WebRTC中音频相关的netEQ
上篇文章(语音通信中终端上的时延(latency)及减小方法)说从本篇开始会切入webRTC中的netEQ主题,netEQ是webRTC中音频技术方面的两大核心技术之一(另一核心技术是音频的前后处理,包括AEC、ANS、AGC等,俗称3A算法)。webRTC是Google收购GIPS重新包装后开源出来的,目前已是有巨大影响力的实时音视频通信解决方案。国内的互联网公司,要做实时音视频通信产品,绝大多数都是基于webRTC来做的,有的是直接用webRTC的解决方案,有的是用webRTC里的核心技术,比如3A算法。不仅互联网公司,其他类型公司(比如通信公司),也会把webRTC里的精华用到自己的产品中。我刚开始做voice engine时,webRTC还未开源,但那时就知道了GIPS是一家做实时语音通信的顶级公司。webRTC开源后,一开始没机会用,后来做OTT语音(APP语音)时用了webRTC里的3A算法。在做了Android手机平台上的音频开发后,用了webRTC上的netEQ,不过用的是较早的C语言版本,不是C++版本,并且只涉及了netEQ中的DSP模块(netEQ有两大模块,MCU(micro control unit, 微控制单元)和DSP(digital signal processing,信号处理单元),MCU负责控制从网络收到的语音包在jitter buffer里的插入和提取,同时控制DSP模块用哪种算法处理解码后的PCM数据,DSP负责解码以及解码后的PCM信号处理,主要PCM信号处理算法有加速、减速、丢包补偿、融合等),MCU模块在CP (communication processor,通讯处理器)上做,两个模块之间通过消息交互。DSP模块经过调试,基本上掌握了机制。MCU模块由于在CP上做,没有source code,我就从网上找来了我们用的版本相对应的webRTC的开源版本,经过了一段时间的理解后,也基本上搞清楚了机制。从本篇开始,我将花几篇讲netEQ(基于我用的早期C语言版本)。这里需要说明的是每个产品在使用webRTC上的代码时都会根据自己产品的特点做一定的修改,我做的产品也不例外。我在讲时一些细节不会涉及,主要讲机制。本篇先对netEQ做一个概述。
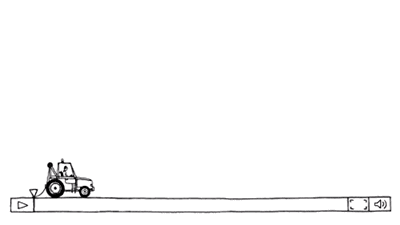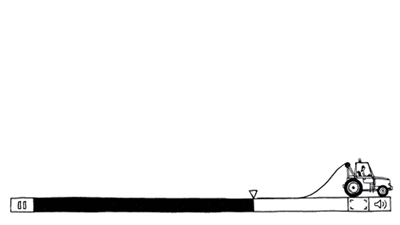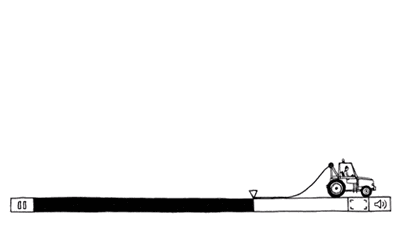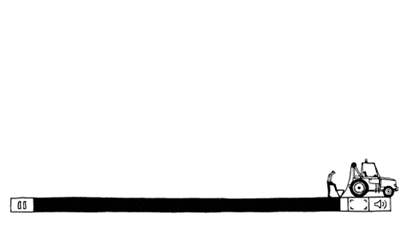
实时IP语音通信的软件架构框图通常如下图:
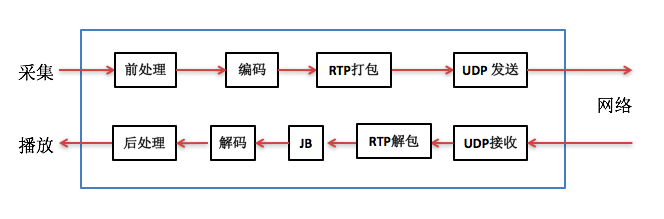
上图中发送方(或叫上行、TX)将从MIC采集到的语音数据先做前处理,然后编码得到码流,再用RTP打包通过UDP socket发送到网络中给对方。接收方(或叫下行、RX)通过UDP socket收语音包,解析RTP包后放入jitter buffer中,要播放时每隔一定时间从jitter buffer中取出包并解码得到PCM数据,做后处理后送给播放器播放出来。
netEQ模块在接收侧,它是把jitter buffer和decoder综合起来并加入解码后的PCM信号处理形成,即netEQ = jitter buffer + decoder + PCM信号处理。这样上图中的软件架构框图就变成下图:
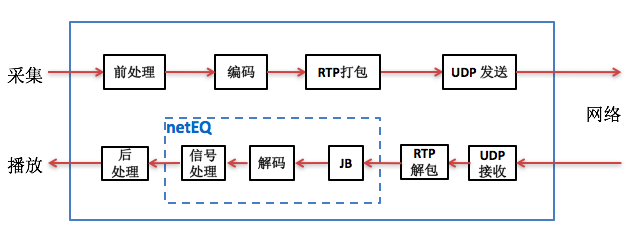
上文说过netEQ模块主要包括MCU和DSP两大单元。它的软件框图如下图:
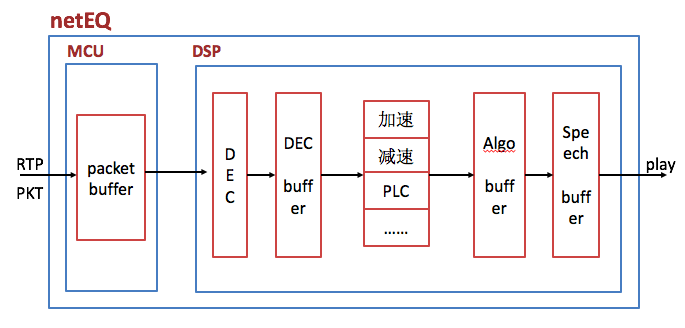
从上两图看出,jitter buffer(也就是packet buffer,后面就跟netEQ一致,表述成packet buffer,用于去除网络抖动)模块在MCU单元内,decoder和PCM信号处理模块在DSP单元内。MCU单元主要负责把从网络侧收到的语音包经过RTP解析后往packet buffer里插入(insert),以及从packet buffer 里提取(extract)语音包给DSP单元做解码、信号处理等,同时也算网络延时(opt BufLevel)和抖动缓冲延时(buffLevelFilt),根据网络延时和抖动缓冲延时以及其他因素(上一帧的处理方式等)决定给DSP单元发什么信号处理命令。主要的信号处理命令有5种,一是正常播放,即不需要做信号处理。二是加速播放,用于通话延时较大的情况,通过加速算法使语音信息不丢而减少语音时长,从而减少延时。三是减速播放,用于语音断续情况,通过减速算法使语音信息不丢而增加语音时长,从而减少语音断续。四是丢包补偿,用于丢包情况,通过丢包补偿算法把丢掉的语音补偿回来。五是融合(merge),用于前一帧丢包而当前包正常收到的情况,由于前一包丢失用丢包补偿算法补回了语音,与当前包之间需要做融合处理来平滑上一补偿的包和当前正常收到的语音包。以上几种信号处理提高了在恶劣网络环境下的语音质量,增强了用户体验。可以说是在目前公开的处理语音的网络丢包、延时和抖动的方案中是最佳的了。
DSP单元主要负责解码和PCM信号处理。从packet buffer提取出来的码流解码成PCM数据放进decoded_buffer中,然后根据MCU给出的命令做信号处理,处理结果放在algorithm_buffer中,最后将algorithm_buffer中的数据放进speech_buffer待取走播放。Speech_buffer中数据分两块,一块是已播放过的数据(playedOut),另一块是未播放的数据(sampleLeft), curPosition就是这两种数据的分割点。另外还有一个变量endTimestamps用于记录最后一个样本的时间戳,并报告给MCU,让MCU根据endTimestamps和packetbuffer里包的timestamp决定是否要能取出包以及是否要取出包。
这里先简要介绍一下netEQ的处理过程,后面文章中会详细讲。处理过程主要分两部分,一是把RTP语音包插入packet packet的过程,二是从packet buffer中提取语音包解码和PCM信号处理的过程。先看把RTP语音包插入packet packet的过程,主要有三步:
- 在收到第一个RTP语音包后初始化netEQ。
- 解析RTP语音包,将其插入到packet buffer中。在插入时根据收到包的顺序依次插入,到尾部后再从头上继续插入。这是一种简单的插入方法。 3.计算网络延时optBufLevel。
再看怎么提取语音包并解码和PCM信号处理,主要有六步:
- 将DSP模块的endTimeStamp赋给playedOutTS,和sampleLeft(语音缓冲区中未播放的样本数)一同传给MCU,告诉MCU当前DSP模块的播放状况。
- 看是否要从packet buffer里取出语音包,以及是否能取出语音包。取出包时用的是遍历整个packet buffer的方法,根据playedOutTS找到最小的大于等于playedOutTS的时间戳,记为availableTS,将其取出来。如果包丢了就取不到包。
- 算抖动缓冲延时buffLevelFilt。
- 根据网络延时抖动缓冲延时以及上一帧的处理方式等决定本次的MCU控制命令。
- 如果有从packet buffer里提取到包就解码,否则不解码。
- 根据MCU给的控制命令对解码后的以及语音缓冲区里的数据做信号处理。
在我个人看来,netEQ有两大核心技术点。一是计算当前网络延时和抖动缓冲延时的算法。要根据网络延时、抖动缓冲延时和其他因素决定信号处理命令,信号处理命令对了能提高音质,相反则会降低音质,所以说信号处理命令的决策非常关键。二是各种信号处理算法,主要有加速(accelerate)、减速(preemptive expand)、丢包补偿(PLC)、融合(merge)和背景噪声生成(BNG),这些都是非常专业的算法。
原文出处:WebRTC中音频相关的netEQ(二):数据结构
上篇(webRTC中音频相关的netEQ(一):概述)是netEQ的概述,知道了它主要是用于解决网络延时抖动丢包等问题提高语音质量的,也知道了它有两大单元MCU和DSP组成。MCU主要是把从网络收到的语音RTP包放进packet buffer内,同时也会根据计算出来的网络延时和抖动缓冲延时以及DSP单元反馈过来的信息决定给DSP发什么控制命令(命令主要有正常播放、加速、减速、丢包补偿、融合等),也会把语音包从packet buffer里取出来给DSP单元处理。DSP主要是对取出来的语音包解码并根据MCU给出的控制命令做信号处理。本篇我们继续讲netEQ,讲主要的数据结构。
要研究一个模块,首先得搞清楚它的数据结构。netEQ中最顶层的结构体是MainInst_t(也就是netEQ结构体),它主要包含两个成员变量,一个是DSPInst_t,另一个是MCUInst_t,正好对应netEQ的两个单元DSP和MCU。具体见图1(这里把次要的成员变量忽略掉了,下同)。在netEQ初始化时生成netEQ的实例,实例中包含DSP和MCU两个子实例。
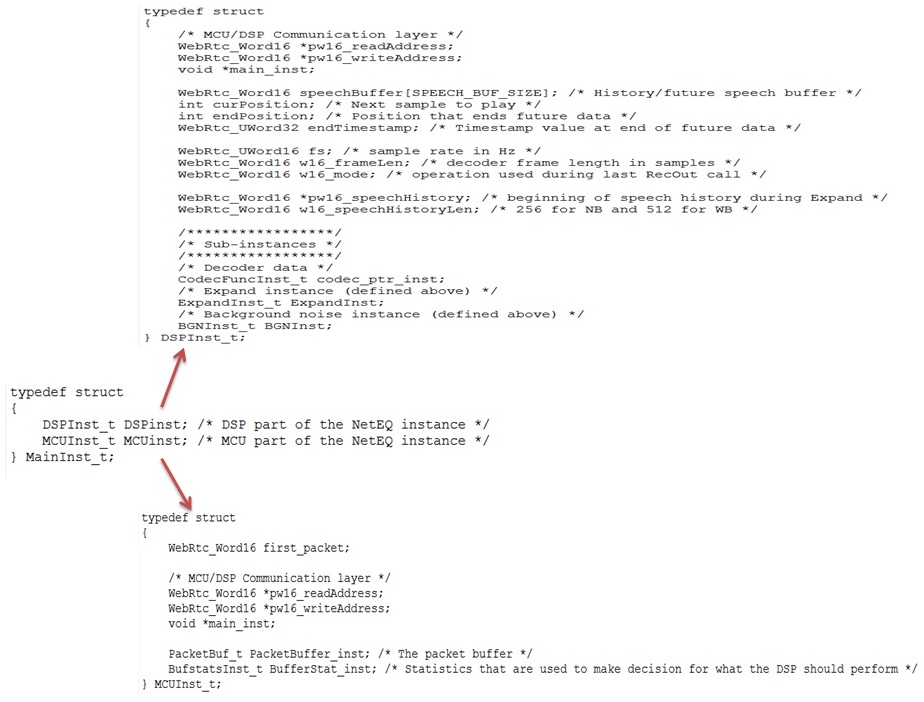
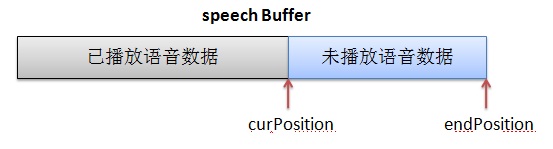
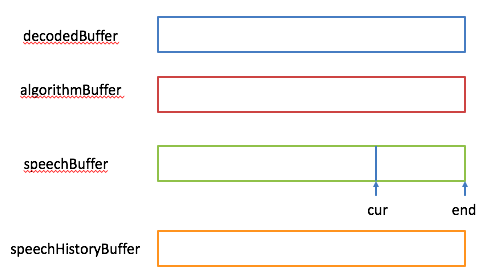
先看DSP结构体,见图1。pw16_readAddress和pw16_writeAddress用于与MCU交互数据。MCU中也有这两个成员变量,先说一下MCU和DSP是怎么交互的。MCU会给DSP发控制命令执行何种信号处理算法,就把命令相关的数据写在自己的pw16_writeAddress的地址上,让 DSP到这个地址上取数据,即DSP的pw16_readAddress就是MCU的pw16_writeAddress。DSP处理完一帧后会给MCU发反馈数据,反馈数据就写在自己的pw16_writeAddress地址上,MCU就从这个地址上去读反馈数据, 即MCU的pw16_readAddress就是DSP的pw16_writeAddress。main_inst指向父结构体netEQ(MainInst_t),这是一种常见的操作手法,便于找到父结构体实例。speechBuffer(语音buffer)用于存放经过解码和信号处理过的语音数据。它分两块,一块是已经播放过的语音数据,另一块是未播放过将要播放的语音数据,成员变量curPosition是分界点。另一成员变量endPosition表示语音buffer的大小,这依据采样率来定。可以用图2表示这三个成员变量的关系:
endTimestamp用于记录语音buffer中未播放的语音数据的最后的时间戳(MCU给DSP的控制命令中会带当前帧的时间戳,解码后通过换算就可以得到endTimestamp)。fs是采样率。w16_frameLen是每帧的采样点数。w16_mode是当前帧的处理方法(是加速处理还是减速处理等),这个值会带给MCU,MCU根据这和网络延时抖动缓冲延时等决定下一帧的处理命令。pw16_speechHistory和w16_speechHistoryLen用于丢包补偿(PLC,控制命令是EXPAND),pw16_speechHistory放最近播放过的历史语音数据,要做PLC时就以这些历史语音数据作为参考数据产生补偿的语音数据。w16_speechHistoryLen是放历史语音数据的buffer(即pw16_speechHistory)的长度,是个定值,依采样率而定。DSP结构体中还有几个子实例,主要有decoder实例(CodecFuncInst_t)、丢包补偿实例(ExpandInst_t)和背景噪声生成实例(BGNInst_t)。
上面说到MCU和DSP的数据交互,我们看一下交互的是什么数据。MCU发给DSP的是控制命令,控制命令数据占3个short大小,第一个short是命令相关的,第二三个是timestamp的高16位和低16位。DSP发给MCU的是反馈数据,反馈数据的结构体如图3:

playedOutTS表示语音buffer中最后数据的时间戳,等于DSP结构体中的endTimestamp。samplesLeft表示语音buffer总未播放的数据长度。lastMode表示上一帧的处理方法,等于DSP结构体中的w16_mode。frameLen表示上一帧解码后成长度。
再看MCU结构体,见图1。first_packet在初始化时置成1,后来收到包后置成0。用它主要是对收到第一个包后给MCU的一些成员变量(比如SSRC)赋值。pw16_readAddress和pw16_writeAddress用于与DSP交互数据,同DSP中的一样。main_inst也同DSP中的一样。MCU中也有两个主要的实例,一个是PacketBuffer_inst,它用于存放从网络收到的语音包。另一个是BufferStat_inst,它用于统计网络延时等。这两个均是非常重要的结构体。先说PacketBuffer_inst,它的定义如图4:

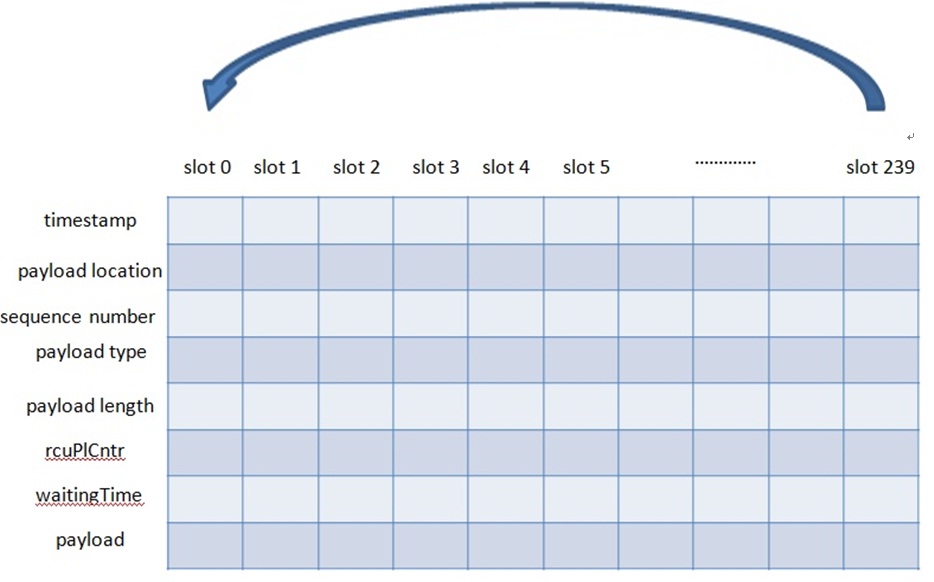
初始化时会分配一块可以存放最大个数(最大个数事先定义好了)语音包的buffer。存放的内容有timeStamp/payloadLocation(包的payload放的地址,指向payload)/seqNumber/payloadType/payloadLengthBytes/rcuPlCntr/waitingTime/payload等(见上图的红框内部分)。存放时并不是每个包的timestamp/payload等放在一起,而是所有包的timestamp放在一起,所有包的sequence number放在一起,其他也是,这样就得到了如下的buffer分布图5:

图5看起来不直观。netEQ中有slot的概念,每个包的timestamp/payload等放在同一个slot内,这样图5就可以表示成图6(图中每块buffer都是连续的,上一块buffer的尾部就是下一块buffer的首部,比如timestamp的尾部就是payload location的首部),这样看起来就直观多了。要获取某个包的属性或者payload,就可以通过slot_index得到。比如要获取第0个包的timestamp,就可以表示成timestamp[0]。怎样存放包搞清楚了就可以很好的理解这个结构体内的其他成员变量了。packSizeSamples表示上一解码的包有多少个采样点。startPayloadMemory表示放payload的起始地址。memorySizeW16表示分配的buffer还剩下的memory size。currentMemoryPos表示放下一个包的payload的起始地址,这个值会放在下一个包的对应的payloadLocation里。等下一个包来后,currentMemoryPos会加上这个包的payload长度重新赋给currentMemoryPos,并作为放下下个包的payload的起始地址。numPacketsInBuffer表示packet buffer里放了多少个包。insertPosition表示下一个包要放的位置。maxInsertPositions表示packetbuffer最大可放的包个数。discardedPackets表示主动丢弃的包个数。

再说BufferStat_inst,它的定义如图7:

w16_noExpand表示上一包的处理是不是EXPAND。avgDelayMsQ8表示平均缓冲延时。maxDelayMs表示最大缓冲延时。AutomodeInst_t是BufferStat_inst的子实例,,主要用于计算网络延时和抖动缓冲延时。它的定义如图8:

成员变量主要分三部分,一是iat(inter-arrival time,相邻包到的时间间隔)统计相关的, iat以包个数为单位,假设一个包20Ms,两个相邻包到的时间间隔是40Ms,iat就为2。有一个大小为65的数组来存放iat(iat从0到64)个数统计的值,基于这些值算网络延迟统计值。二是iat峰值统计相关的,用两个长度为8的数组来存放iat的峰值,一个用来存放峰值幅度,另一个用来存放峰值间隔。峰值间隔是automode结构体中另一个参数peakIatCountSamp,它用于统计当前探测到的峰值距离上次峰值的时间间隔,以采样点个数为单位。三是包相关的,有lastSeqNo(上一个收到包的sequence number)、lastTimeStamp(上一个收到包的timestamp)等。这些都是为了计算optBufLevel(网络延时)和buffLevelFilt(抖动缓冲延时)。MCU发给DSP的控制命令就是根据网络延时和抖动缓冲延时以及上一次的处理方式等得到的。需要注意的是这些变量中一些是以Q格式(Q格式相关的可以见我前面的文章Android手机上Audio DSP频率低 memory小的应对措施)表示的,算网络延时和抖动缓冲延时都是用Q格式算的,这加大了理解的难度。
原文出处:WebRTC中音频相关的netEQ(三):存取包和延时计算
上篇(webRTC中音频相关的netEQ(二):数据结构)讲了netEQ里主要的数据结构,为理解netEQ的机制打好了基础。本篇主要讲MCU中从网络上收到的RTP包是怎么放进packet buffer和从packet buffer里取出来,以及网络延时值(optBufLevel)和抖动缓冲延时值(buffLevelFilt)的计算。先看RTP语音包是怎么放进packet buffer的。
前面说过把从网络收到的RTP包放进packet buffer时有个slot概念,每个slot里放一个包的属性(比如timestamp、sequence number等)和payload。Packet buffer初始化时把numPacketsInBuffer(已有的包个数)和insertPosition(下一个包放的位置)置成0,也把属性和payload置成合理的值(比如把payloadLengthBytes(payload长度)置成0,把payloadType(负载类型)置成-1)。当一个RTP包要放进packet buffer时,先要看packetbuffer是否为空(即numPacketsInBuffer是否为零)。如为空,直接把包放在slot0的位置(把包的属性以及payload放到slot 0的位置上)。如不为空,insertPosition加1,先看这个slot上是否有包(标志是payloadLengthBytes是否为零,为零表示没包。当这个slot上的包被取走时payloadLengthBytes会被置为零)。如有包说明packet buffer 满了,需要reset(代码中叫flush)packet buffer,然后把当前包放在slot 0的位置(Packet buffer中能放的包个数是一个很大的值,通常不会放满)。如未满,则直接放在下一个slot上。下面举例说明。假设packet buffer最多可以放240个包,则slot范围是0--239,如下图。从网络上收到的第一个包会放在slot 0的位置,第二个包放在slot1的位置,以此类推,第240个包会放在slot239的位置。当一个包从packet buffer取出时,相应slot就又被初始化了。当第241个包来时就又放到slot0的位置。当包放进相应slot时要check这个slot里是否有包(标准是payloadLengthBytes是否为零),有包则说明packet buffer已满需要reset/flush,然后这个包放在slot0的位置。
接下来看怎么从pakcet buffer里取一个语音包,这要依赖于从DSP模块带来的timestamp值(记为timestamp_from_dsp)。遍历packet buffer里每个slot,如果这个slot上语音包的timestamp小于timestamp_from_dsp,并且slot上有payload,就可以认为这个包来的太迟应该主动discard掉,包括reset这个slot和packet buffer里包个数减一等。遍历完packet buffer后把离timestamp_from_dsp最近的语音包的timestamp(即语音包的timestamp减去timestamp_from_dsp的值最小)对应的slot作为将要取出来的slot,把语音包从这个slot取出来后同样要reset这个slot以及packet buffer里包个数减一等。
从上面的描述可以看出这种放包的方式是比较简单的,是按照语音包到netEQ的先后顺序依次放在buffer里,而且可能是乱序的(收到包时就有可能是乱序的)。这就要求在取包时要遍历buffer把离DSP模块带过来的timestamp最近的timestamp的包取出来,遍历要用for循环,这就增加了计算量。这跟我以前做的jitter buffer的设计是有很大区别的。那种思想是把乱序的包排好序后再放在buffer里,取包时就不需要遍历buffer,而是从头上依次向后取。具体怎么实现的可以看我前面的文章(音频传输之Jitter Buffer设计与实现)。
下面看怎么计算网络延时统计值(optBufLevel),这是难点之一。假设每包20Ms,理想情况下每隔20Ms从网咯上收到一个语音包。实际情况是网络有延时丢包抖动,导致并不是每隔20Ms收到一个包,而是有时几十甚至100多毫秒收不到一个包,有时20Ms内收到几个包。我们要算出网络延时的统计值,作为产生向DSP发出控制命令的依据之一。怎么算呢?netEQ用包到的时间间隔来算,它的意思是当前收到的包相对上一个收到的包的时间间隔,以包个数为单位。当每收到一个包时就把packetIatCountSamp(已采样点数为单位)清零,以后每取一帧数据播放就把packetIatCountSamp加上一帧的采样点数(以AMR-WB每帧20Ms为例,每帧有320个采样点。每取一帧,packetIatCountSamp就增加320),当下一个包到时,拿packetIatCountSamp除以320就可以 算出两个包之间的间隔了。
下面给出计算网络延时的算法:
- 计算当前包绝对到达间隔iat(以数据据包个数为单位),计算公式如下:
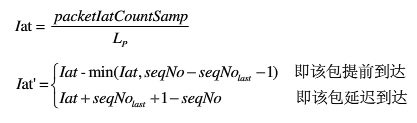
根据公式,提前到达的数据包的iat均为0,正常到达的iat为1,延迟一个包时间到达的Iat为2。Iat的最大值为64,即有65种(0--64)种可能。
- 更新iat在每个值(0--64)上的概率分布。初始化时每个值(0--64)上的概率均为0,随着包的到来,每个值上的概率都在动态的改变着。概率更新分以下几小步:
1) 用遗忘因子f对当前概率进行遗忘,计算公式如下:
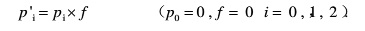
这里有个遗忘因子(forgetting factor)的概念。每个值上的概率均要算一下,得到新的概率。
2) 增大本次计算到的iat的概率,计算公式如下:
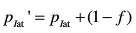
3) 更新遗忘因子f,使f为递增趋势,即通话时间越长,包间隔iat的概率分布越稳定。计算公式如下:
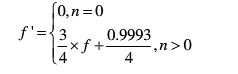
4) 调整本次计算到的iat的概率,使整个iat的概率分布之和近似为1。假设当前概率分布之和为tempSum,则计算公式如下:

统计满足95%概率的iat值,记为B。根据下式可以算出B的值。
统计iat的峰值
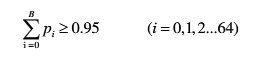
netEQ中采用两个长度为8的数组来统计iat的峰值,一个用来存峰值幅度,另一个用来存峰值间隔。峰值间隔是结构体automode中另一个参数peakIatCountSamp,用于统计当前探测到的峰值距离上次探测到的峰值的间隔,以样本个数为单位。当iat的值大于2B时就认为峰值出现了,把当前的iat和peakIatCountSamp值存在数组里。如果数组未满,就放在上一个峰值位置后的空的位置上;如果满了,就淘汰掉数组里最早的那个峰值,其他峰值左移,并把新的峰值放在数组里index为7的位置上。这里需要说明的是当两个数组的值不足8个时,峰值数组是不起作用的。
- 计算optBufLevel
当峰值数组起作用并且当前peakIatCountSamp小于等于峰值间隔数组中最大的间隔两倍时,optBufLevel取峰值数组中的最大值。否则optBufLevel 就为B。
以上是我照本宣科的把怎么算网络延时的算法表述出来。我基本理解了算法的思想,但是不清楚算法中的一些系数是怎么得到的。用google搜了一下,没找到相关的文档说明,这也是好多开源软件的通病,没有文档。我猜测是相关开发人员用数学建模的方法得到的系数值吧。如果有哪位朋友知道,麻烦给讲讲,先谢谢了。讲讲我对这个算法的理解吧。算网络延时是基于概率来算的,共有65个样本(0延时,一个包延时,2个包延时,…….,64个延时)。初始化时各个样本的概率(占的百分比)均为0。通话后某个延时值出现了它的概率值就要变大,相应的其他延时值的概率就要变小(已经为零的没办法再变小,依旧为零)。算法里先用遗忘因子去减小各个延时值的概率,然后再去变大本次延时值的概率,为了保证概率和为1要做一些微调(也会去更新遗忘因子)。然后从零延时开始把各个延时值的概率加起来,达到95%的值就可初步认为是延时值了。比如0延时概率为0.1, 1个包延时概率为0.7, 2个包延时概率为0.09,3个包延时概率为0.07,这时概率和为0.96,已达到0.95的线,取网络延时最大的值3,就可初步认为网络延时为3个包的延时。还要看当前网络状况,如果一段时间内频繁出现延时的峰值,说明当前网络环境比较糟糕,为了提高语音质量需要加大网络延时的值,就把峰值数组里的最大值,作为最终的网络延时值。
算网络延时是在语音包放进packet buffer后。算抖动缓冲延时是在收到DSP模块给MCU模块发反馈信息后(要用到反馈信息)以及从packet buffer取语音包前。下面给出计算步骤:
根据packet buffer里已有的语音包的个数算出已有的样本数,记为samples_in_packetbuffer,这依赖于采样率和包时长,以AMR-WB为例,采样率为16kHZ,包时长为20ms,可算出每包有320个样本。假设packet buffer里有5个语音包,则packet buffer里已有的样本数为1600 (1600 = 320*5)。
在speech buffer里未播放的(即sampleLeft)样本也要算在抖动缓冲延时内。它与packet buffer内的样本数相加就是实时的抖动缓冲延时(samples_jitter_delay,以样本个数为单位),即
samples_jitter_delay = samples_in_packet_buffer + samplesLeft,再除以每包样本数samples_per_packet,就可以得到实时抖动缓冲延时值(以包个数为单位)。计算bufferLevelFilt,公式如下:
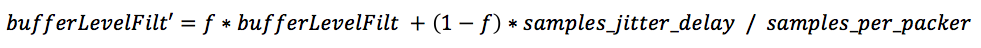
这里计算的是抖动缓冲延时的自适应平均值,f是计算均值的遗忘因子,根据网络状况自适应的变化,具体取值见下式:

其中B为前面算网络延时时的B值(以包个数为单位)。
- 如果经过加速或者减速播放,则需要去修正bufferLevelFilt,公式如下:
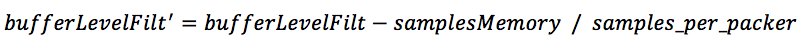
其中samplesMemory表示加速或减速播放后数据长度的伸缩变化,已样本个数为单位。若为加速,sampleMemory为正值,bufferLevelFilt减小;若为减速,sampleMemory为负值,bufferLevelFilt变大。
上面讲了MCU中网络延时和抖动缓冲延时的计算,MCU也收到了DSP模块发过来的反馈报告。后面MCU就要根据这些来决定给DSP模块发什么样的控制命令(加速/减速等),这是下一篇的主要内容。
原文出处:WebRTC中音频相关的netEQ(四):控制命令决策
上篇(webRTC中音频相关的netEQ(三):存取包和延时计算)讲了语音包的存取以及网络延时和抖动缓冲延时的计算,MCU也收到了DSP模块发来的反馈报告。本文讲MCU模块如何根据网络延时、抖动缓冲延时和反馈报告等决定发给DSP模块的控制命令, 好让DSP模块先对取出的语音包做解码处理(如果有的话)以及根据这些命令做信号处理。
MCU模块给DSP模块发的控制命令主要有正常播放(normal)、加速播放(accelerate)、减速播放(preemptive expand)、丢包补偿(PLC,代码中叫expand)、融合(merge),还有些次要的,如解码器重新初始化(decoder re-init)、packet buffer 重置(packet buffer reset)等。这里讲主要的控制命令是怎么决策的,次要的相对简单就略去不讲了,有兴趣的可以自己去看相关代码。DSP模块收到这些命令后会转化为自己的处理命令,下表列出了主要的控制命令和处理命令的映射关系。
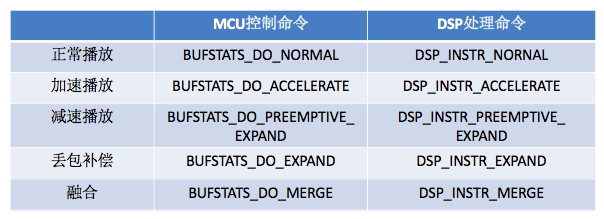
MCU模块给DSP模块发什么样的控制命令首先取决于当前帧和前一帧的接收情况。当前帧和前一帧的接收情况主要分以下四种(对当前帧和前一帧做排列组合得到四种情况):
- 当前帧和前一帧都接收正常,数据包会进入正常的解码流程。MCU模块会发正常播放、加速播放、减速播放三种控制命令中的一个给DSP,解码后的数据会根据命令做相应的处理。
- 当前帧接收正常,但前一帧丢失。如果前一帧丢失,但当前帧接收正常,说明前一帧是通过丢包补偿生成的。为了使前一帧由丢包补偿生成的数据和当前没有丢包的帧的数据保持语音连续,需要根据前后帧的相关性做平滑处理。这种情况下MCU模块会发正常播放、融合两种控制命令中的一个给DSP。DSP模块先对当前帧解码,然后解码后的数据会根据命令做相应的处理。
- 仅当前帧发生丢包或延迟,这时就不需要解码了。MCU模块会发丢包补偿命令给DSP,DSP模块会进入丢包补偿单元来生成补偿数据。
- 当前帧丢失或延迟,前一帧同样丢失或延迟。MCU模块会连续的发丢包补偿命令给DSP,DSP模块也会连续的进入丢包补偿单元来生成补偿数据。不过越到后面生成的补偿数据效果越差。
在上面的四种情况中,有些情况下MCU模块只会发一种命令给DSP模块,比如当前帧丢失,只会发丢包补偿控制命令给DSP。但有些情况下MCU模块可能会发几种命令中的一种给DSP模块,比如当前帧和前一帧都接收正常,MCU模块会发正常播放、加速播放、减速播放三种控制命令中的一个给DSP。到底发哪种命令呢,这就取决于网络延时、抖动缓冲延时以及DSP发给MCU的反馈报告等因素了。这是本文的重点,下面具体讲。
在DSP发给MCU的反馈报告中有个变量playedOutTS,它表示已经播放到的PCM数据的时间戳。同时MCU中还有个变量availableTS,它表示packet buffer中能获得的有效包的起始时间戳,显然如果availableTS等于0表示packet buffer为空。如果playedOutTS等于availableTS,它说明语音包正常接收;如果playedOutTS小于availableTS,它说明有语音包的丢失或者延时,需要做丢包补偿(PLC)。上篇文章(webRTC中音频相关的netEQ(三):存取包和延时计算)中讲了网络延时值(optBufLevel)和抖动缓冲延时值(buffLevelFilt)的计算,MCU就是要根据时间戳(playedOutTS & availableTS)的关系和延时(optBufLevel & buffLevelFilt)的关系以及上一帧的播放模式等来决定发什么样的控制命令给DSP。先举个简单的例子,如果playedOutTS = availableTS并且buffLevelFilt > optBufLevel,这说明当前包正常接收,但是抖动缓冲延时大于网络延时,即缓冲的包多了增加了时延,需要做加速播放处理,所以MCU会发加速处理命令给DSP。下面给出各个控制命令的条件,即满足所列条件时MCU就会发相应的控制命令给DSP。
1,正常播放控制命令 / 加速播放控制命令 / 减速播放控制命令的条件
正常播放控制命令为BUFSTATS_DO_NORMAL。加速播放控制命令为BUFSTATS_DO_ACCELERATE,加速播放的原因是要播放的数据正常到达,但是抖动缓冲延时大于网络延时,增加了时延,因此要加速播放。减速播放控制命令为BUFSTATS_DO_PREEMPTIVE_EXPAND,又称为优先扩展控制命令。减速播放的原因是要播放的数据正常到达,但是抖动缓冲延时小于网络延时,会引起播放时声音的断续,降低音质,因此要减速播放,拉长时间,使不会出现断续。这三种控制命令都有一个必要条件,那就是playedOutTS = availableTS, 所以把这三种控制命令放在一起讲。在"playedOutTS = availableTS"条件下,只有三种控制命令可供选择,要么正常播放,要么加速播放,要么减速播放。把加速播放和减速播放的条件搞清楚了,剩下的就是正常播放条件了。下图更直观的说明了正常播放、加速播放和减速播放的关系,去掉加速和减速的就是正常播放的了。
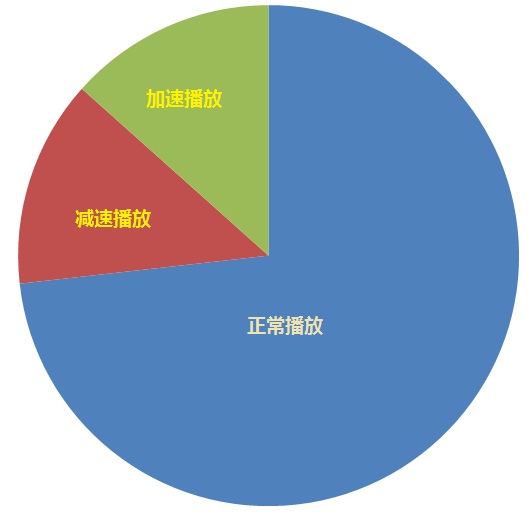
先看加速播放的条件。它的第二个条件是上一帧播放模式不为丢包补偿(第一个条件为playedOutTS = availableTS),第三个条件是下列两个之一:
1) 加速播放第三个条件之一
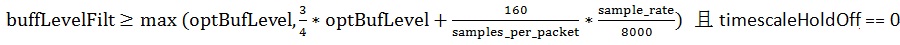
其中sample_rate为采样率,如8000/16000。samples_per_packet为每个包的采样点数,以16KHZ/每包20ms为例,samples_per_packet就为320。 timescaleHoldOff初始化为32,且每发生一次加速或减速播放就右移一位。此参数是为了防止连续的加速或减速播放恶化人耳的听觉感受。
2)加速播放第三个条件之二
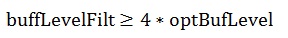
再看减速播放的条件。它的第一个条件与第二个条件与加速播放一样,第三个条件如下:
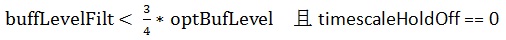
说实话我没有完全理解上面三个加减速的数学表达式的判据,尤其是系数值的选取。我知道不能简单的认为"buffLevelFilt > optBufLevel"就加速"buffLevelFilt < optBufLevel"就减速,要真的这么判断的话效果肯定是不好的。如果哪位朋友理解了,麻烦给讲讲,先谢谢了!
除加减速播放这些条件外,剩下的就是正常播放了。可以写成如下的伪代码:
If(playedOutTS == availableTS)
{
If(上一帧播放模式不为丢包补偿)
{
If(加速播放第三个条件是下列之一 || 加速播放第三个条件是下列之二)
return 加速播放;
If(减速播放第三个条件)
return 减速播放;
}
return 正常播放;
}
2,丢包隐藏控制命令的条件
丢包隐藏控制命令为BUFSTATS_DO_EXPAND,又称为扩展控制命令。丢包隐藏的原因是要播放的包已丢失或者还没到(延时)。发生丢包隐藏的场景有:
- availableTS = 0,即packet buffer为空,显然这时需要做丢包补偿。
- playedOutTS < availableTS,即要播放的包丢失或者延时到,但是packet buffer里有缓冲包,需要满足下面两个条件之一即可:
- 上一帧播放模式不为丢包补偿
- 上一帧播放模式为丢包补偿,且前面几帧均为丢包补偿,这是连续丢包的场景,这时要看连续丢包补偿的次数。netEQ设定最多可以补偿100ms的数据,以每包20ms为例,最多可以补偿5个包,其实100ms后的补偿效果也不好了。所以连续丢包补偿的次数小于5的话,还会继续丢包补偿,否则就不做丢包补偿了。
3,融合控制命令的条件
融合控制命令为BUFSTATS_DO_MERGE,主要用于丢包隐藏后产生的PCM数据与从packet buffer里取出的数据的衔接过程。所以产生融合控制命令的条件是:
1)playedOutTS < availableTS (此式也表示packet buffer不为空,为空时availableTS = 0)
2)上一帧的处理模式为丢包补偿
以上就是主要的控制命令的条件。可能不同版本之间可能有差异,我是根据我用的版本来讲的。就像上面我说的,有些我也没有完全理解,只是把它照本宣科的讲出来。苦于没有文档呀,网上也没有相关的论述,目前只能先这样了,后面如果完全理解了再补充。
原文出处:WebRTC中音频相关的netEQ(五):DSP处理
上篇(webRTC中音频相关的netEQ(四):控制命令决策)讲了MCU模块是怎么根据网络延时、抖动缓冲延时和反馈报告等来决定给DSP模块发什么控制命令的。DSP模块根据收到的命令进行相关处理,处理简要流程图如下。
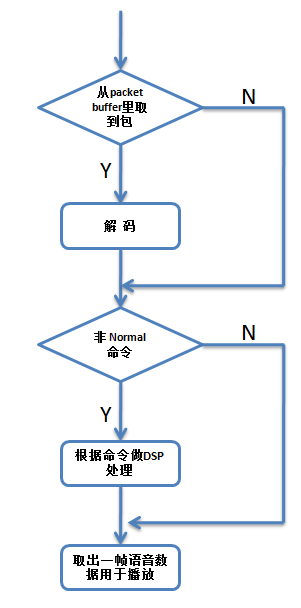
从上图看出如果有语音包从packet buffer里取出来先要做解码得到PCM数据,没有就不用做解码了。编解码也是数字信号处理算法的一种,是个相当大的topic,不是本文所关注的,本文关注的是对解码后的PCM数据做数字信号处理,如加减速。如果命令是非Normal命令,就要根据命令做DSP处理,是Normal命令就不用做了。最后取出一帧数据用于播放。
MCU发给DSP的主要的控制命令有正常播放(normal)、加速播放(accelerate)、减速播放(preemptive expand)、丢包补偿(PLC,代码中叫expand)、融合(merge)等。正常播放就是不需要做额外的DSP处理。加减速也就是改变语音时长,即在不改变语音的音调并保证良好音质的情况下使语音在时间轴上压缩或者拉伸,或者叫变速不变调。语音时长调整算法可分为时域调整和频域调整,时域调整以重叠区波形相似性(WSOLA)算法为代表,通常用在语音通信中。频域调整通常音乐数据中。丢包补偿就是基于先前的语音数据生成当前丢掉的语音数据。融合处理发生在上一播放的帧与当前解码的帧不是连续的情况下,需要来衔接和平滑一下。这些都是非常专业的算法,本文不会涉及,本文是讲工程上的一些实现,主要是buffer的处理。
在讲这些处理之前先看netEQ里相关的几块buffer,分别是decodedBuffer(用于放解码后的语音数据)、algorithmBuffer(用于放DSP算法处理后的语音数据)、speechBuffer(用于放将要播放的语音数据,这个在前面的文章(webRTC中音频相关的netEQ(二):数据结构)中讲过)和speechHistoryBuffer(用于放丢包补偿的历史语音数据,即靠这些数据来产生补偿的语音数据)。
先看加速处理。它主要用于加速播放,是抖动延迟过大时在不丢包的情况下尽量减少抖动延迟的关键措施。它的处理流程如下:
1,看decodedBuffer里是否有30Ms的语音数据(语音数据量要大于等于30Ms才能做加速处理),如果没有就需要向speechBuffer里未播放的语音数据借,使满足大于等于30Ms的条件。下图示意了借的步骤:
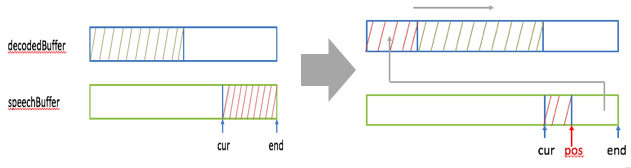
先算出decodedBuffer里缺的样本数(记为nsamples, 等于30Ms的样本数减去buffer里已有的样本数),即需要向speechBuffer借的样本数。然后在decodedBuffer里将已有的样本数右移nsamples,同时从speechBuffer里end处开始取出nsamples个样本,将其放在decodedBuffer里开始处空出来的地方。
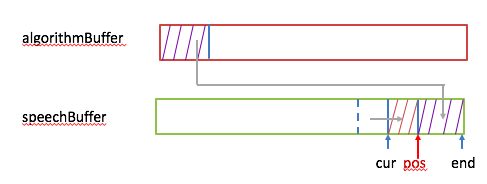
2,做加速算法处理,输入是decodedBuffer里的30Ms语音数据,输出放在algorithmBuffer里。如果压缩后的样本数小于向speechBuffer借的样本个数nsamples(假设小msamples),不仅要把这些压缩后的样本拷进speechBuffer里(从end位置处向前放),同时还要把从cur到pos处的样本数向后移msamples,cur指针也向后移msamples个数。下图给出了示意:
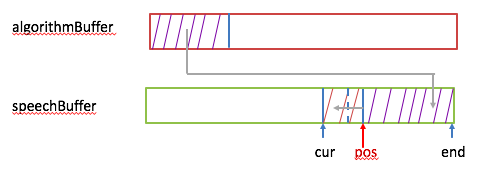
如果压缩后的样本数大于向speechBuffer借的样本个数(假设大qsamples),先要把从cur到pos处的样本数向前移qsamples(cur和pos指针都要向前移qsamples个数),然后把这些压缩后的样本拷进speechBuffer里(从pos位置处向后放)。下图给出了示意:
3,从speechBuffer里取出一帧语音数据播放,同时把cur指针向后移一帧的位置。
减速处理的流程跟加速是类似的, 这里就不详细讲了。下面开始讲丢包补偿,它的处理流程如下:
1,基于speechHistoryBuffer利用丢包补偿算法生成补偿的语音数据(记样本数为nsamples)放在algorithmBuffer里,同时还要更新speechHistoryBuffer里的数据为下次做丢包补偿做准备。示意图如下:
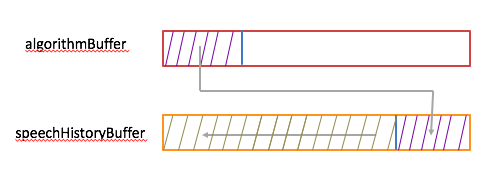
先把speechHistoryBuffer里的数据左移nsamples,然后把algorithmBuffer里的nsamples个样本放在speechHistoryBuffer的尾部。
2,把algorithmBuffer里生成的数据放到speechBuffer里。示意图如下:
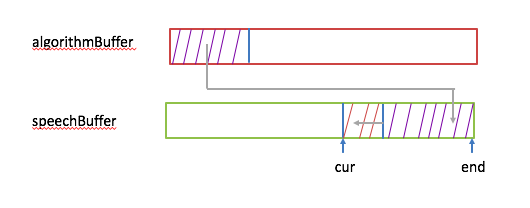
先将speechBuffer里的数据左移nsamples,然后把algorithmBuffer里的nsamples个样本放在speechBuffer的尾部,同时cur指针也要左移nsamples。
3,从speechBuffer里取出一帧语音数据播放,同时把cur指针向后移一帧的位置。
至于merge中buffer的处理,相对简单,这里就不讲了。至此我觉得netEQ的主要核心点都讲完了,共5篇,算一个系列吧。理解了这些核心点后要想对netEQ有更深的认识就得去实际的调试了,把一些细节搞得更清楚。netEQ里面的细节特别多,要想全部搞清楚是要花不少时间的。要是全部搞清楚了对语音接收侧处理的认识会有一个质的提升。