WebRTC拥塞控制02
本文是
WebRTC 拥塞控制第 4 篇
- 导读
- 指数移动均值、方差、标准差、归一化
- AIMD 码率控制概述
- 状态切换
- 控制算法
- 源码分析
- Update 函数
- ChangeBitrate 函数
- ChangeState 函数
- AdditiveRateIncrease 函数
- GetNearMaxIncreaseRateBps 函数
- MultiplicativeRateIncrease 函数
- UpdateMaxThroughputEstimate 函数
- 再谈 ChangeBitrate 函数
- 测试用例
导读
上一篇介绍了网络带宽的检测过程以及在该过程中产生的三种信号:overuse、normal、underuse。
本篇将介绍这三种信号如何驱动码率控制器工作,这个过程涉及到:三种码率控制状态(increase、decrease、hold)的切换、增加码率的算法(加性增大与乘性增大)、减少码率的算法(指数回退,即乘性减小)、最大码率方差的计算。
指数移动均值、方差、标准差、归一化
在介绍 WebRTC 码率控制算法之前,先来了解几个与统计学相关的概念。
- 方差(Variance)
统计中的方差是每个样本值与样本均值之差的平方值的平均数。
- 标准差(Standard Deviation)
标准差是方差的算术平方根,反映一个数据集的离散程度。
- 归一化(Normalize)
把数据经过处理后使之限定在一定的范围内。
- 指数平滑移动均值 (Exponential Moving Average)
EMA 是以指数式递减加权的移动平均,它是一种趋向类指标,其原理是一阶滞后滤波法。EMA 可以降低周期的性干扰,在波动频率较高的场景中有很好的效果。
在 WebRTC 拥塞控制 | Trendline 滤波器[1] 一文中,较为详细的介绍了指数平滑法,可移步阅读。
AIMD 码率控制概述
AIMD 是 TCP 拥塞控制中码率调节的概念。在 计算机网络[2] 一书中,对 AIMD 算法做了如下描述:
在拥塞避免阶段,拥塞窗口是按照线性规律增大的,这常称为加法增大 AI(Additive Increase)。而一旦出现超时或 3 个重复的确认,就要把门限值设置为当前拥塞窗口值的一半,并大大减小拥塞窗口的数值。这常称为乘法减小 MD(Multiplicative Decrease)。二者合在一起就是所谓的 AIMD 算法。
状态切换
GCC 草案[3] 定义了三种码率控制状态:
The rate control subsystem has 3 states: Increase, Decrease and Hold. "Increase" is the state when no congestion is detected; "Decrease" is the state where congestion is detected, and "Hold" is a state that waits until built-up queues have drained before going to "increase" state.
三种状态在 WebRTC 中表示如下:
enum RateControlState {
kRcHold, kRcIncrease, kRcDecrease
};
码率控制状态之间的切换,如下图所示:
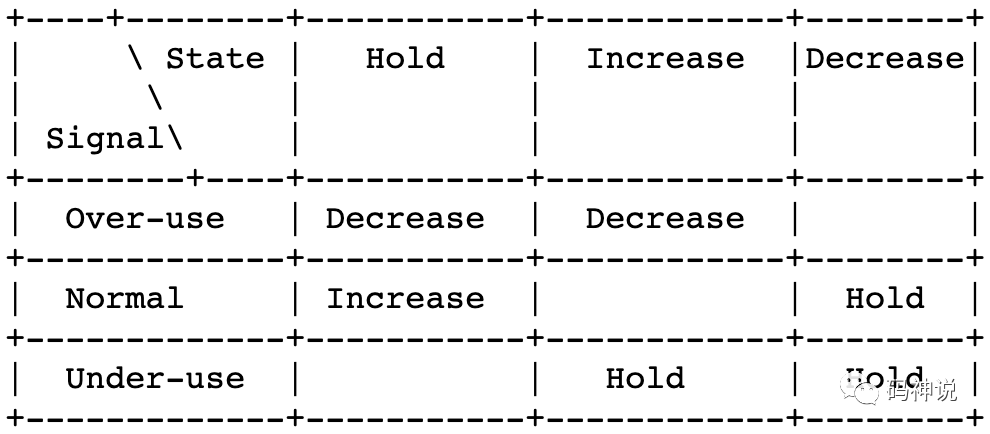
- 收到 overuse 信号,码率控制器总是进入 decrease 状态。
- 收到 underuse 信号,码率控制器总是进入 hold 状态。
- 收到 normal 信号,码率控制器提升当前状态。
- 当前在 hold 状态,提升到 increase 状态。
- 当前在 decrease 状态,提升到 hold 状态。
关于码率控制状态切换,有两点个人理解:
- 收到过载信号,将码率降低,这很好理解,但是收到低载信号,为何进入码率保持状态?
我的理解是,收到 underuse 信号,说明网络上传输的流量很少,网络链路容量完全可以承载当前发送码率,不需要做任何改变,保持该码率即可。
- 收到正常信号,hold 状态提升到 increase 状态很好理解,但是 decrease 状态为何要提升到 hold 状态?
我的理解是,在网络正常的情况下,原来的码率处于 decrease 状态,说明码率已经降低到适应当前网络状况了,所以转向 hold 状态。
控制算法
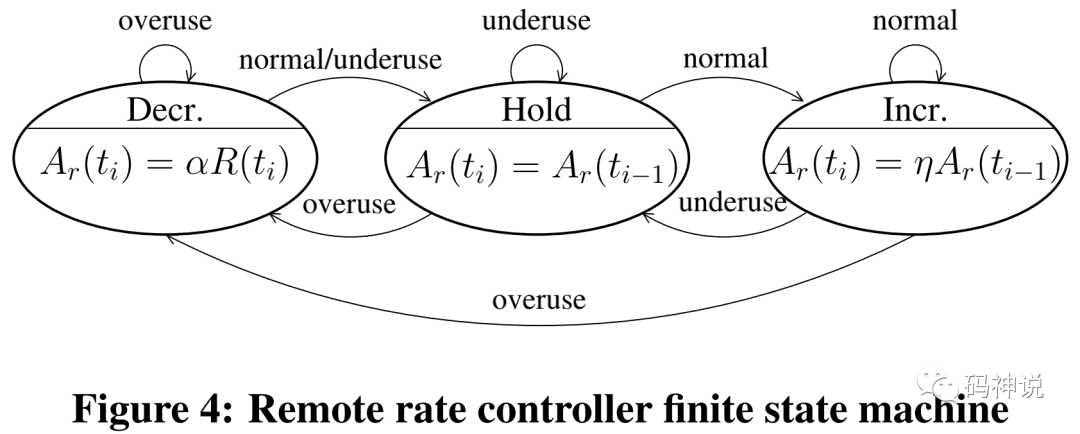
WebRTC 借鉴 AIMD 这种码率调节思想,设计了一套自己的算法:
注意,上面的码率调节算法最初用于 Receive-side BWE,在 WebRTC 最新的 Send-side BWE 中复用了该算法。
结合三种码率状态之间的切换与调节算法,下面的图应该不难理解,具体的码率调节过程下文会详细介绍。
源码分析
基于 WebRTC M71 版本
码率控制在 AimdRateControl 类中实现,该类的重要的成员函数如下:
class AimdRateControl {
public:
uint32_t Update(
const RateControlInput* input,
int64_t now_ms);
int GetNearMaxIncreaseRateBps() const;
private:
void ChangeState(
const RateControlInput& input,
int64_t now_ms);
uint32_t ChangeBitrate(
uint32_t current_bitrate,
const RateControlInput& input,
int64_t now_ms);
uint32_t MultiplicativeRateIncrease(
int64_t now_ms,
int64_t last_ms,
uint32_t current_bitrate_bps) const;
uint32_t AdditiveRateIncrease(
int64_t now_ms,
int64_t last_ms) const;
void UpdateMaxThroughputEstimate(
float estimated_throughput_kbps);
};
Update 函数
该函数为驱动 AimdRateControl 工作的外部接口函数,其内部调用私有成员函数 ChangeBitrate。
ChangeBitrate 函数
该函数为整个码率控制算法的核心实现函数,主要流程包括:
- 根据输入的带宽检测信号,更新码率控制状态,在
ChangeState函数中实现。 - 根据新的码率控制状态和最大码率的标准差,进行相应的码率控制,计算新的码率。
- 如果码率控制状态为 hold,码率保持不变。
- 如果码率控制状态为 increase,根据当前码率是否接近网络链路容量对其进行 加性增大 或者 乘性增大。
- 如果码率控制状态为 decrease,对码率进行 乘性减小,并更新当前网络链路容量估计值的方差,即最大码率的方差。
- 控制新的码率值在一定范围内。
当码率控制算法计算出的新的码率值过大,超过发送端的发送能力,则需要将新的码率值限制到一定区间内,这也避免了发送端码率增长过快。
关于 2 中详细的码率控制过程,在源码分析的最后会继续介绍。
ChangeState 函数
该函数输入带宽检测信号,从而对码率控制状态进行切换。
switch (input.bw_state) {
case BandwidthUsage::kBwNormal:
if (rate_control_state_ == kRcHold) {
rate_control_state_ = kRcIncrease;
}
break;
case BandwidthUsage::kBwOverusing:
if (rate_control_state_ != kRcDecrease) {
rate_control_state_ = kRcDecrease;
}
break;
case BandwidthUsage::kBwUnderusing:
rate_control_state_ = kRcHold;
break;
}
关于状态切换,有一点 WebRTC 源码并未体现:当收到 normal 信号时,如果当前状态是 decrease,应该提升到 hold 状态。
除此之外,码率控制状态的切换过程与上文描述的一致。
AdditiveRateIncrease 函数
该函数执行加性增大算法,输入当前时间和上次码率被更新的时间,返回增加的码率大小。
return static_cast<uint32_t>(
(now_ms - last_ms) *
GetNearMaxIncreaseRateBps() / 1000);
根据源码可知:加性增大的码率大小 = 距上次码率更新所经历的时间(秒) * 每秒应该增加的码率大小。所以,真正的加性增大算法在GetNearMaxIncreaseRateBps 函数中实现。
注意,GetNearMaxIncreaseRateBps 函数名告诉我们,在码率接近网络链路容量时,进行加性增大。
GetNearMaxIncreaseRateBps 函数
该函数会计算在当前码率下执行加性增大算法后增加的码率值。
计算当前码率下每帧的大小,假设帧率为 30fps。
double bits_per_frame =
static_cast<double>(current_bitrate_bps_) / 30.0;
计算每帧的包数,假设每包大小为 1200B。
double packets_per_frame =
std::ceil(bits_per_frame / (8.0 * 1200.0));
注意,每帧的包数向上取整,至少为 1,也就是说,如果每帧大小小于单个包大小 1200 bytes,也会认为每帧含有一个包。
计算当前码率下每个包实际的大小。
double avg_packet_size_bits =
bits_per_frame / packets_per_frame;
计算 response_time,其大小为 rtt 加上 100 ms 的发送端 BWE 延迟,rtt 默认值为 200ms。
const int64_t response_time = in_experiment_ ?
(rtt_ + 100) * 2 : rtt_ + 100;
加性增大的原则应该是:每一个 response_time 增加一个包的大小。
那么,每秒包含 (1000 / response_time) 个 response_time interval,则每秒应该增加 (1000 / response_time)个包的大小,于是,加性增大的码率值就计算出来了。
constexpr double kMinIncreaseRateBps = 4000;
return static_cast<int>(std::max(
kMinIncreaseRateBps,
(avg_packet_size_bits * 1000) / response_time));
有两点需要注意:
- 加性增大的码率值至少为 4Kbps,比如在低码率场景下,加性增大的码率值可能小于 4Kbps。
- GCC 草案规定每一个 response_time interval,码率增加至多半个包的大小,而非 WebRTC 源码中一个包的大小。
MultiplicativeRateIncrease 函数
该函数执行乘性增大算法,输入当前时间和上次码率被更新的时间,返回增加的码率大小。
double alpha = 1.08;
if (last_ms > -1) {
auto time_since_last_update_ms =
rtc::SafeMin<int64_t>(now_ms - last_ms, 1000);
alpha = pow(alpha, time_since_last_update_ms / 1000.0);
}
uint32_t multiplicative_increase_bps =
std::max(current_bitrate_bps * (alpha - 1.0), 1000.0);
将距上次码率更新所经过的时间作为指数,计算增长系数 alpha。alpha 初值取 1.08,最大值也为 1.08,也就是说,乘性增大的码率值最大不会超过当前码率的 8%。
UpdateMaxThroughputEstimate 函数
该函数输入网络带宽过载状态下的码率估计值 estimated_throughput_kbps,计算网络链路容量的方差。
注意,该函数只有在收到过载信号降低码率时才会被调用,这是因为:一旦检测到过载并准备降低码率时,说明当前网络链路已经达到了最大吞吐量(带宽),此时的码率估计值才能代表网络链路容量 ,从而作为样本并计算其方差。
可以认为,网络链路容量 link capacity 代表了网络吞吐量 throughput,也即带宽 bandwidth。
也可以认为,过载状态下的码率估计值 estimated_throughput_kbps 即为最大码率,计算网络链路容量的方差就是计算最大码率的方差。
- 一次指数平滑法计算最大码率的指数移动均值
estimated_throughput_kbps 为接近 link capacity 的最大码率估计值,即样本值。
avg_max_bitrate_kbps_ 为最大码率的估计值 estimated_throughput_kbps 的均值,即样本均值。
const float alpha = 0.05f;
avg_max_bitrate_kbps_ =
(1 - alpha) * avg_max_bitrate_kbps_ +
alpha *estimated_throughput_kbps;
- 一次指数平滑法计算最大码率的方差
这里求最大码率的方差并不是进行简单平均,而是也采用了指数移动平均求取方差,并使用最大码率均值对方差进行归一化。
const float norm =
std::max(avg_max_bitrate_kbps_, 1.0f);
var_max_bitrate_kbps_ =
(1 - alpha) * var_max_bitrate_kbps_ +
alpha *
(avg_max_bitrate_kbps_ -
estimated_throughput_kbps) *
(avg_max_bitrate_kbps_ -
estimated_throughput_kbps) / norm;
对于求取最大码率均值与方差时的指数平滑系数,GCC 草案的建议值为 0.95。
- 将归一化后的方差控制到 [0.4, 2.5] 区间范围之内。
// 0.4 ~= 14 kbit/s at 500 kbit/s
if (var_max_bitrate_kbps_ < 0.4f) {
var_max_bitrate_kbps_ = 0.4f;
}
// 2.5f ~= 35 kbit/s at 500 kbit/s
if (var_max_bitrate_kbps_ > 2.5f) {
var_max_bitrate_kbps_ = 2.5f;
}
再谈 ChangeBitrate 函数
在了解了码率控制状态如何切换、加性增大与乘性增大算法以及如何计算最大码率方差之后,我们再来看一下码率增加或者减少的详细过程。
- 计算最大码率标准差
UpdateMaxThroughputEstimate 函数计算出了最大码率的方差,只需要对其开根号,就可以得到标准差。
const float std_max_bit_rate =
sqrt(var_max_bitrate_kbps_ *
avg_max_bitrate_kbps_);
注意,因为这个方差使用了最大码率均值进行归一化,所以开根号之前要乘以最大码率均值,还原真正的方差值。
最大码率标准差表征了链路容量 link capacity 的估计值相对于均值的波动程度。
- 增加码率
关于码率增加是选择加性增大还是乘性增大,GCC 草案规定如下:
The system does a multiplicative increase if the current bandwidth estimate appears to be far from convergence, while it does an additive increase if it appears to be closer to convergence. "Close" is defined as three standard deviations around this average.
如果 rate_control_region_ == kRcNearMax,即当前码率接近 link capacity,此时增长需放慢,选择加性增大。
如果 rate_control_region_ == kRcMaxUnknown,即当前码率远未达到 link capacity,此时可放手增大,选择乘性增大。
rate_control_region_ 初始化为 kRcMaxUnknown,也就是说,WebRTC码率控制模块以增加码率(乘性增大)的状态启动。
case kRcIncrease:
if (avg_max_bitrate_kbps_ >= 0 &&
estimated_throughput_kbps >
avg_max_bitrate_kbps_ +
3 * std_max_bit_rate)
{
rate_control_region_ = kRcMaxUnknown;
avg_max_bitrate_kbps_ = -1.0;
}
if (rate_control_region_ == kRcNearMax)
{
uint32_t additive_increase_bps =
AdditiveRateIncrease(now_ms,
time_last_bitrate_change_);
new_bitrate_bps +=
additive_increase_bps;
} else
{
uint32_t multiplicative_increase_bps =
MultiplicativeRateIncrease(now_ms,
time_last_bitrate_change_,
new_bitrate_bps);
new_bitrate_bps +=
multiplicative_increase_bps;
}
time_last_bitrate_change_ = now_ms;
break;
如果当前网络吞吐量的评估值与最大码率均值的差大于最大码率标准差的 3 倍。认为最大码率均值不可靠,丢弃之前的码率评估数据,复位并重新计算。
同时,认为当前的 link capacity 是未知的,设置 rate_control_region_ 为 kRcMaxUnknown,乘性增大码率以探索 link capacity,即最大码率。
- 降低码率
根据公式 1,码率的降低以接收端反馈后的码率估计值 estimated_throughput_bps 为基准,而非当前码率,回退系数为 0.85。
如果回退后的码率大于当前发送码率(当 estimated_throughput_bps 出现较大波动时可能会出现这种情况),则以最大码率均值avg_max_bitrate_kbps_ 为基准进行回退。
总之,码率降低的原则是:降低后的新的码率必须保证小于等于当前的发送码率。
码率降低后将 rate_control_region_ 设置为 kRcNearMax,说明此时码率已经接近 link capacity,之后如果收到normal 信号需要增大码率,只能选择加性增大。
new_bitrate_bps =
static_cast<uint32_t>(beta_ *
estimated_throughput_bps + 0.5);
if (new_bitrate_bps > current_bitrate_bps_)
{
if (rate_control_region_ != kRcMaxUnknown)
{
new_bitrate_bps =
static_cast<uint32_t>(beta_ *
avg_max_bitrate_kbps_ * 1000 + 0.5f);
}
new_bitrate_bps = std::min(
new_bitrate_bps,
current_bitrate_bps_);
}
rate_control_region_ = kRcNearMax;
下面要判断网络是否发生退化:即降低后的码率值是否小于当前码率与回退系数以及网络退化系数的乘积。其中,回退系数依然为 0.85,网络退化系数为 0.9。
如果码率降低的过多,那么这次降低的值 last_decrease_ 将视为无效,不会用于 BWE 周期的计算。
constexpr float kDegradationFactor = 0.9f;
if (smoothing_experiment_ &&
new_bitrate_bps <
kDegradationFactor * beta_ *
current_bitrate_bps_) {
last_decrease_ = absl::nullopt;
} else {
last_decrease_ =
current_bitrate_bps_ - new_bitrate_bps;
}
接下来,判断本次最大码率评估值(样本值)相对于最大码率均值(样本均值)的离散程度是否在合理范围内。
如果差值小于 3 个标准差,认为最大码率均值不可靠,复位。
if (estimated_throughput_kbps <
avg_max_bitrate_kbps_ -
3 * std_max_bit_rate) {
avg_max_bitrate_kbps_ = -1.0f;
}
接下来,更新最大码率均值与方差,将码率控制状态设置为 hold,直到网络链路缓冲区队列清空。
如果码率降低后,网络依然拥塞,那么会继续触发 overuse 信号降低码率。
UpdateMaxThroughputEstimate(
estimated_throughput_kbps);
// Stay on hold until the pipes are cleared.
rate_control_state_ = kRcHold;
break;
最后,将新的码率控制到区间 [minconfigured_bitrate_bps, 1.5f * estimated_throughput_bps + 10000] 之内。
最大限制码率是 estimated_throughput_bps 的线性函数,限制码率的原因上文已经做过解释,不再赘述。
测试用例
- 测试 1
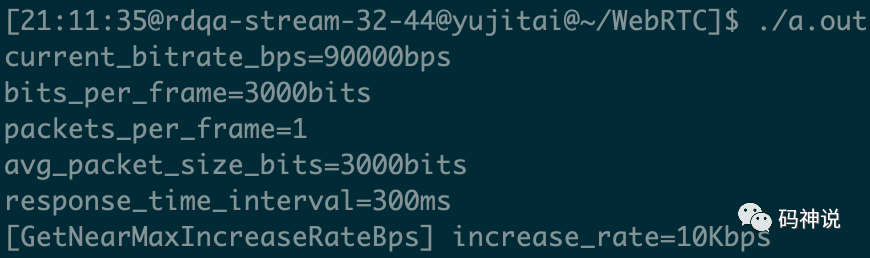
为了更深刻的理解加性增大算法的计算过程,我对 GetNearMaxIncreaseRateBps 函数进行了测试,测试代码很简单:
constexpr int kBitrate = 90000;
aimd_rate_control->SetEstimate(kBitrate,
simulated_clock.TimeInMilliseconds());
aimd_rate_control->GetNearMaxIncreaseRateBps();
设置码率控制器初始码率为 90000bps,计算在该码率下,执行加性增大算法后增大的码率值(每秒)是多少,测试输出如下图所示:
- 测试 2
为了进一步理解过载信号被触发后码率降低的流程,进行如下测试:
constexpr int kInitialBitrate = 50000000;
aimd_rate_control->SetEstimate(
kInitialBitrate,
simulated_clock.TimeInMilliseconds());
constexpr int kAckedBitrate =
40000000 / kFractionAfterOveruse;
RateControlInput input(
BandwidthUsage::kBwOverusing,
kAckedBitrate);
aimd_rate_control->Update(&input,
simulated_clock.TimeInMilliseconds());
设置码率控制器初始码率为 50Mbps,接下来输入过载信号以及发送端的码率估计值 kAckedBitrate(根据接收端反馈的 transport feedback 报文估计码率)。
测试输出如下图所示,可知,带宽过载后的新的码率值为 40 Mbps,在 kAckedBitrate 的基础上回退了 0.85 倍,与上一次的码率相比下降了 10Mbps。

- 测试 3
最后,看一下在网络正常的情况下码率乘性增大的过程。
constexpr int kAckedBitrate = 10000;
aimd_rate_control->SetEstimate(
kAckedBitrate,
simulated_clock.TimeInMilliseconds());
while (simulated_clock.TimeInMilliseconds() -
kClockInitialTime < 20000) {
RateControlInput input(
BandwidthUsage::kBwNormal,
kAckedBitrate);
aimd_rate_control->Update(
&input,
simulated_clock.TimeInMilliseconds());
simulated_clock.AdvanceTimeMilliseconds(1000);
}
设置码率控制器初始码率为 10000bps,每隔 1 秒进行一次 Update,每次的输入信号皆为 normal,每次的输入码率估计值均为10000bps,观察 20 秒内的码率变化,测试输出如下:
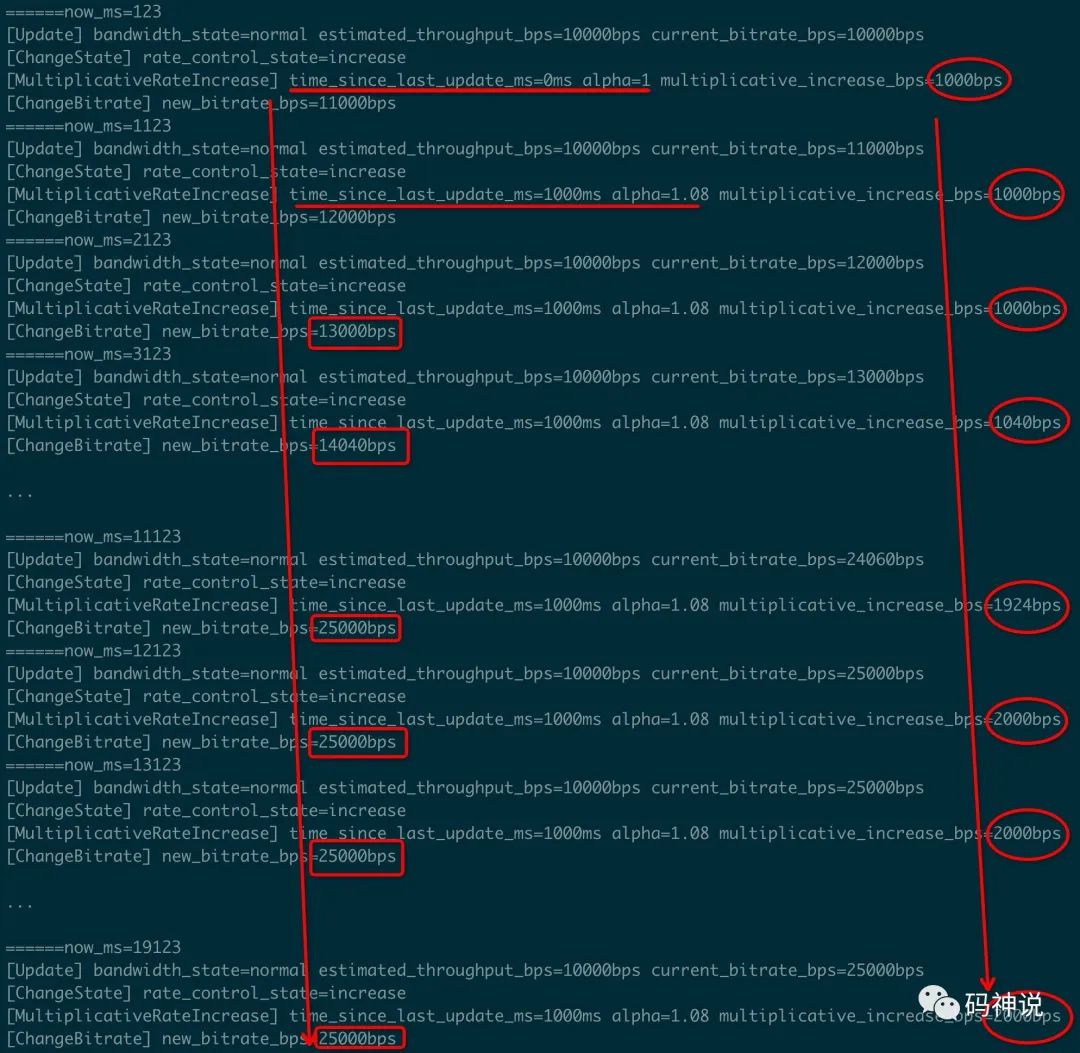
观察测试输出,可知:
- 在首次计算时,乘性增大系数 alpha 的时间指数为 0,因此 alpha 的值为 1 而非 1.08,理论上增加的码率值为 0,但是 WebRTC 规定了码率乘性增大的最小值 1000bps。
- 之后,由于我们每隔一秒 Update 一次,因此 alpha 的时间指数为 1,alpha 值为 1.08。从第四次计算开始,每次增加的码率超过了 1000bps。
- 因为每次输入的码率估计值为 10000 bps,因此可知码率最大值不能超过 1.5 * 10000 + 10000 = 25000bps。因此最终码率值增大到 25Kbps 后保持不变。
至此,WebRTC 的码率控制模块就讲完了,加上前面的三篇,大概脉络如下:
- 计算包组时间差
- trendline 滤波器计算延迟梯度
- 过载检测
- 码率控制
那么问题来了,发送端是如何知道发送的报文到达接收端的时间的呢?这可是计算包组时间差必不可少的条件,更是发送端 BWE 的一切之源头。
其实这个源头的秘密就在于接收端会反馈 transport feedback rtcp 报文到发送端,下一篇会介绍这个特殊的 rtcp 报文,感谢阅读。
参考资料
[2]AIMD 算法: 计算机网络第7版
[3]GCC 草案: https://tools.ietf.org/html/draft-ietf-rmcat-gcc-02#section-5.5
原文出处:WebRTC 拥塞控制 | Transport-CC 之 RTP 头部扩展与 RTCP Feedback 报文
本文是
WebRTC 拥塞控制第 5 篇
- 导读
- RTP 头部扩展
- 扩展格式
- 三问 transport-wide sequence number
- TransportFeedback 报文
- 格式总览
- 记录 RTP 包到达状态之 Packet Chunk
- 记录 RTP 包到达时间之 Receive Delta
- 抓包分析
导读
在 WebRTC 的 Send-side BWE 中,大多数拥塞控制逻辑被放到了发送端,这样做除了方便维护,也增加了相关算法的灵活性,而这一切正是基于Transport-CC(Transport-wide Congestion Control)。
为了使用 Transport-CC,WebRTC 做了两件事:一是针对于发送端,增加 RTP 头部扩展 Transport-wide Sequence Number,二是针对于接收端,增加新的 RTCP 反馈报文 TransportFeedback 。
Transport-CC 的大致逻辑为:发送端发送带有 Transport-wide Sequence Number 头部扩展的 RTP 包,接收端接收这些 RTP 包,缓存它们的到达时间并构造 TransportFeedback 报文反馈给发送端,发送端进行最终的网络拥塞控制。
从本篇开始,将围绕 TransportFeedback 报文,介绍其格式以及 Send-side BWE 在接收端以及发送端的拥塞控制策略。
RTP 头部扩展
扩展格式
RTP 头部 Transport-wide Sequence Number 扩展格式定义如下:
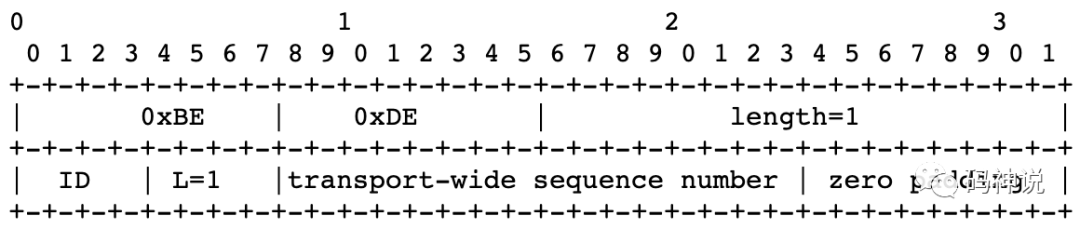
该扩展以 0xBEDE 开头,transport-wide sequence number 字段占用两个字节,从 1 开始递增到 65535 后会向前回绕到1。
使用 wireshark 对带有 transport-wide sequence number 扩展的 RTP 流进行抓包,结果如下图:
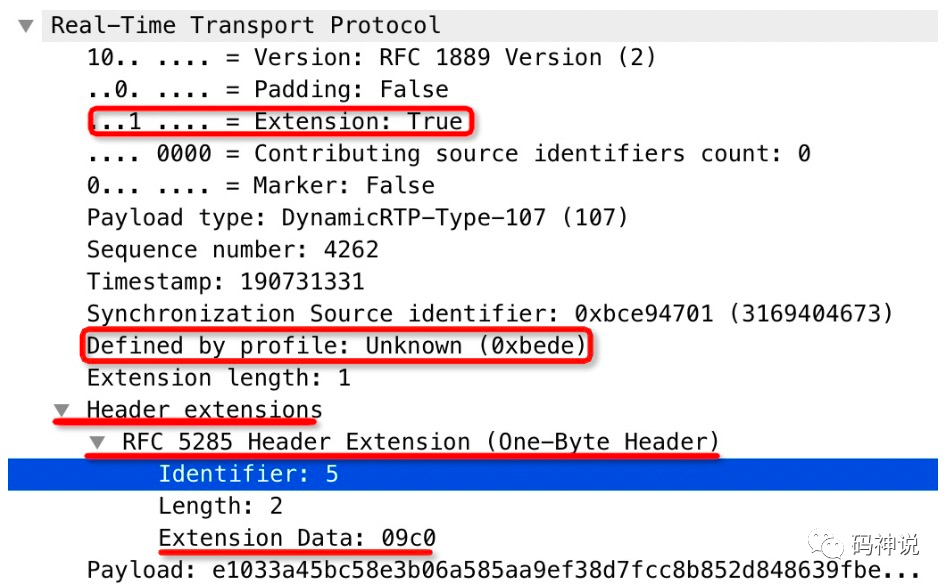
可以看到,该 RTP 包的 transport-wide sequence number 为 0x09c0(2496)。
三问 transport-wide sequence number
- 什么是 transport-wide sequence number?
transport-wide sequence number 对经由同一个 PeerConnection(亦或 socket)发送出去的 RTP 包进行计数,是网络传输层的数据包的 sequence number。
- 为什么要使用 transport-wide sequence number?
我们知道,RTP 包头部已经含有 sequence number 字段用于记录 RTP 包的序列号,那么为何还要增加 transport-wide sequence number 呢?
这是因为,RTP 包头部的 sequence number 字段是针对单路媒体流(MediaStream)进行计数,并不能对某个PeerConnection 通道进行计数,从而估计该 PeerConnection 通道的带宽使用情况。
一般情况下,一个 PeerConnection 只会包含一路流(无论是用于推流还是拉流),此时 RTP 包头部的 sequence number 可以满足需求。但是,一个 PeerConnection 也可能会包含多路流。比如在视频连麦中, 用户既要推自己的流又要拉对方的流,这就是所谓的PeerConnection 多路复用。
由于 RTP 包头部的 sequence number 针对每一路流单独计数,此时便不再满足需求。因此,为了能对某个 PeerConnection 通道进行带宽估计,在 RTP 头部增加一个网络传输层扩展 transport-wide sequence number,使用统一的计数器对该通道下所有的视频流进行计数。
举个例子,假设同一个 PeerConnection 下传输两个视频流 A 与 B,它们的 RTP 包记为 Ra(n, m),Rb(n, m),n 表示 sequence number,m 表示 transport-wide sequence number,这样,同一个 PeerConnection下,视频流按如下形式传输:Ra(1, 1)、Ra(2, 2)、Rb(1, 3)、Rb(2, 4)、Ra(3, 5)、Ra(4, 6)、Rb(3, 7)、Rb(4, 8)。
总结一下,正如 transport-wide-cc 草案[1] 说得那样,使用 transport-wide sequence number 的好处有两点:
- 更适用于拥塞控制。
因为拥塞控制算法不是在媒体流上运行,而是在传输层的数据包流上运行。
- 更快速的丢包检测与恢复。
比如两路流 A 和 B,当 stream A 发生丢包,则不必等到 stream A 的下一个包到来再触发丢包检测机制,从而进行 nack 请求。来自stream B 的包也同样可以触发丢包检测机制,因为两路流使用统一的 transport-wide sequence number 进行计数。
- 如何使用 transport-wide sequence number?
Send-side BWE 启动的关键在于开启 RTP 头部扩展 transport-wide sequence number,这样,接收端才能反馈TransportFeedback 报文。开启头部扩展的方式很简单,只需要在 sdp 信息中加入相应的 extmap 属性,如下:
a=extmap:5 http://www.ietf.org/id/draft-holmer-rmcat-transport-wide-cc-extensions-01
相应的,WebRTC 在获取视频引擎能力的函数中开启 transport-cc RTP 头部扩展,代码如下:
RtpCapabilities GetCapabilities() const {
RtpCapabilities capabilities;
capabilities.header_extensions.push_back(webrtc::RtpExtension(
webrtc::RtpExtension::kTransportSequenceNumberUri,
webrtc::RtpExtension::kTransportSequenceNumberDefaultId));
}
TransportFeedback 报文
正如 Remb 作为 Receive-side BWE 的关键 RTCP 报文,Transport Feedback 则作为 Send-side BWE 的关键 RTCP 报文,它们是拥塞控制算法架在发送端与接收端之间的一座桥梁。
这两种与拥塞控制相关的 RTCP 报文的类型如下表所示:
| rtcp | packet type | feedback message type |
|---|---|---|
| remb | 206 (psfb) | 15 |
| transport feedback | 205 (rtpfb) | 15 |
在 WebRTC 中,接收端发送 TransportFeedback 报文的时间间隔是一个动态值(50ms ~ 250ms)。发送间隔会根据码率值的 5% 进行计算,也就是说 TransportFeedback 报文至多占用总带宽的 5%。
同理,开启 transport-cc 的 TransportFeedback 报文反馈,需要在 sdp 中增加 rtcp-fb 属性。
a=rtcp-fb:107 transport-cc
WebRTC 视频编解码器默认开启 transport-cc 的 rtcp-fb 属性,代码如下:
void AddDefaultFeedbackParams(VideoCodec* codec) {
codec->AddFeedbackParam(FeedbackParam(
kRtcpFbParamTransportCc,
kParamValueEmpty));
}
格式总览
先整体看下 TransportFeedback 包的格式:

整体格式为:4 字节 RTCP 固定头部 + 8 字节 ssrc 信息 + 真正的 TransportFeedback 报文的反馈信息 Feedback Control Info。
- packet status count
2 字节,表示这个 TransportFeedback 包记录了多少个 RTP 包的到达信息。
- base sequence number
2 字节,TransportFeedback 包中记录的第一个 RTP 包的 transport-wide sequence number。
一般情况下,当前 TransportFeedback 包的 base sequence number 加上 packet status count 等于下一个 TransportFeedback 包的 base sequence number。
但是注意,在反馈的各个 TransportFeedback 包中,base sequence number 不一定是递增的,也有可能比之前的小。在 RTP 包乱序到达的场景下会发生这种情况,这会导致之前已经被反馈的 RTP 包的到达信息再次被反馈。
- feedback packet count
1 字节,每发送一个 TransportFeedback 包计数器都会加 1,相当于 RTCP 的 sequence number,用于检测 TransportFeedback 包的丢包情况,取值范围 [0, 255]
- reference time
3 字节,表示参考时间,单位为 64ms,TransportFeedback 包记录的 RTP 包的到达时间以它作为基准进行计算。
- packet chunk
2 字节,记录 RTP 包的到达状态。注意,本文所指的 RTP 包的到达状态包括包到达和包未到达。
- recv delta
1 字节或者 2 字节,记录 RTP 包之间的到达时间偏移。
记录 RTP 包到达状态之 Packet Chunk
Packet Status Symbols
在介绍 packet chunk 之前,我们先来看一下 RTP 包的三种到达状态( Packet Status Symbols)。
- 00 Packet not received
到达状态为包未到达,无到达时间偏移。
- 01 Packet received, small delta
到达状态为包到达,到达时间偏移小。
- 10 Packet received, large or negative delta
到达状态为包到达,到达时间偏移大或者为负值。
- 11 [Reserved]
保留,目前不处理这种情况。
在网络质量高的情况下,RTP 包的到达时间偏移一般很小,属于 small delta。
注意,在 RTP 包乱序的场景下,比如,下一个期望接收的包号是 3,结果来的是 5,对于 4 号包的处理,WebRTC 的做法是:将其到达状态标记为Packet not received ,设置其到达时间偏移为 0,即没有 recv delta。不过,4 号包不一定真的丢失,如果接下来 4 号包到达,那么依然会被标记为 Packet received 状态并以 TransportFeedback RTCP 报文的形式反馈给发送端。
接下来介绍 packet chunk。
packet chunk有两种类型,Run length chunk(行程长度编码数据块)与 Status vector chunk(状态矢量编码数据块),对应 packet chunk 结构的两种编码方式。
两种类型的 chunk 的长度都是 2 字节,数据包状态以 chunk 块的形式描述。
Run Length Chunk(行程长度编码数据块)
先来了解下 Run Length(行程长度)编码。
Run Length 编码是一种简单的数据压缩算法,其基本思想是将重复且连续出现多次的字符使用
连续出现次数+字符来描述。例如:aaabbbcdddd 通过 Run Length 编码就可以压缩为 3a3bc4d。Run Length Chunk 中就使用了 Run Length 编码标识连续多个相同状态的包。
Run length chunk 第一个 bit 为 0,后面跟着包的到达状态 packet status symbol 以及具有该到达状态的包的数量 run length,格式如下:

- chunk type (T)
1 bit,值为 0。
- packet status symbol (S)
2 bits,标识包的到达状态(00、01、10)。
- run length (L)
13 bits,行程长度,标识有多少个连续包具有相同的到达状态。
下面举个例子说明。

chunk type 为 0 ,可知为 RLE chunk。
packet status symbol 为 00,可知包的到达状态为 Packet not received。
run length 为 0000011011101,即 221,可知有 221 个连续的包的到达状态为 Packet not received。
Status Vector Chunk(状态矢量编码数据块)
Status vector chunk 第一个 bit 为 1,后面跟着 1 bit symbol size,决定 symbol list 的大小为 7 还是 14,格式如下:

- chunk type (T)
1 bit,值为 1。
- symbol list
14 bits,packet status symbol list,标识一系列包的到达状态,根据 symbol size 值的不同,具有不同的编码方式,总共能标识 7 或 14 个包的到达状态。
- symbol size (S)
注意,这个 S 并不是 packet status symbol,而是 packet status symbol size,它决定包的到达状态的编码方式,即packet status symbol 用 1 个 bit 表示还是用 2 个 bit 表示。
S=0,表示每 1 个 bit 表示 1 个包的到达状态,1 bit 可表示的状态只有 packet not received(00) 与 packet received(01) 两种,此时 symbol list 可以标识 14 个包的到达状态。
S=1,表示每 2 个 bit 表示 1 个包的到达状态,2 bit 可表示目前已定义的全部状态:packet not received(00)、packet received(01)、和 packet received(10),此时 symbol list 可以标识 7 个包的到达状态。
可以看出,这样极致的利用每一个 bit,是为了尽可能用更小的空间表示更多的包的到达状态。
下面举个例子说明。

chunk type 为 1 ,可知为 Status Vector chunk。
symbol size 为 0,可知包的到达状态用 1 bit 来表示,一共可以标识 14 个包的到达状态。
symbol list 标识的包的到达状态依次是:
1x packet not received
5x packet received
3x packet not received
3x packet received
2x packet not received
记录 RTP 包到达时间之 Receive Delta
到达时间偏移,表示 RTP 包到达时间与前面一个 RTP 包到达时间的间隔,单位是 250us(0.25ms)。
对于当前 TransportFeedback 包中记录的第一个 RTP 包,虽然它的前面没有 RTP 包,但是也会计算它的到达时间偏移。不过该包的到达时间偏移是相对于 reference time 的,至于这样做的原因,我猜测可能是为了统一处理的逻辑吧。
packet chunk 用到了不同编码方式,对于收到的 RTP 包才添加到达时间信息,而且是通过时间间隔的方式记录到达时间。
- 如果在 packet chunk 中记录了一个
Packet received, small delta状态的包,那么会在 receive delta 列表中添加一个 8-bit unsigned 长度的 receive delta ,取值范围为[0, 255]。由于 receive delta 单位为 0.25ms,所以此时 receive delta,即到达时间偏移量的取值范围为[0ms, 63.75ms]。 - 如果在 packet chunk 中记录了一个
Packet received, large or negative delta状态的包,那么会在 receive delta 列表中添加一个 16-bit signed 长度的 receive delta ,取值范围为[-32768, 32767]。由于 receive delta 单位为 0.25ms,所以此时 receive delta,即到达时间偏移量的取值范围为[-8192.0ms, 8191.75ms]。 - 如果到达时间偏移超过了最大限制,那么会构建一个新的 TransportFeedback RTCP 包,由于
reference time长度为 3 字节,所以目前的包中 3 字节长度能够覆盖很大范围了。
我们发现,packet chunk 中包的三种到达状态:0(未到达,可能丢失)、1(到达,小的到达时间偏移)、2(到达,大的到达时间偏移) ,恰好对应receive delta 的三种不同的长度:0 字节,1 字节,2 字节。因此,总结一下:对于每一个到达状态为 Packet received 的 RTP 包:
- 如果到达状态为 01,即到达时间偏移小,那么 receive delta 使用 1 字节表示。
- 如果到达状态为 10,即到达时间偏移大,那么 receive delta 使用 2 字节表示。
- 如果到达时间偏移已经超出了最大限制,另起新的 TransportFeedback 包。
对于到达状态为 Packet not received 的 RTP 包,因为根本未到达,所以不需要 receive delta 标识。在 WebRTC 的实现中执行 AddDeltaSize(0) 函数,来标记这是一个未到达的包。
可以看出,对于不同大小的到达时间偏移,receive delta 占用的字节长度也不同,与 packet chunk 不同的编码方式一样,这样做的目的是尽可能减小 TransportFeedback 包的大小,尽量降低 TransportFeedback 反馈报文的带宽占用。
最后,对于 Packet received, small delta 状态的包来说:
- receive delta 最大值为 63.75ms,这意味着 1 秒时间跨度最少能标识 1000/63.75~=16 个包,如果包大小为 1200 bytes,那么码率可达 150 Kbps。
- receive delta 时间单位为 0.25ms,这意味着 1 秒时间跨度最多能标识 1000/0.25 = 4000 个包,如果包大小为 1200 bytes,那么码率可达 38.4 Mbps。
抓包分析
下面,我们抓包来实际看下 TransportFeedback 报文的格式,如下图:
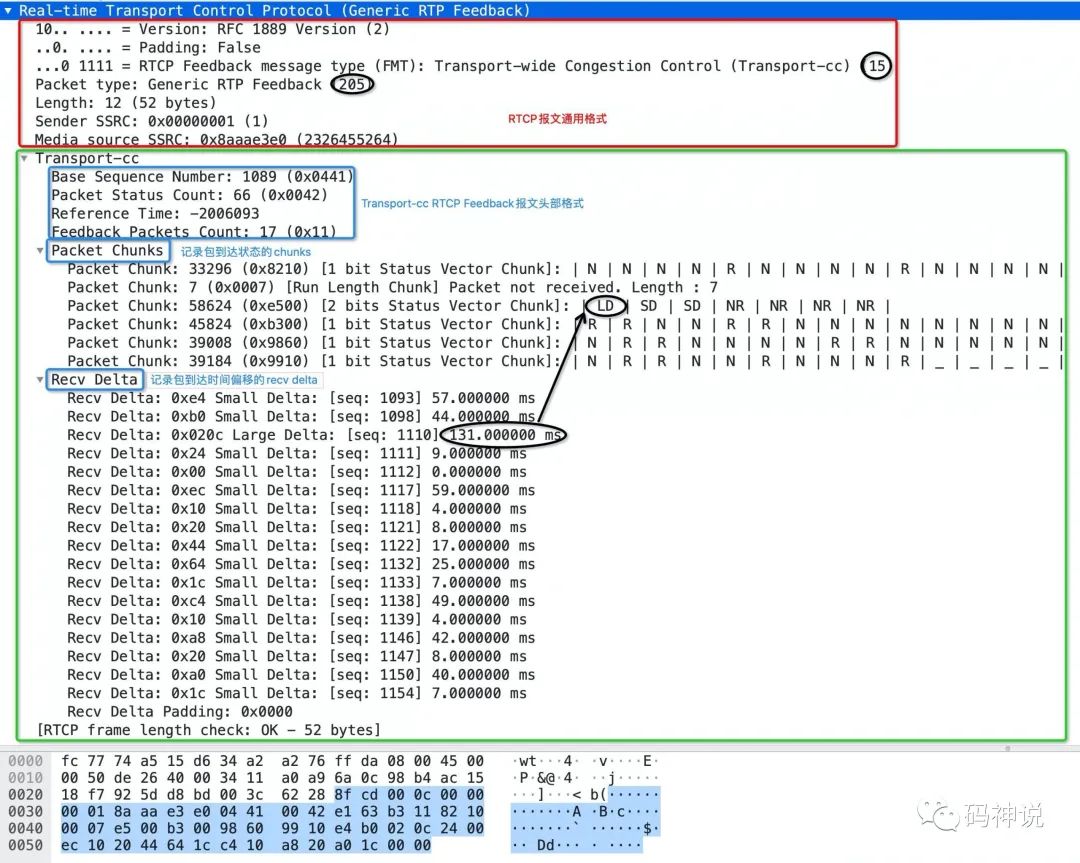
红色方框中的部分是 RTCP 报文的通用格式,其中,前 8 个字节(固定4 字节头部和 sender ssrc 字段)是所有 RTCP 报文所共有的,而有没有 media source ssrc 字段则要视具体的 RTCP 报文而定。
比如 Nack、Pli、TransportFeedback 报文就有这个字段,Sender report、Receiver report 则没有这个字段,而Fir、Remb 报文虽然有这个字段但是却设置为 unused 状态(值为 0)。
绿色方框中的部分是真正的 TransportFeedback 报文的格式,总体分为三大部分:头部、记录包到达状态的 chunk 以及记录包到达时间偏移的recv delta。
观察上图,我总结了几个比较重要的点以帮助你更好的理解这个报文:
该报文
base sequence number为 1089,packet status count 为 66,那么下一个要发送的 TransportFeedback 报文的 base sequence number 为 1089 + 66 = 1155。该报文携带了全部三种不同编码方式的 chunks。对于 1 bit status vector chunk,N 代表
packet not received,R 代表packet received,small delta,对于 2 bit status vector chunk,NR 代表packet not received,SD(small delta) 代表packet received,small delta,LD(large delta) 代表packet received,large delta。到达状态为
packet not received的包没有 recv delta。观察上图,packet status count 值为 66,不妨数一下 chunks 记录的包的到达状态的数量,为 14 + 7 + 7 + 14 + 14 + 10 = 66,二者一致。然而 recv delta 的数量却只有 17,因为只有真正收到了包,才会记录其到达时间偏移,这应该很好理解。small delta 的取值范围是
[0ms, 63.75ms],观察 recv delta,存在一个 large delta 为 131ms,已经超出了 63.75ms,其他的 small delta 都是在 63.75ms 之内。
至此,我们了解了 transport-cc 的关键策略:增加 RTP 头部扩展和 RTCP Feedback 报文,本篇着重介绍了它们的格式。下一篇将围绕着 TransportFeedback 报文,深入源码,介绍 transport-cc在接收端以及发送端的逻辑框架,感谢阅读。
参考资料
[1]transport-wide-cc 草案: https://tools.ietf.org/html/draft-holmer-rmcat-transport-wide-cc-extensions-01