线、动态监测、智能路由等功能。
优化思路4:如果感觉自己的编解码,前期处理等花费时间比较多,我们就需要选择合适的音视频编解码器,进行算法调优降低延时,比如我们在播放端能支持硬解的优先选择硬解否则才选择软解。
上面所说的任何一种实践方法用一两篇文章都讲述不完,特别对于一些GCC、BBR等网络传输算法,依然是高校和大厂最前沿最热门的研究领域,需要用心学习才能落地到工程项目上,这里只是简单的提出,有兴趣的需要进一步搜索学习和实践。后面本公众号也会进行逐渐介绍这些算法,敬请期待。
案例分享:
案例1:
问题:
前一阵我们做了一个项目,就是将自家消费类摄像头的视频投屏到像Alexa的智能音箱上,当然音箱就是带屏幕那种,类似小度小度。实际测试发现,延时比较大,大概有七八秒钟的样子,但是对于Alexa这种智能音箱也就是播放器,我们能干预的很有限,毕竟推动亚马逊研发给你优化这些都是不太可能的,但是我们想把自家摄像头视频投屏到Alexa后,这样在他们商场上架我们产品可以加快我们的硬件海外出货速度,同时还可以增加我们视频云的套餐订阅量。
措施:
最后我们采取了优化转分发服务器缓存的做法,采取了服务端主动追帧和丢帧的策略使服务器端的缓存能够根据当前网络状态进行自动调节,让Alexa播放器的播放缓存总是处于基本饥饿状态,经过一番优化后,延时从七八秒降低到一二秒,达到了上架IPC摄像头的条件。
所以服务端和播放端的缓存优化是降低延时的一个比较重要手段。
案例2:
问题:
还有一个项目采用了自动切换网络传输协议的措施来降低延时,摄像头的视频一般要推送到云服务器上,然后才能进行大规模的转发和分发。这是因为摄像头毕竟是嵌入式设备,并发量非常有限,能同时推送的视频路数也就一两路,如何想无限制进行分发和允许多客户端同时观看,就需要先让摄像头的视频上云到服务端的流媒体,再进行大规模的分发和转发,这也是视频监控的基本玩法。但是我们摄像头以前只支持TCP长链接方式向服务器推流,这样当网络不好就会丢包重传,延时也逐渐积累增大。甚至网络非常不好时,延时会达到几十秒,用户体验很不好。
措施:
我们流媒体服务端会收集播放器的延时数据和丢包,然后当达到一定条件,我们通过信令服务器进行传输协议切换,重新让摄像头推流。将TCP推流改成UDP推流,我们在流媒体服务器端重新实现组包和增加丢帧策略,降低播放端延时,效果最后也得到了客户的满意。
今天就说这么多,祝您心情愉快,工作顺利!
往期回顾文章:
原文出处:SDP在RTSP、国标GB28181、WebRTC中的实践
问题背景:
无论你是用微信进行视频电话还是开Zoom视频会议,按照OSI网络七层参考模型,我们进行这些活动之前一般都要先建立一组会话。在建立会话的过程中,我们需要描述下会话的一些信息,描述这种会话能力时用到了SDP协议,也就是会话描述协议Session Description Protocol,协议详细内容在RFC4566中规定。
这么说可能不够直白,大白话解释就是:由于Web端、IOS、Android、PC、MAC端的差异性导致它们对音视频的支持能力不同,所以我们进行一些音视频会话之前,需要交互下彼此的音视频编解码能力、网络带宽和传输协议等信息,这些需要协商的信息需要用SDP来描述。
注意的是SDP虽然具备这些能力参数信息的描述功能,但是SDP并不是传输协议,需要用RTSP、SIP、HTTP等协议进行承载传输、交换,如果大家协调好了之后,就可以建立会话,完成真实的音视频码流传输,再完成解码和播放。
这篇文章主要讲下SDP协议格式和规范、具备哪些描述能力、最后再通过在RTSP和基于SIP的国标协议进行实例分析下,当然目前比较火的WebRTC在建立音视频会话前也是通过这套协议描述会话信息的。SDP应用在任何场景和行业标准中,一般都进行了裁剪和进一步的规范,如果你要了解所有的SDP信息,你可以参考RFC4566文档,如果需要了解在WebRTC中使用可以参考链接:https://www.ietf.org/archive/id/draft-nandakumar-rtcweb-sdp-08.txt
SDP格式和规范
SDP场景:
SDP一般用在媒体会话建立之前,可以适用于实时流媒体、点播、直播等领域,特别在音视频通话、视频会议、VoIP、视频监控等领域应用较多。媒体码流一般基于RTP传输,服务质量用RTCP协议保障。
但是SDP的交互不是所有音视频会话建立时都是必须的,假如双方提前约定好这些音视频会话创建需要的信息就不用这个步骤来交互彼此的SDP信息,比如HTTP-FLV、RTMP-FLV直播和点播方案,因为一旦采用了这套方案,这些音视频会话建立需要的信息都是确定的,但是这样会降低或者说没有充分发挥端到端的音视频能力,协商显得更加灵活点。
SDP作用:
SDP作用包括以下一些方面
1)建立会话的详细信息,包括名称,网络,带宽等信息
3)包含在会话中的媒体信息,包括:
媒体类型(video, audio, etc)
传输协议(RTP/UDP/IP, H.320, etc)
媒体格式(H.261 video, MPEG video, etc)
多播或远端(单播)地址和端口4)为接收媒体而需的信息
5)使用的带宽信息
6)可信赖的接洽信息
如果拓展,还可以描述会话的安全方案信息、服务质量信息等,其中WebRTC就在SDP的基础上进行了继续拓展,可以参考:
https://www.ietf.org/archive/id/draft-nandakumar-rtcweb-sdp-08.txt。
SDP格式:
标准的SDP规范主要包括SDP描述格式和SDP结构,其中SDP结构里面最重要的两项内容是会话描述信息和媒体描述信息。
说了这么多,先上个SDP的示例,有个SDP的直观认识:
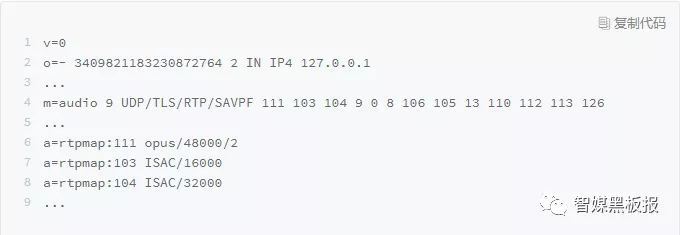
SDP是由多个
整个SDP 由这样一行行的key-value字符串组成,同时整个字符串组成了会话信息描述和多个媒体级别描述。至于会话信息和媒体信息描述的key和value到底怎么定义需要继续分析下各个字段,其中有些字段是必须的有些是可选项。
会话描述和媒体描述,一般会话级描述从v=开始一直到第一个媒体描述为止,媒体描述是从m=开始一直到下一个媒体描述m=的位置之前。也就是说SDP里面一般先从会话信息v=开始,然后后面跟几个m=的媒体描述组成。
会话级的作用域是整个会话,其位置从v=开始到第一个媒体描述m=为止;
媒体级描述 是对单个媒体流即音频流、视频流和字幕流等的单个媒体描述,如果有多个流则用多组媒体级描述。其中每个媒体级描述就是从m=开始到下一个媒体描述m=为止。

SDP结构:
上面了解了SDP的基本信息,下面看下各个字段含义,当然字段非常多,只看一些常用和必须的,对于有些场景下的字段你需要参看SDP的RFC4566文档进一步了解,同时了解下各个行业的标准对这一块的规定,后面示例分析会介绍完整的应用字段解释。
会话描述部分:
- v**=**
v就是protocol version,必选字段,表示了SDP的版本号但是不包含子版本号,一般就是v=0。
- o**=**
o是owner,必选字段,对会话发起者的一个信息描述,其中包含了用户名、会话ID、网络地址等信息。格式是:
o=
- s**=**
s即session name,表示的会话名称,必选字段。在整个SDP里面只有一个会话名称,有且仅有一个这样的字段。
- t**=**
t即time the session is active,必选字段,表示的是该会话的开始到结束时间,如果是持久会话,则时间值填0,这样的时间是NTP时间,单位是秒,格式是 :
t=
媒体描述部分:
这部分字段非常多,也重点介绍几个,其余字段用到需要参考RFC文档和后面的示例分析:
- m**=**
m就是media name and transport address,可选字段,但是一般音视频会话至少有音频流或者视频流,所以一般也是都会有的,如果多个流则有多个,一般就是从这个m=到下个媒体会话m=结束,格式:
m=
- a=
a是attribute,可选字段,表示的媒体的属性,进一步的描述媒体信息,可以有多个属性,其中比较重要的属性就是rtpmap和fmtp,格式是:
a=
a=
rt**pmap属性,表示媒体流传输协议的RTP具体内容:**
a=rtpmap:
rtpmap:是rtp map即RTP参数映射表
fmtp属性,在rtpmap基础上进一步描述音视频具体编码参数信息:
格式:
a=fmtp:
fmtp,格式参数,即 format parameters;
SDP的字段非常多,在不同场景下约束不同,下面看下在RTSP、国标SIP协议、WebRTC中的具体示例。
示例分析:
RTSP中的SDP:
RTSP即Real Transport Stream Protocol实时流媒体传输协议,一般和RTP、RTCP搭配使用,该协议用来进行媒体的控制和会话的建立,比如开始、暂停、倍速控制媒体文件的播放,RTP协议用来进行码流的传输,RTCP保障服务的Qos质量。该协议的应用场景在视频监控最多,一般的视频监控产品如摄像机、NVR等都原生支持RTSP协议,同时该协议在一些智能家居方面如智能音箱也有所使用,比如AWS Alexa在进行视频投屏时就支持该协议。
这里只探讨下RTSP协议的创建媒体会话时,用SDP交互会话信息时的情况,顺便给大家一个测试地址,然后用VLC播放视频抓包就可以学习RTSP、RTP协议,RTSP协议默认端口554,测试地址:
rtsp://wowzaec2demo.streamlock.net/vod/mp4:BigBuckBunny_115k.mov
这是抓包在DESCRIBE信令的SDP信息:
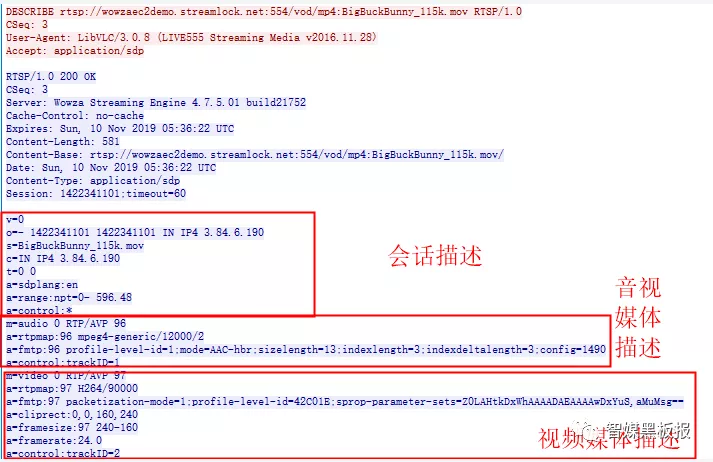
会话描述协议:
v=0
解释:版本号,一般默认是0;
o=- 1422341101 1422341101 IN IP4 3.84.6.190
解释:会话发起者信息会话名称 网络类型 IP地址等信息;
s=BigBuckBunny_115k.mov
解释:会话名称
c=IN IP4 3.84.6.190
解释:
格式:c=
链接信息,包含网络类型和IP地址等信息;
a=range:npt=0- 596.48
解释:用来表示媒体流的长度为596.48秒
音频**媒体描述信息**:
m=audio 0 RTP/AVP 96
解释:表示该路会话的的audio是通过RTP来格式传送的,其payload值为96但是传送的端口还没有定。
a=rtpmap:96 mpeg4-generic/12000/2
解释:rtpmap的信息,表示音频为AAC的其sample采样率为12000双通道音频,其中mpeg4-generic代表了AAC的互联网媒体类型。
a=fmtp:96 profile-level-id=1;mode=AAC-hbr;sizelength=13;indexlength=3;indexdeltalength=3;config=1490
解释:这里面是AAC的详细编码和封装信息:
profile-level-id=1;mode=AAC-hbr;
profile中指定1表示低复杂度类型,mode=AAC-hbr代表编码模式;
sizelength=13;indexlength=3;indexdeltalength=3
涉及到AAC的AU Header,如果一个RTP包则只包含一个AAC包,则没有这三个字段,有则说明是含有AU Header字段,具体参考RTP对音频AAC的封装。
AU-size由sizeLength决定表示本段音频数据占用的字节数
AU-Index由indexLength决定表示本段的序号, 通常0开始
AU-Index-delta由indexdeltaLength 决定表示本段序号与上一段序号的差值;config=1490十六进制:1490
二进制:0001 0100 1001 0000
十进制:2、9、2
分别代表aac的profile是2、9代表采样率是12000,通道个数是2立体声,具体参考AAC的ADTS头定义。
a=control:trackID=1
解释:通过媒体流1来发送音频;
视频**媒体描述信息**:
m=video 0 RTP/AVP 97
解释:表示该路会话的的audio是通过RTP来格式传送的,其payload值为97但是传送的端口还没有定。
a=rtpmap:97 H264/90000
解释:表示该路会话的的Video是通过RTP来格式传送的,其payload值为97,编码器是H264,采样率90000。
a=fmtp:97 packetization-mode=1;profile-level-id=42C01E;sprop-parameter- sets=Z0LAHtkDxWhAAAADAEAAAAwDxYuS,aMuMsg==
解释:这里面包含一些RTP封包模式,视频质量等级,视频的SPS、PPS等信息。
表示该路会话的的audio是通过RTP来格式传送的,其payload值为97。
当 packetization-mode 的值为 1 时RTP打包H.264的NALU单元必须使用非交错(non-interleaved)封包模式.
当 profile-level-id的值为 42C01E 时, 第一个字节0x42表示 H.264 的 profile_idc类型Baseline profile , 第二字节代表profile_iop,各个Bit代表视频序列遵循的条款,第三个字节表示 H.264 的 Profile级别,0x1E即30代表了levle_idc为3,即30/3,具体信息参考H.264的SPS PPS即可。
sprop-parameter-sets是SPS和PPS的的Base64之后的字符串,中间以逗号分割,后面会专门写篇文章介绍下,主要描述了编码器的参数信息,对初始化播放器有帮助;
a=cliprect:0,0,160,240
解释:一些offer和answer的加密属性;
a=framesize:97 240-160
解释:RTP负载类型97,帧宽和高分别为240*160
a=framerate:24.0
解释:最大帧率速度为24帧/s
a=control:trackID=2
解释:通过媒体流1来发送视频;
基于SIP协议**国标GB28181中的SDP:**
国标协议也是基于SIP协议开发的,所以这里的SDP协议是在给前端设备下发INVITE信令的回复中带上来的,这里的SDP主要是为了不同的厂家,使用 GB对接的时候,上级要能正常看下级推送过来的摄像头的视频,回放,以及球机控制等等的功能。
现在看一个抓包文件中INVITE回复携带的SDP描述信息:
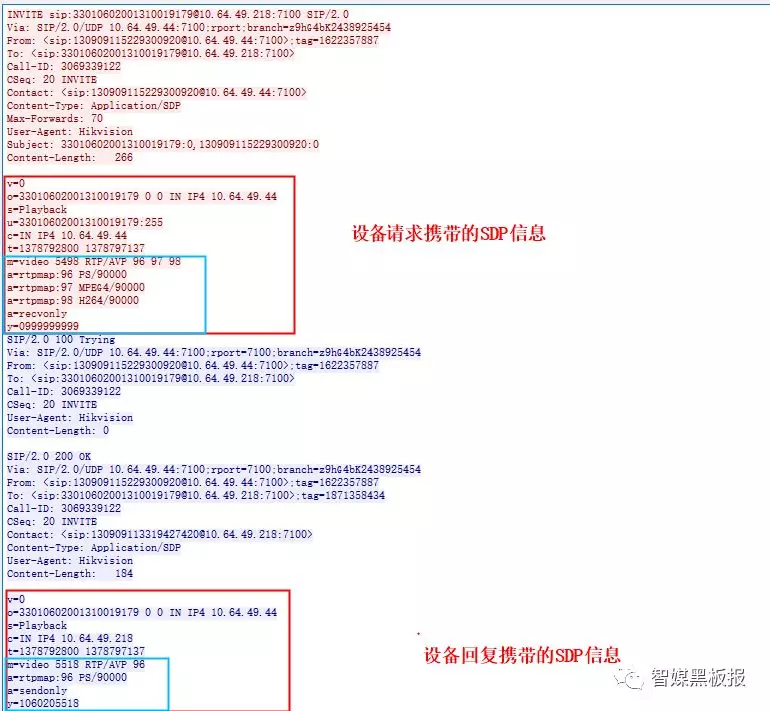
会话信息描述国标的规定:
v=0
v字段给出了 SDP 的版本,当前规范版本是 0,这个版本没有小号版本。
o=
源(客户端的SIP编号)<用户名><会话 ID><会话版本><网络类型><地址类型><单播地址>
如 32028100001320000001 0 0 IN IPV4 192.168.0.101
各个字段解释:
<用户名> 用户登录的源主机名字,如果不能提供则用"-"表示,用户名不能包含空格。这
里一般是摄像机的国标 ID
<会话 ID> 是一个字符串,<用户名><会话 ID><网络类型><单播地址>这个组合形成该会话
的唯一标识。用 0 标识的居多
<会话版本> 会话版本号,推荐使用 NTP 时间戳。用 0 标识的居多
<网络类型> 目前是 IN 代表 internet,未来可能会有其他值。
<地址类型> 目前只有 IPV4 和 IPV6 两种,目前主要是 IPV4,。
<单播地址> 创建会话的主机地址。一般为媒体服务器的地址。
注意:有时候处于某种原因,用户名和 IP 不想明确表示,只要保证 o 字段全球唯一,用户名和 IP 可以随机。
- s=
请求媒体流的操作类型,play 代表实况;playback 代表回放。download 代表下载,Talk
代表语音。
- u=
行应填写视音频文件的 URI。 该 URI 取值有两种方式: 简捷方式和普通方式。
简捷方式常用 摄像机 ID:其他参数格式。如 32028100001320000001:10111
普通方式采用 http://存储设备 ID[/文件夹] /文件名, [/文件夹] 为 0-N 级文件夹。
简捷方式中冒号后面文件类型,如果s=playback时,则0有时代表的全天录像,1代表事件录像等,一般默认为3.有些海康平台这里进行了区分,如果值填错会导致回放录像失败。
- c=
<网络类型><地址裂类型><链接地址>
如 IN IPV4 192.168.0.100
6.t=
t字段在回放和下载时,t 行值为开始时间和结束时间。使用的时间为 UNIX 时间戳,需要
用 UNIX 时间戳转为北京时间。如果是直播则是0.
媒体信息描述国标的规定:
- m=
m 字段描述媒体类型,媒体端口,媒体协议,以及媒体负载方式
例:
m=video 6000 RTP/AVP 96------媒体类型视频或视音频,传输端口 6000,RTP over UDP,负载类型 96
m=video 6000 TCP/RTP/AVP 96------媒体类型视频或视音频,传输端口 6000,RTP over TCP,负载类型 96
m=audio 6000 RTP/AVP 8------媒体类型为音频,传输端口 6000,RTP over UDP,负载类型 8
- a=
a=rtpmap: **
a=downloadspeed: 下载倍速(取值为整型) ;
a=filesize: 文件大小(单位:Byte) , a 字段可携带文件大小参数, 用于下载时的进度计算。
下面可以参考IETF RFC4571的规定,解析setup connection recvonly等属性:
a=setup:TCP 连接方式(表示本 SDP 发送者在 RTP over TCP 连接建立时是主动还是被动发起 TCP 连接, “active”为主动, “passive”为被动)
a=connection:new (表示采用 RTP over TCP 传输时新建或重用原来的 TCP 连接, 可固定采用新建 TCP 连接的方式)
a=recvonly 只接受(收流端)只用于媒体,不用于控制协议
a=sendonly 只发送(发流端)只用于媒体,不用于控制协议
y **字段:**由 10 位十进制整数组成的字符串,表示 SSRC 值
第一位为 0 代表实况,为 1 则代表回放, 第二位至第六位由监控域 ID 的第 4 位到第 8 位组成,最后 4 位为不重复的 4 个整数 ;
有了以上基础分析国标SIP中的SDP信息就非常简单了,不再赘述。
WebRTC中的SDP:
WebRTC中的SDP信息比较关键,是分析代码流程和驱动整个业务运转起来的关键,同时WebRTC规范也对SDP的RFC4566规范进行了进一步的规范,也已经成为SDP草案,具体参考:https://www.ietf.org/archive/id/draft-nandakumar-rtcweb-sdp-08.txt
其中SDP包含了下面几个板块的内容,比RTSP和SIP中的更丰富更强大:
其中会话描述、网络描述、媒体流描述和SDP的RFC4566规范是一致的,同时增加了安全描述和服务质量QOS描述,我们进行了P2P抓包:

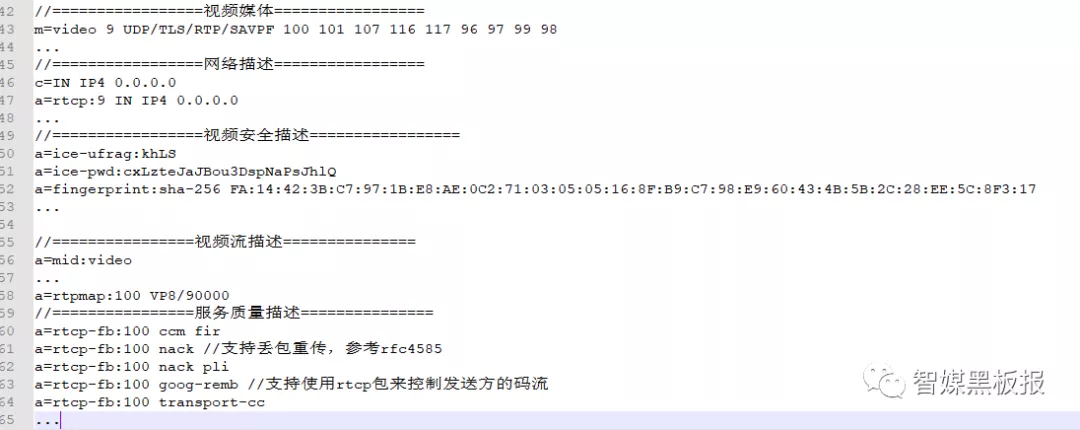
WebRTC中的SDP 是由一个会话层和多个媒体层组成的, 而对于每个媒体层,WebRTC又将其细划为四部分,即媒体流、网络描述、安全描述和服务质量描述。
其中,安全描述起到两方面的作用,一方面是进行网络连通性检测时,对用户身份进行认证;另一方面是收发数据时,对用户身份的认证,以免受到对方的攻击;
服务质量描述指明启动哪些功能以保证音视频的质量,如启动带宽评估,当用户发送数据量太大超过评估的带宽时,要及时减少数据包的发送;启动防拥塞功能,当预测到要发生拥塞时,通过降低流量的方式防止拥塞的发生等等,这些都属于服务质量描述的范畴。
总结起来就是,SDP是由一个会话层与多个媒体层组成,每个媒体层又分为媒体流描述、网络描述、安全描述和服务质量描述,而每种描述下面又需要你参考草案来解析和理解。
总结:
这篇文章主要介绍了下SDP协议的内容、格式和规范,以及通过RTSP、SIP、WebRTC中三个例子分析了下SDP中各个字段和应用。平时学习时有这个整体框架就行,一些文中没出现的字段需要你查标准的RFC文档进行学习和理解。
同时在GB28181协议中,由于各个厂家对有些字段理解不规范,导致有歧义经常会出现连接摄像头失败,拉流失败等问题,需要在实践中解决和兼容。
往期文章回顾:
音视频解封装:MP4核心Box详解及H264&AAC打包方案