WebRTC拥塞控制01
原文出处:WebRTC 拥塞控制 | 计算包组时间差-InterArrival
本文是
WebRTC 拥塞控制第 1 篇
- 导读
- 延迟梯度与包组
- Pre-filtering
- 源码分析
- ComputeDeltas 函数
- PacketInOrder 函数
- BelongsToBurst 函数
- NewTimestampGroup 函数
- 测试用例
导读
GCC(Google Congestion Control)包含两种拥塞控制算法:一种是基于丢包的,一种是基于延迟的。GCC最后综合这两种算法得到一个目标码率,基于延迟的拥塞控制算法相较于基于丢包的拥塞控制算法更为复杂。本篇是 WebRTC 拥塞控制算法讲解第一篇,主要介绍包组和延迟梯度等一些基本理论,并深入源码介绍包组间的时间差值的计算过程。
延迟梯度与包组
延迟梯度描述了从发送端到目的地的包所经历的端到端的延迟变化趋势。GCC算法正是使用延迟梯度来推断网络拥塞,以动态的限制发送速率。在基于接收端的拥塞控制算法中,使用卡尔曼滤波器计算延迟梯度,而在基于发送端的拥塞控制算法中,则使用Trendline 滤波器计算延迟梯度。下面是维基百科对于延迟[1](或称队列延迟、排队延迟)的描述:
这个术语最常用于路由器。当数据包到达路由器时,必须对它们进行处理和传输。路由器一次只能处理一个包。
如果数据包到达的速度比路由器处理它们的速度快(例如在突发数据传输中),路由器就会把它们放入队列(也称为网络缓冲区),直到路由器可以开始传输它们。
延迟也会因分组的不同而不同,因此在测量和评估排队延迟时通常会生成平均值和统计数据。
计算延迟梯度需要了解包组的概念,在 WebRTC 中,延迟不是一个个包来计算的,而是通过将包分组,然后计算这些包组之间的延迟,这样做可以减少计算次数,同时减少误差。包组根据包的发送时间的差值来划分。判断新包组的方法是:如果当前包的发送时间与当前包组的第一个包的发送时间的差值大于5ms,那么认为这个包属于新的包组。为什么是 5ms 呢?GCC 草案[2]里的一段话回答了这个问题:
The Pacer sends a group of packets to the network every burst_time interval. RECOMMENDED value for burst_time is 5 ms.
接下来,再引出两个概念:包组间的发送时间差 inter-departure 与到达时间差 inter-arrival。
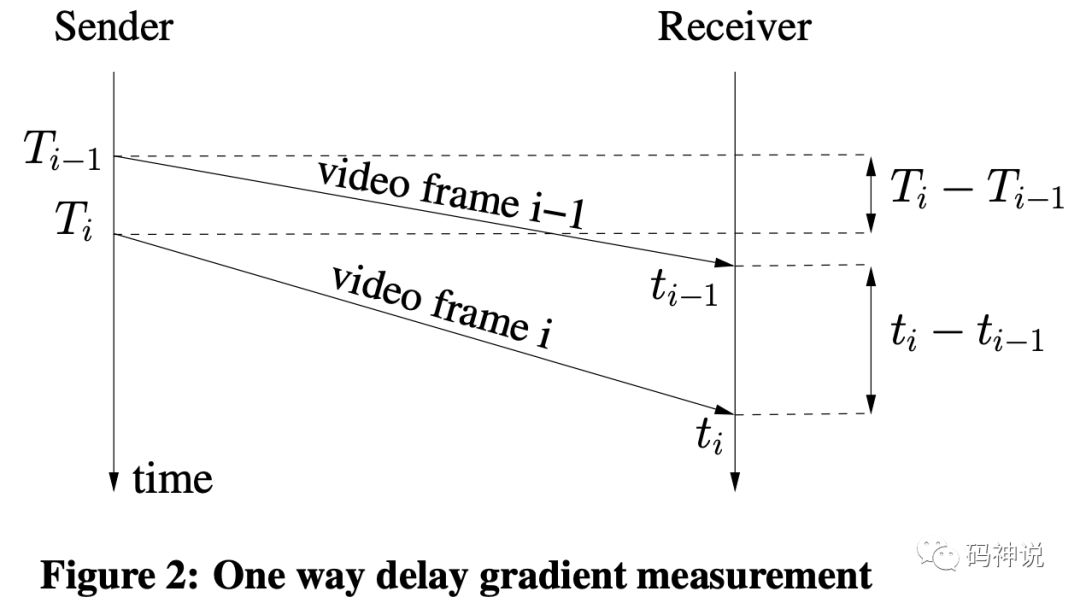
如上图所示,video frame i-1 与 video frame i 代表相邻的两个包组,T(i) 代表包组 i 最后一个包的发送时间,t(i) 代表包组的最后一个包的到达时间,那么有:
inter-depature = T(i) - T(i-1)
inter-arrival = t(i) - t(i-1)
inter-group delay variation =
d(i) = inter-arrival - inter-depature
inter-group delay variation 是两个包组之间的延迟变化,显然,如果这个值很大,那么网络很可能发生了拥塞。WebRTC Trendline 滤波器会对这个值进行最小二乘法线性回归得到最终的延迟梯度值,并与动态的阈值进行比较,从而进行拥塞控制,下一篇将会介绍这个过程。
Pre-filtering
在计算包组间的时间差值的时候,并不是简单的将包组两两之间的 inter-arrival delta time 和 inter-depature delta time 计算出来就了事。这个过程还需要对包进行过滤,比如对突发数据的处理、对包的发送时间乱序的处理、对包的到达时间乱序或者跳变的处理,这些处理过程称为预过滤。
注意,GCC 草案对于预过滤的定义是:旨在处理因为网络信道中断等非网络拥塞原因被排队滞留在网络缓冲区的数据包在网络恢复后以突发的方式进行发送的场景,也就是说,预过滤的目的是处理突发的数据包。GCC 草案的详细描述如下,其中,对于突发数据包的判断在下文会提到。
The pre-filtering aims at handling delay transients caused by channel outages.
During an outage, packets being queued in network buffers, for reasons unrelated to congestion, are delivered in a burst when the outage ends.
The pre-filtering merges together groups of packets that arrive in a burst. Packets are merged in the same group if one of these two conditions holds:
- A sequence of packets which are sent within a burst_time interval constitute a group.
- A Packet which has an inter-arrival time less than burst_time and an inter-group delay variation d(i) less than 0 is considered being part of the current group of packets.
源码分析
基于 WebRTC M71 版本。
ComputeDeltas 函数
WebRTC 的 InterArrival 类实现了包组的时间差值计算,其对外接口为ComputeDeltas。输入每个包的发送时间、到达时间、系统时间、包大小,输出包组的发送时间间隔、到达时间间隔、包组大小差值,供Trendline 滤波器计算延迟梯度。整个时间差值计算的子过程包括:包的有序性判断、新包组的判断、突发数据的判断。这些函数的声明如下所示:
class InterArrival {
public:
bool ComputeDeltas(
uint32_t timestamp,
int64_t arrival_time_ms,
int64_t system_time_ms,
size_t packet_size,
uint32_t* timestamp_delta,
int64_t* arrival_time_delta_ms,
int* packet_size_delta);
private:
bool PacketInOrder(
uint32_t timestamp);
bool NewTimestampGroup(
int64_t arrival_time_ms,
uint32_t timestamp) const;
bool BelongsToBurst(
int64_t arrival_time_ms,
uint32_t timestamp) const;
};
ComputeDeltas 函数整体计算流程如下:
- 如果是首个包,存储包组信息,返回 false
- 如果包不是有序发送,丢弃,返回 false。
- 如果是当前包组的包,更新包组信息,返回 false。
- 如果是突发数据,认为是当前包组的包,更新包组信息,返回 false。
- 如果是新的包组到来,根据当前包组和上一个包组的信息计算时间差值,返回 true。
下面详细介绍步骤 5 的计算过程:当到来的数据包属于新的包组时,开始计算之前的两个包组的发送时间差与到达时间差。
注意,发送时间差和到达时间差都是根据包组的最后一个包的发送时间和到达时间进行计算,核心代码如下:
*timestamp_delta =
current_timestamp_group_.timestamp -
prev_timestamp_group_.timestamp;
*arrival_time_delta_ms =
current_timestamp_group_.complete_time_ms -
prev_timestamp_group_.complete_time_ms;
之后,要对计算出来的到达时间间隔进行异常处理,我称之为预过滤。
- 到达时间与系统时钟的偏差是否存在不成比例的跳变?
正常情况下,二者基本一致。若偏差 > kArrivalTimeOffsetThresholdMs(3000ms),重置。
int64_t system_time_delta_ms =
current_timestamp_group_.last_system_time_ms -
prev_timestamp_group_.last_system_time_ms;
if (*arrival_time_delta_ms - system_time_delta_ms >=
kArrivalTimeOffsetThresholdMs) {
Reset();
return false;
}
- 包在 socket 接收到 BWE 这段路径中是否被重新排序?
如果 inter-arrival time delta < 0,说明包组在收到本地到达时间戳后被重新排序(可能是乱序到达的包被重新排序),连续超过kReorderedResetThreshold(3) 次,重置。
if (*arrival_time_delta_ms < 0) {
++num_consecutive_reordered_packets_;
if (num_consecutive_reordered_packets_ >=
kReorderedResetThreshold) {
Reset();
}
return false;
} else {
num_consecutive_reordered_packets_ = 0;
}
至此,新包组到来时计算包组时间差值的过程就讲述完毕了。
关于步骤 2、4、5 中,如何判断包发送有序?如何判断突发数据?如何判断到来的包是否属于新的包组?下面将依次解答。
PacketInOrder 函数
该函数用来判断包是否有序发送。根据包的发送时间与当前包组第一个包的发送时间的差值,即时间戳是否增长来判断是否是乱序包。
// Assume that a diff which is
// bigger than half the timestamp
// interval (32 bits) must be due to
// reordering.
uint32_t timestamp_diff = timestamp -
current_timestamp_group_.first_timestamp;
return timestamp_diff < 0x80000000;
解释一下差值为什么要和 0x80000000 进行比较:时间戳变量的类型都是 uin32_t,而无符号数小减大会得到一个特别大的数字,这个数字比 0x80000000 大得多。当包的发送时间戳降序,timestamp_diff < 0x80000000 自然不成立,函数返回 false。这里涉及到 WebRTC 中判断最新的包序号和时间戳的算法,实现在 module_common_types_public.h 文件中。
另外,需要注意的是:比较的基准时间是当前包组的首包的发送时间,如果一组包的发送时间降序,但都大于首包的发送时间,那么也认为是有序的,并会用于包组时间差的计算:更新当前包组的到达时间以及最新的发送时间而不是最后一个包的发送时间。
BelongsToBurst 函数
该函数用于判断是否是突发数据。
int propagation_delta_ms =
arrival_time_delta_ms -
ts_delta_ms;
if (propagation_delta_ms < 0 &&
arrival_time_delta_ms <=
kBurstDeltaThresholdMs &&
arrival_time_ms -
current_timestamp_group_.first_arrival_ms <
kMaxBurstDurationMs)
return true;
由上面代码可知,满足以下条件,认为是突发数据包:
- 延迟梯度 < 0
- 到达时间间隔 <= kBurstDeltaThresholdMs(5ms)
- 与当前包组的首包到达时间的差值 < kMaxBurstDurationMs(100ms)
突发数据包将被归为当前的包组。
NewTimestampGroup 函数
该函数用于判断是否属于新的包组。
bool InterArrival::NewTimestampGroup(
int64_t arrival_time_ms,
uint32_t timestamp) const {
if (current_timestamp_group_.IsFirstPacket()) {
return false;
} else if (BelongsToBurst(arrival_time_ms, timestamp)) {
return false;
} else {
uint32_t timestamp_diff = timestamp -
current_timestamp_group_.first_timestamp;
return timestamp_diff >
kTimestampGroupLengthTicks;
}
}
由上面代码可知,满足以下条件,认为是新的包组:
- 不是首包
- 不是突发数据包
- 新包的发送时间与当前包组的第一个包的发送时间的差值 > kTimestampGroupLengthTicks(5ms)
只有当新的包组到来且在这之前已经有了两个包组,才会(对这两个包组)进行时间差值的计算。
测试用例
为了能够更好地掌握包组时间差值的计算过程,我对 WebRTC 的 inter_arrival_unittest.cc测试文件进行了修改,并加入了一些关键日志帮助理解。下图是其中一个测试函数的输出:
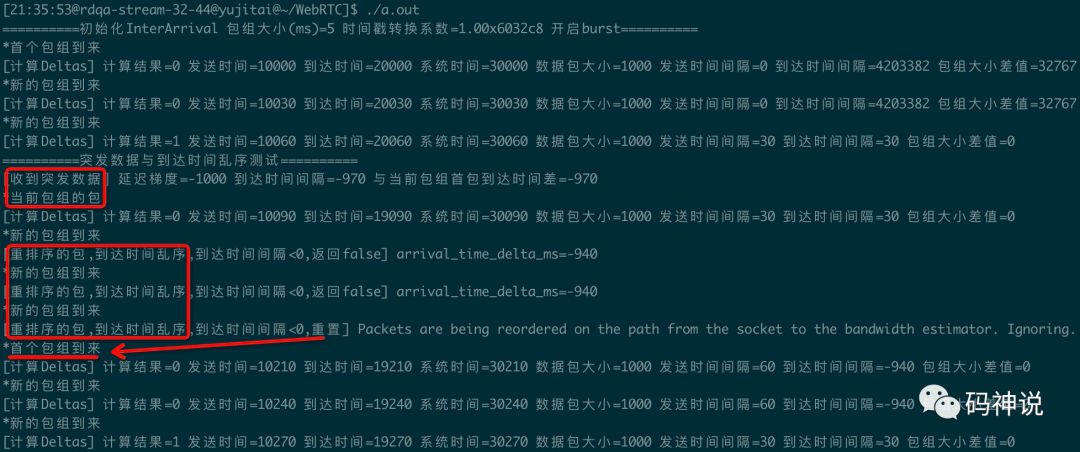
该测试函数对正常累加、突发数据、到达时间乱序这三种收包场景进行了测试。
一共测试了 10 个包组:前 3 个包组正常到达,在收到第 3 个包组时,对前面 2 个包组进行时间差计算;在第 4 个包组发送前,使其到达时间减少1000ms,之后,第 4 个包组检测为突发数据包,认为是当前包组的包;第 5~7 个包被检测为到达时间乱序包,并被重置;经过前面的重置,最后 3 个包恢复了正常的计算逻辑。
测试函数的源码以及完整的测试用例,在我的 github 仓库中。
源码地址:https://github.com/yujitai/WebRTC-Research
您也可以访问我的知乎或者个人网站,找到这篇文章直接跳转到源码地址。
下一篇,将介绍 WebRTC 的 Trendline 滤波器。本文至此结束,感谢收看。
参考资料
[1]队列延迟: https://en.wikipedia.org/wiki/Queuing_delay
[2]谷歌拥塞控制算法草案: https://tools.ietf.org/html/draft-ietf-rmcat-gcc-02
原文出处:WebRTC 拥塞控制 | Trendline 滤波器
本文是
WebRTC 拥塞控制第 2 篇
- 导读
- 指数平滑
- 一次指数平滑法(Single Exponential Smoothing)
- 指数平滑系数(Smoothing Coeff)
- 最小二乘法求解线性回归
- 线性回归(Linear Regression)
- 最小二乘法(Least Square)
- 源码分析
- Trendline 滤波器参数
- LinearFitSlope 函数
- Update 函数
- 测试用例
导读
上一篇介绍了包组时间差的相关概念与计算过程,在 ComputeDeltas 函数中,我们最终得到了包组的发送时间差 send_delta_ms和到达时间差 arrival_delta_ms。
本篇将介绍 WebRTC 的 Trendline滤波器如何根据计算出来的发送时间差与到达时间差去评估最终的延迟梯度的趋势值,在此之前,需要了解指数平滑与线性回归的相关概念。
指数平滑
一次指数平滑法(Single Exponential Smoothing)
指数平滑法(Exponential Smoothing) 是在移动平均法基础上发展起来的一种时间序列分析预测法,它是通过计算指数平滑值,配合一定的时间序列预测模型对现象的未来进行预测。其原理是任一期的指数平滑值都是本期实际观察值与前一期指数平滑值的加权平均,因此也是一种特殊的加权平均法。一次指数平滑法预测公式如下:
- 为 t+1 时刻的一次指数平滑趋势预测值
- 为 t 时刻的一次指数平滑趋势预测值
- 为 t 时刻的实际观察值
- 为权重系数,也称为指数平滑系数
再来看百度百科对指数平滑法[1]的一段描述:
简单的全期平均法是对时间数列的过去数据一个不漏地全部加以同等利用;移动平均法则不考虑较远期的数据,并在加权移动平均法中给予近期数据更大的权重;而指数平滑法则兼容了全期平均和移动平均所长,不舍弃过去的数据,但是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数。
为了加深对上面这段话的理解,我们把一次指数平滑公式进行变形:公式 (1) 中,最后的 表示如下:
将公式 (2) 代入公式 (1),整理得:
同理,可以将 的表示代入公式 (3),最后得到的通用公式如下:
观察公式 (4),可知:
- 权重系数按等比级数减少,公比为 ,这便是指数平滑法中
指数的意义所在。 - 在 0 到 1 之间,所以 的值会越来越小,也就是说,距离 t+1 时刻越久远的实际观察值,对 t+1 时刻的预测值的影响就越小。
指数平滑系数(Smoothing Coeff)
指数平滑系数的选择的原则如下:
- 如果时间序列波动不大,比较平稳,则平滑系数应取小一点,以减少修正幅度,使预测模型能包含较长时间序列的信息。
- 如果时间序列具有迅速且明显的变动倾向,则平滑系数应取大一点,以使预测模型灵敏度高些,以便迅速跟上数据的变化。
在 WebRTC 发送端基于延迟的拥塞控制中,累计延迟梯度的指数平滑系数为 0.9。
最小二乘法求解线性回归
线性回归(Linear Regression)
如果预测的变量是连续的,我们称其为回归。回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归或者简单线性回归。线性回归过程主要解决的就是如何通过样本来获取最佳的拟合线。
最小二乘法(Least Square)
也称最小平方法[2],是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。
简单线性回归最常用的方法便是最小二乘法,其数学推导过程如下:
假设拟合直线为
对任意样本点 ,误差为
当 为最小时拟合度最高
对 a 和 b 分别求一阶偏导,得:
令公式 (5) 和公式 (6) 等于 0,并且有:,,得到最终解:
源码分析
基于 WebRTC M71 版本。
Trendline 滤波器参数
Trendline 滤波器的三个重要参数分别是:窗口大小、平滑系数、延迟梯度趋势的增益。
窗口大小决定收到多少包组之后开始计算延迟梯度趋势;平滑系数用于累计延迟梯度的一次指数平滑计算;对累计延迟梯度平滑值进行最小二乘法线性回归之后求得延迟梯度趋势,会乘以增益并和阈值作比较,以检测带宽使用状态。下面是 WebRTC 中这三个参数的默认值。
constexprsize_t
kDefaultTrendlineWindowSize = 20;
constexprdouble
kDefaultTrendlineSmoothingCoeff = 0.9;
constexprdouble
kDefaultTrendlineThresholdGain = 4.0;
LinearFitSlope 函数
该函数使用最小二乘法求解线性回归,输入 window_size_ 个样本点(arrival_time_ms, smoothed_delay),输出延迟梯度变化趋势的拟合直线斜率 trendline_slope。
absl::optional<double> LinearFitSlope(
const std::deque<std::pair<double, double>>& points);
求解过程完全参照公式 (7)。
Update 函数
该函数输入包组间到达时间差与发送时间差以及包组的到达时间,并估计延迟梯度的趋势。
class TrendlineEstimator {
public:
void Update(
double recv_delta_ms,
double send_delta_ms,
int64_t arrival_time_ms);
};
该函数是 Trendline 滤波器的核心实现,包括:
- 计算延迟梯度
- 计算累计延迟梯度的一次指数平滑值
- 最小二乘法线性回归求延迟梯度趋势斜率
- 检测带宽使用状态,比如是否过载
- 更新延迟梯度趋势动态阈值
本篇介绍前 3 个实现过程。
- 计算延迟梯度
const double delta_ms =
recv_delta_ms - send_delta_ms;
上一篇已经介绍过延迟梯度的计算公式:
d(i) = inter-arrival - inter-depature
那么延迟梯度为何能作为网络拥塞的标志呢?
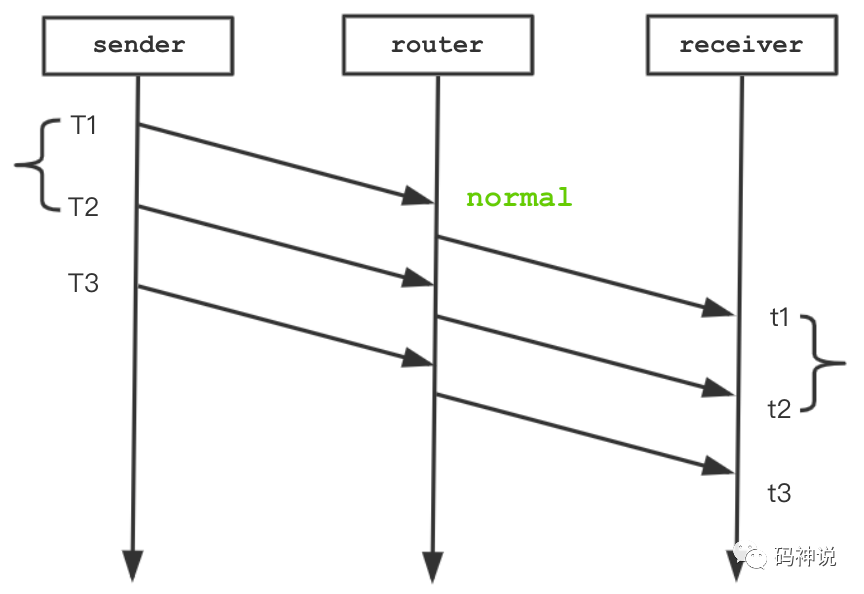
当网络没有拥塞,延迟梯度:t2 - t1- (T2 - T1) = 0,如下图所示。
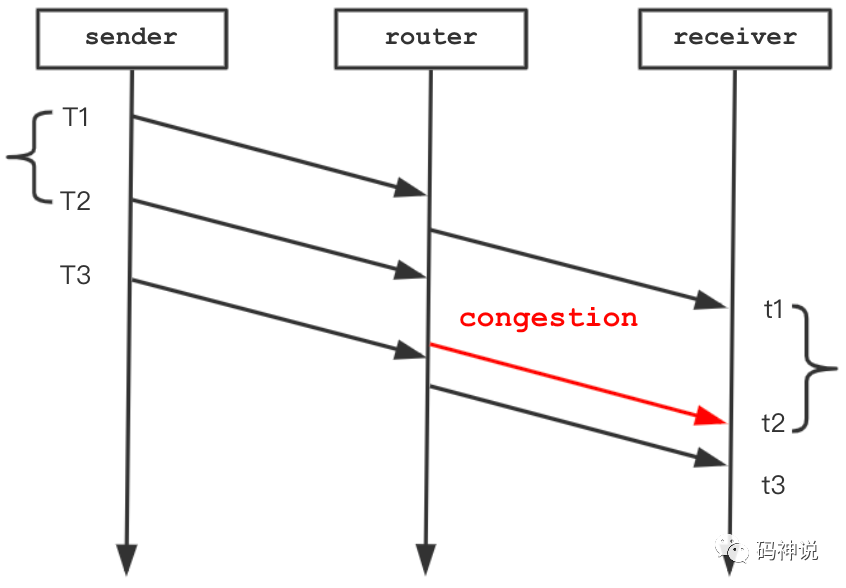
当网络存在拥塞,数据包经过 router 节点时经历排队等待,导致到达时间比原本要晚,延迟梯度:t2 - t1- (T2 - T1) > 0,如下图所示。
因此,延迟梯度可以作为网络拥塞的指示。把一段时间内的数据包组的延迟梯度累加、平滑、回归,最终得到延迟梯度的趋势,这就是 Trendline 滤波器要做的事情。
- 累计延迟梯度一次指数平滑
// Exponential backoff filter.
accumulated_delay_ += delta_ms;
smoothed_delay_ = smoothing_coef_ * smoothed_delay_ +
(1 - smoothing_coef_) * accumulated_delay_;
注意,计算一次指数平滑值的公式为 ,实际观测值前面的系数为 。而上述源码的计算公式的实际观测值 accumulated_delay_ 的平滑系数为,形式不一,但本质不变。
smoothing_coef_ 取 0.9,那么 accumulated_delay_ 前的平滑系数为0.1,这意味着新的延迟梯度观测值的变化对平滑值的影响较小,减少了修正幅度。
上面提到的指数平滑系数的选择的原则:当时间序列波动不大,比较平稳的时候会选择较小的系数。
- 最小二乘法线性回归求延迟梯度趋势斜率
累计延迟梯度平滑值 smoothed_delay_ 计算出来之后将作为 y 轴的数据与作为 x 轴数据的到达时间序列存入队列。当样本点的数量达到滤波器的窗口大小,开始使用最小二乘法求解线性回归,LinearFitSlope 函数实现了这个过程。
// Simple linear regression.
// Update trend_ if it is possible to fit a line to the data. The delay
// trend can be seen as an estimate of (send_rate - capacity)/capacity.
delay_hist_.push_back(std::make_pair(
static_cast<double>(arrival_time_ms - first_arrival_time_ms_),
smoothed_delay_));
trend = LinearFitSlope(delay_hist_).value_or(trend);
最终得到了线性回归的解:延迟梯度的变化趋势 trend,其实就是很多离散的样本点的拟合直线斜率。这个预测的斜率值 trend可以表征网络的拥塞程度(网络缓冲区,即路由器数据包排队的消涨情况):
- 0 < trend < 1,数据包延迟不断加大,路由器缓冲队列长度持续增加,直到网络缓冲区被填满。
- trend == 0,数据包延迟恒定,路由器缓冲区队列长度不变。
- trend < 0,数据包延迟不断减少,路由器缓冲区队列长度不断减少,直到队列为空。
测试用例
下面进行简单的测试,将 Trendline 滤波器窗口设置为 20,平滑系数设置为 0.9,增益设置为 1。按照 slope = 0.5的期望延迟梯度趋势斜率构造了 41 个包组,测试输出如下:
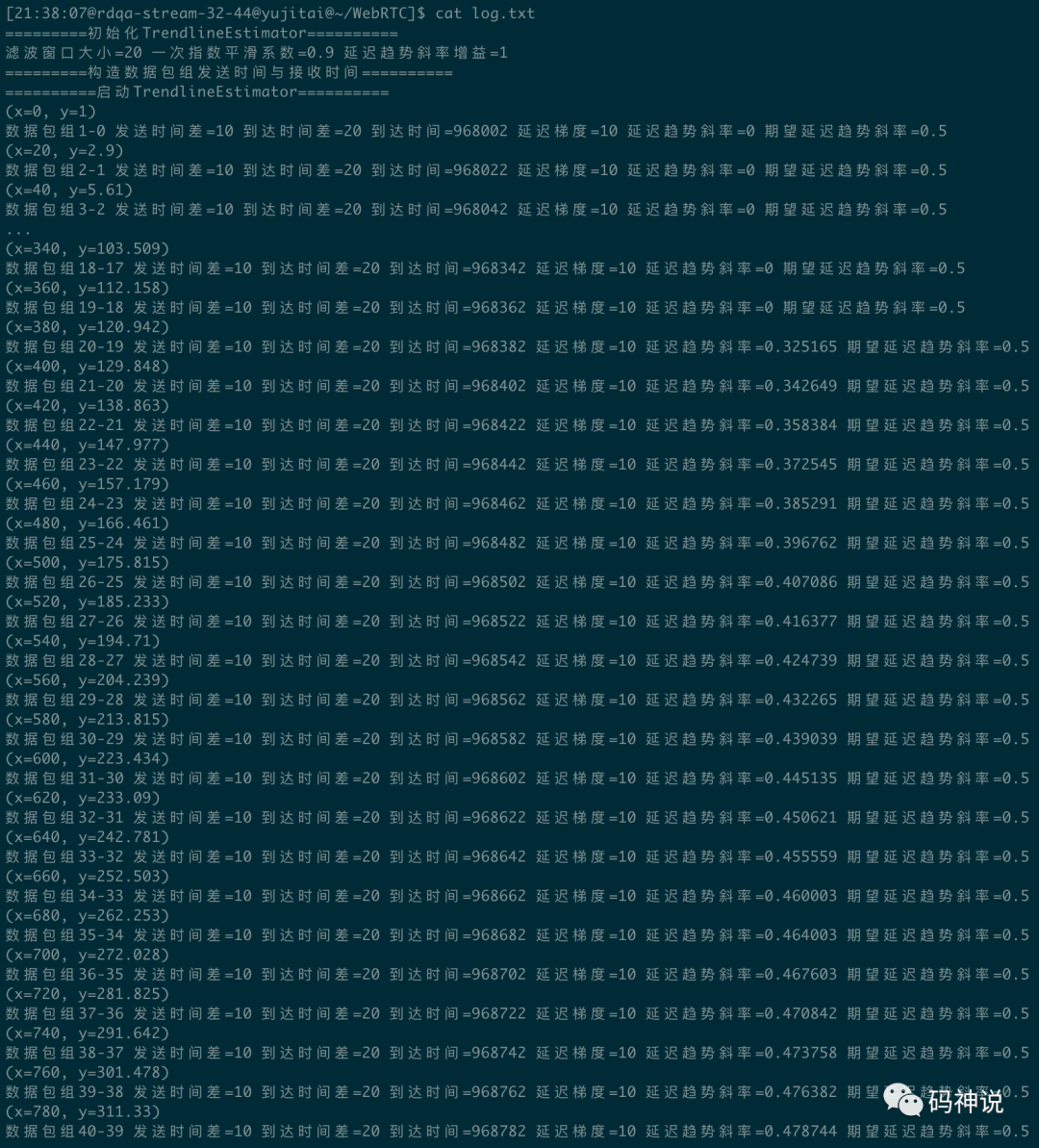
当样本点到达窗口大小 20 时,开始线性回归求解延迟梯度趋势斜率,x 代表包组到达时间与首个包组到达时间的差值,y 代表延迟梯度平滑值。可以看到,随着样本数量增多,斜率值逼近期望值 0.5。
为了有更直观的认识,我将测试数据导入 Minitab Express,进行一次指数平滑计算,如下图:
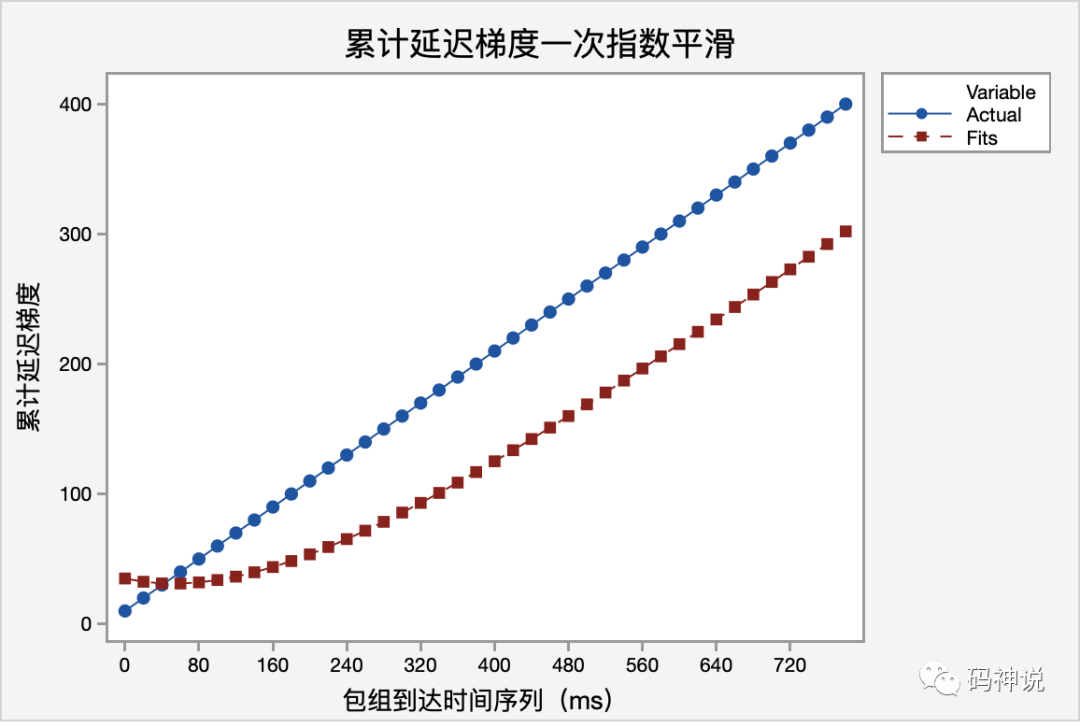
可以看到,一次指数平滑法进行预测,预测趋势与实际变动趋势一致,但预测值比实际值滞后,这是指数平滑法的一个缺点。一次指数平滑法优点在于它在计算中将所有 的观察值考虑在内,对各期按时期的远近赋予不同的权重,使预测值更接近实际观察值。
继续对计算完成的延迟梯度的平滑值进行简单的线性回归,如下图:
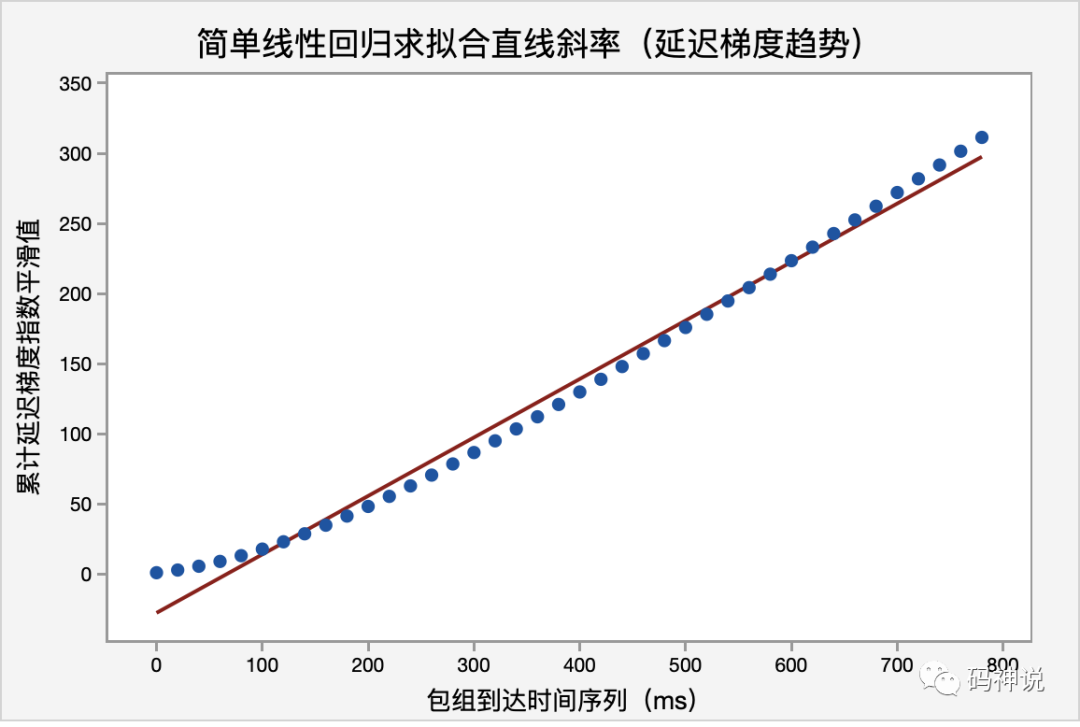
回归公式(Regression Equation):C3 = − 27.641 + 0.416902C1,求得的拟合直线的斜率为0.416902,加大样本的数据量,线性回归模型的预测会更加接近 0.5。
至此,延迟梯度趋势的计算过程介绍完毕,这个趋势值要与动态阈值进行比较,以检测网络带宽使用是否过载,下一篇会介绍这个过程,感谢阅读。
参考资料
[1]指数平滑法: https://baike.baidu.com/item/指数平滑法
[2]最小二乘法: https://baike.baidu.com/item/最小二乘法/2522346?fr=aladdin
本文是
WebRTC 拥塞控制第 3 篇
- 导读
- 网络带宽使用状态
- 自适应阈值的设计
- 为什么要动态自适应?
- 阈值自适应算法
- 源码分析
- Detect 函数
- UpdateThreshold 函数
- 测试用例
导读
上一篇介绍了 Trendline 滤波器计算延迟梯度趋势的过程,求得了最终值 trendline_slope。接下来,就要用这个斜率值与阈值进行比较,从而检测网络带宽的使用状态,比如是否过载。实际的带宽检测过程涉及到:调整延迟梯度斜率值、过载触发条件、阈值自适应,本篇将介绍这个过程。
网络带宽使用状态
WebRTC 定义了三种网络带宽的使用状态:Normal、Underuse、Overuse,即正常、低载、过载。
enum class BandwidthUsage {
kBwNormal = 0,
kBwUnderusing = 1,
kBwOverusing = 2,
};
下图展示了过载检测中三种信号的产生机制,其中,上下两条红色曲线表示动态阈值 ,蓝色曲线表示调整后的延迟梯度斜率值 。
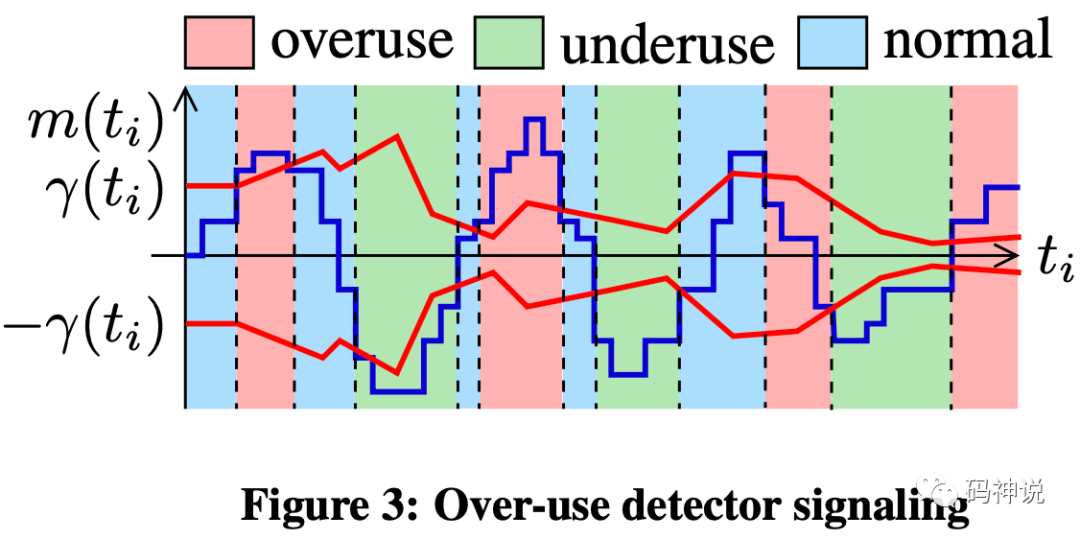
可知,网络带宽使用状态的判定方法为:
> ,overuse < -,underuse -,normal
自适应阈值的设计
为什么要动态自适应?
- 使用太大的阈值 ,那么当检测到过载信号时队列延迟可能已经很大了,或者根本检测不到网络拥塞,算法不够灵敏。
- 使用太小的阈值 ,对于很小的延迟梯度趋势 的增长,可能会被判定为网络带宽过载,使得发送码率降低,算法过于敏感。
- 固定的阈值会导致与 TCP(采用基于丢包的拥塞控制)的竞争中被饿死,要保证内部协议公平性(Intra-protocol fairness)。
比如,在 GCC 流与 TCP 流共存的场景下,延迟梯度 ,如果 ,那么 GCC 流会受到 TCP 流的过高的延迟梯度的影响,连续触发过载信号,降低自己的发送码率,导致 GCC 流的接收者被 "饿死"。Gcc Analysis[1] 解释了这个问题:
adaptive threshold is able to solve the starvation issue and allows the GCC flow to share the bottleneck fairly with the concurrent TCP flow,γ(t) follows m(t) with a smaller time constant which avoids the generation of a large number of consecutive overuse signals and prevents the starvation of the GCC flow.
理想的网络环境中,延迟梯度为 0,而在实际的网络环境中,延迟梯度则是不断变化的,让阈值跟随延迟梯度的变化而进行动态调整,可以降低 GCC 算法对延迟梯度变化的敏感度。
阈值自适应算法
GCC 提出的阈值自适应算法公式如下:
其中,,代表包组到达时间差,即距上一次阈值更新的时间差。 代表阈值的增长率(有可能负增长),增长的基准值是当前调整后的延迟梯度趋势值与当前阈值的差 - 。
系数按如下公式取值:
和 决定了阈值的减少和增加的速度。当延迟梯度斜率值 在阈值范围 内时,要降低阈值,否则,要升高阈值。总之,阈值动态调整的原则是: 随 而动。
GCC 草案[2] 建议 和 的取值分别是 0.00018 和 0.01,即阈值的增长速率要大于阈值的降低速率。上文已经解释了这样做的目的:降低过载检测算法的敏感度,保证在和 TCP 的竞争中的公平性。
源码分析
基于 WebRTC 71 版本。
网络带宽的过载检测与动态阈值的更新也是在 TrendlineEstimator 类中实现的,函数声明如下:
class TrendlineEstimator {
private:
void Detect(double trend,
double ts_delta,
int64_t now_ms);
void UpdateThreshold(
double modified_trend,
int64_t now_ms);
};
每个数据包组(除了首个包组)的到来都会触发过载检测和阈值的动态更新。
Detect 函数
该函数输入延迟梯度趋势的值、包组的发送时间差、包组的到达时间,从而评估网络带宽的使用状态,比如是否过载?
- 对延迟梯度趋势斜率值 进行调整。
constexpr int kMinNumDeltas = 60;
const double modified_trend =
std::min(num_of_deltas_, kMinNumDeltas) *
trend * threshold_gain_;
num_of_deltas_ 表示包组间延迟梯度计算的次数,取值范围是 [2, 60],threshold_gain_ 是 Trendline 滤波器的增益参数,其默认值为 4,这两个变量都会对延迟梯度趋势值进行放大。
这里的关键就在于为何要放大 ?
是一个斜率值,取值范围 (-1, 1),这个值很小,而阈值 要跟随 的变化而变化,这可能导致 很容易的超过 从而触发连续的过载信号。放大 可以使得算法不会因为 的波动而过于敏感。
过载信号触发条件
延迟梯度斜率值 > 当前阈值
- 过载总时长 > kOverUsingTimeThreshold(10ms)
- 过载次数 >= 1
- 当前延迟梯度斜率值 > 上一次的延迟梯度斜率值,即延迟在不断恶化。
if (modified_trend > threshold_) {
if (time_over_using_ == -1) {
time_over_using_ = ts_delta / 2;
} else {
time_over_using_ += ts_delta;
}
overuse_counter_++;
if (time_over_using_ >
overusing_time_threshold_ &&
overuse_counter_ > 1) {
if (trend >= prev_trend_) {
time_over_using_ = 0;
overuse_counter_ = 0;
hypothesis_ =
BandwidthUsage::kBwOverusing;
}
}
}
值得一提的是,源码关于过载时间的计算是:过载时长等于包组发送时间差值send_delta_ms的累加。但是在首次检测到过载时,过载时长会初始化为包组发送时间差的一半,我把这个做法理解为一种类似于 TCP 的慢启动策略。注意,在满足所有条件触发过载信号后,过载时长与过载次数这两个变量要重置为 0。
UpdateThreshold 函数
该函数动态更新延迟梯度趋势的阈值。
当延迟梯度斜率和阈值的差值大于 kMaxAdaptOffsetMs(15) 时,不更新阈值。
if (fabs(modified_trend) > threshold_ +
kMaxAdaptOffsetMs) {
last_update_ms_ = now_ms;
return;
}
这种情况可能发生在这样的场景:因为某些原因,网络链路的容量突然降低,导致延迟梯度瞬间急剧增长。
接下来就是新阈值的计算过程了,完全参考公式 (1)。注意,WebRTC 对 和 的取值分别是 0.0087 和 0.039,并非 GCC 草案的建议值。
int64_t time_delta_ms = std::min(now_ms - last_update_ms_, kMaxTimeDeltaMs);
threshold_ += k * (fabs(modified_trend) - threshold_) * time_delta_ms;
threshold_ = rtc::SafeClamp(threshold_, 6.f, 600.f);
还有两点值得一提:
- 阈值计算公式中的
time_delta_ms指的是包组的到达时间差arrival_delta_ms,而上文中过载时长则是根据包组的发送时间差send_delta_ms来计算。 - 初始阈值设置为 12.5,计算后的阈值需要控制到 [6, 600] 这个区间内。GCC 草案解释了这么做的原因:
since a too small del_var_th(i) can cause the detector to become overly sensitive.
测试用例
继续使用了上篇的测试用例,一共构造了 41 个包组,来模拟过载检测的过程,输出如下:

观察日志输出,有几个比较关键的点:
- 初始的延迟梯度阈值设置为 12.5,随后开始动态自适应,一直调整到了 GCC 草案建议的阈值范围的最小值 6,在包组 21 到来并开始计算延迟梯度斜率之前,保持不变。
- 包组 21 到来之前,样本点数量未达到窗口大小,虽然不会进行延迟梯度斜率的计算,但是会执行过载检测和动态阈值更新,由于斜率初始化为 0,小于阈值 6,故认为网络状态正常。
- 包组 21 到来之后,样本点达到窗口大小 20,开始计算延迟梯度斜率,可以看出,阈值跟随斜率而变动,但由于斜率一直大于阈值,故网络一直处于过载状态。
至此,网络带宽过载检测的内容介绍完毕。下一篇将介绍三种网络带宽使用状态的信号(normal、overuse、underuse)如何驱动 AIMD 码率控制器工作,从而有效的进行拥塞控制,感谢阅读。
参考资料
[1] Gcc Analysis: https://c3lab.poliba.it/images/6/65/Gcc-analysis.pdf
[2]GCC 草案: https://tools.ietf.org/html/draft-ietf-rmcat-gcc-02#section-5.4