WebRTC音视频同步机制
原文出处:WebRTC音视频同步机制实现分析
音视频同步事关多媒体产品的最直观用户体验,是音视频媒体数据传输和渲染播放的最基本质量保证。音视频如果不同步,有可能造成延迟、卡顿等非常影响用户体验的现象。因此,它非常重要。一般说来,音视频同步维护媒体数据的时间线顺序,即发送端在某一时刻采集的音视频数据,接收端在另一时刻同时播放和渲染。
本文在深入研究WebRTC源代码的基础上,分析其音视频同步的实现细节,包括RTP时间戳的产生,RTCP SR报文的构造、发送和接收,音视频同步的初始化和同步过程。RTP时间戳是RTP数据包的基石,而RTCP SR报文是时间戳和NTP时间之间进行转换的基准。下面详细描述之。
1 RTP时间戳的产生
“The timestamp reflects the sampling instant of the first octet in the RTP data packet. The sampling instant must be derived from a clock that increments monotonically and linearly in time to allow synchronization and jitter calculations. The resolution of the clock must be sufficient for the desired synchronization accuracy and for measuring packet arrival jitter (one tick pervideo frame is typically not sufficient). ”
由以上定义可知,RTP时间戳反映RTP负载数据的采样时刻,从单调线性递增的时钟中获取。时钟的精度由RTP负载数据的采样频率决定,比如视频的采样频率一般是90khz,那么时间戳增加1,则实际时间增加1/90000秒。
下面回到WebRTC源代码内部,以视频采集为例分析RTP时间戳的产生过程,如图1所示。

视频采集线程以帧为基本单位采集视频数据,视频帧从系统API被采集出来,经过初步加工之后到达VideoCaptureImpl::IncomingFrame()函数,设置render_time_ms_为当时间(其实就是采样时刻)。
执行流程到达VideoCaptureInput::IncomingCapturedFrame()函数后,在该函数设置视频帧的timestamp,ntp_time_ms和render_time_ms。其中render_time_ms为当前时间,以毫秒为单位;ntp_time_ms为采样时刻的绝对时间表示,以毫秒为单位;timestamp则是采样时间的时间戳表示,是ntp_time_ms和采样频率frequency的乘积,以1/frequency秒为单位。由此可知,timestamp和ntp_time_ms是同一采样时刻的不同表示。
接下来视频帧经过编码器编码之后,发送到RTP模块进行RTP打包和发送。构造RTP数据包头部时调用RtpSender::BuildRTPheader()函数,确定时间戳的最终值为rtphdr->timestamp = start_timestamp + timestamp,其中start_timestamp是RtpSender在初始化时设置的初始时间戳。RTP报文构造完毕之后,经由网络发送到对端。
2 SR报文构造和收发
由上一节论述可知,NTP时间和RTP时间戳是同一时刻的不同表示,区别在于精度不同。NTP时间是绝对时间,以毫秒为精度,而RTP时间戳则和媒体的采样频率有关。因此,我们需要维护一个NTP时间和RTP时间戳的对应关系,该用以对两种时间的进行转换。RTCP协议定义的SR报文维护了这种对应关系,下面详细描述。
2.1 时间戳初始化
在初始化阶段,ModuleRtpRtcpImpl::SetSendingStatus()函数会获取当前NTP时间的时间戳表示(ntp_time * frequency),作为时间戳初始值分别设置RTPSender和RTCPSender的start_timestamp参数(即上节在确定RTP数据包头部时间戳时的初始值)。
视频数据在编码完之后发往RTP模块构造RTP报文时,视频帧的时间戳timestamp和本地时间capture_time_ms通过RTCPSender::SetLastRtpTime()函数记录到RTCPSender对象的last_rtp_timestamp和last_frame_capture_time_ms参数中,以将来将来构造RTCP SR报文使用。
2.2 SR报文构造及发送
WebRTC内部通过ModuleProcessThread线程周期性发送RTCP报文,其中SR报文通过RTCPSender::BuildSR(ctx)构造。其中ctx中包含当前时刻的NTP时间,作为SR报文[1]中的NTP时间。接下来需要计算出此刻对应的RTP时间戳,即假设此刻有一帧数据刚好被采样,则其时间戳为:
rtp_timestamp = start_timestamp_ + last_rtp_timestamp_ +
(clock_->TimeInMilliseconds() - last_frame_capture_time_ms_) *
(ctx.feedback_state_.frequency_hz / 1000);
至此,NTP时间和RTP时间戳全部齐活儿,就可以构造SR报文进行发送了。
2.3 SR接收
接收端在收到SR报文后,把其中包含的NTP时间和RTP时间戳记录在RTCPSenderInfo对象中,供其他模块获取使用。比如通过RTCPReceiver::NTP()或者SenderInfoReceived()函数获取。
3 音视频同步
前面两节做必要的铺垫后,本节详细分析WebRTC内部的音视频同步过程。
3.1 初始化配置
音视频同步的核心就是根据媒体负载所携带RTP时间戳进行同步。在WebRTC内部,同步的基本对象是AudioReceiveStream/VideoReceiveStream,根据sync_group进行相互配对。同步的初始化设置过程如图2所示。
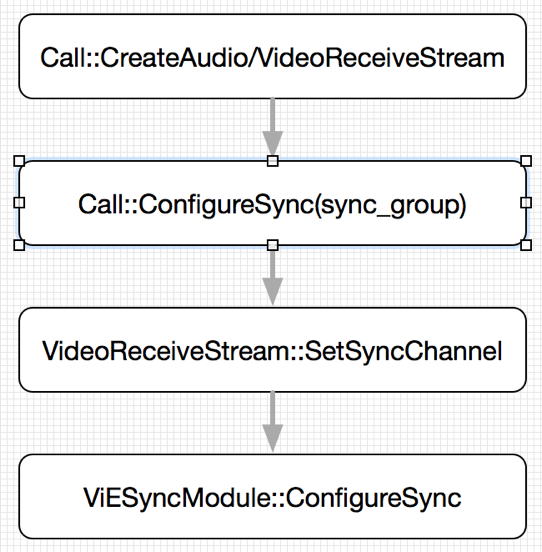
Call对象在创建Audio/VideoReceiveStream时,调用ConfigureSync()进行音视频同步的配置。配置参数为sync_group,该参数在PeerConnectionFactory在创建MediaStream时指定。在ConfigureSync()函数内部,通过sync_group查找得到AudioReceiveStream,然后再在video_receive_streams中查找得到VideoReceiveStream。得到两个媒体流,调用VideoReceiveStream::SetSyncChannel同步,在ViESyncModule::ConfigureSync()函数中把音视频参数进行保存,包括音频的voe_channel_id、voe_sync_interface, 和视频的video_rtp_receiver、video_rtp_rtcp。
3.2 同步过程
音视频的同步过程在ModuleProcessThread线程中执行。ViESyncModule作为一个模块注册到ModuleProcessThread线程中,其Process()函数被该线程周期性调用,实现音视频同步操作。
音视频同步的核心思想就是以RTCP SR报文中携带的NTP时间和RTP时间戳作为时间基准,以AudioReceiveStream和VideoReceiveStream各自收到最新RTP时间戳timestamp和对应的本地时间receive_time_ms作为参数,计算音视频流的相对延迟,然后结合音视频的当前延迟计算最终的目标延迟,最后把目标延迟发送到音视频模块进行设置。目标延迟作为音视频渲染时的延迟下限值。整个过程如图3所示。
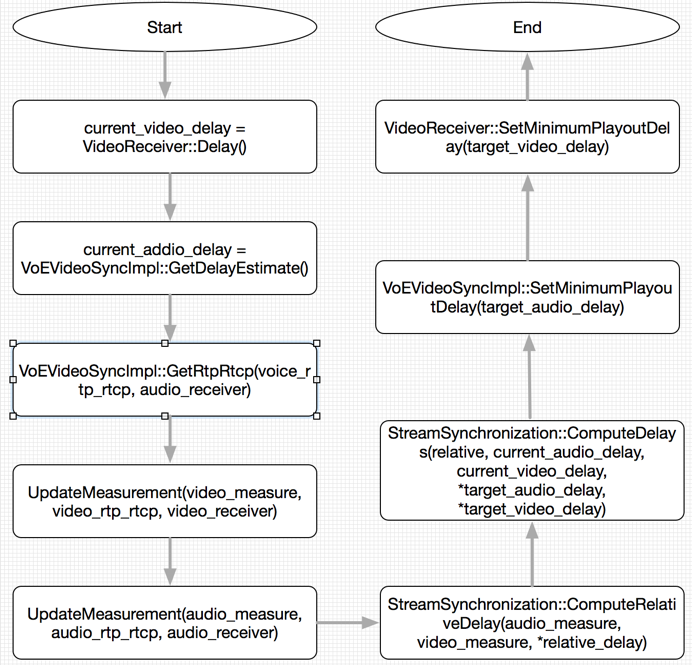
首先,从VideoReceiver获得当前视频延迟current_video_delay,即video_jitter_delay,decode_delay和render_delay的总和。然后从VoEVideoSyncImpl获得当前音频延迟current_audio_delay,即audio_jitter_delay和playout_delay的总和。
然后,音视频分别以各自的rtp_rtcp和rtp_receiver更新各自的measure。其基本操作包括:从rtp_receiver获取最新接收到的RTP报文的RTP时间戳latest_timestamp和对应的本地接收时刻latest_receive_time_ms,从rtp_rtcp获取最新接收的RTCP SR报文中的NTP时间和RTP时间戳。然后把这些数据都存储到measure中。注意measure中保存最新两对RTCP SR报文中的NTP时间和RTP时间戳,用来在下一步计算媒体流的采样频率。
接下来,计算最新收到的音视频数据的相对延迟。其基本流程如下:首先得到最新收到RTP时间戳latest_timestamp对应的NTP时间latest_capture_time。这里用到measure中存储的latest_timestamp和RTCP SR的NTP时间和RTP时间戳timestamp,利用两对数值计算得到采样频率frequency,然后有latest_capture_time = latest_timestamp / frequency,得到单位为毫秒的采样时间。最后得到音视频的相对延迟:
relative_delay = video_measure.latest_receive_time_ms -
audio_measure.latest_receive_time_ms -
(video_last_capture_time - audio_last_capture_time);
至此,我们得到三个重要参数:视频当前延迟current_video_delay, 音频当前延迟current_audio_delay和相对延迟relative_delay。接下来用这三个参数计算音视频的目标延迟:首先计算总相对延迟current_diff = current_video_delay – current_audio_delay + relative_delay,根据历史值对其求加权平均值。如果current_diff >0,表明当前视频延迟比音频延迟长,需要减小视频延迟或者增大音频延迟;反之如果current < 0,则需要增大视频延迟或者减小音频延迟。经过此番调整之后,我们得到音视频的目标延迟audio_target_delay和video_target_delay。
最后,我们把得到的目标延迟audio_target_delay和video_target_delay分别设置到音视频模块中,作为将来渲染延迟的下限值。到此为止,一次音视频同步操作完成。该操作在ModuleProcessThread线程中会周期性执行。
4 总结
本文详细分析了WebRTC内部音视频同步的实现细节,包括RTP时间戳的产生,RTCP SR报文的构造、发送和接收,音视频同步的初始化和同步过程。通过本文,对RTP协议、流媒体通信和音视频同步有更深入的认识。
参考文献
[1] RFC3550 - RTP: A Transport Protocol for Real-Time Applications
原文出处:WebRTC音视频同步详解
1 WebRTC版本
m74
2 时间戳
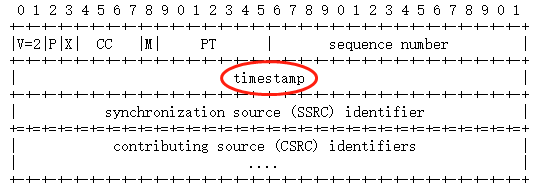
音视频采样后会给每个音频采样、视频帧打一个时间戳,打包成RTP后放在RTP头中,称为RTP时间戳,RTP时间戳的单位依赖于音视频流各自的采样率。
RTP Header格式如下:
2.1 视频时间戳
视频时间戳的单位为1/90000秒,但是90000并不是视频的采样率,而只是一个单位,帧率才是视频的采样率。
不同打包方式下的时间戳:
- Single Nalu:如果一个视频帧包含1个NALU,可以单独打包成一个RTP包,那么RTP时间戳就对应这个帧的采集时间;
- FU-A:如果一个视频帧的NALU过大(超过MTU)需要拆分成多个包,可以使用FU-A方式来拆分并打到不同的RTP包里,那么这几个包的RTP时间戳是一样的;
- STAP-A:如果某帧较大不能单独打包,但是该帧内部单独的NALU比较小,可以使用STAP-A方式合并多个NALU打包发送,但是这些NALU的时间戳必须一致,打包后的RTP时间戳也必须一致。
2.2 音频时间戳
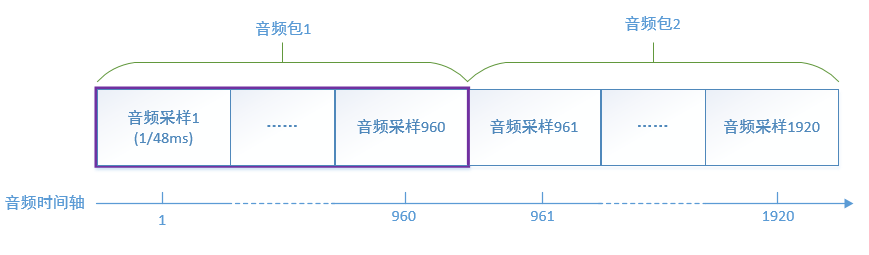
音频时间戳的单位就是采样率的倒数,例如采样率48000,那么1秒就有48000个采样,每个采样1/48ms,每个采样对应一个时间戳。RTP音频包一般打包20ms的数据,对应的采样数为 48000 * 20 / 1000 = 960,也就是说每个音频包里携带960个音频采样,因为1个采样对应1个时间戳,那么相邻两个音频RTP包的时间戳之差就是960。
2.3 NTP时间戳
RTP的标准并没有规定音频、视频流的第一个包必须同时采集、发送,也就是说开始的一小段时间内可能只有音频或者视频,再加上可能的网络丢包,音频或者视频流的开始若干包可能丢失,那么不能简单认为接收端收到的第一个音频包和视频包是对齐的,需要一个共同的时间基准来做时间对齐,这就是NTP时间戳的作用。
NTP时间戳是从1900年1月1日00:00:00以来经过的秒数,发送端以一定的频率发送SR(Sender Report)这个RTCP包,分为视频SR和音频SR,SR包内包含一个RTP时间戳和对应的NTP时间戳,接收端收到后就可以确定某个流的RTP时间戳和NTP时间戳的对应关系,这样音频、视频的时间戳就可以统一到同一个时间基准下。
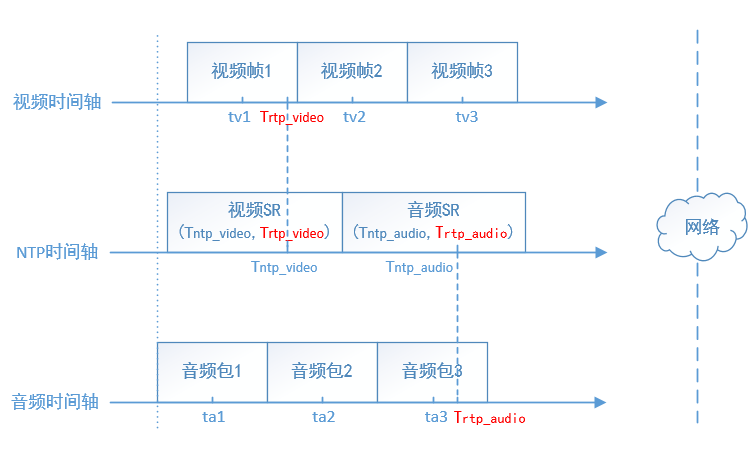
如上图,发送端的音视频流并没有对齐,但是周期地发送SR包,接收端得到音视频SR包的RTP时间戳、NTP时间戳后通过线性回归得到NTP时间戳Tntp和RTP时间戳Trtp时间戳的对应关系:
- Tntp_audio = f(Trtp_audio)
- Trtp_video = f(Trtp_video)
其中Tntp = f(Trtp) = kTrtp + b 为线性函数,这样接收端每收到一个RTP包,都可以将RTP时间戳换算成NTP时间戳,从而在同一时间基准下进行音视频同步。
2 延迟
视频延迟的单位为ms,对音频来说,由于采样跟时间戳一一对应,所有时间延迟都会被换算成了缓存大小(音频包的个数),其值为:
音频延迟 = 时间延迟 << 8 / 20
也就是说,对48000的采样率,960个采样对应一个20ms包,时间延迟 / 20ms等于延迟了几个包,左移8(乘以256)也就是所谓的Q8,是为了用定点数表示一定精度的浮点数。
3 同步
3.1 一张图看懂音视频同步
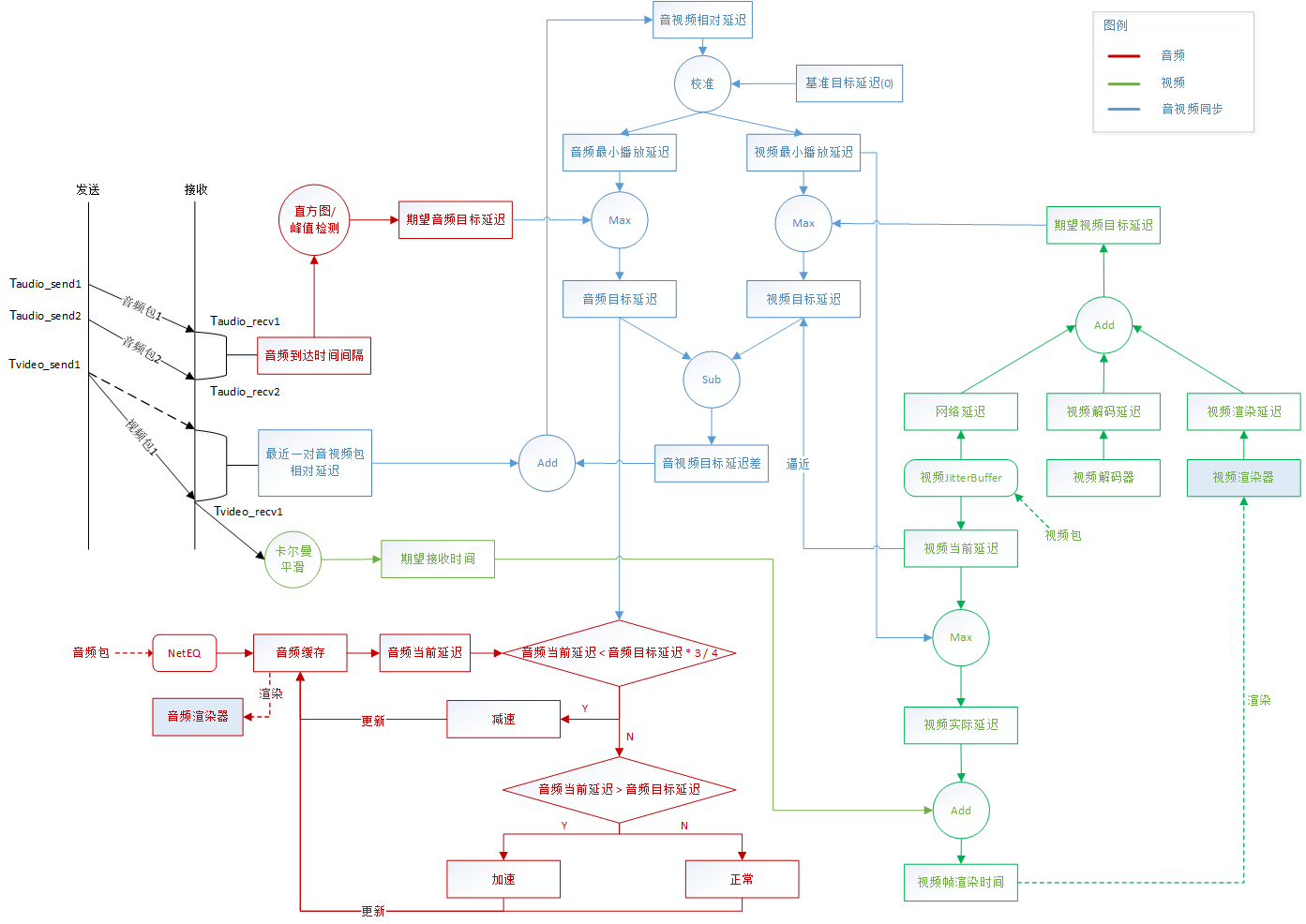
首先接收端需要按照音、视频各自的帧率来解码、渲染,保证流畅地播放,在这个基础上,需要计算音视频两个流目前的相对延迟,分别给音、视频两个流施加一定的延迟,保证音视频的同步。
延迟播放,也就意味着在缓存中暂时存放数据,延迟换流畅。
对音频来说,施加的延迟直接影响到音频缓存的大小,音频缓存的大小就体现了音频的播放延迟。
对视频来说,施加的延迟影响到视频帧的渲染时间,通过比较渲染时间和当前时间来决定解码后的视频帧需要等待还是需要立刻渲染。
正确设置好音视频各自的播放延迟后,音视频达到同步的效果。
可以看到,音视频同步中主要需要做到三点:
- 正确计算音视频相对延迟;
- 正确计算音视频各自的网络目标时延;
- 正确设置音视频各自的播放延迟。
3.2 音视频相对延迟
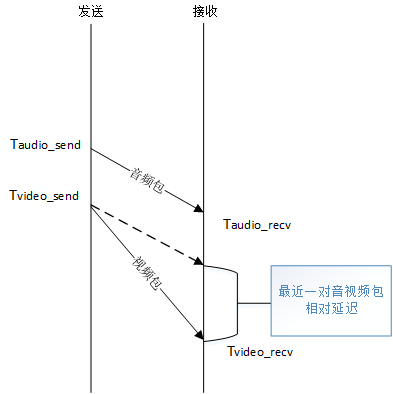
如上图:
最近一对音视频包的相对延迟 = (Tvideo_recv - Taudio_recv) - (Tvideo_send - Taudio_send)
其中Tvideo_recv、Taudio_recv分别是接收端收到视频包、音频包记录的本地时间,可以直接获取,而Tvideo_send,Taudio_send作为视频包、音频包的发送时间无法直接获取,因为接收到的RTP包只有RTP时间戳,无法直接作为本地时间来与Tvideo_recv、Taudio_recv进行运算,这时候就需要SR包中携带的NTP时间戳和RTP的对应关系来进行换算。
通过SR包中的NTP时间戳和RTP时间戳做线性回归(通过采样归纳映射关系)得到两者的线性关系:
Tntp = f(Trtp) = kTrtp + b
这样RTP时间戳就可以直接转化为NTP时间戳,也就是发送端本地时间。从最近一对音视频包相对延迟的计算公式可以看出,分别对发送端和接收端的时间做运算,两者都在同一时间基准,可以排除NTP时间同步问题的影响。
stream_synchronization.cc:34 StreamSynchronization::ComputeRelativeDelay
3.3 期望目标延迟
期望目标延迟就是保证音频流、视频流各自流畅播放的期望延迟。
从3.1的图可以看出,对视频来说,期望目标延迟 = 网络延迟 + 解码延迟 + 渲染延迟,对音频来说,期望目标延迟 = 前后两个音频包之间的到达间隔的期望值。在接收时间的基础上,加上各自的期望目标延迟进行播放,可以保证音频、视频流可以按照各自的步调进行流畅无卡顿的播放。
既要流畅播放又要进行同步,这就是为什么在计算音视频流相对延迟的时候要同时考虑最近一对音视频包的相对延迟又要考虑音视频目标延迟差的原因。
stream_synchronization.cc:34 StreamSynchronization::ComputeRelativeDelay
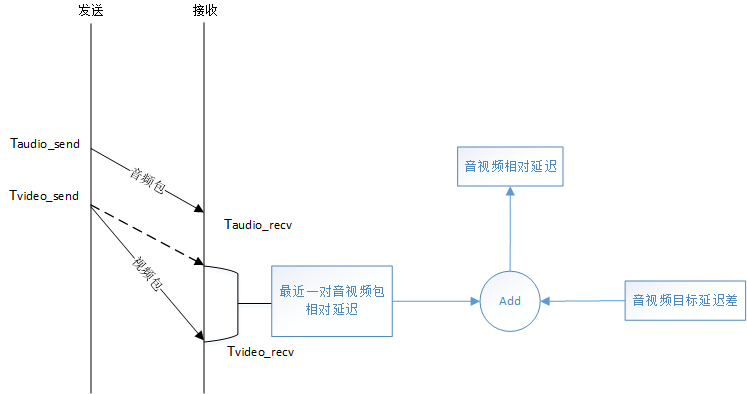
当前音视频流相对延迟 = 最近一对音视频包的相对延迟 + 音视频目标延迟之差
3.3.1 期望视频目标延迟
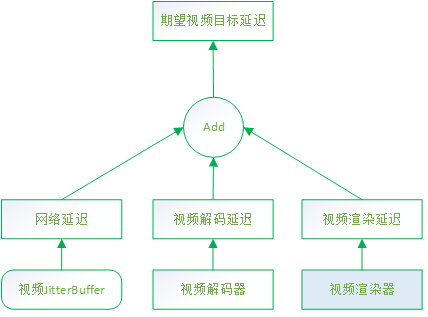
期望视频目标延迟 = 网络延迟 + 解码延迟 + 渲染延迟
网络延迟其实就是视频JittterBuffer输出的延迟googJitterBufferMs,可以参考我的文章《WebRTC视频JitterBuffer详解》7.1节[抖动计算],简单说就是通过卡尔曼滤波器计算视频帧的到达延迟差(抖动),作为网络的延迟。
解码时间的统计方法:统计最近最多10000次解码的时间消耗,计算其95百分位数Tdecode,也就是说最近95%的帧的解码时间都小于Tdecode,以之作为解码时间。
视频渲染延迟默认是一个定值:10ms。
timing.cc:210 VCMTiming::TargetVideoDelay
3.3.2 期望音频目标延迟
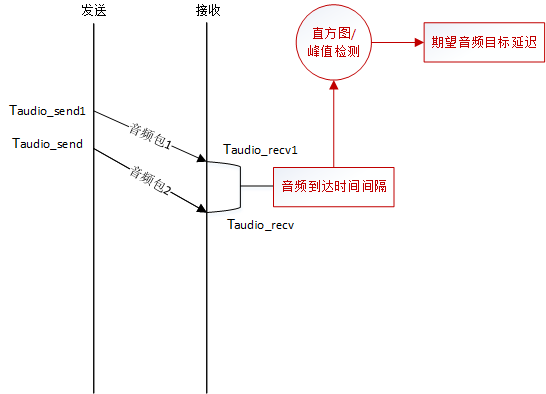
期望音频目标延迟的算法和视频解码时间的算法类似,但是用直方图来存放最近的65个音频包的到达间隔,取95百分位数Taudio_target_delay,也就是说最近一段时间内,有95%的音频包的到达间隔都小于Taudio_target_delay。同时考虑到网络突发的可能,增加了峰值检测,去掉异常的时间间隔。
取这个值作为期望目标延迟来影响音频的播放,可以保证绝大多数情况下音频流的流畅。
neteq_impl.cc:311 NetEqImpl::FilteredCurrentDelayMs
3.4 音视频同步
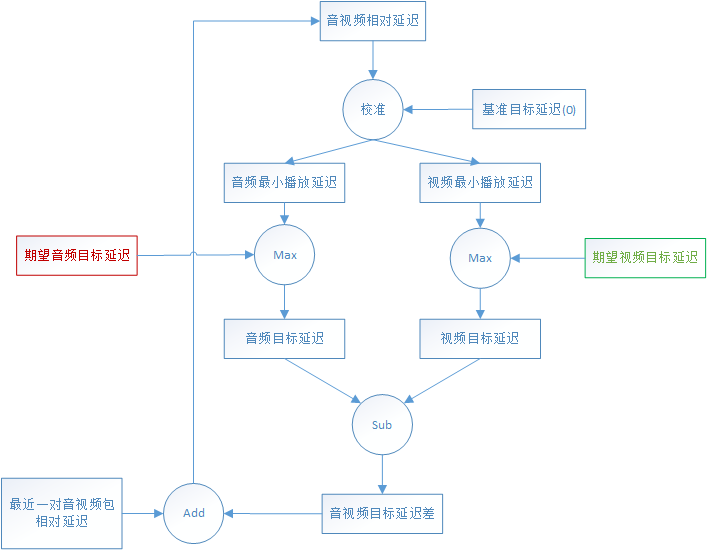
同步器的外部输入有:
- 期望音频目标延迟,以该延迟播放,音频是流畅的;
- 期望视频目标延迟,以该延迟播放,视频是流畅的;
- 最近一对音视频包的相对延迟。
最近一对音视频包的相对延迟与音视频的目标延迟差之和,得到当前时刻的音视频相对延迟,也就是音、视频流目前的时间偏差。
- 当相对延迟 > 0,说明视频比较慢,视频延迟与基准(
base_target_delay_ms_,默认0)比较:extra_video_delay_ms > base_target_delay_ms_,减小视频流延迟,设置音频延迟为基准;extra_video_delay_ms <= base_target_delay_ms_,增大音频流延迟,设置视频延迟为基准;
- 当相对延迟 < 0,说明音频比较慢,音频延迟与基准(
base_target_delay_ms_,默认0)比较:extra_audio_delay_ms > base_target_delay_ms_,减小音频流延迟,设置视频延迟为基准;extra_audio_delay_ms <= base_target_delay_ms_,增大视频流延迟,设置音频延迟为基准。
使用这个算法,可以保证音、频流的延迟都趋向于逼近基准,不会出现无限增加、减小的情况。同时,一次延迟增大、减小的延迟diff_ms被设置为相对延迟的一半,并限制在80ms范围之内,也就是说WebRTC对一次同步的追赶时间做了限制,一次延迟增大、减小最大只能是80ms,因此如果某个时刻某个流发生了较大抖动,需要一段时间另外一个流才能同步。
经过了以上校准之后,输出了同步后音频、视频流各自的最小播放延迟。
extra_audio_delay_ms -> 音频最小播放延迟
extra_video_delay_ms -> 视频最小播放延迟
理论上将这两个播放延迟分别施加到音、视频流后,这两个流就是同步的,再与音、视频流各自期望目标延迟取最大值,得到音、视频流的最优目标延迟(googTargetDelayMs),施加在音、视频流上,可以保证做到既同步、又流畅。
stream_synchronization.cc:64 StreamSynchronization::ComputeDelays
3.5 渲染时间
3.5.1 视频渲染时间
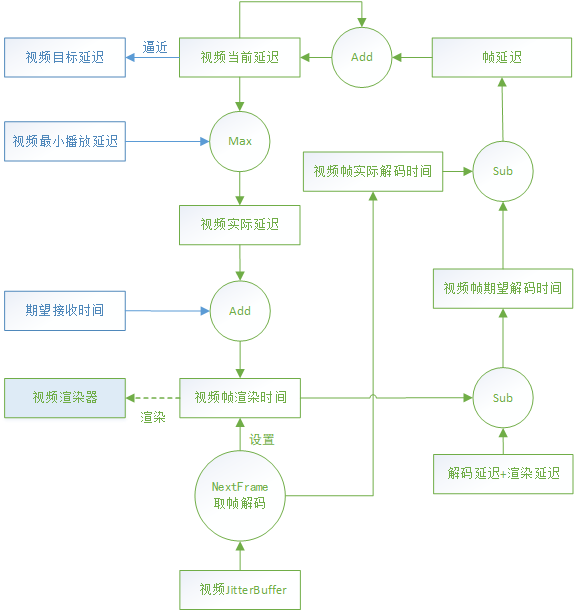
该图是计算视频渲染时间的总体描述图,仍然比较复杂,以下分几个部分描述。
3.5.1.1 期望接收时间
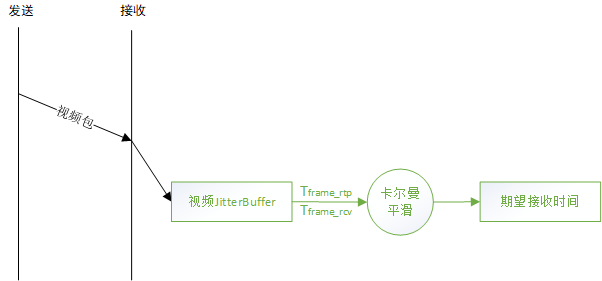
TimestampExtrapolator类负责期望接收时间的产生,视频JitterBuffer(的FrameBuffer)每收到一帧,会记录该帧的RTP时间戳Tframe_rtp和本地接收时间Tframe_rcv,其中第一帧的RTP时间戳为Tfirst_frame_rtp和本地接收时间Tfirst_frame_rcv。
记帧RTP时间戳之差:Tframe_rtp_delta = Tframe_rtp - Tfirst_frame_rtp
帧本地接收时间之差:Tframe_recv_delta = Tframe_recv - Tfirst_frame_rcv
两者为线性关系,期望RTP时间戳之差Tframe_rtp_delta = _w[0] * Tframe_recv_delta + _w[1]
通过卡尔曼滤波器得到线性系数_w[0]、_w[1],进而得到期望接收时间的值:
Tframe_recv = Tfirst_frame_rcv + (Tframe_rtp_delta - _w[1]) / _w[0]
也就是说,卡尔曼滤波器输入视频帧的RTP时间戳和本地接收时间观测值,得到视频帧最优的期望接收时间,用于平滑网络的抖动。
timestamp_extrapolator.cc:137 TimestampExtrapolator::ExtrapolateLocalTime
3.5.1.2 视频当前延迟 - googCurrentDelayMs
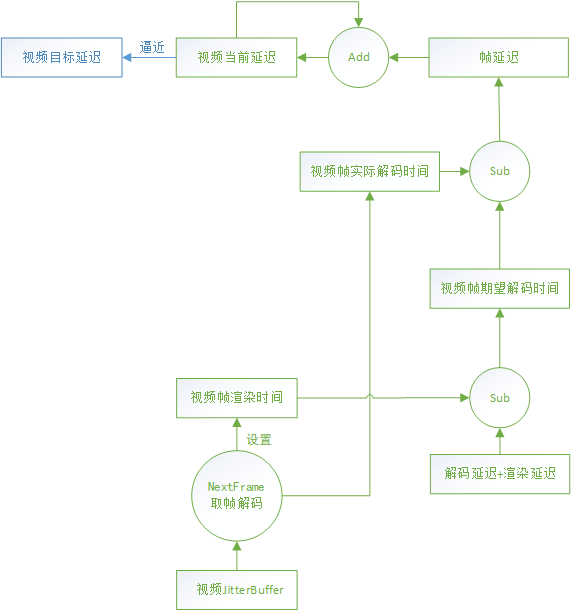
解码器通过视频JitterBuffer的NextFrame方法获取一帧去解码时会设置该帧的期望渲染时间Texpect_render,以及该帧的实际开始解码时间Tactual_decode。
该帧的期望开始解码时间为期望渲染时间减去解码、渲染的延迟:
Texpect_decode = Texpect_render - Tdecode_delay - Trender_delay
那么该帧产生的延迟为实际开始解码时间减去期望开始解码时间:
Tframe_delay = Tactual_decode - Texpect_decode
该帧延迟和上一个时刻的视频当前延迟叠加,如果仍然小于目标延迟,则增长视频当前延迟。
Tcurrent_delay = max(Tcurrent_delay + Tframe_delay, Ttarget_delay)
也就是视频当前延迟以目标延迟为上限逼近目标延迟。
timing.cc:96 VCMTiming::UpdateCurrentDelay
3.5.1.3 计算渲染时间
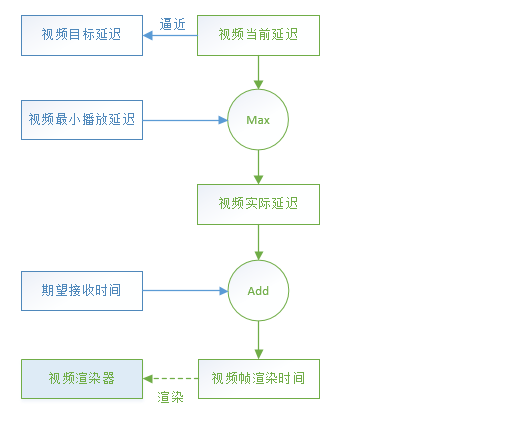
取同步后的延迟作为视频的实际延迟,也就是当前延迟和最小播放延迟的最大者:
Tactual_delay = max(Tcurrent_delay , Tmin_playout_delay)
至此,当前视频帧的期望接收时间Tframe_recv和视频实际延迟Tactual_delay都已经得到,可以计算最终的视频帧渲染时间:
Trender_time = Tframe_recv + Tactual_delay
timing.cc:169 VCMTiming::RenderTimeMs
3.5.2 音频渲染时间
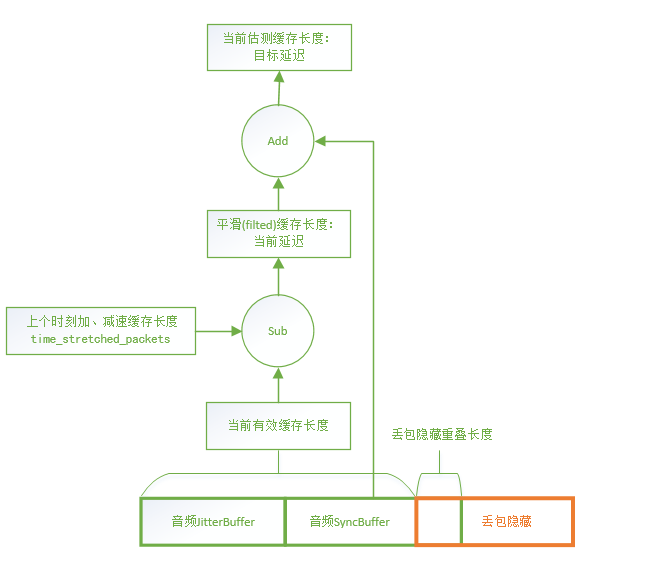
NetEQ中有若干缓存用来暂存数据,主要的是JitterBuffer(PacketBuffer)、SyncBuffer,分别存放解码前和解码后的数据,这些缓存的大小就体现了音频当前的延迟。
NetEQ的BufferLevelFilter类维护音频的当前延迟,音频渲染器每取一次音频数据都根据当前剩余的缓存大小设置一次音频的当前延迟并进行平滑,得到平滑后的当前延迟(googCurrentDelayMs)。
buffer_level_filter.cc:29 BufferLevelFilter::Update
NetEQ的DecisionLogic类比较下一个音频包的时间戳与SynBuffer中的结尾时间戳,如果不相等,也就是不连续,那么需要进行丢包隐藏(Expand/PLC)或者融合(Merge);如果相等,也就是连续,则根据当前缓存的大小与目标延迟大小来决定是对音频数据进行加速、减速,或者正常播放。
decision_logic.cc:100 DecisionLogic::GetDecision
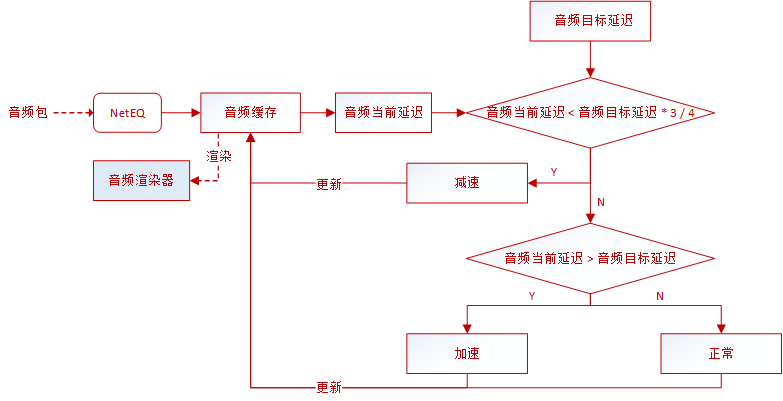
- 如果音频当前延迟 < 3 / 4音频目标延迟,也就是缓存数据较少,需要减速播放等待目标延迟;
- 如果音频当前延迟 > 音频目标延迟,也就是缓存数据过多,需要加速播放追赶目标延迟。
decision_logic.cc:283 DecisionLogic::ExpectedPacketAvailable
音频就是以缓存长度追赶目标延迟的方式达到延迟一定时间的效果,最终和视频的目标延迟对齐后,实现了音视频同步。
原文出处:WebRTC音视频同步原理与实现
所有的基于网络传输的音视频采集播放系统都会存在音视频同步的问题,作为现代互联网实时音视频通信系统的代表,WebRTC 也不例外。本文将对音视频同步的原理以及 WebRTC 的实现做深入分析。
1、时间戳 (timestamp)
同步问题就是快慢的问题,就会牵扯到时间跟音视频流媒体的对应关系,就有了时间戳的概念。
时间戳用来定义媒体负载数据的采样时刻,从单调线性递增的时钟中获取 , 时钟的精度由 RTP 负载数据的采样频率决定。音频和视频的采样频率是不一样的,一般音频的采样频率有 16KHz、44.1KHz、48KHz 等,而视频反映在采样帧率上,一般帧率有 25fps、29.97fps、30fps 等。
习惯上音频的时间戳的增速就是其采样率,比如 16KHz 采样,每 10ms 采集一帧,则下一帧的时间戳,比上一帧的时间戳,从数值上多 16x10=160,即音频时间戳增速为 16/ms。而视频的采样频率习惯上是按照 90KHz 来计算的,就是每秒 90K 个时钟 tick,之所以用 90K 是因为它正好是上面所说的视频帧率的倍数,所以就采用了 90K。所以视频帧的时间戳的增长速率就是 90/ms。
2、时间戳的生成
音频帧时间戳的生成
WebRTC 的音频帧的时间戳,从第一个包为 0,开始累加,每一帧增加 = 编码帧长 (ms) x 采样率 / 1000,如果采样率 16KHz,编码帧长 20ms,则每个音频帧的时间戳递增 20 x 16000/1000 = 320。这里只是说的未打包之前的音频帧的时间戳,而封装到 RTP 包里面的时候,会将这个音频帧的时间戳再累加上一个随机偏移量(构造函数里生成),然后作为此 RTP 包的时间戳,发送出去,如下面代码所示,注意,这个逻辑同样适用于视频包。
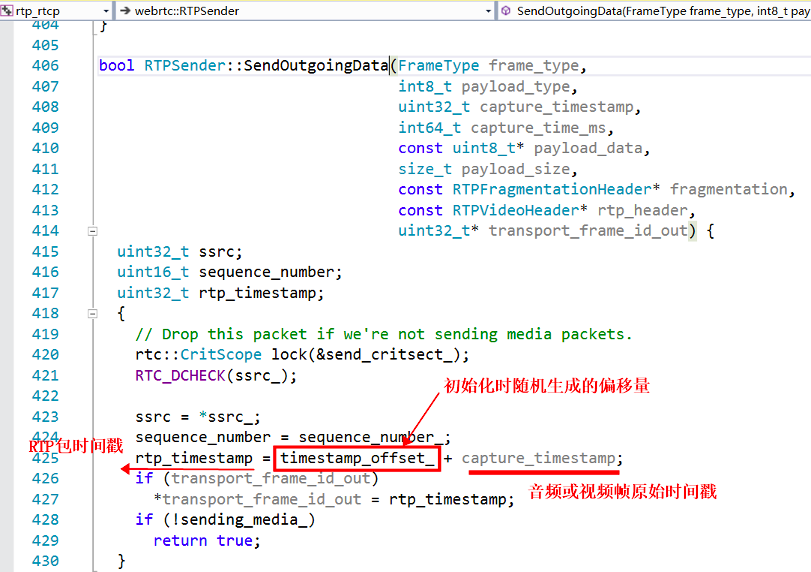
视频帧时间戳的生成
WebRTC 的视频帧,生成机制跟音频帧完全不同。视频帧的时间戳来源于系统时钟,采集完成后至编码之前的某个时刻(这个传递链路非常长,不同配置的视频帧,走不同的逻辑,会有不同的获取位置),获取当前系统的时间 timestamp_us_,然后算出此系统时间对应的 ntp_time_ms_,再根据此 ntp 时间算出原始视频帧的时间戳 timestamp_rtp_,参看下面的代码,计算逻辑也在 OnFrame 这个函数中。
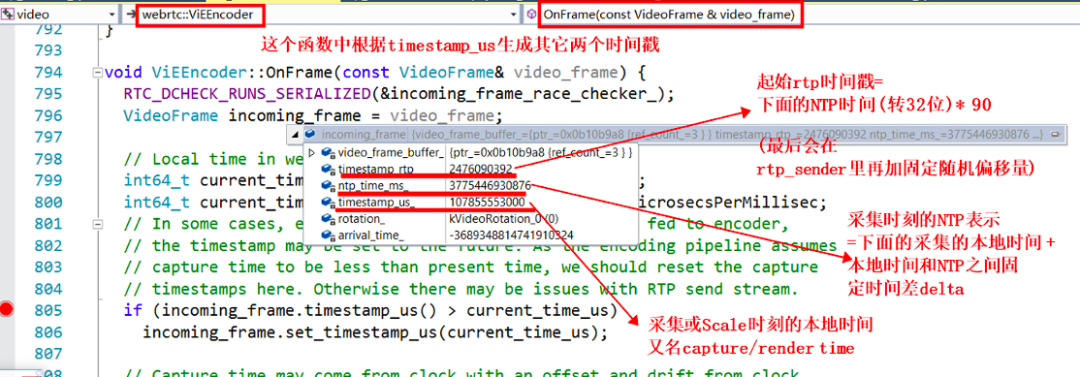
为什么视频帧采用了跟音频帧不同的时间戳计算机制呢?我的理解,一般情况音频的采集设备的采样间隔和时钟精度更加准确,10ms 一帧,每秒是 100 帧,一般不会出现大的抖动,而视频帧的帧间隔时间较大采集精度,每秒 25 帧的话,就是 40ms 一帧。如果还采用音频的按照采样率来递增的话,可能会出现跟实际时钟对不齐的情况,所以就直接每取一帧,按照取出时刻的系统时钟算出一个时间戳,这样可以再现真实视频帧跟实际时间的对应关系。
跟上面音频一样,在封装到 RTP 包的时候,会将原始视频帧的时间戳累加上一个随机偏移量(此偏移量跟音频的并不是同一个值),作为此 RTP 包的时间戳发送出去。值得注意的是,这里计算的 NTP 时间戳根本就不会随着 RTP 数据包一起发送出去,因为 RTP 包的包头里面没有 NTP 字段,即使是扩展字段里,我们也没有放这个值,如下面视频的时间相关的扩展字段。

3、音视频同步核心依据
从上面可以看出,RTP 包里面只包含每个流的独立的、单调递增的时间戳信息,也就是说音频和视频两个时间戳完全是独立的,没有关系的,无法只根据这个信息来进行同步,因为无法对两个流的时间进行关联,我们需要一种映射关系,将两个独立的时间戳关联起来。
这个时候 RTCP 包里面的一种发送端报告分组 SR(SenderReport) 包就上场了,详情请参考RFC3550。
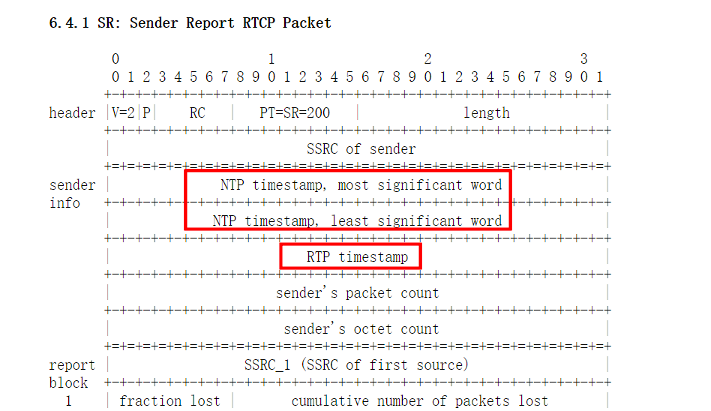
SR 包的其中一个作用就是来告诉我们每个流的 RTP 包的时间戳和 NTP 时间的对应关系的。靠的就是上边图片中标出的 NTP 时间戳和 RTP 时间戳,通过 RFC3550 的描述,我们知道这两个时间戳对应的是同一个时刻,这个时刻表示此 SR 包生成的时刻。这就是我们对音视频进行同步的最核心的依据,所有的其它计算都是围绕这个核心依据来展开的。
4、SR 包的生成
由上面论述可知,NTP 时间和 RTP 时间戳是同一时刻的不同表示,只是精度和单位不一样。NTP 时间是绝对时间,以毫秒为单位,而 RTP 时间戳则和媒体的采样频率有关,是一个单调递增数值。生成 SR 包的过程在 RTCPSender::BuildSR(const RtcpContext &ctx) 函数里面,老版本里面有 bug,写死了采样率为 8K,新版本已经修复,下面截图是老版本的代码:
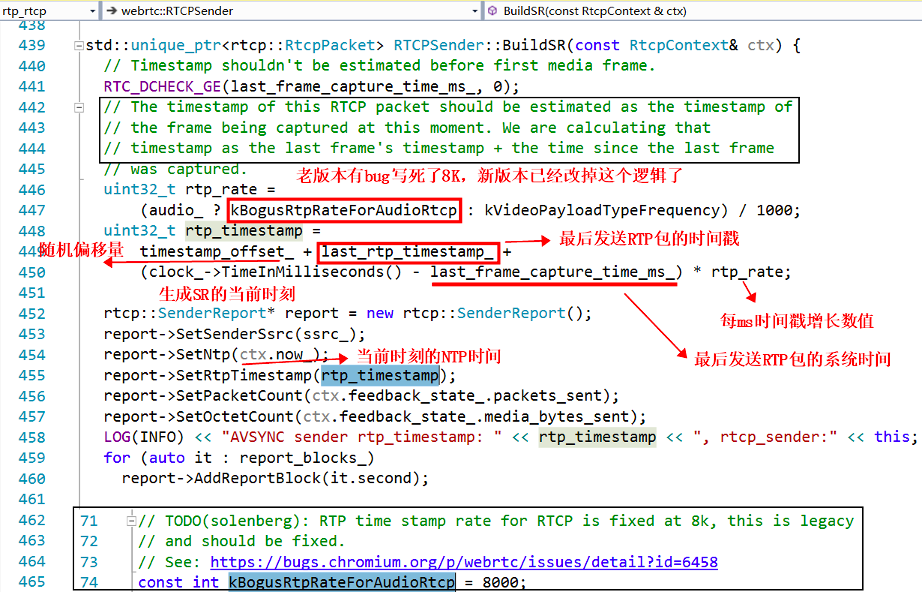
计算的思路如下
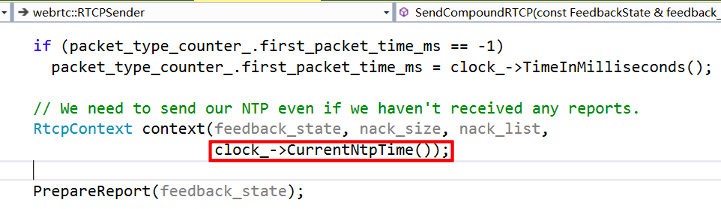
首先,我们要获取当前时刻(即 SR 包生成时刻)的 NTP 时间。这个直接从传过来的参数 ctx 中就可以获得:
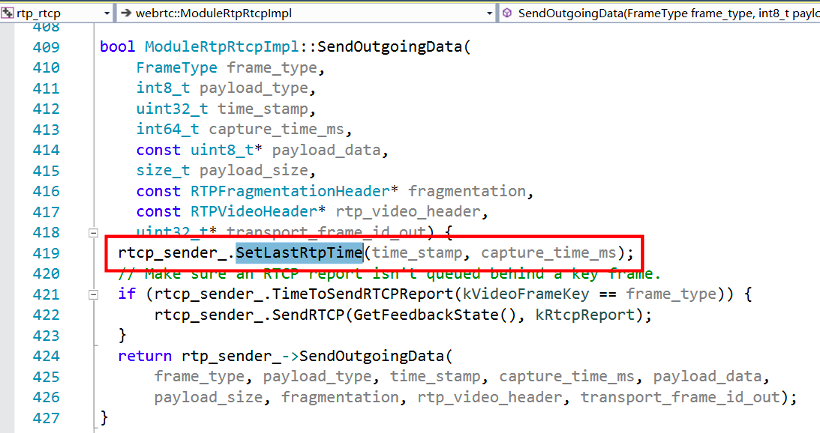
其次,我们要计算当前时刻,应该对应的 RTP 的时间戳是多少。根据最后一个发送的 RTP 包的时间戳 last_rtp_timestamp_ 和它的采集时刻的系统时间 last_frame_capture_time_ms_,和当前媒体流的时间戳的每 ms 增长速率 rtp_rate,以及从 last_frame_capture_time_ms_ 到当前时刻的时间流逝,就可以算出来。注意,last_rtp_timestamp_ 是媒体流的原始时间戳,不是经过随机偏移的 RTP 包时间戳,所以最后又累加了偏移量 timestamp_offset_。其中最后一个发送的 RTP 包的时间信息是通过下面的函数进行更新的:
5、音视频同步的计算
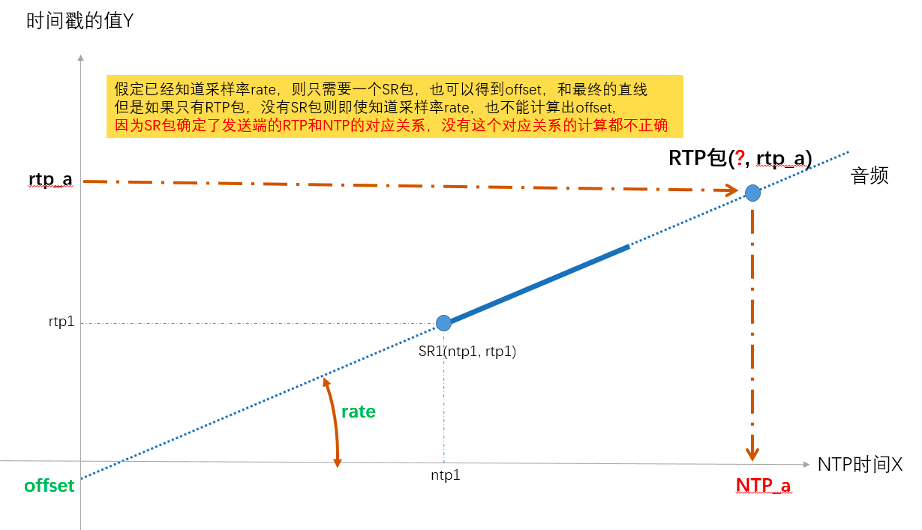
因为同一台机器上音频流和视频流的本地系统时间是一样的,也就是系统时间对应的 NTP 格式的时间也是一样的,是在同一个坐标系上的,所以可以把 NTP 时间作为横轴 X,单位是 ms,而把 RTP 时间戳的值作为纵轴 Y,画在一起。下图展示了计算音视频同步的原理和方法,其实很简单,就是使用最近的两个 SR 点,两点确定一条直线,之后给任意一个 RTP 时间戳,都可以求出对应的 NTP 时间,又因为视频和音频的 NTP 时间是在同一基准上的,所以就可以算出两者的差值。
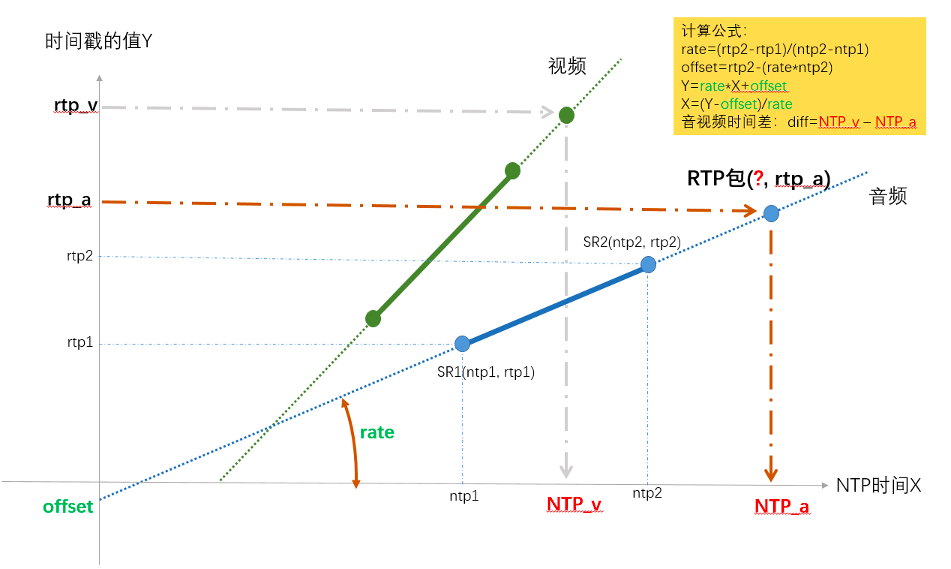
上图以音频的两个 SR 包为例,确定出了 RTP 和 NTP 对应关系的直线,然后给任意一个 rtp_a,就算出了其对应的 NTP_a,同理也可以求任意视频包 rtp_v 对应的 NTP_v 的时间点,两个的差值就是时间差。
下面是 WebRTC 里面计算直线对应的系数 rate 和偏移 offset 的代码:
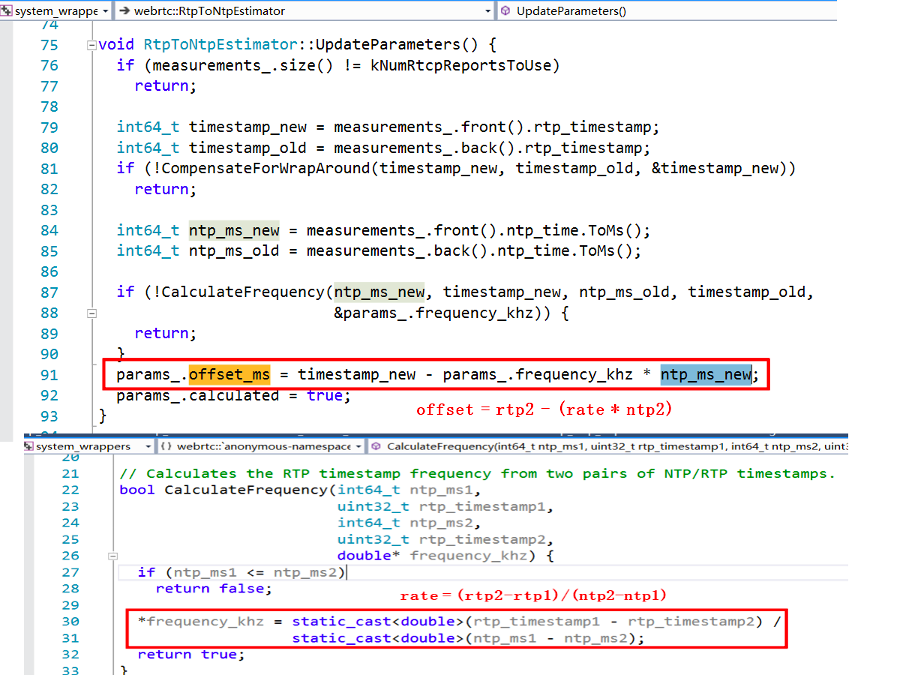
在 WebRTC 中计算的是最新收到的音频 RTP 包和最新收到的视频 RTP 包的对应的 NTP 时间,作为网络传输引入的不同步时长,然后又根据当前音频和视频的 JitterBuffer 和播放缓冲区的大小,得到了播放引入的不同步时长,根据两个不同步时长,得到了最终的音视频不同步时长,计算过程在StreamSynchronization::ComputeRelativeDelay() 函数中,之后又经过了StreamSynchronization::ComputeDelays() 函数对其进行了指数平滑等一系列的处理和判断,得出最终控制音频和视频的最小延时时间,分别通过syncable_audio_->SetMinimumPlayoutDelay(target_audio_delay_ms) 和 syncable_video_->SetMinimumPlayoutDelay(target_video_delay_ms) 应用到了音视频的播放缓冲区。
这一系列操作都是由定时器调用 RtpStreamsSynchronizer::Process() 函数来处理的。
另外需要注意一下,在知道采样率的情况下,是可以通过一个 SR 包来计算的,如果没有 SR 包,是无法进行准确的音视频同步的。
WebRTC 中实现音视频同步的手段就是 SR 包,核心的依据就是 SR 包中的 NTP 时间和 RTP 时间戳。最后的两张 NTP 时间-RTP 时间戳 坐标图如果你能看明白(其实很简单,就是求解出直线方程来计算 NTP),那么也就真正的理解了 WebRTC 中音视频同步的原理。如果有什么遗漏或者错误,欢迎大家一起交流!