TCP_BBR拥塞控制算法解析
原文出处:BBR及其在实时音视频领域的应用
实时音视频系统要求低延时,流畅性好,而实际网络状态却是复杂多变的,丢包,延时和网络带宽都在时刻变化,这就对网络拥塞控制算法提出了很高的要求。本文来自网易云信资深工程师肖磊在LiveVideoStackCon2019北京站上的精彩分享,文章中详细介绍了BBR拥塞控制算法产生背景及其演进。
大家好,我是网易云信音视频工程师肖磊,目前致力于实时音视频领域的QoS研究,通过优化拥塞控制算法,为用户提供高带宽利用率,低延时,抗抖动能力强的实时音视频服务。
本次我分享的主题是BBR及其在实时音视频领域的应用,BBR全称是Bottleneck Bandwidth and RTT,它是谷歌在2016年推出的全新网络拥塞控制算法,在此之后大家对于拥塞控制的关注度逐渐提高,越来越多的新算法被推出。本次分享的内容主要包括BBR算法的基本原理以及BBR算法如何应用在网易云信的实时音视频产品中。
1. BBR产生的背景
拥塞控制始于20世纪80年代,当时TCP是滑动窗口的算法,拥塞窗口固定,需要通过不断地响应报文推动滑动窗口前进。但在1986年TCP导致了拥塞崩溃,比如现在多端采用TCP发起报文,实际带宽达不到所能提供的最大带宽时网络出现拥堵,此时会有越来越多的TCP发起重试,进而加剧拥堵情况。
2000年之后伴随着互联网大爆发,各类应用特别是音视频应用数量大幅增加,TCP拥塞控制算法无法满足当前互联网应用对网络传输高实时性、高带宽利用率、高吞吐量的需求,在这种背景下BBR应运而生。
1.1 TCP算法存在的问题

在互联网发展的过程当中,TCP算法也做出了一定改变,先后演进了Reno、NewReno、Cubic和Vegas,这些改进算法大体可以分为基于丢包和基于延时的拥塞控制算法。基于丢包的拥塞控制算法以Reno、NewReno为代表,它的主要问题有Buffer bloat和长肥管道两种,基于丢包的协议拥塞控制机制是被动式的,其依据网络中的丢包事件来做网络拥塞判断。即使网络中的负载很高,只要没有产生拥塞丢包,协议就不会主动降低自己的发送速度。最初路由器转发出口的Buffer是比较小的,TCP在利用时容易造成全局同步,降低带宽利用率,随后路由器厂家由于硬件成本下降不断地增加Buffer,基于丢包反馈的协议在不丢包的情况下持续占用路由器buffer,虽然提高了网络带宽的利用率,但同时也意味着发生拥塞丢包后,网络抖动性加大。另外对于带宽和RTT都很高的长肥管道问题来说,管道中随机丢包的可能性很大,TCP的默认buffer设置比较小加上随机丢包造成的cwnd经常下折,导致带宽利用率依旧很低。
基于延时的拥塞控制算法以vegas为代表,但当vegas出现时,基于丢包的拥塞控制算法在市面已经占据主流,vegas抢不到带宽出现“饿死”现象,因此也没办法与之抗争。
在BBR出现之前,TCP的拥塞控制一直逃脱不了这两个方向,另外优化TCP的拥塞控制难免涉及到内核的修改,这也是限制TCP继续优化的一大问题。
1.2 BBR算法的特点及核心
BBR(Bottleneck Bandwidth and Round-triagation time)是一种基于带宽和延迟反馈的拥塞控制算法。目前已经演化到第二版,是一个典型的封闭反馈系统,发送多少报文和用多快的速度发送这些报文都是在每次反馈中不断调节。在BBR提出之前,拥塞控制都是基于事件的算法,需要通过丢包或延时事件驱动;BBR提出之后,拥塞控制是基于反馈的自主自动控制算法,对于速率的控制是由算法决定,而不由网络事件决定,算法核心是“不排队”。
2. BBR算法基本原理
2.1 BBR结构图
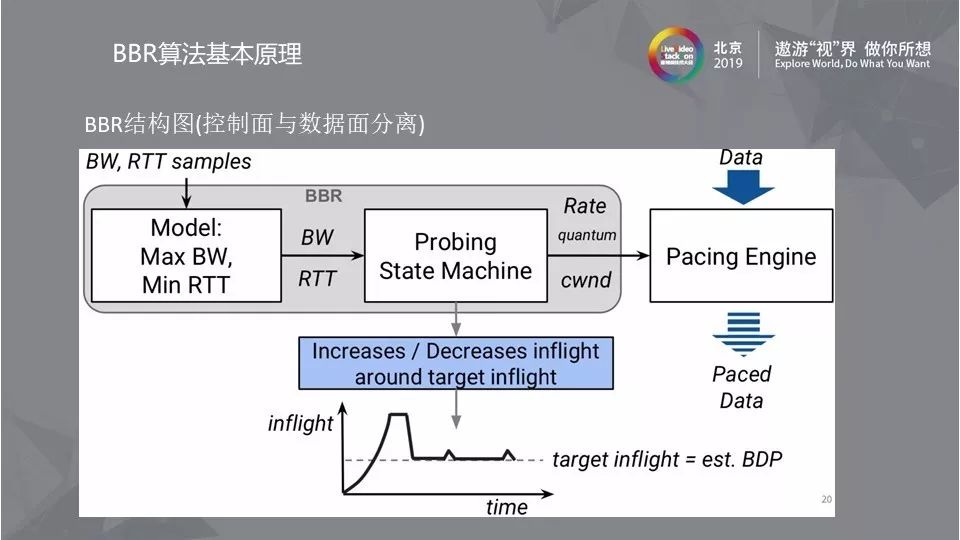
BBR算法的核心是找到最大带宽(Max BW)和最小延时(Min RTT)这两个参数,最大带宽和最小延时的乘积可以得到BDP(Bandwidth Delay Product), 而BDP就是网络链路中可以存放数据的最大容量。BDP驱动Probing State Machine得到Rate quantum和cwnd,分别设置到发送引擎中就可以解决发送速度和数据量的问题。
2.2 即时带宽的计算
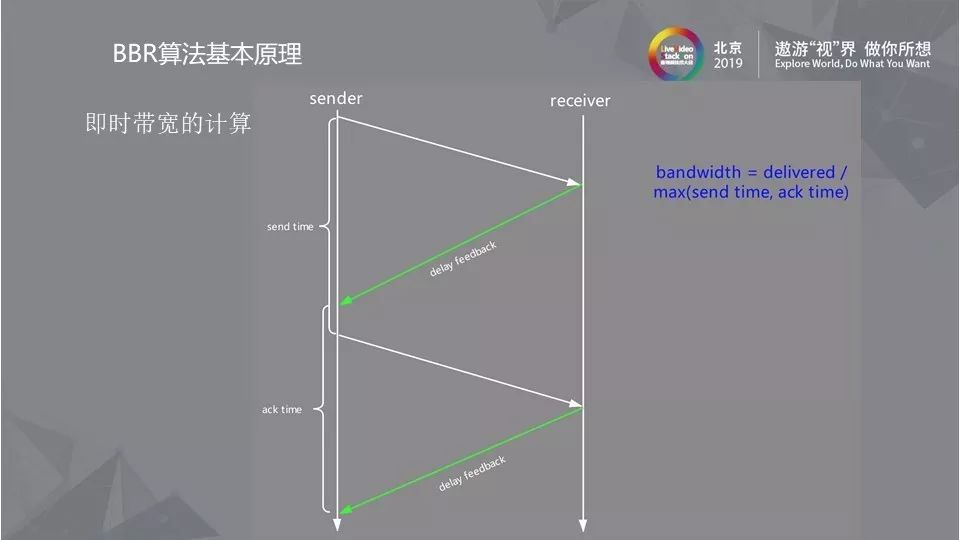
一般情况下的即时带宽计算,很多人认为将发送报文和收到报文的时间点记录下来,发包数量再除以时间就可以得到带宽,但这样的计算方式是错误的。由于delay feedback表示一组报文的响应,一组报文之后会有一个延迟的相应来通知哪些报文没有收到,以及收到的时间差是多少。delay feedback容易受到网络影响,因此报文不会均匀发送,易发生聚合和丢包现象,在计算时要考虑发送的时间差和ack的时间差,公式为:bandwidth = delivered/max(send time,ack time),这样才能抵消掉延迟聚合和丢失的情况。
2.3 BDP
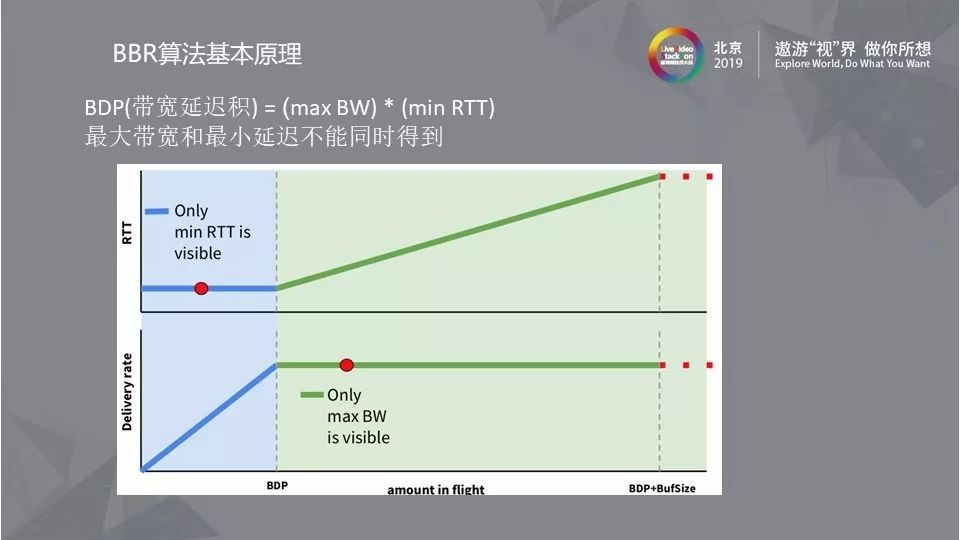
BDP(带宽延迟积)是BBR算法中的核心,其中最大带宽和最小延迟不能同时得到。如图所示,横轴是网络链路中的数据量,纵轴分别是RTT和带宽,在RTT不变的时候,网络没有发生拥塞,带宽一直在上升,没有达到最大,而当带宽停止上涨的时候,网络开始拥塞,RTT持续变大,直到发生丢包。图中BDP所标识的点就是理想情况下最大带宽和最小延时。很明显只有在没有发生拥塞时才能得到RTT的数值,因此很难在同一时刻找到最小的RTT和最大带宽。
2.4 BBR状态机
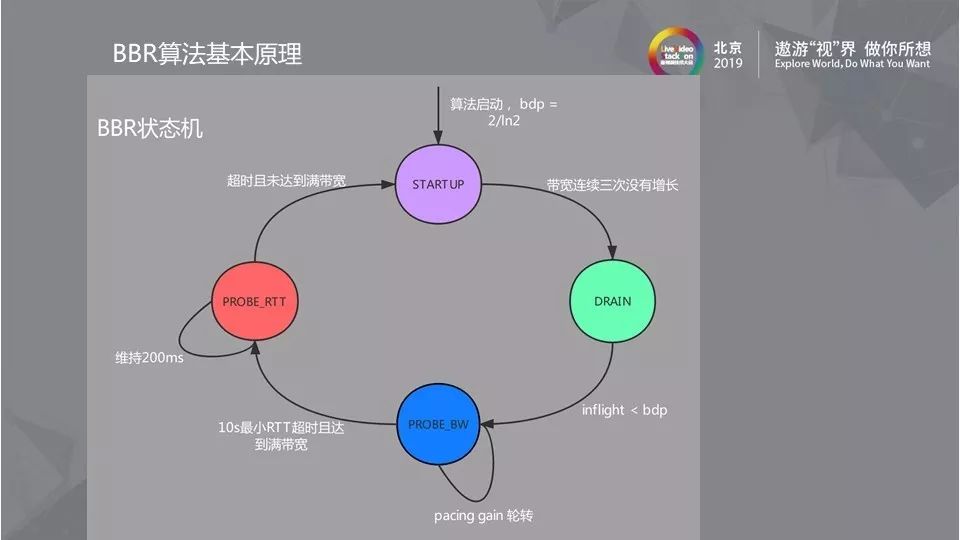
既然最大带宽和最小延迟不能同时得到,必然存在探测最大带宽和最小RTT的过程。上图表示的是BBR的状态机,状态机分为Startu,Drain,ProbeBW,ProbeRTT4个阶段。Startu阶段类似于普通拥塞控制里的慢启动,以2/ln2的增益系数持续更新发包速率,带宽连续三次没有增长就可以判定达到最大带宽而进入Drain状态。
进入Drain状态时队列可能存在拥堵,因此需要把Startu状态中产生的队列排空,排空的速率是ln2/2,如果inflight < BDP说明此时网络由BBR造成的拥塞已经全部排空,如果 inflght > BDP 说明此时网络还有拥塞,不能进入下一个状态。
拥塞排空之后会进入探测带宽阶段,探测最大带宽的方法是在10个RTT中观测到的最大带宽,以此数据作为最大带宽。如果10s没有得到最小RTT,超时之后需要继续探测最小RTT。探测最小RTT需要尽量避免网络拥堵,降低拥塞窗口,发送比较少的报文。整个BBR的拥塞控制在启动之后,最终是在Drain和ProbeBW阶段之间切换。
3. BBR算法的优缺点
BBR相对TCP的优点包括抗丢包能力强、延迟低、抢占能力强和平稳发送。在BBR算法之前的TCP Cubic,拥塞控制算法并没有平稳发送的说法,而只是判断发送与否的问题,BBR算法出现之后,会平稳的发送数据,不会突发流量冲击。BBR相对TCP的优点包括抗丢包能力强、延迟低、抢占能力强和平稳发送。在BBR算法之前的TCP Cubic,拥塞控制算法并没有平稳发送的说法,而只是判断发送与否的问题,BBR算法出现之后,会平稳的发送数据,不会突发流量冲击。
3.1 抗丢包能力强
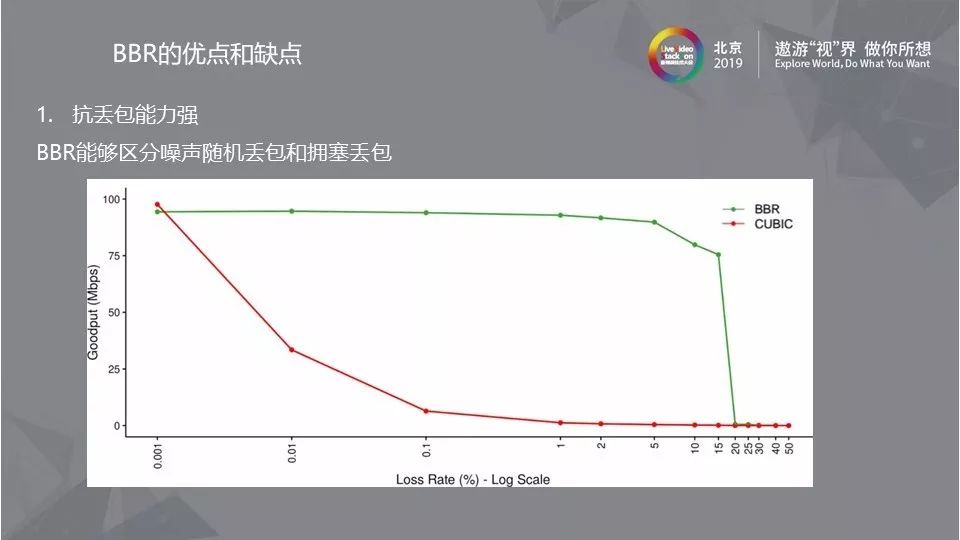
关于BBR算法的抗丢包能力可以用上图来说明,BBR算法不会因为一次或者偶然的丢包就大幅降低吞吐量,因此具有较强的抗丢包能力。
3.2 低延迟/抢占能力强

对于BBR在低延迟方面的优势来说,由于目前关于拥塞控制的算法很多,BBR在运转时设备中可能会有多种拥塞控制算法同时作用的情况,BBR算法只能保证自己不排队。但在实际现行网络下,是否排队并不由BBR一个算法决定,运行过程中BBR算法不会加重网络拥塞。
在带宽探测阶段,BBR算法每一轮都会尝试上探更大的带宽,由此可以很快抢占其他拥塞算法让出来的带宽,这也是BBR算法抢占能力强的原因。
3.3 平稳发送

之前提到在TCP算法中并没有平稳发送的说法,BBR算法后来引入了平稳发送的概念,不只解决了发送多少的问题,还解决了发送速率的问题,具体实现是使用cwnd控制发送数量,发送速度使用漏桶算法控制。BBR算法中的cwnd与TCP算法不同,TCP算法中的cwnd是对网络状态的模拟,分为发送窗口和接收窗口,而BBR算法只有发送窗口,且cwnd = 2*BDP。
3.4 收敛速度慢/高于一定丢包率吞吐量下跌
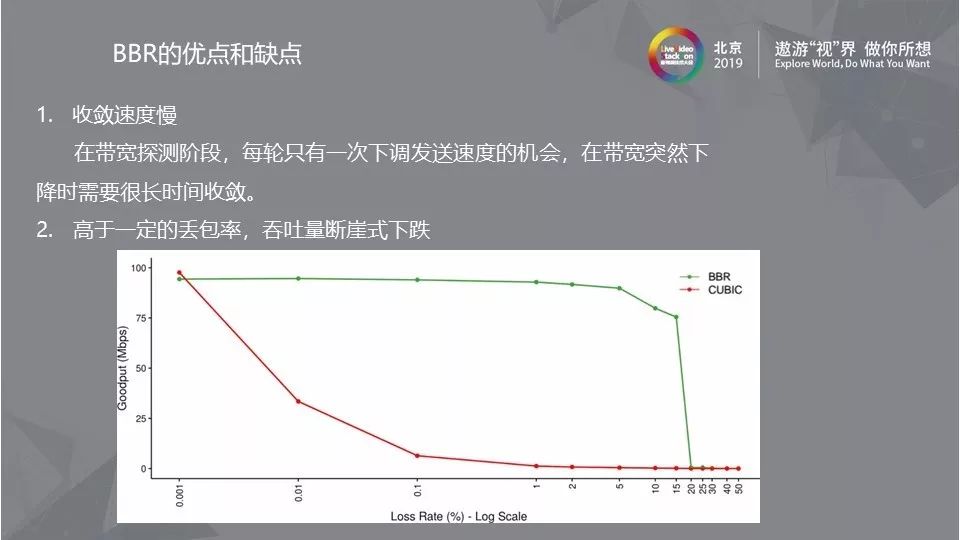
BBR算法在具备一些优势的同时也存在一定的缺点,比如原始的BBR算法收敛性受到pacing gain周期影响,带宽突降的时候,BBR需要多个轮次才会降到实际带宽。这其中的原因是BBR每轮只能降速一次,而pacing gain的6个RTT的保持周期大大加长了这个时间。由于pacing gain上探周期的1.25无法抵消掉25%以上的丢包,这会造成带宽反馈持续下降,BBR吞吐量就会断崖式下跌。
3.5 深队列竞争不过Cubic
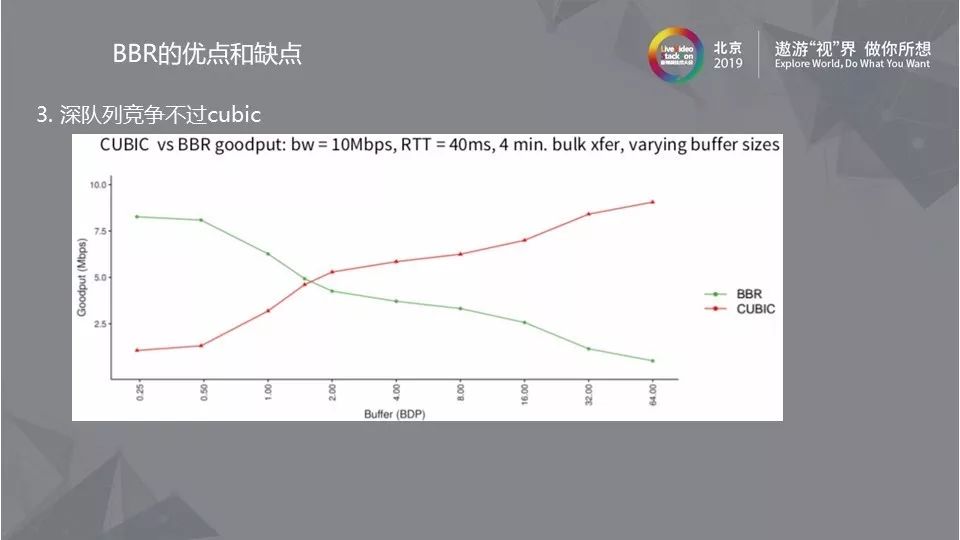
BBR算法设计之初cwnd = 2*BDP,在此之前BBR算法要比Cubic强很多,但在实际的网络环境中,如果出现buffer很大的情况,BBR是比Cubic竞争性差的,因此在应用BBR算法时必须了解当前的网络状况。
3.6 算法公平性/抗抖动能力

在算法公平性方面,BBR在与Reno竞争时可以占用90%以上的带宽,但在与多个BBR流竞争时,RTT高的流占用带宽更高,其中也暴露的漏洞是如果想占用更高带宽,可以人为调高RTT的值,这些并不是BBR算法的设计初衷。在抗抖动能力方面,RTT的抖动使BBR无法得到准确的BDP,探测带宽很有可能低于可用带宽。
4. BBR应用在实时音视频领域
4.1 BBR在实时音视频领域的优势

如果将BBR算法应用在实时音视频领域,需要满足带宽(特别是低带宽场景)探测准确,适合实时音视频传输的低延时需求,能够满足音视频传输码率平稳的需求以及快速响应带宽变化这四个要求。
4.2 BBR在实时音视频领域存在的问题

满足以上四个实时音视频需求的同时,BBR算法在应用时也存在着收敛速度慢、抗丢包能力无法达到预期的问题,另外实时音视频领域需要提供稳定的视频流,但BBR的ProbeRTT阶段只发4个包,发送速率下降太多会引发延迟加大和卡顿问题,最后BBR探测带宽需要Paddin有可能造成带宽浪费。
4.3 收敛速度/抗丢包能力解决办法

针对BBR应用在实时音视频领域遇到的问题,目前已经有不少解决方案。对于收敛速度慢的问题来说,BBR V2提出在Probe Down一次排空到位(inflight < BDP),另外还可以随机化6个1x平稳发送周期,缩短排空所需要的时间。对于抗丢包能力不足的问题来说,目前BBR算法的抗丢包能力是足够的,但在一些极端网络条件下可以把丢包率补偿到pacing rate,有效提升抗丢包能力。
4.4 ProbeRTT阶段问题解决办法
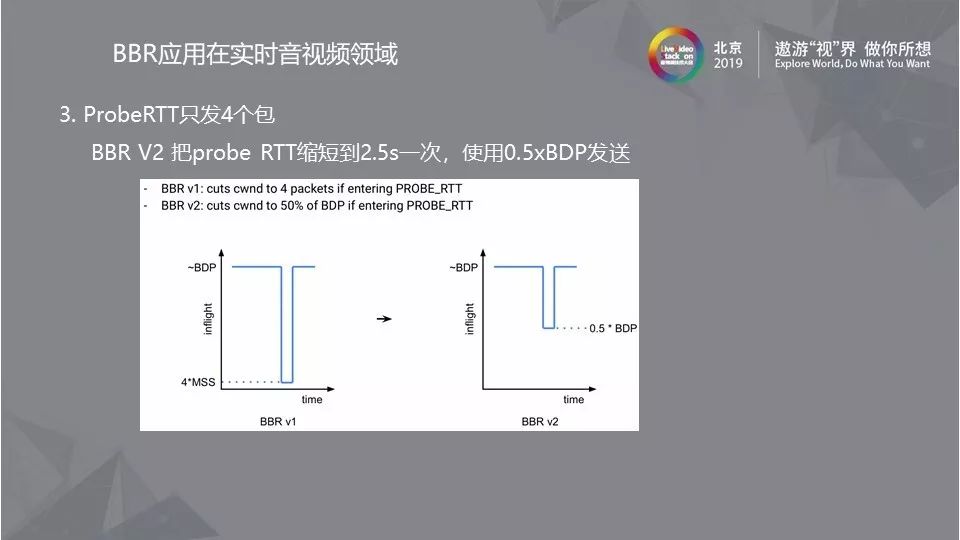
ProbeRTT并不适用实时音视频领域,因此可以选择直接去除,或者像BBR V2把ProbeRTT缩短到2.5s一次,使用0.5xBDP发送。
4.5 Padding/RTT不公平问题

为了保持带宽竞争性和平稳发送,BBR中的padding不可或缺,想要迅速感知带宽变化也必须有padding的存在。关于RTT不公平问题之前有提到RTT大占据的带宽多,但在排空阶段一次排空就可以缓解这个问题。
4.6 Cubic与BBR对比
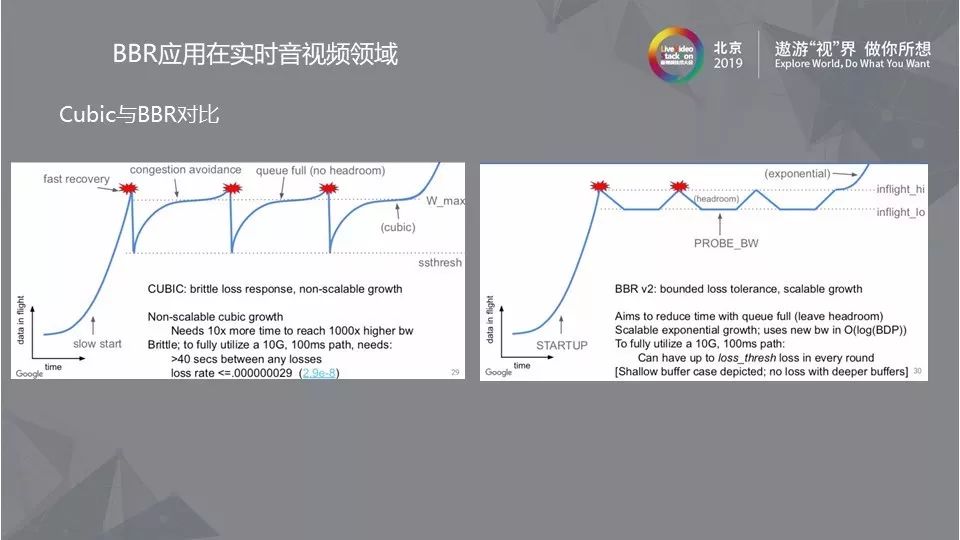
由上图整体可以看出BBR带宽利用率要高于Cubic。
4.7 BBR与GCC对比
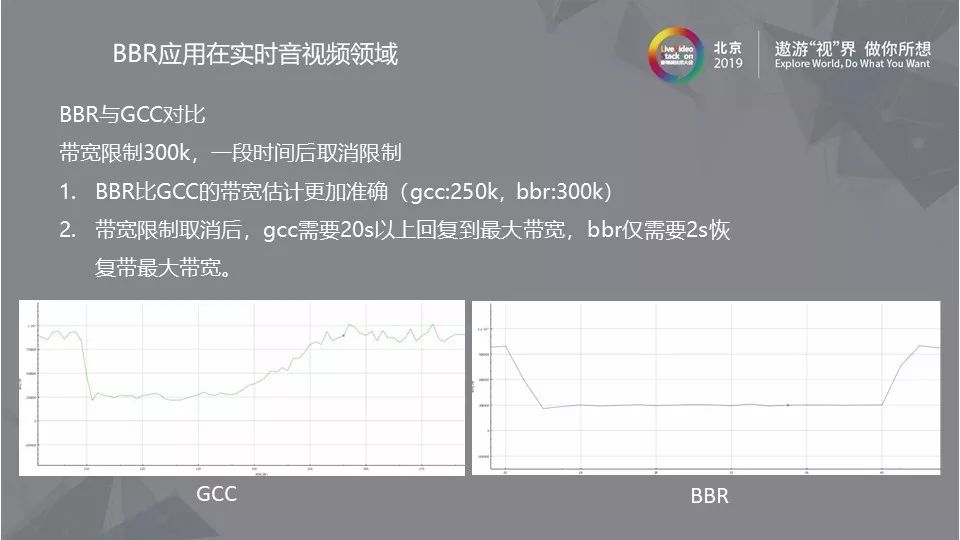
目前GCC控制算法在实时音视频领域占据主流,但WebRTC的GCC算法仍然有一些局限性,比如将带宽限制在300k,一段时间后取消限制的场景来对比,由图像对比可以得到,BBR比GCC的带宽估计更加准确(GCC:250k,BBR:300k),而在带宽限制取消后,GCC需要20s以上才能恢复到最大带宽,BBR仅需要2s就可以恢复。
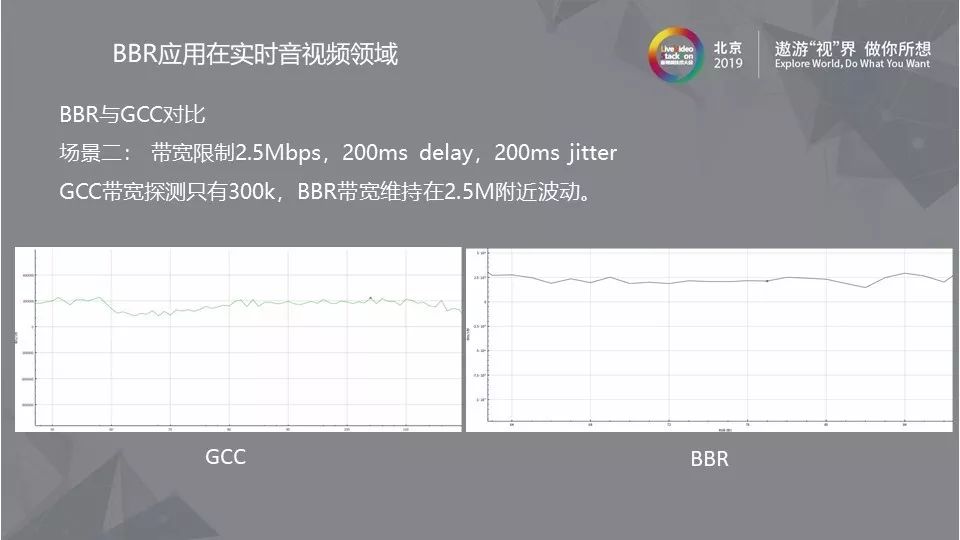
如果将带宽限制在2.5Mbs,加入200ms delay,200ms jitter,此场景中GCC和BBR的表现如图所示,GCC带宽探测只有300k,而BBR带宽维持在2.5M附近波动,在如此恶劣的网络环境中BBR的表现已经是相当优秀了。
总结来看,BBR算法有很多优点的同时也有很多缺点,目前没有一个算法能够适用所有的网络状态,针对不同的网络状态选择不同的拥塞算法似乎是一个可行的办法,但基于当前拥塞算法,融合其他算法的优点也是可以实现的,在此希望能够涌现出更多有兴趣的人为实时音视频领域的拥塞算法出力。
原文出处:BBR在实时音视频领域的应用
小议BBR算法
BBR全称Bottleneck Bandwidth and RTT,它是谷歌在2016年推出的全新的网络拥塞控制算法。要说明BBR算法,就不能不提TCP拥塞算法。
传统的TCP拥塞控制算法,是基于丢包反馈的协议。基于丢包反馈的协议是一种被动式的拥塞控制机制,其依据网络中的丢包事件来做网络拥塞判断。即便网络中的负载很高时,只要没有产生拥塞丢包,协议就不会主动降低自己的发送速度。
TCP在发送端维护一个拥塞窗口cwnd,通过cwnd来控制发送量。采用AIMD,就是加性递增和乘性递减的方式控制cwnd,在拥塞避免阶段加性增窗,发生丢包则乘性减窗。
这个拥塞控制算法的假定是丢包都是拥塞造成的。
TCP拥塞控制协议希望最大程度的利用网络剩余带宽,提高吞吐量。然而,由于基于丢包反馈协议在网络近饱和状态下所表现出来的侵略性,一方面大大提高了网络的带宽利用率;但另一方面,对于基于丢包反馈的拥塞控制协议来说,大大提高网络利用率同时意味着下一次拥塞丢包事件为期不远了,所以这些协议在提高网络带宽利用率的同时也间接加大了网络的丢包率,造成整个网络的抖动性加剧。
TCP拥塞控制算法的假定是丢包都是拥塞造成的,而事实上,丢包并不总是拥塞导致,丢包可能原因是多方面,比如:路由器策略导致的丢包,WIFI信号干扰导致的错误包,信号的信噪比(SNR)的影响等等。这些丢包并不是网络拥塞造成的,但是却会造成TCP 控制算法的大幅波动,即使在网络带宽很好的情况下,仍然会出现发送速率上不去的情况。比如长肥管道,带宽很高,RTT很大。管道中随机丢包的可能性很大,这就会造成TCP的发送速度起不来。
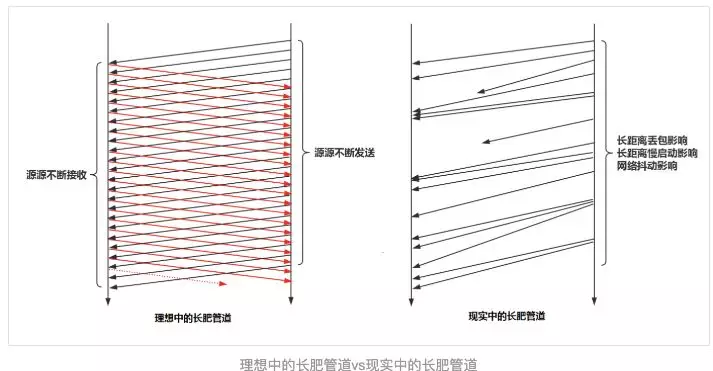
Google 的BBR出现很好的解决了这个问题。BBR是一种基于带宽和延迟反馈的拥塞控制算法。它是一个典型的封闭反馈系统,发送多少报文和用多快的速度发送这些报文都是每次反馈中不断调节。
BBR算法的核心就是找到两个参数,最大带宽和最小延时。最大带宽和最小延时的乘积就是BDP(Bandwidth Delay Product), BDP就是网络链路中可以存放数据的最大容量。知道了BDP就可以解决应该发送多少数据的问题,而网络最大带宽可以解决用多大速度发送的问题。如果网络比作一条高速公路,把数据比作汽车,最大带宽就是每分钟允许通行的汽车数量,最小RTT就是没有拥堵情况下,汽车跑一个来回需要的时间,而BDP就是在这条路上排满汽车的数量。
BBR如何探测最大带宽和最小延时
BBR是如何探测最大带宽和最小延时呢?首先有一点就是最大带宽和最小延时是无法同时得到的。
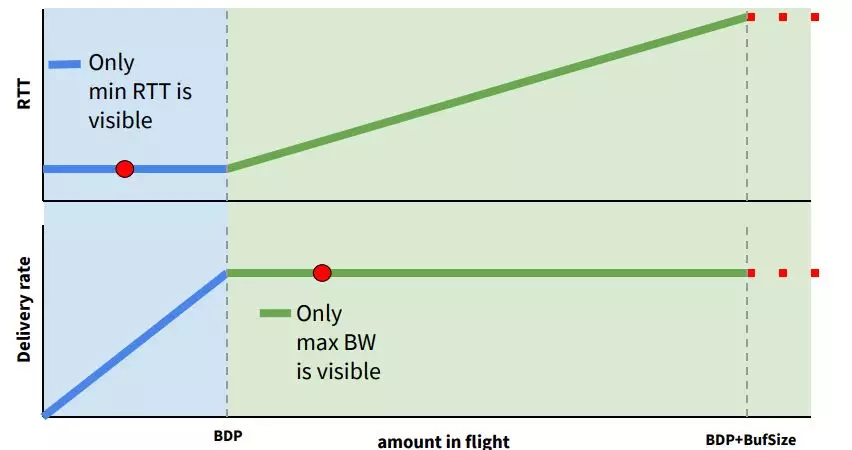
如图所示,横轴是网络链路中的数据量,纵轴分别是RTT和带宽。可以发现在RTT不变的时候,带宽一直在上升,没有达到最大,因为这个时候网络没有拥塞,而带宽停止上涨的时候RTT持续变大,一直到发生丢包。因为这个时候,网络开始拥塞,报文累积在路由器的buffer中,这样延时持续变大,而带宽不会变大。图中BDP的竖线所标识的就是理想情况下最大带宽和最小延时。很明显,要找到BDP, 很难在同一时刻找到最小的RTT和最大带宽。这样最小RTT和最大带宽必须分别探测。
探测最大带宽的方法就是尽量多发数据,把网络中的buffer占满,带宽在一段时间内不会增加,这样可以得到此时的最大带宽。
探测最小RTT的方法就是尽量把buffer腾空,让数据交付延时尽量低。
由此,BBR就引入了基于不同探测阶段的状态机。
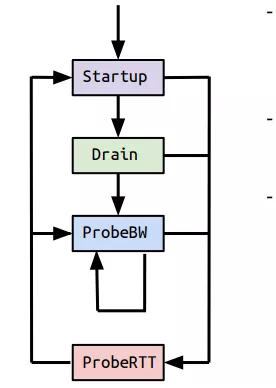
状态机分为4个阶段,Startup,Drain,ProbeBW, ProbeRTT。
Startup类似于普通拥塞控制里的慢启动,增益系数是 2ln2,每一个来回都以这个系数增大发包速率,估测到带宽满了就进入Drain状态,连续三个来回,测得的最大瓶颈带宽没有比上一轮增大 25%以上,就算带宽满了。
进入 Drain状态,增益系数小于 1,也就降速了。一个包来回,把 Startup状态中产生的拍队排空,怎样才算队列空了?发出去还没有 ACK 的数据包量 inflight,与 BDP 进行比较,inflight < BDP 说明空了,道路不那么满了,如果 inflght > BDP 说明还不能到下一个状态,继续 Drain。
ProbeBW是稳定状态,这时已经测出来一个最大瓶颈带宽,而且尽量不会产生排队现象。之后的每个来回,在 ProbeBW状态循环(除非要进入下面提到的ProbeRTT状态),轮询下面这些增益系数,[5/4, 3/4, 1, 1, 1, 1, 1, 1],如此,最大瓶颈带宽就会在其停止增长的地方上下徘徊。大部分时间都应该处于 ProbeBW状态。
前面三种状态,都可能进入 ProbeRTT状态。超过十秒没有估测到更小的 RTT 值,这时进入ProbeRTT状态,把发包量降低,空出道路来比较准确得测一个 RTT 值,至少 200ms或一个包的来回之后退出这个状态。检查带宽是否是满的,进入不同的状态:如果不满,进入 Startup状态,如果满,进入 ProbeBW状态。
BBR算法不会因为一次或者偶然的丢包就大幅降低吞吐量,这样就比TCP就有较强的抗丢包能力。
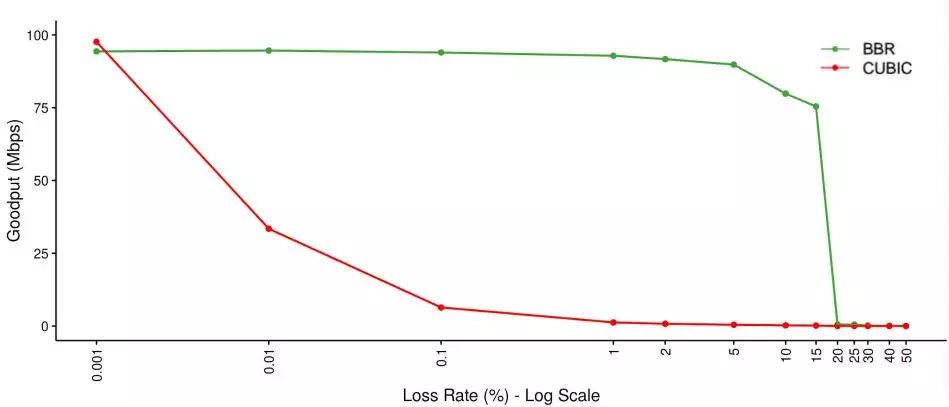
如图所示,cubic在丢包率上升的时候,吞吐量下降很快。而BBR在5%以上的丢包才会出现明显的吞吐量下降。
BBR与基于丢包反馈的cubic和基于延时反馈的vegas算法的本质区别在于,BBR无视随机丢包,无视时延短暂波动,采用了实时采集并保留时间窗口的策略,保持对可用带宽的准确探知。事实上,丢包并不一定会造成带宽减少,延迟增加也不一定会造成带宽减少,cubic无法判断是否拥塞造成的丢包,vegas对延时增加过于敏感,会导致竞争性不足。
BBR可以区分出噪声丢包和拥塞丢包,这样意味着,BBR比传统TCP拥塞控制算法具有更好的抗丢包能力。
BBR在实时音视频领域的应用
实时音视频系统要求低延时,流畅性好,而实际网络状态却是复杂多变的,丢包,延时和网络带宽都在时刻变化,这就对网络拥塞控制算法提出了很高的要求。它需要一种带宽估计准确,抗丢包和抖动能力好的拥塞控制算法。
目前Google的webrtc提供了GCC控制算法,它是一种发送侧基于延迟和丢包的控制算法,这个算法的原理在很多地方都有详细描述,这里不再赘述。GCC用于实音视频的主要问题还在于在带宽发生变化时,它的带宽跟踪时间比较长,这样就会造成带宽突变的时候无法及时准确探测带宽,可能造成音视频卡顿。
既然BBR有良好的抗丢包能力,自然也被想到应用到实时音视频领域。但是,BBR并不是为处理实时音视频设计的,所以需要对一些问题做一些优化。
第一,BBR在丢包率达到25%以上,吞吐量会断崖式下降。
这是由BBR算法的pacing_gain数组[5/4, 3/4, 1, 1, 1, 1, 1, 1]的固定参数决定的。
在pacing_gain数组中,其增益周期的倍数为5/4,增益也就是25%,可以简单理解为,在增益周期,BBR可以多发送25%的数据。
在增益期,丢包率是否抵消了增益比25%?也就是说,x是否大于25。
假设丢包率固定为25%,那么,在增益周期,25%的增益完全被25%的丢包所抵消,相当于没有收益,接下来到了排空周期,由于丢包率不变,又会减少了25%的发送数据,同时丢包率依然是25%...再接下来的6个RTT,持续保持25%的丢包率,而发送率却仅仅基于反馈,即每次递减25%,我们可以看到,在pacing_gain标识的所有8周期,数据的发送量是只减不增的,并且会一直持续下去,这样就会断崖式下跌。
怎样才能对抗丢包,这就需要在每个周期考虑丢包率,把丢包率补偿进去。比如丢包率达到25%的时候,增益系数就变成50%,这样就可以避免由于丢包带来的反馈减损,然而,你又如何判断这些丢包是噪声丢包还是拥塞丢包呢?答案在于RTT,只要时间窗口内的RTT不增加,那么丢包就不是拥塞导致的。
第二,BBR的最小RTT有个10s超时时间,在10s超时后,进入ProbeRTT状态,并持续最小200ms,此状态下,为了排空拥塞,inflight只允许有4个包,这会导致音视频数据在这段时间内堆积在发送队列中,使得时延增加。
可行的解决办法是,不再保留ProbeRTT状态,采用多轮下降的方式排空拥塞,然后采样最小RTT,也就是在infight > bdp的时候,设置pacinggain为0.75,用0.75倍带宽作为发送速率,持续多轮,直到inflight < bdp, 此外,最小RTT的超时时间改成2.5s,也就是说不采用非常激进的探测方式,避免了发送速率的大幅波动,可以改善探测新的带宽过程中发送队列中产生的延时。
第三,开始提到pacing gain数组上探周期为1.25倍带宽,随后是0.75倍带宽周期,这两个RTT周期之间会出现发送速率的剧烈下降,这可能会使音视频数据滞留在buffer中发不出去,引入不必要的延时。
解决办法可以考虑减小上探周期和排空周期的幅度,比如使用[1.1 0.9 1 1 1 1 1 1]这种pacinggain参数,这样做的优点就是可以保证媒体流的平稳发送,发送速率不会大幅波动,缺点是,网络带宽改善的时候,上探时间会变长。
第四,BBR探测新带宽收敛慢的问题
原始的BBR算法的收敛性受到pacinggain周期影响,带宽突降的时候,BBR需要多个轮次才会降到实际带宽。这是由于BBR每轮只能降速一次,而pacinggain的6个RTT的保持周期大大加长了这个时间。解决的办法就是随机化pacinggain的6个保持周期,如果是0.75倍周期,就一次降速到位,这样可以极大的减少BBR的收敛时间。
最后,BBR算法看似简单,但是应用到实时音视频却没有那么简单,需要大量的实验优化,谷歌也在webrtc中引入BBR,目前仍在测试中。本文提到的改进方法是网易云信在这方面的一些尝试,希望能够抛砖引玉,有更多有兴趣的人能够为BBR应用到实时音视频领域出力。
原文出处:TCP BBR拥塞控制算法解析
2016年底,Google发表了一篇优化tcp传输算法的文章,极大的提高了tcp得throughput,并且已经集成到Linux 4.9 内核。本文给出了论文中省略的一些背景知识,并结合自己的理解做了更加细节的介绍,可以帮助读者理解整个bbr算法。
1.背景
1.1TCP 基于丢包的拥塞控制
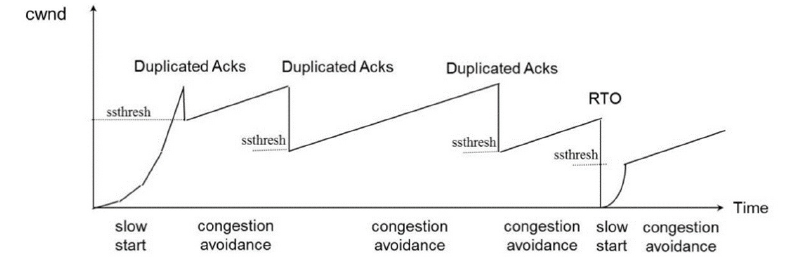
TCP拥塞控制将丢包视为网络出现拥塞的信号,以下为其四个主要过程:
引用自参考资料[5]
(1)慢启动阶段(slow start)
当建立新的TCP连接时,拥塞窗口(congestion window,cwnd)初始化为一个数据包大小。源端按cwnd大小发送数据,每收到一个ACK确认,cwnd就增加一个数据包发送量,这样cwnd就随着回路响应时间(Round Trip Time,RTT)的增加呈指数增长。
(2)拥塞避免阶段(congestion avoidance)
如果TCP源端发现超时或收到3个相同ACK时,即认为网络发生了拥塞。此时就进入拥塞避免阶段。慢启动阈值(ssthresh)被设置为当前拥塞窗口大小的一半;如果超时,拥塞窗口被置1。当cwnd>ssthresh,TCP就执行拥塞避免算法,此时,cwnd在每次收到一个ACK时只增加1/cwnd个数据包。这样,在一个RTT内,cwnd将增加1,所以在拥塞避免阶段,cwnd线性增长。
(3)快速重传阶段(Fast Retransmit)
快重传要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时捎带确认。快重传算法规定,发送方只要一连收到三个重复确认ACK就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器RTO超时。
(4)快速恢复阶段(Fast Recovery)
与快速重传配合使用,有以下两个要点:
①当发送方连续收到三个重复确认时,就执行“乘法减小”算法,即把ssthresh门限减半。但是接下去并不执行慢开始算法。
②考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh的大小,然后执行拥塞避免算法。
2.动机
2.1 基于丢包的拥塞控制算法的两大缺陷
(1)不能区分是拥塞导致的丢包还是错误丢包
基于丢包的拥塞控制方法把数据包的丢失解释为网络发生了拥塞,而假定链路错误造成的分组丢失是忽略不计的,这种情况是基于当时V. Jacobson的观察,认为链路错误的几率太低从而可以忽略,然而在高速网络中,这种假设是不成立的,当数据传输速率比较高时,链路错误是不能忽略的。在无线网络中,链路的误码率更高,因此,如果笼统地认为分组丢失就是拥塞所引起的,从而降低一半的速率,是对网络资源的极大浪费。
(2)引起缓冲区膨胀
我们会在网络中设置一些缓冲区,用于吸收网络中的流量波动,在连接的开始阶段,基于丢包的拥塞控制方法倾向于填满缓冲区。当瓶颈链路的缓冲区很大时,需要很长时间才能将缓冲区中的数据包排空,造成很大的网络延时,这种情况称之为缓冲区膨胀。在一个先进先出队列管理方式的网络中,过大的buffer以及过长的等待队列,在某些情况下不仅不能提高系统的吞吐量甚至可能导致系统的吞吐量近乎于零。并且当所有缓冲区都被填满时,会出现丢包。
2.2 网络工作的最优点是可达到的
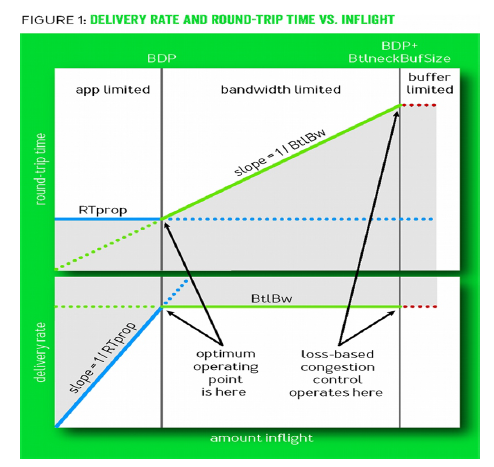
引用自参考资料[1]
当网络中数据包不多,还没有填满瓶颈链路的管道时,随着投递率的增加,往返时延不发生变化。当数据包刚好填满管道,达到网络工作的最优点(满足最大带宽BtlBw和最小时延RTprop),定义带宽时延积BDP=BtlBw × RTprop,则在最优点网络中的数据包数量=BDP。继续增加网络中的数据包,超出BDP的数据包会占用buffer,达到瓶颈带宽的网络的投递率不再发射变化,RTT会增加。继续增加数据包,buffer会被填满从而发生丢包。故在BDP线的右侧,网络拥塞持续作用。过去基于丢包的拥塞控制算法工作在bandwidth-limited区域的右侧边界,将瓶颈链路管道填满后继续填充buffer,直到buffer填满发生丢包,拥塞控制算法发现丢包,将发送窗口减半后再线性增加。过去存储器昂贵,buffer的容量只比BDP稍大,增加的时延不明显,随着内存价格的下降导致buffer容量远大于BDP,增加的时延很大。
3.基本观点
(1)不考虑丢包
(2)估计最优工作点 (max BW, min RTT)
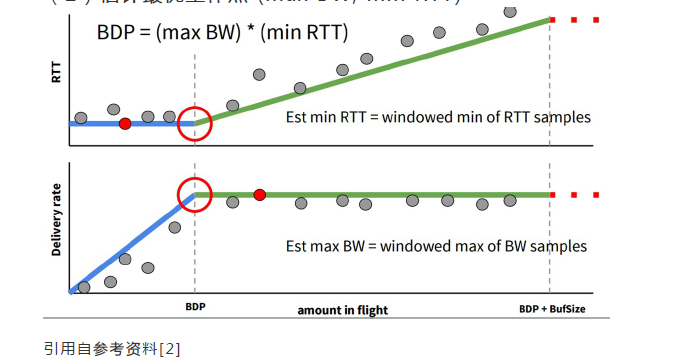
上图红色圆圈所示即为网络工作的最优点,此时数据包的投递率=BtlBW(瓶颈链路带宽),保证了瓶颈链路被100%利用;在途数据包总数=BDP(时延带宽积),保证未占用buffer。
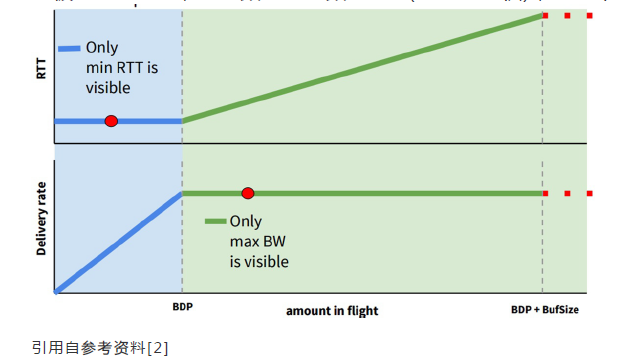
然而max BW和min RTT不能被同时测得。要测量最大带宽,就要把瓶颈链路填满,此时buffer中有一定量的数据包,延迟较高。要测量最低延迟,就要保证buffer为空,网络中数据包越少越好,但此时带宽较低。
BBR的解决办法是:
交替测量带宽和延迟,用一段时间内的带宽极大值和延迟极小值作为估计值。
4.设计细节
4.1BBR的四个状态(启动、排空、带宽探测、时延探测)
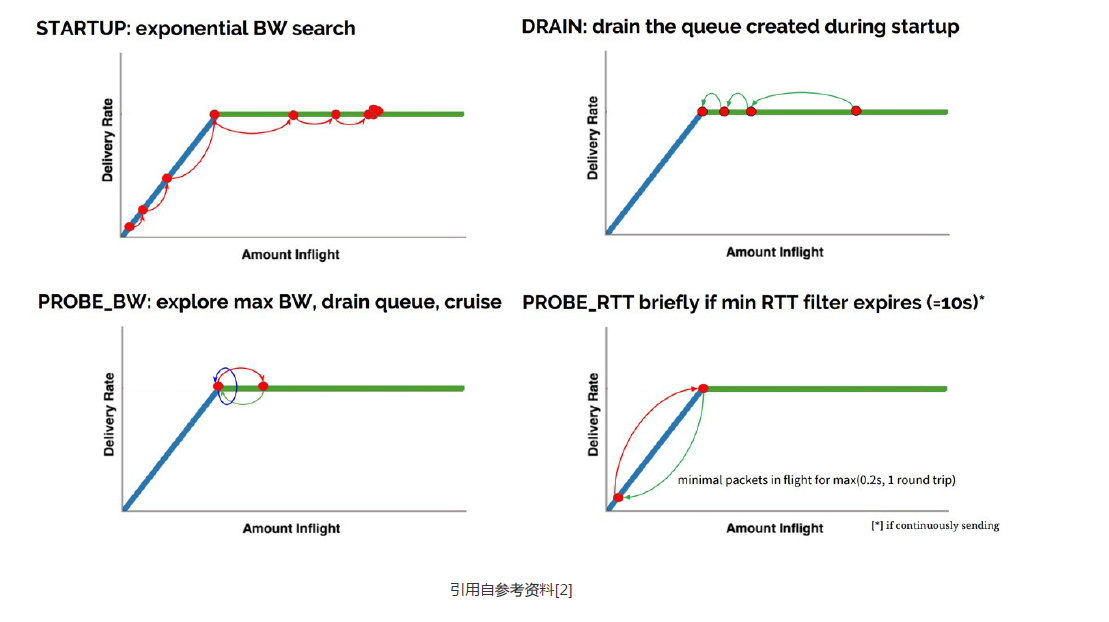
(1)当连接建立时,BBR采用类似标准TCP的slow start,指数增加发送速率,目的也是尽可能快的占满管道,经过三次发现投递率不再增长,说明管道被填满,开始占用buffer它进入排空阶段(事实上此时占的是三倍带宽*延迟)
(2)在排空阶段,指数降低发送速率,(相当于是startup的逆过程)将多占的2倍buffer慢慢排空
(3)完成上面两步,进入稳定状态后,BBR改变发送速率进行带宽探测:先在一个RTT时间内增加发送速率探测最大带宽,如果RTT没有变化,后减小发送速率排空前一个RTT多发出来地包,后面6个周期使用更新后的估计带宽发包
(4)还有一个阶段是延迟探测阶段:BBR每过10秒,如果估计延迟不变,就进入延迟探测阶段,为了探测最小延迟,BBR在这段时间内发送窗口固定为4个包,即几乎不发包,占整个过程2%的时间。
4.2带宽的动态更新(带宽探测)
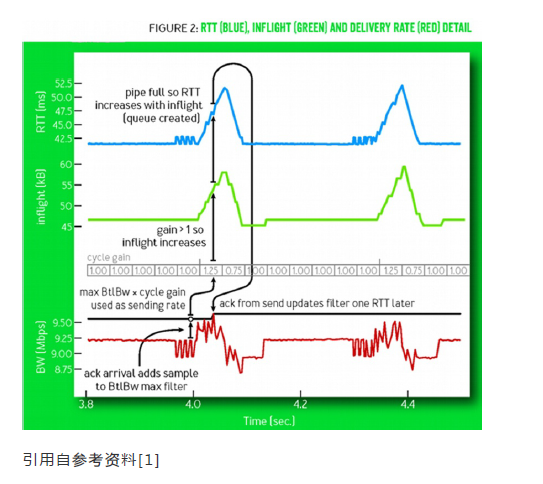
带宽探测占据BBR绝大部分时间。在startup阶段,BBR已经得到网络带宽的估计值。在带宽探测阶段,BBR利用一个叫做 cycle gain的数组控制发送速率,进行带宽的更新。cycle gain数组的值为 5/4, 3/ 4, 1, 1, 1, 1, 1, 1,BBR将max BtlBW*cycle gain的值作为发送速率。一个完整的cycle包含8个阶段, 每个阶段持续时间为一个RTprop。
故如果数组的值是1,就保持当前的发送速率,如果是1.25,就增加发送速率至1.25倍BW,如果是0.75,BBR减小发送速率至0.75倍BW。
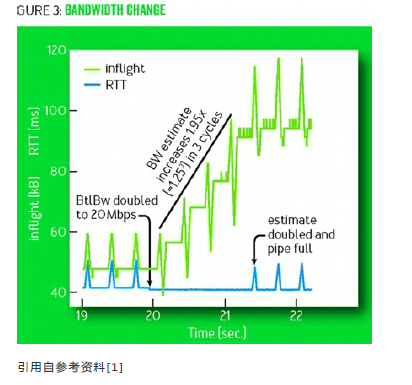
上图显示的是一个a 10-Mbps, 40-ms的数据流在第20s时网络带宽增加一倍至20 Mbp时,BBR是如何更新的。向上的尖峰表明它增加发送速率,向下的尖峰表明它降低发送速率,如果带宽不变,增加发送速率肯定会使RTT增加,降低发送速率是为了让他要把上一周期多发的包排空,如果带宽增加,则增加发包速率时RTT不变。这样经过三个周期之后,估计的带宽也增加了一倍。
上图所示为在第40s,是当网络带宽由20 Mbps减半至10 Mbps时,BBR的带宽探测如何发挥作用。因为发送速率不变,inflight增加,多出来的数据包占用了buffer,RTT增加,BBR从而减小发送速率,经过4秒后,有效带宽也降低为一半。
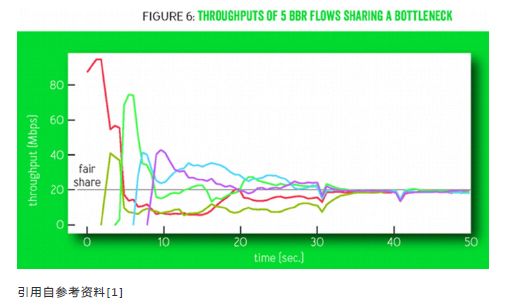
4.3多条BBR数据流分享瓶颈链路带宽
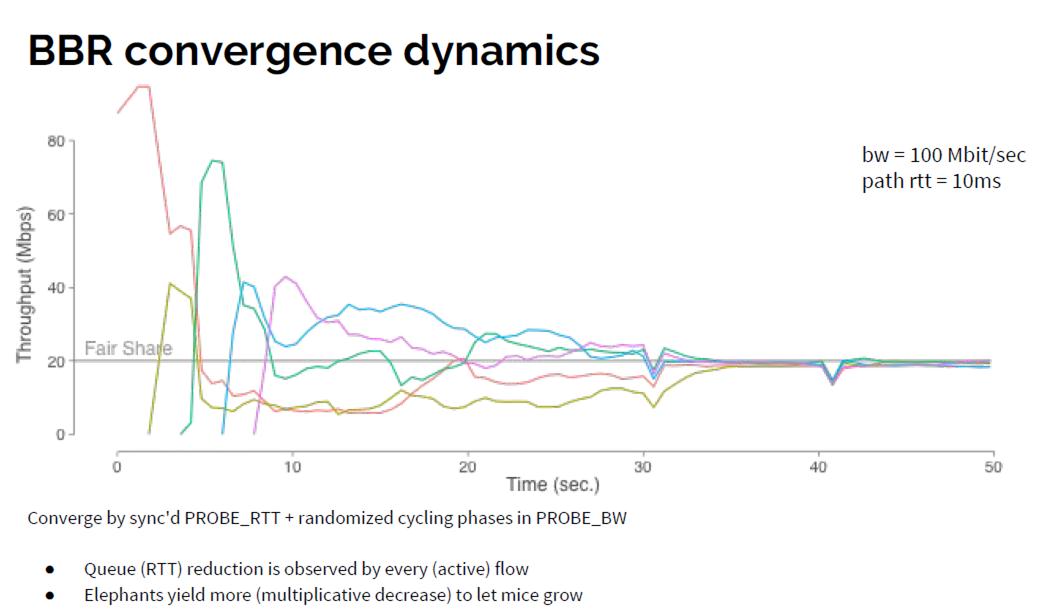
上图所示为多条独立的BBR数据流分享100-Mbps/10-ms瓶颈链路的情况:一条连接独占整个链路时,它的可用带宽近似为链路的物理带宽,n条连接共享链路时,最理想最公平的情况就是BW/n。每条连接的startup阶段都会尝试增加带宽,所以吞吐量会有一个向上的尖峰,已经在链路中的连接会检测到拥塞而减小自己的发送速率,吞吐量会下降。
最后通过反复的带宽探测,他们都会趋于收敛,带宽得到均分。
5.实验结果
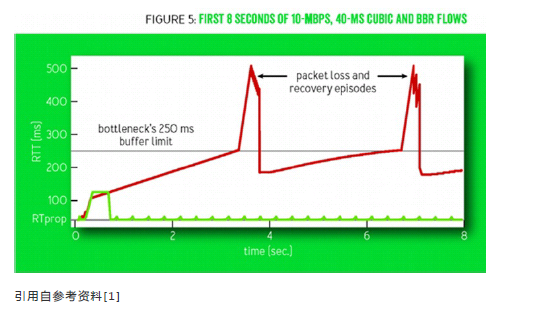
上图所示为CUBIC(红线)和BBR(绿线)的RTT 随时间的变化:
CUBIC(红线):可见周期性地延迟变化,缓存几乎总是被填满。
BBR(绿线):除了在statup和drain阶段,RTT会发生较大的变化,在网络带宽保持不变时,RTT只有细微的变化,这些小尖峰是BBR尝试增加发包速率产生的,每8个往返延迟为周期的延迟细微变化。
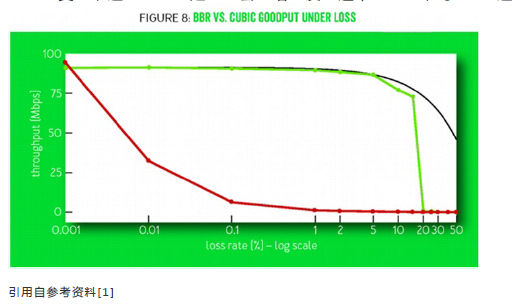
上图所示为在有随机丢包情况下BBR(绿线)和CUBIC(红线)吞吐量的比较。
如图所示,CUBIC(红线)在万分之一丢包率的情况下,CUBIC带宽只剩30% 千分之一丢包率时只剩10%,在百分之一丢包率时就几乎没有吞吐量 。而BBR在丢包率5%以下几乎没有带宽损失。
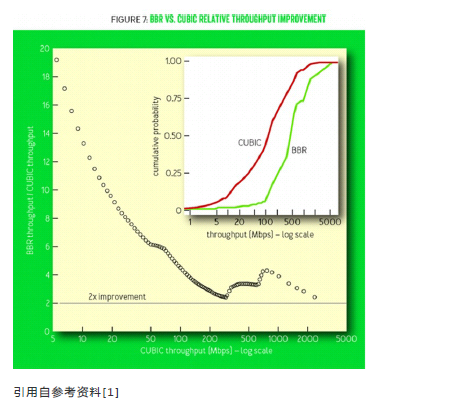
上图中,横轴是CUBIC的吞吐量,纵轴是BBR的吞吐量与CUBIC吞吐量之比,可见在吞吐量情况低的情况下,BBR与CUBIC吞吐量之比很大,说明吞吐量越低的网络,BBR性能越卓越。
6.总结
(1)吞吐量的显著提高
BBR已经在Google跨数据中心的内部广域网(B4)上部署,相对于CUBIC,BBR的吞吐量提高了133
(2)易于集成
能够在开源的Linux kernel中应用且只需要改变数据发送端。
7.参考资料
[1]Cardwell,Neal,et al.BBR:Congestion-Based Congestion Control.Queue14.5(2016):50.
[2]Yuchung Cheng,Neal Cardwell.Making Linux TCP Fast[EB/OL]. [2016-10]. http://netdevconf.org/1.2/slides/oct5/04_Making_Linux_TCP_Fast_netdev_1.2_final.pdf
[3]李博杰.Linux Kernel 4.9 中的 BBR 算法与之前的 TCP 拥塞控制相比有什么优势[EB/OL].[2016-12-15].https://www.zhihu.com/question/53559433.
[4]Bomb250.来自Google的TCP BBR拥塞控制算法解析[EB/OL].[2016-10-16].http://blog.csdn.net/dog250/article/details/52830576.
[5]陈皓.TCP 的那些事儿(下)[EB/OL].[2014-5-28].http://coolshell.cn/articles/11609.html
周六,由于要赶一个月底的Deadline,因此选择了在家VPN加班,大半夜就爬起来跑用例,抓数据...自然也就没有时间写文章和外出耍了...不过利用周日的午夜时间(不要问我为什么可以连续24小时不睡觉,因为我觉得吃饭睡觉是负担),我决定把工作上的事情先放下,还是要把每周至少一文补上,这已经成了习惯。由于上周实在太忙乱,所以自然根本没有更多的时间去思考一些“与工作无关且深入”的东西,我指的与工作无关并非意味着与IT,与互联网无关,只是意味着不是目前我在做的。比如在两年前,VPN,PKI这些是与工作有关的,而现在就成了与工作无关的,古代希腊罗马史一直都是与工作无关的,直到我进了罗马历史研究相关的领域去领薪资,直白点说,老板不为之给我支付薪水的,都算是工作无关的东西。玩转与思考这些东西是比较放得开的,不需要对谁负责,没有压力,没有KPI,没有Deadline,完全自由的心态对待之,说不定真的很容易获得真知。
我认识一个草根鼓手朋友,玩转爵士鼓的水准远高于那些所谓的专业鼓手,自然带有一种侠客之风传道授业解惑,鼓槌随心所欲地挥舞在他自己的心中,没有任何负担和障碍,任何的节奏都可以一气呵成,从来不打重复鼓点,那叫一个帅!然而他并非专业考级出来的,是拜师出来后自己摸索的。
要兴趣去自然挥洒,而不是迫于压力去应对。
我也是鼓手,但我打的不是爵士鼓,我是鼓噪者,技术的鼓噪者。本文与TCP BBR算法相关。
0.说明
BBR热了一段时间后终于回归了理性,这显然要比过热地炒作要好很多。这显然也是我所期望的。
本文的内容主要解释一些关于BBR的细节问题。这些问题一般人可能不会关注,但是针对这些问题仔细思考的话,会得到很多有用的东西。在解释这些问题时,我依然倾向于使用图解的方式,但这一次我不再使用Wireshark的tcptrace图了,而是使用时序图的方式,因为这种时序图既然能够令人一目了然地解释TCP三次握手,四次分手,TIME-WAIT等,那它自然也能解释更复杂的机制,比如说拥塞控制。
1.延迟ACK以及ACK丢失并不会影响TCP的传输速率
在大的时间尺度上看,延迟ACK以及ACK丢失并不会对速率造成任何影响,比如一个文件4个TCP段正好发完,即便前面几个ACK全部丢失,只有最后一个到达,那它的传输总时间也是不变的。
但是在细微的时间段内,由于延迟ACK或者ACK丢失带来的时间偏差却是不可忽略的。
首先我们再次看一下BBR是如何测量即时速率的。测量即时速率需要做一个除法,分子是一段时间内成功到达对端的数据包总量,分母就是这段时间。BBR会在每收到一次ACK的时候测量一次即时速率。计算需要的数据分别在数据传输和数据被ACK的时候采样。很显然,我们可以想当然地拍脑袋得出一个算法:
设数据包x发出的时间为t1,数据包x被应答的时间为t2,则在数据包x被应答时采集的即时速率为:
Rate=(从x被发出到x被应答之间一共ACK以及SACK了多少个数据包)/(t2-t1)
但是这会造成什么问题呢?这会造成误差。如下图所示:
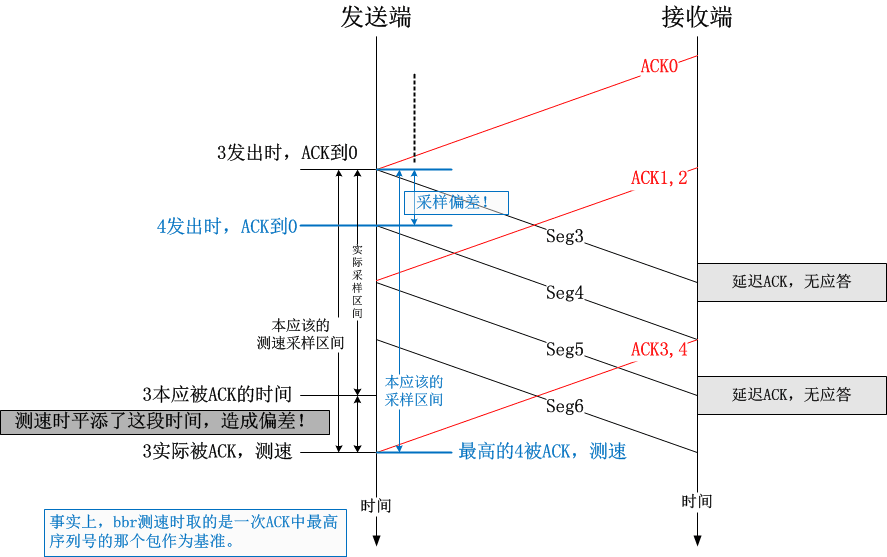
BBR如果依赖这种即时的速率测量机制来运作的话,在ACK丢失或者延迟ACK的情况下会造成测量值偏高。举一个简单的例子:
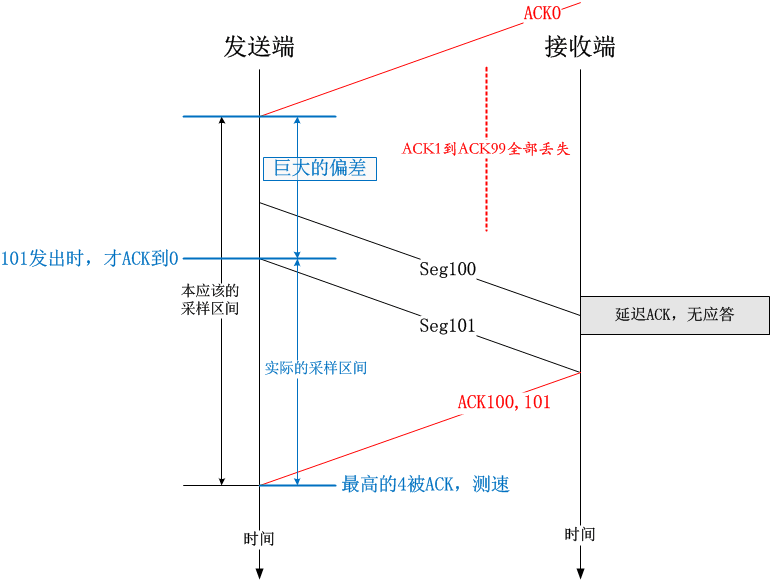
那么,BBR是如何做到不引入这种误差从而精确测量即时速率的呢?很简单,将t1改成至数据包x发出时为止,最后一个(S)ACK收到的时间即可。
详情请参考内核源码的net/ipv4/tcp_rate.c文件,原理非常简单。
所以说,BBR的速率测量值并不受延迟ACK,ACK丢失的影响,其测量方法是妥当的。之所以上面给出一个错误的方法,是想展示一下什么样的做法是不妥当的,以及容易引起质疑的点在哪里。
结论很明确,延迟ACK,ACK丢失,并不影响BBR速率的采集值。
接下来谈第二个问题,关于BBR的拥塞窗口大小的问题。
2.为什么BBR要把计算出来的BDP乘以2作为拥塞窗口值?
这个问题可以换一种问法,即BBR的bbr_cwnd_gain值如何解释:
/* The gain for deriving steady-state cwnd tolerates delayed/stretched ACKs: */
static const int bbr_cwnd_gain = BBR_UNIT * 2;
我们知道,BBR将Pacing Rate作为第一控制要素,按照计算得到的Pacing Rate平缓地发送数据包即可,既然是这样,拥塞窗口的存在还有何意义呢?
BBR的拥塞窗口控制已经退化到了规定一个限额,它主要是为了灌满管道,解决由于ACK丢失导致的无包可发的问题。
我先来阐述问题。
BBR第一次把速率控制计算和实际的传输相分离,又一个典型的控制面与数据面相分离的案例。也就是说,BBR核心模块计算出一个速率,然后就把数据包扔给Pacing发送引擎模块(当前的实现是FQ,我自己也实现了一个),具体何时发送由Pacing发送引擎来控制,二者之间通过一个发送缓冲区来交互,具体结构如下图:
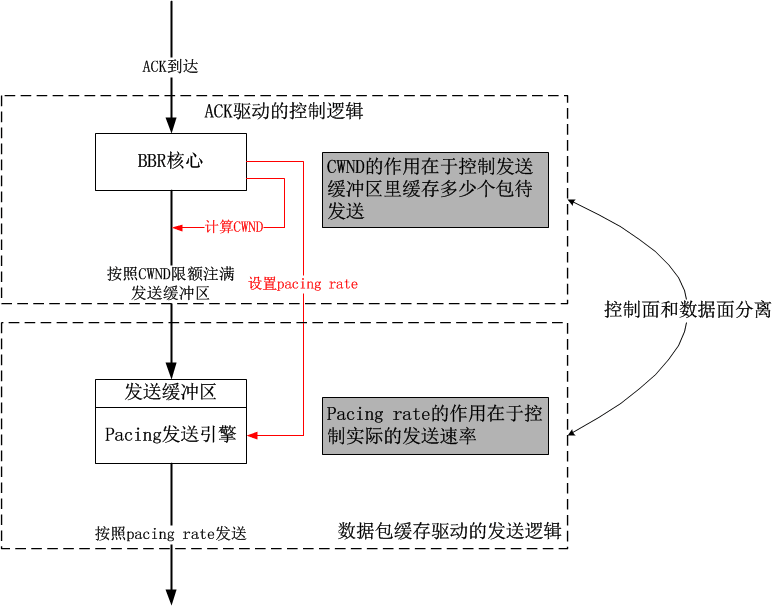
可见,拥塞窗口控制的是“到底扔多少数据到发送缓冲区合适”的。接下来的问题显然就是,拥塞窗口到底是多少合适呢?
虽然BBR分离了控制逻辑和数据发送逻辑,但是TCP的一切都是ACK时钟驱动的,如果ACK该来的时候没有来,比如说丢了,比如延迟了,那么就会影响BBR整个核心的运作,进而影响Pacing发送引擎的数据发送动作,BBR要做的是,即便没有ACK来驱动,也可以自行发送本该发送的数据包,因此Pacing发送引擎的发送缓冲区的意义重要,说白了就是,发送缓冲区里一定要有足够的数据包才行,就算ACK没有来,引擎还是有包可发的。
下面来展示一幅图:
如果这个图有不解之处,像往常一样,大家一起讨论,但总的来讲,我觉得问题不大,所以说才会基于上图产生了下图:
该图示中,我把TCP层的BBR核心模块和FQ的发送模块都画了出来,这样我们可以清晰看出拥塞窗口的作用。实际上,BBR核心模块按照拥塞窗口即inflight的限制,将N个数据包注入到Pacing发送引擎的发送缓冲区中,这些包会在这个缓冲区内部排队,最终在轮到自己的时候被发送出去。由于这个缓冲区里有足够的数据包,所以即使是ACK丢失了多个,或者接收端有LRO导致ACK被大面积聚集且延迟,发送缓冲区里面的数据包也足够发送一阵子了。
维护这么一个发送缓冲区的好处是在缓冲区不溢出(为什么不溢出?那是算出来的,正好两倍)的前提下时时刻刻有包可发,然而代价也是有的,就是增加了RTT,因为在发送缓冲区里排队的时间也要被算在RTT里面的。不过这无所谓,这并不影响性能,数据包不管是在TCP层的发送队列里,还是在FQ的队列里,最终都是要发出去的。值得注意的是,本地的FQ队列和中间节点的队列性质完全不同,本地的队列是独占的,主动的,而中间节点队列是共享的,被动的,所以这里并没有因为RTT的增加而损失性能。这就好比你有一张银行卡专门用来还房贷,由于利息的浮动,所有每月还款金额不同,为了不欠款,你每个月总是要存进足额的钱进去,一般要远多于平均的还贷额度才最保险,但这并不意味着你多存了钱这些钱就亏了,在还清贷款之前,存进去的钱早晚都是要还贷的。
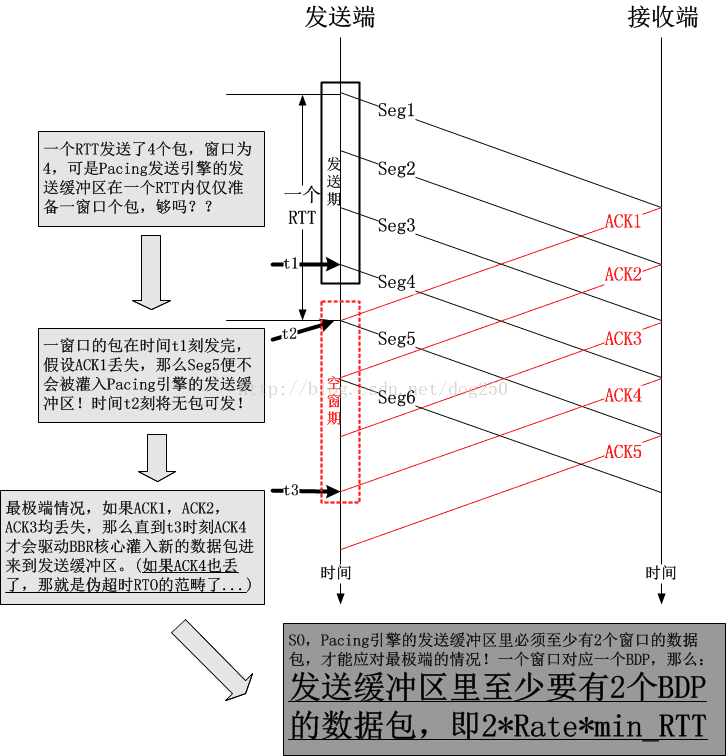
3.为什么在探测最小RTT的时候最少要保持4个数据包
首先要注意的是,用1个包去探测最小RTT会更好,然而效率可能会更低;用5个包去探测最小RTT效率更好,但是可能会导致排队,为什么4个包不多也不少呢?
我尝试用一个时序图来说明问题:
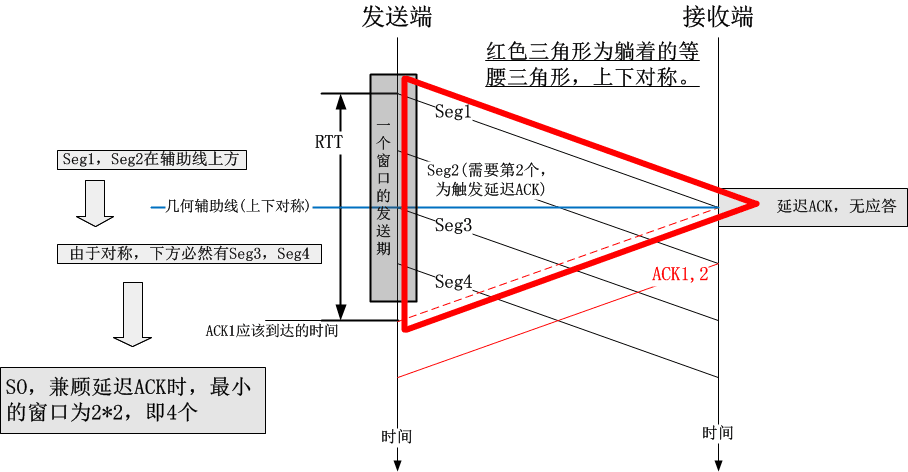
可见,4个包的窗口是合理的,infilght分别是:刚发出的包,已经到达接收端等待延迟应答的包,马上到达的应答了2个包的ACK。一共4个,只有1个在链路上,另外1个在对端主机里,另外2个在ACK里。路上只有1个包,这绝对合理,如果一条路连1个包都容纳不下了,那还玩个屎啊!
以上的论述,仅仅为了帮大家理解以下一段注释的深意:
/* Try to keep at least this many packets in flight, if things go smoothly. For
* smooth functioning, a sliding window protocol ACKing every other packet
* needs at least 4 packets in flight:
*/
static const u32 bbr_cwnd_min_target = 4;
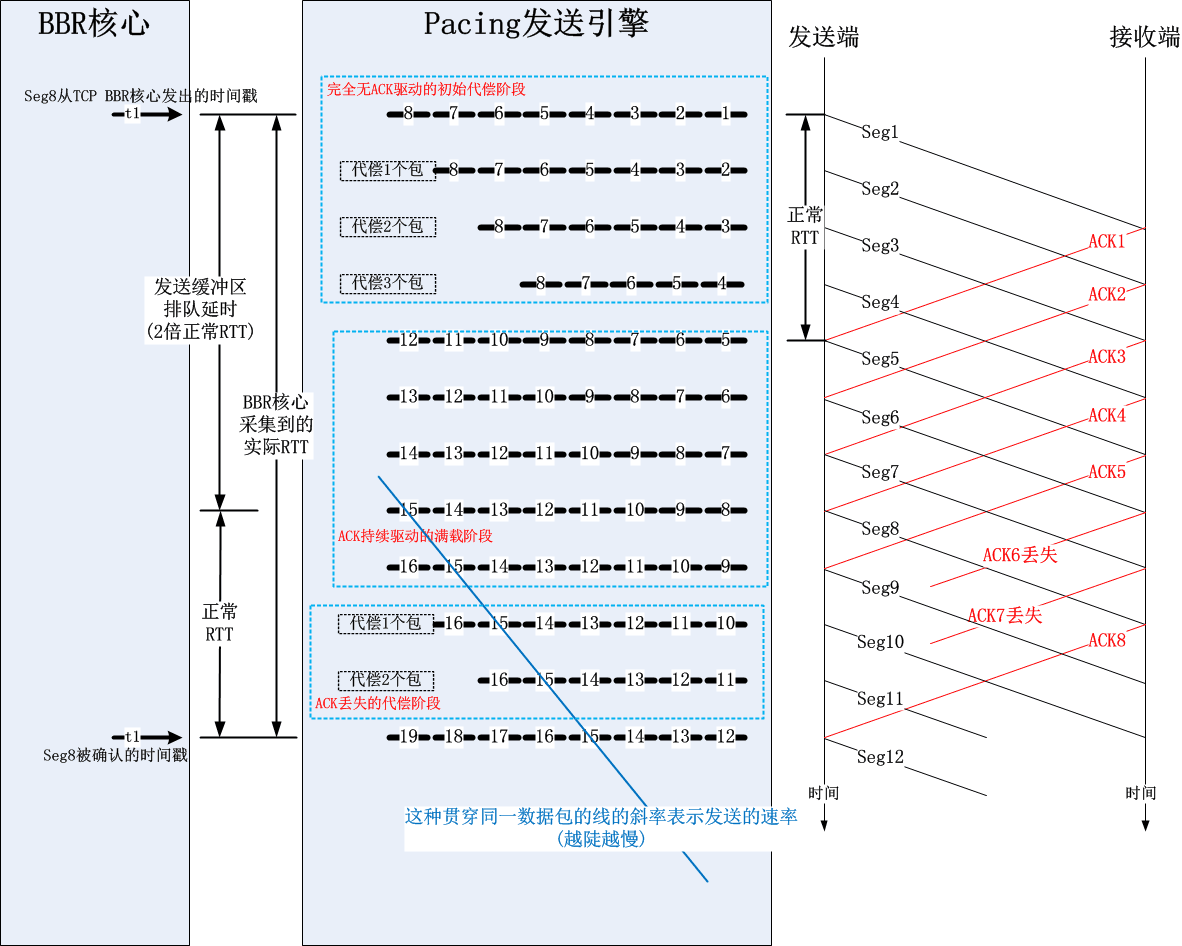
4.用时序图总览一下BBR的Startup/Drain/ProbeBW阶段
我以下面的时序图展示一下BBR的流程:
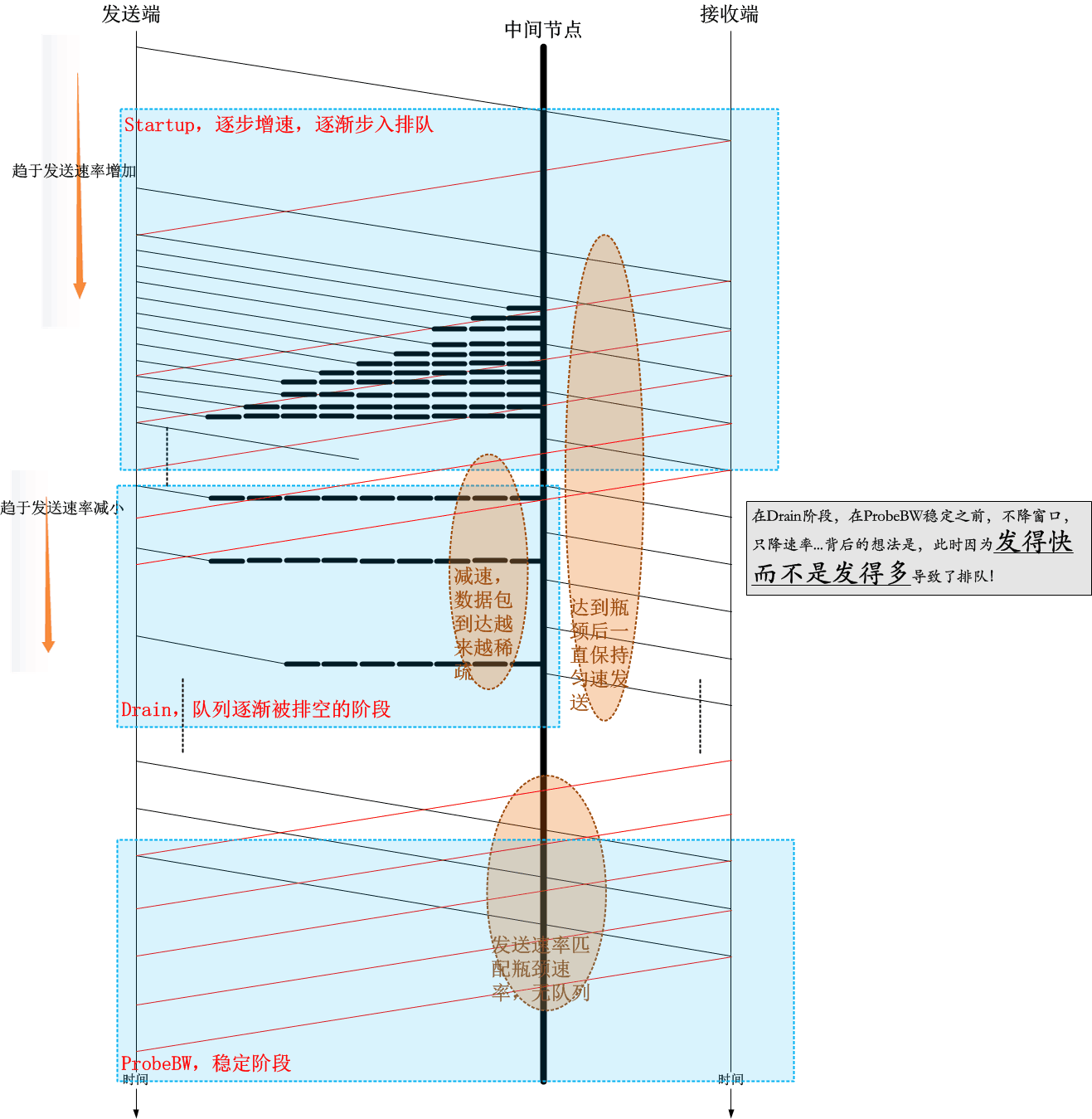
5.Startup阶段拥塞窗口计算的滞后性
我们知道,BBR里面拥塞窗口已经不再是主控因素,事实上它的名字应该改成“发送缓冲区限额”会比较合适了,为了方便起见,我仍然称它为拥塞窗口,虽然它的含义已经改变。
在Startup阶段,发送速率每收到一个ACK都会提高bbr_high_gain:
/* We use a high_gain value of 2/ln(2) because it's the smallest pacing gain
* that will allow a smoothly increasing pacing rate that will double each RTT
* and send the same number of packets per RTT that an un-paced, slow-starting
* Reno or CUBIC flow would:
*/
static const int bbr_high_gain = BBR_UNIT * 2885 / 1000 + 1;
这个其实跟传统拥塞算法的“慢启动”效果是类似的。
然而BBR计算拥塞窗口是用“当前采集到的速率”乘以“当前采集到的最小RTT”来计算的,这就造成了“当前发送窗口”和“当前已经提高的速率”之间的不匹配,所以,计算拥塞窗口的时候,gain因子也必须是bbr_high_gain,从而可以吸收掉速率的实际提升。
6.由ACK通告的接收窗口还有意义吗?
在以往的Reno/CUBIC年代,窗口的计算是根据既有的固定数学公式算出来的,完全仅仅由ACK来驱动,无视事实上的传输速率,所以彼一时的拥塞窗口仅仅可以代表网络的情况,即便如此,这种网络状态的结论也是猜的。
到了BBR时代,主动测量传输速率,将网络处理能力和主机处理能力合二为一,如果网络瓶颈带宽为10,而主机处理能力为8,那么显然采集到的带宽不会大于8!反之亦然。如果BBR测量的即时速率很准确的话,我想通告窗口就完全没有意义了,通告的接收窗口会被忠实地反映在发送端采集到的即时速率里。BBR只是重构了拥塞控制算法,但还没有重构TCP处理核心,我想BBR可以重构之!
7.BBR在计算拥塞窗口时其它的关键点
1.延迟ACK的影响
计算拥塞窗口的时候,会将目标拥塞窗口进行一下调整:
/* Reduce delayed ACKs by rounding up cwnd to the next even number. */
cwnd = (cwnd + 1) & ~1U;
此处向上取偶数就是为了平滑最后一个延迟ACK的影响,如果最后一个延迟ACK该来的没来,那么这个向上取偶数可以为之补上。
2.Offload的影响
* To achieve full performance in high-speed paths, we budget enough cwnd to
* fit full-sized skbs in-flight on both end hosts to fully utilize the path:
* - one skb in sending host Qdisc,
* - one skb in sending host TSO/GSO engine
* - one skb being received by receiver host LRO/GRO/delayed-ACK engine
...
/* Allow enough full-sized skbs in flight to utilize end systems. */
cwnd += 3 * bbr->tso_segs_goal;
8.关于我的Pacing发送引擎
我在今年1月份写了一版和TCP BBR相结合的Pacing发送引擎,以消除FQ对RTT测量值(增加排队延迟)的影响,详见:
《彻底实现Linux TCP的Pacing发送逻辑-普通timer版》
《彻底实现Linux TCP的Pacing发送逻辑-高精度hrtimer版》
个人觉得我这个要比FQ那个好很多,毕竟是原汤化原食的做法吧。
直接在TCP层做Pacing其实并不那么Cheap,因为三十多年来,TCP并没有特别严重的Buffer bloat问题,所以TCP的核心框架实现几乎都是突发数据包的,完全靠ACK来驱动发送,这个TCP核心框架比较类似一个令牌桶,而不是一个整型器!
令牌桶:决定能不能发送;
整型器:决定如何发送数据,是突发还是Pacing发送;
可见这两者是完全不同的机制!要想把一个改成另一个,这个重构的工作量是可想而知。因此我实现的那个TCP Pacing只是一个简版。真正要做得好的话,势必要重构TCP发送队列的操作策略,比如出队,入队,调度策略。
现阶段,我们能使用的一个稳定版本的Pacing替代方案就是FQ,我们看看Linux的注释怎么说:
/* Set the sk_pacing_rate to allow proper sizing of TSO packets.
* Note: TCP stack does not yet implement pacing.
* FQ packet scheduler can be used to implement cheap but effective
* TCP pacing, to smooth the burst on large writes when packets
* in flight is significantly lower than cwnd (or rwin)
*/
结语
今天是周六,白天我折腾了一天工作,结果没有什么结果,也算认了。我又不能让这么一天就这么过去,于是我去超市买了一瓶真露,回到家看了个系列纪录片(关于甲午战争的),然后写完并补充了这篇文章,唉,一想到天亮我就倍感恐惧,老婆一天都要去代课,小小下午还有排练和培训,家里还有一大堆挂件安装工作...
写本文的初衷一部分来自于工作,更多的来自于发现国内几乎还没有中文版的关于TCP bbr算法的文章,我想抢个沙发。本文写于2016/10/15!
本文的写作方式可能稍有不同,之前很多关于OpenVPN,Netfilter,IP路由,TCP的文章中,我都是先罗列了问题,然后阐述如何解决这个问题。但是本文不同!本文的内容来自于我十分厌恶的一个领域,其中又牵扯到我十分厌恶的一家公司-华夏创新(Appex),这些令我厌恶的东西让我不得不放弃很多的东西。所以,我不会先说业界遇到了什么问题,而是直接步入主题,阐述bbr算法的组成。我十分讨厌与人谈论关于TCP拥塞控制的话题,一方面是因为这个话题太过发散,任何人都可以说出自己的理由让人信服自己的忽悠人的算法,另一方面,我觉得我接触到的所有人当中并没有人真的懂这些(当然,我也不懂!而且比那些人更加不懂!),所以我宁可花些时间在预研或者研发上,我也不想跟人瞎逼逼或者听别人瞎逼逼。
随便提出一个TCP拥塞算法,任何人都可以做到说它好,任何人也可以做到说它不好,因为没人真的懂网络,所以聊这些是没有意义的!TCP不是网络范畴的技术,它是控制论范畴的,TCP技术不属于网络技术!
我的观点是,正确的做法只有一种,其它的都是错误的做法,都没有意义!
国庆节前,我看到了bbr算法,发现它就是那个唯一正确的做法(可能有点夸张,但起码它是一个通往正确道路的起点!),所以花了点时间研究了一下它,包括其patch的注释,patch代码,并亲自移植了bbr patch到更低版本的内核,在这个过程中,我也产生了一些想法,作为备忘,整理了一篇文章,记如下,多年以后,再看TCP bbr算法的资料时,我的记录也算是中文社区少有的第一个吃螃蟹记录了,也算够了!
正文之前,给出本文的图例:
使用BBR之前
我希望更多的人试用这个算法,并且与我共享测试结果,包括但不限于算法的带宽利用率,抢占性等!特别是温州皮鞋产老板!这个算法并不是我写的,既然开源那就不应该封闭于任何公司或者个人,所以我有权在这里就我知道的东西述说一二。
我深深地明白,我以下写的这些有很多理解不周到的地方,我也深深的明白很多传统学生出身的人不会告诉我那些疏漏,我指的是温州老板那样的人,因为他们几乎都是在索取而不分享,如果他们发现了我的疏漏,他们会默默记上一笔,到头来他们学会了我分享的东西,他们又改进了我的疏漏(但是并不告诉我!),他们又拥有自己独立学会的那些东西(他们也不会告诉我!),所以,最终,他们任何人都比我更加博学且高明!然而不幸的是,这就是我的目标,我并不在乎那些人,我甚至不会在乎自己!
所以,赶紧试用bbr吧,赶紧改进吧,功劳是你的,虚无是我的!
BBR的组成
bbr算法实际上非常简单,在实现上它由5部分组成:
1.即时速率的计算
计算一个即时的带宽bw,该带宽是bbr一切计算的基准,bbr将会根据当前的即时带宽以及其所处的pipe状态来计算pacing rate以及cwnd(见下文),后面我们会看到,这个即时带宽计算方法的突破式改进是bbr之所以简单且高效的根源。计算方案按照标量计算,不再关注数据的含义。在bbr运行过程中,系统会跟踪当前为止最大的即时带宽。
2.RTT的跟踪
bbr之所以可以获取非常高的带宽利用率,是因为它可以非常安全且豪放地探测到带宽的最大值以及rtt的最小值,这样计算出来的BDP就是目前为止TCP管道的最大容量。bbr的目标就是达到这个最大的容量!这个目标最终驱动了cwnd的计算。在bbr运行过程中,系统会跟踪当前为止最小RTT。
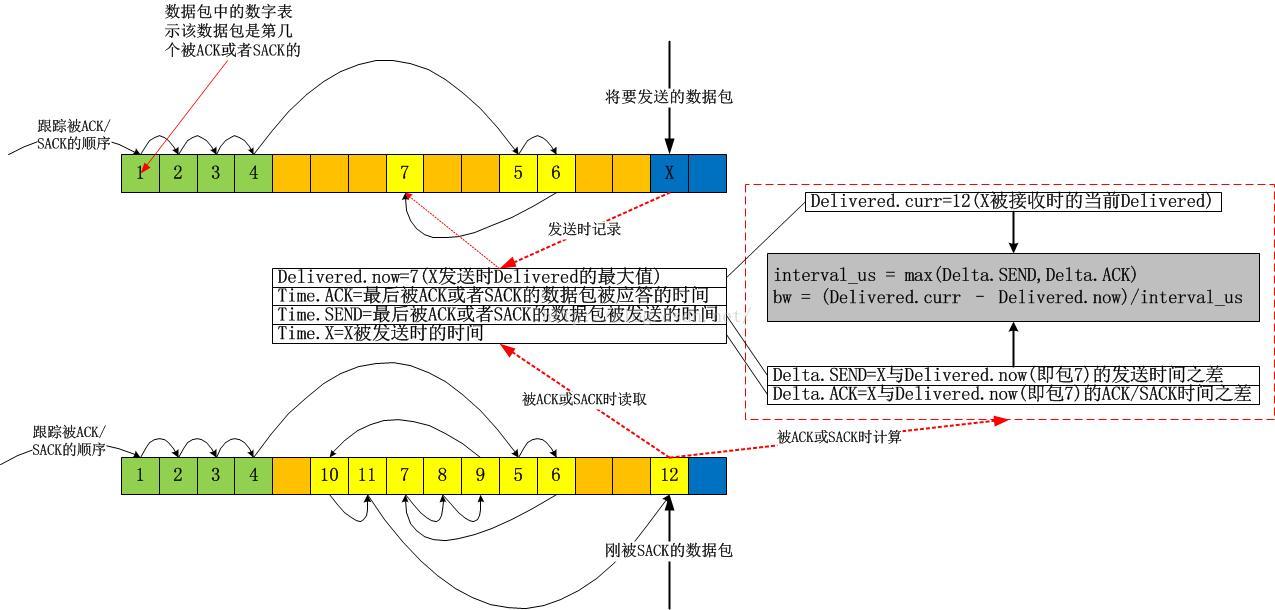
3.bbr pipe状态机的维持
bbr算法根据互联网的拥塞行为有针对性地定义了4中状态,即STARTUP,DRAIN,PROBE_BW,PROBE_RTT。bbr通过对上述计算的即时带宽bw以及rtt的持续观察,在这4个状态之间自由切换,相比之前的所有拥塞控制算法,其革命性的改进在于bbr拥塞算法不再跟踪系统的TCP拥塞状态机,而旨在用统一的方式来应对pacing rate和cwnd的计算,不管当前TCP是处在Open状态还是处在Disorder状态,抑或已经在Recovery状态,换句话说,b br算法感觉不到丢包,它能看到的就是bw和rtt!
4.结果输出-pacing rate和cwnd
首先必须要说一下,bbr的输出并不仅仅是一个cwnd,更重要的是pacing rate。在传统意义上,cwnd是TCP拥塞控制算法的唯一输出,但是它仅仅规定了当前的TCP最多可以发送多少数据,它并没有规定怎么把这么多数据发出去,在Linux的实现中,如果发出去这么多数据呢?简单而粗暴,突发!忽略接收端通告窗口的前提下,Linux会把cwnd一窗数据全部突发出去,而这往往会造成路由器的排队,在深队列的情况下,会测量出rtt剧烈地抖动。
bbr在计算cwnd的同时,还计算了一个与之适配的pacing rate,该pacing rate规定cwnd指示的一窗数据的数据包之间,以多大的时间间隔发送出去。
5.其它外部机制的利用-fq,rack等
bbr之所以可以高效地运行且如此简单,是因为很多机制并不是它本身实现的,而是利用了外部的已有机制,比如下一节中将要阐述的它为什么在计算带宽bw时能如此放心地将重传数据也计算在内...
带宽计算细节以及状态机
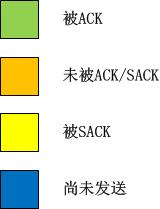
1.即时带宽的计算
bbr作为一个纯粹的拥塞控制算法,完全忽略了系统层面的TCP状态,计算带宽时它仅仅需要两个值就够了:
1).应答了多少数据,记为delivered;
2).应答1)中的delivered这么多数据所用的时间,记为interval_us。
将上述二者相除,就能得到带宽:
bw = delivered/interval_us
非常简单!以上的计算完全是标量计算,只关注数据的大小,不关注数据的含义,比如delivered的采集中,bbr根本不管某一个应答是重传后的ACK确认的,正常ACK确认的,还是说SACK确认的。bbr只关心被应答了多少!
这和TCP/IP网络模型是一致的,因为在中间链路上,路由器交换机们也不会去管这些数据包是重传的还是乱序的,然而拥塞也是在这些地方发生的,既然拥塞点都不关心数据的意义,TCP为什么要关注呢?反过来,我们看一下拥塞发生的原因,即数据量超过了路由器的带宽限制,利用这一点,只需要精心地控制发送的数据量就好了,完全不用管什么乱序,重传之类的。当然我的意思是说,拥塞控制算法中不用管这些,但这并不意味着它们是被放弃的,其它的机制会关注的,比如SACK机制,RACK机制,RTO机制等。
接下来我们看一下这个delivered以及interval_us的采集是如何实现的。还是像往常一样,我不准备分析源码,因为如果分析源码的话,往往难以抓住重点,过一段时间自己也看不懂了,相反,画图的话,就可以过滤掉很多诸如unlikely等异常流或者当前无需关注的东西:
上图中,我故意用了一个极端点的例子,在该例子中,我几乎都是使用的SACK,当X被SACK时,我们可以根据图示很容易算出从Delivered为7时的数据包被确认到X被确认为止,一共有12-7=5个数据包被确认,即这段时间网络上清空了5个数据包!我们便很容易算出带宽值了。我的这个图示在解释带宽计算方法之外,还有一个目的,即说明bbr在计算带宽时是不关注数据包是否按序确认的,它只关注数量,即数据包被网络清空的数量。实实在在的计算,不猜Lost,不猜乱序,这些东西,你再怎么猜也猜不准!
计算所得的bw就是bbr此后一切计算的基准。
2.状态机
bbr的状态机转换图以及注释如下图所示:
通过上述的状态机以及上一节的带宽计算方式,我们知道了bbr的工作方式:不断地基于当前带宽以及当前的增益系数计算pacing rate以及cwnd,以此2个结果作为拥塞控制算法的输出,在TCP连接的持续过程中,每收到一个ACK,都会计算即时的带宽,然后将结果反馈给bbr的pipe状态机,不断地调节增益系数,这就是bbr的全部,我们发现它是一个典型的封闭反馈系统,与TCP当前处于什么拥塞状态完全无关,其简图如下:
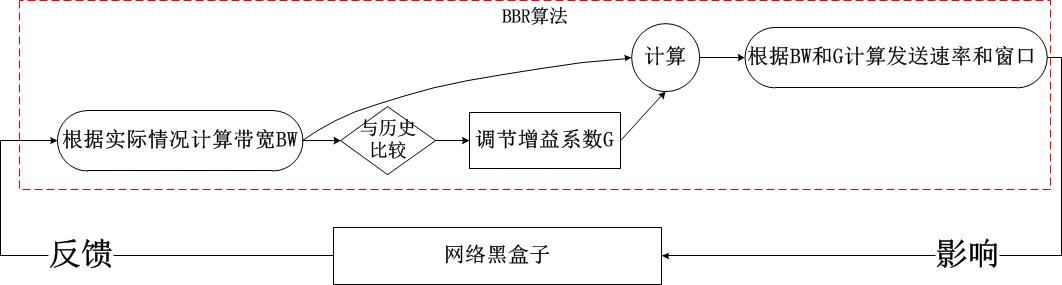
这非常不同于之前的所有拥塞控制算法,在之前的算法中,我们发现拥塞算法内部是受外部的拥塞状态影响的,比如说在Recovery状态下,甚至都不会进入拥塞控制算法,在bbr进入内核之前,Linux使用PRR算法控制了Recovery状态的窗口调整,即便说这个时候网络已经恢复,TCP也无法发现,因为TCP的Recovery状态还未恢复到Open,这就是根源!
pacing rate以及cwnd的计算
这一节好像是重点中的重点,但是我觉得如果理解了bbr的带宽计算,状态机以及其增益系数的概念,这里就不是重点了,这里只是一个公式化的结论。
pacing rate怎么计算?很简单,就是是使用时间窗口内(默认10轮采样)最大BW。上一次采样的即时BW,用它来在可能的情况下更新时间窗口内的BW采样值集合。这次能否按照这个时间窗口内最大BW发送数据呢?这样看当前的增益系数的值,设为G,那么BW*G就是pacing rate的值,是不是很简单呢?!
至于说cwnd的计算可能要稍微复杂一点,但是也是可以理解的,我们知道,cwnd其实描述了一条网络管道(rwnd描述了接收端缓冲区),因此cwnd其实就是这个管道的容量,也就是BDP!
BW我们已经有了,缺少的是D,也就是RTT,不过别忘了,bbr一直在持续搜集最小的RTT值,注意,bbr并没有采用什么移动指数平均算法来“猜测”RTT(我用猜测而不是预测的原因是,猜测的结果往往更加不可信!),而是直接冒泡采集最小的RTT(注意这个RTT是TCP系统层面移动指数平均的结果,即SRTT,但brr并不会对此结果再次做平均!)。我们用这个最小RTT干什么呢?
当前是计算BDP了!这里bbr取的RTT就是这个最小RTT。最小RTT表示一个曾经达到的最佳RTT,既然曾经达到过,说明这是客观的可以再次达到的RTT,这样有益于网络管道利用率最大化!
我们采用BDP*G'就算出了cwnd,这里的G'是cwnd的增益系数,与带宽增益系数含义一样,根据bbr的状态机来获取!
bbr的细节浅述
该节的题目比较怪异,既然是细节为什么又要浅述??
这是我的风格,一方面,说是细节是因为这些东西还真的很少有人注意到,另一方面,说是浅述,是因为我一般都不会去分析代码以及代码里每一个异常流,我认为那些对于理解原理帮助不大,那些东西只是在研发和优化时才是有用的,所以说,像往常一样,我这里的这个小节还是一如既往地去谈及一些“细节”。
1.豪放且大胆的安全探测
在看到bbr之后,我觉得之前的TCP拥塞控制算法都错了,并不是思想错了,而是实现的问题。
bbr之所以敢大胆的去探测预估带宽是因为TCP把更多的权力交给了它!在bbr之前,很多本应该由拥塞控制算法去处理的细节并不归拥塞控制算法管。在详述之前,我们 必须分清两件事:
1).传输多少数据?
2).传输哪些数据?
按照“上帝的事情上帝管,凯撒的事情凯撒管”的原则,这两件事本来就该由不同的机制来完成,不考虑对端接收窗口的情况下,拥塞窗口是唯一的主导因素,“传输多少数据” 这件事应该由拥塞算法来回答,而“传输哪些数据”这个问题应该由TCP拥塞状态机以及SACK分布来决定,诚然这两个问题是不同的问题,不应该杂糅在一起。
然而,在bbr进入内核之前的Linux TCP实现中,以上两个问题并不是分得特别清。TCP的拥塞状态只有在Open时才是上述的职责分离的完美样子,一旦进入Lost或者Recovery,那么拥塞控制算法即便对“问题1):传输多少数据”都无能为力,在Linux的现有实现中,PRR算法将接管一切,一直把窗口下降到ssthresh,在Lost状态则反应更加激烈,直接cwnd硬着陆!随后等丢失数据传输成功后再执行慢启动....在重新进入Open状态之前,拥塞控制算法几乎不会起作用,这并不是一种高速公路上的模式(小碰擦,拍照后停靠路边,自行解决),更像是闹市区的交通事故处理方式(无论怎样,保持现场,直到交警和保险公司的人来现场处置)。
bbr算法逃离了这一切错误的做法,在bbr的patch中,并非只是完成了一个tcp_bbr.c,而是对整个TCP拥塞状态控制框架进行了大手术,我们可以从以下的拥塞控制核心函数中可见一斑:
static void tcp_cong_control(struct sock *sk, u32 ack, u32 acked_sacked,
int flag, const struct rate_sample *rs)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
if (icsk->icsk_ca_ops->cong_control) {
// 如果是bbr,则完全被bbr接管,不管现在处在什么状态!
/* 目前而言,只有bbr使用了这个机制,但我相信,不久的将来,
* 会有越来越多的拥塞控制算法使用这个统一的完全接管机制!
* 就我个人而言,在几个月前就写过一个patch,接管了tcp_cwnd_reduction
* 这个prr的降窗过程。如果当时有了这个框架,我就有福了!
*/
icsk->icsk_ca_ops->cong_control(sk, rs);
return;
}
// 否则继续以往的错误方法!
if (tcp_in_cwnd_reduction(sk)) {
/* Reduce cwnd if state mandates */
// 非Open状态中拥塞算法不受理窗口调整
tcp_cwnd_reduction(sk, acked_sacked, flag);
} else if (tcp_may_raise_cwnd(sk, flag)) {
/* Advance cwnd if state allows */
tcp_cong_avoid(sk, ack, acked_sacked);
}
tcp_update_pacing_rate(sk);
}
在这个框架下,无论处在哪个状态(Open,Disorder,Recovery,Lost...),如果拥塞控制算法自己声明有这个能力,那么具体可以传输多少数据,完全由拥塞控制算法自行决定,TCP拥塞状态控制机制不再干预!
2.为什么bbr可以忽略Recovery和Lost状态
看懂了以上第1点,这一点就很容易理解了。
在第1点中,我描述了bbr确实忽略了Recovery等非Open的拥塞状态,但是为什么可以忽略呢?一般而言,很多人都会质疑,会说bbr采用这么鲁莽的方式,最终一定会让窗口卡住不再滑动,但是我要反驳,你难道不知道cwnd只是个标量吗?我画一个图来分析:
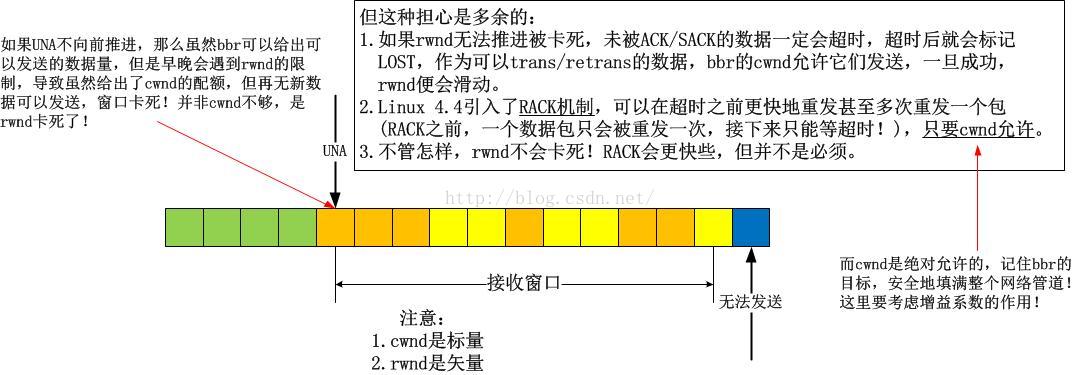
看懂了吗?不存在任何问题!基本上,我们在讨论拥塞控制算法的时候,会忽略流量控制,因为不想让rwnd和cwnd杂糅起来,但是在这里,它们相遇了,幸运的是,并没有引发冲突!
然而,这并不是全部,本节旨在“浅析”,因此就不会关注代码处理的细节。在bbr的实现中,如果算法外部的TCP拥塞状态已经进入了Lost,那么cwnd该是多少呢?在bbr之前的拥塞算法中,包括cubic在内的所有算法中,当TCP核心实现从将cwnd调整到1或者prr到ssthresh一直到恢复到Open状态,拥塞算法无权干预流程,然而bbr不。虽然说进入Lost状态后,cwnd会硬着陆到1,然而由于bbr的接管,在Lost期间,cwnd还是可以根据即时带宽调整的!
这意味着什么?
这意味着bbr可以区别噪声丢包和拥塞丢包了!
a).噪声丢包
如果是噪声丢包,在收到reordering个重复ACK后,由于bbr并不区分一个确认是ACK还是SACK引起的,所以在bbr看来,即时带宽并没有降低,可能还有所增加,所以一个数据包的丢失并不会引发什么,bbr依旧会给出一个比较大的cwnd配额,此时虽然TCP可能已经进入了Recovery状态,但bbr依旧按照自己的bw以及调整后的增益系数来计算cwnd的新值,过程中并不会受到任何TCP拥塞状态的影响。
如此一来,所有的噪声丢包就被区别开来了!bbr的宗旨是:“首先,在我的bw计算指示我发生拥塞之前,任何传统的TCP拥塞判断-丢包/时延增加,均全部失效,我并不care丢包和RTT增加”,随后brr又会说:“但是我比较care的是,RTT在一段时间内(随你怎么配,但我个人倾向于自学习)都没有达到我所采集到的最小值或者更小的值!这也许意味着着链路真的发生拥塞了!”...
b).拥塞丢包
将a)的论述反过来,我们就会得到奇妙的封闭性结论。这样,bbr不光是消除了吞吐曲线的锯齿(ssthresh所致,bbr并不使用ssthresh!),而且还消除了传统拥塞控制算法(指bbr以及封闭的傻逼Appex之前)的判断滞后性问题。在cubic发现丢包进而判断为拥塞时,拥塞可能已经缓解了,但是cubic无法发现这一点。为什么?原因在于cubic在计算新的cwnd的时候,并没有把当前的网络状态(比如bw)当作参数,而只是一味的按照数学意义上的三次方程去计算,这是错误的,这不是一个正确的反馈系统的做法!
基于a)和b),看到了吧,这就是新的拥塞判断机制!综合考虑丢包和RTT的增加:
b-1).如果丢包时真的发生了拥塞,那么测量的即时带宽肯定会减少,否则,丢包即拥塞就是谎言。
b-2).如果RTT增加时真的发生了拥塞,那么测量的即时带宽肯定会减少,否则,时延增加即拥塞就是谎言。
_bbr测量了即时带宽,这个统一cwnd和rtt的计量,完全忽略了丢包,因此bbr的算法思想是TCP拥塞控制的正轨!事实上,丢包本就不应该作为一种拥塞的标志,它只是拥塞的表现。
3.状态机的点点滴滴
我在上文已经呈现了关于STARTUP,DRAIN,PROBE_BW,PROBE_RTT的状态图以及些许细节,当时我指出这个状态图的目标是为了完成bbr的目标,即填满整个网络!在这个状态图看来,所有已知的东西就是当前的即时带宽,所有可以计算的东西就是增益系数,然后根据这两个元素就可以轻易计算出pacing rate和cwnd,是不是很简单呢?整体看来就是就是这么简单,但是从细节上看,不同的pipe状态中的增益系数的计算却是值得推敲的,以下是bbr处在各个状态时的增益
系数:
STARTUP:2~3
DRAIN:pacing rate的增益系数为1000/2885,cwnd的增益系数为1000/2005+1。
PROBE_BW:5/4,1,3/4,bbr在PROBE_BW期间会随机在这些增益系数之间选择当前的增益系数。
PROBE_RTT:1。但是在探测RTT期间,为了防止丢包,cwnd会强制cut到最小值,即4个MSS。
我们可以看到,bbr并没有明确的所谓“降窗时刻”,一切都是按照状态机来的,期间丝毫不会理会TCP是否处在Open,Recovery等状态。在此前的拥塞控制算法中,除了Vegas等基于延时的算法会在计算得到的target cwnd小于当前cwnd时视为拥塞而在算法中降窗外,其它的所有基于丢包的算法中均是检测到丢包(RTO或者reordering个重复ACK)时降窗的,可悲的是,这个降窗过程并不受拥塞算法的控制,拥塞算法只能消极地给出一个ssthresh值,即降窗的目标,这显然是令人无助的!
bbr不再关注丢包事件,它并不把丢包当成很严重的事,这事也不归它管,只要TCP拥塞状态机控制机制可以合理地将一些包标记为LOST,然后重传它们便是了,bbr能做的仅仅是告诉TCP一共可以发出去多少数据,仅此而已!然而,如果TCP并没有把LOST数据包合理标记好,bbr并不care,它只是根据当前的bw和增益系数给出下一个pacing rate以及cwnd而已!
4.关于Sched FQ
这里涉及的是bbr之外的东西,Fair queue!在bbr的patch最后,会发现几行注释:
NOTE: BBR must be used with the fq qdisc ("man tc-fq") with pacing enabled, since pacing is integral to the BBR design and implementation. BBR without pacing would not function properly, and may incur unnecessary high packet loss rates.
记住这几行文字并理解它们。
这是bbr最为重要的一方面。虽然说Linux的TCP实现早就支持的pacing rate,但直到4.8版本都没有在TCP层面支持它,很大的一部分原因是因为借助已有的FQ可以很完美地实现pacing rate!TCP可以借助FQ来实现平缓而非突发的数据发送!
关于FQ的详细内容可以去看相关的manual和源码,这里要说的仅仅是,FQ可以根据bbr设置的pacing rate将一个cwnd内的数据的发送从“突发到网络”这种行为变换到“平缓发送到网路”的行为,所谓的平缓发送指的就是数据包是按照带宽速率计算的间隔一个个发送到网络的,而不是突发进网络的!
这样一来,就给了网络缓存以缓解的机会!记住,关键问题是bbr会在每收到ACK/SACK时计算bw,这个精确的测量不会漏掉任何可乘之机,即便当前网络拥塞了,它只要能在下一时刻恢复,bbr就可以发现,因此即时带宽通常可以表现这一点!
5.其它
还有关于令牌桶监管发现(lt policed)的主题,long term采样的主题,留到后面的文章具体阐述吧,本文已经足够长了。
6.bufferbloat问题
关于深队列,数据包如何如何长时间排队但不丢包却引发RTO,对于浅队列,数据包如何如何频繁丢包...谈起这个话题我一开始想滔滔不绝,后来想骂人,现在我三缄其口!任何人都知道端到端的QoS是一个典型的反馈系统,但是任何人都只是夸夸其谈,我选择的是闭口不说,如果非要我说,我的回答就是:不知道!
这是一个怎么说都能对又怎么说都能错的话题,就像股票预测那样,所以我选择闭嘴。
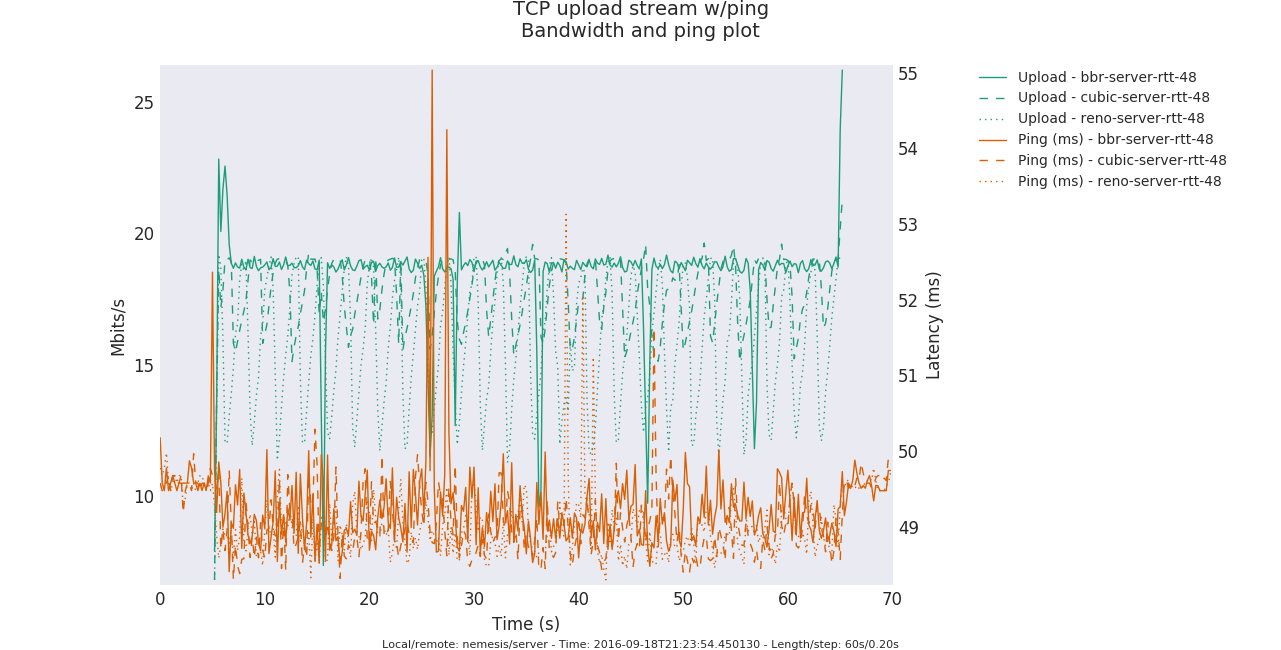
bbr算法到来后,单单从公共测试结果上看,貌似解决了bufferbloat问题,也许吧,也许。bbr好像真的开始在高速公路上飚车了...最后给出一个测试图,来自《A quick look at TCP BBR》:
bbr代码的简单性和复杂性
我一向觉得TCP拥塞控制算法太过复杂,而复杂的东西基本上就是用来装逼的垃圾,直到遇到了bbr。
Neal Cardwell提供的patch简单而又直接,大家可以从该bbr的pach上一看究竟!在bbr模块之外,Neal Cardwell主要更改了tcp_ack函数里面关于delivered计数的部分以及拥塞控制主函数,这一切都十分显然,只要patch代码就可以一目了然。在数据包被发送的时候-不管是初次发送还是重传,均会被当前TCP的连接状况记录在该数据包的tcp_skb_cb中,在数据包被应答的时候-不管是被ACK还是被SACK,均会根据当前的状态和其tcp_skb_cb中状态计算出一个带宽,这些显而易见的逻辑相比任何人都应该知道哪里的代码被修改了!
然而,这种查找和确认的工作太令人感到悲哀,读懂代码是容易的,移植代码是无聊的,因为时间卡的太紧!我必须要说的是,如果一件感兴趣的事情变成了必须要完成的工作,那么做它的激情起码减少了1/4,OK,还不算太坏,然而如果这个必须完成的工作有了deadline,那么激情就会再减少1/4,最后,如果有人在背后一直催,那么完蛋,这件事可以瞬间完成,但是我可以郑重说明这是凑合的结果!但是实际上,这件事本应该可以立即快速有高质量的完成并验收!
写在最后
我本来应该可以把本文写的更长些,但是打住了,因为我没有时间,没有精力,更没有业务去继续,我写这一切纯粹是闲的,周末比较无聊,所以信手拈来几笔画了几张图,完成了本文。
我之所以不继续下去的原因更多的是只是因为没有时间!我比较讨厌急功近利,我比较喜欢工匠精神,一种时间打磨精品的精神,一种自由引导创造的精神,如果没有时间,什么都是掰扯!
比较讽刺的是,这个bbr算法显然不是一个“一周或者两周搞定的算法”,但是中国人却希望花更少的时间去将其“拿来”就用....中国人认为任何事情都是可以靠加班可以解决的,所谓愚公移山,精卫填海,铁杵磨针,人心齐泰山移的精神早已深入人心,殊不知这种XX行径根本经不起推敲,你把全中国14亿不止的人聚集起来一起去推泰山,看能推得动么?你真的用一根铁杵去磨针么?为什么不去想着买针!?傻逼!我不说了,本文所写的技术中透露的态度,与生活无关,亦与工作无关,这种态度完全是我自己一个人的世界,与不理解以及反对的人,不讨论,不争论,不辩论...!技术是大家的,态度是个人的。
原文出处:从TCP拥塞本质看BBR算法及其收敛性(附CUBIC的改进/NCL机制)
本文试图给出一些与BBR算法相关但却是其之外的东西。
1.TCP拥塞的本质
注意,我并没有把题目定义成网络拥塞的本质,不然又要扯泊松到达和排队论了。事实上,TCP拥塞的本质要好理解的多!TCP拥塞绝大部分是由于其”加性增,乘性减“的特性造成的!
也就是说,是TCP自己造成了拥塞!TCP加性增乘性减的特性引发了丢包,而丢包的拥塞误判带来了巨大的代价,这在深队列+AQM情形下尤其明显。
我尽可能快的解释。争取用一个简单的数学推导过程和一张图搞定。
除非TCP端节点之间的网络带宽是均匀点对点的,否则就必然要存在第二类缓存。TCP并无法直接识别这种第二类缓存。正是这第二类缓存的存在导致了拥塞的代价特别严重。我依然用经典的图作为基准来解释:
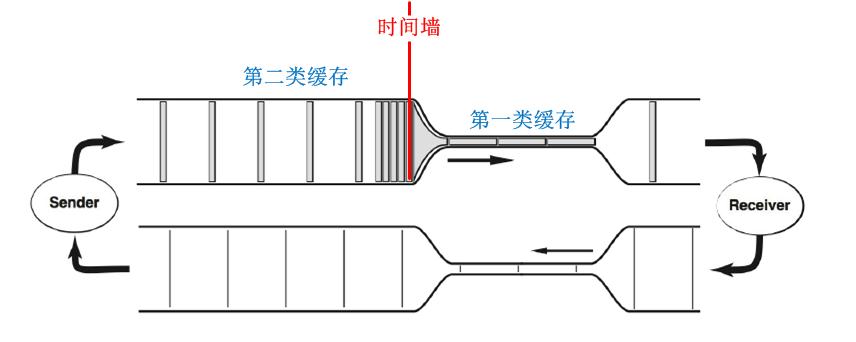
第二类缓存的时间墙特征导致了排队的发生,而排队会导致一个TCP连接中数据包的RTT变大。为了讨论方便,我们假设TCP端节点之间管道最细处(即Bottleneke处)的带宽为B,那么正如上图所表明的,我把TCP端节点之间的网络中,凡是带宽比B大的网络均包含在第二类缓存中,也就是说,凡是会引起排队的路径,均是第二类缓存。
假设TCP端节点之间的BDP为C,那么:
C = C1 + C2 (其中C1是网络本身的管道容量,而C2是节点缓存的容量)
由于路径中最小带宽为B,那么整个链路的带宽将由B决定,在排队未发生时(即没有发生拥塞时),假设测量RTT为rtt0,发送速率为B0=B,则:
C1 = B0*rtt0 C = B0rtt0 +C2 > Brtt0
此时,任何事情均为发生,一切平安无事!继续着TCP”加性增“的行为,此时发送端继续线性增加发送速率,到达B1,此时:
B0rtt0 < B1rtt1
C是客观的不变量,这会导致C2开始被填充,即开始轻微排队。排队会造成RTT的增加。假设C2已经被加性增特性填充到满载的临界,此时发送带宽为B2,即:
C = B2rtt2 = Brtt0 + C2
B2*rtt2是定值,rtt2在增大,B2则必须减小!但是”临界值已经达到“这件事反馈到发送端,至少要经过1/2个RTT,在忽略延迟ACK和ACK丢失等反馈失灵情形下,最多的反馈时间要1个RTT。问题是,TCP发送端怎么知道C2已经被填满了??它不知道!除非再增加一些窗口,多发一个数据包!这行为是如此的小心翼翼,以至于你会认为这是多么正确的做法!在发送端不知情的情况下,会持续增加或者保持当前的拥塞窗口,但是绝对不会降低,然而此时RTT已经增大,必须降速了!事实上,在丢包事件发生前,TCP是一定会加性增窗的,也就是说,丢包是TCP唯一可以识别的事件!
TCP在临界点的加性增窗行为,目的只是为了探测C2是不是已经被填满。我们来根据以上的推导计算一下这次探测所要付出的代价。由于反馈C2已满的时间是1/2个RTT到1个RTT,取决于C2的位置,那么将会在1/2个RTT到1个RTT的时间内面临着丢包!注意,这里的代价随着C2的增加而增加,因为C2越大,RTT的最终测量值,即rtt2则越大!这就是深队列丢包探测的问题。
然而,在30多年前,正是这个”加性增“行为,直接导出了”基于丢包的拥塞控制算法“。那时没有深队列,问题貌似还不严重。但随着C2的增加,问题就越来越严重了,RTT的增大使得丢包处理的代价更大!
记住,对丢包的敏感不是错误,基于丢包的拥塞探测的算法就是这样运作的,错误之处在于,丢包的代价太大-窗口猛降,造成管道被清空。这是由于深队列的BufferBloat引发的问题,在浅队列中问题并不严重。随着路由器AQM技术的发展,好的初衷会对基于丢包的拥塞探测产生反而坏的影响。
现在,我们明白了,之所以基于丢包的拥塞控制算法的带宽利用率低,就是由于其填充第二类缓存所平添排队延迟造成的虚假且逐渐增大的RTT最终导致了BDP很大的假象,而这一切的目的,却仅仅是为了探测丢包,自以为在丢包前已经100%的利用了带宽,然而在丢包后,所有的一切都加倍还了回去!是丢包导致了带宽利用率的下降,而不是增加!!
总结一句,用第二类缓存来探测BDP是一种透支资源的行为。
我一直觉得这不是TCP的错,但在发现BBR是如此简单之后,不再这么认为了,事实上,通过探测时间窗口内的最大带宽和最小RTT,就可以明确知道是不是已经填满了第一类缓存,并停止继续填充第二类缓存,即向最小化排队的方向收敛!曾经的基于时延的算法,比如Vegas,其实已经在走这条路了,它已经知道RTT的增加意味着排队了,只是它没有采用时间窗口过滤掉常规波动,而是采用了RTT增量窗口来过滤波动,最终甚至由于RTT抖动主动减少窗口,所以会造成竞争性不足。不管怎样,这是一种君子行为,它总是无力对抗基于丢包算法的流氓行为。
BBR综合了二者,对待君子则君子(不会填充第二类缓存,造成排队,因为一旦排队,所有连接的RTT均会增加,对类似Vegas的不利),对待流氓则流氓(采用滑动时间窗口抗带宽噪声,采用固定超时时间窗口抗RTT噪声,时间窗口内,决不降速),这是一种什么行为?我觉得比较类似警察的行为...
如果不是很理解,那么看看那些高速公路上随意变道或者占用应急车道的行为导致的后果吧(大多数没有什么后果,原因在于监管的不力,这就好像CUBIC遇到了Vegas一样!)。基于此,即便不使用BBR算法,最好也不要使用基于时延的Vegas等算法,但是也许,我们可以更好的改进CUBIC,我们也许已经知道了如何去更改CUBIC了。CUBIC的问题不是其算法本身导致的,而是TCP拥塞控制的框架导致的。见本文”CUBIC更改前奏-实现NCL(非拥塞丢包)“小节。
本节的最后,我们来看点关于第二类缓存的特性。
第二类缓存既然不是用来进行”BDP探测“(事实上,BDP的组成里根本就该有第二类缓存)的,那要它干什么??
我想这里可以简单解释一下了。第二类缓存的作用是为了适配统计复用的分组交换网络上路由器处理不过来这个问题而引入的。如果没有路由器交换机节点的存在,那么第二类缓存这里什么也没有:
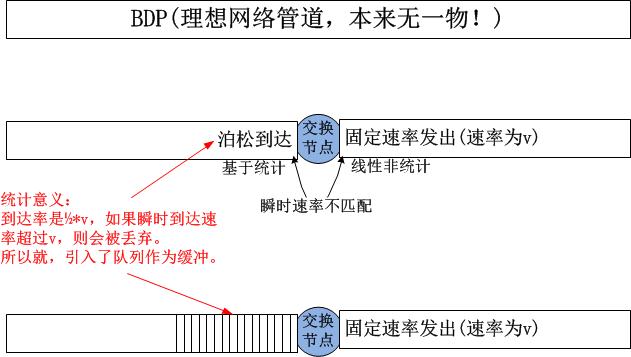
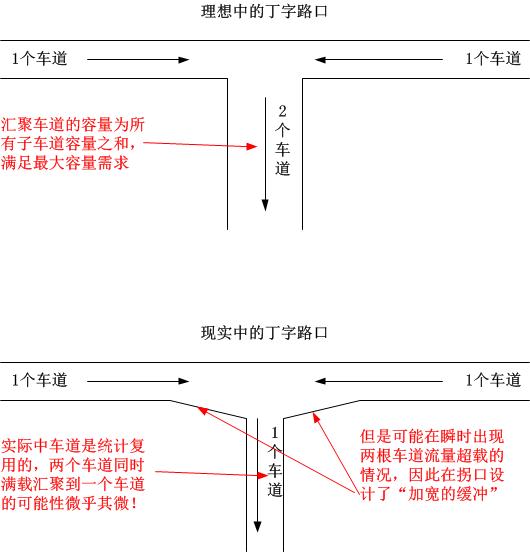
如果你想最快速度理解上图中泊松到达这个点的入口行为和固定速率发出的出口行为,请考虑丁字路由或十字路口,和路由器一样,只有在交叉点的位置才需要第二类缓存来平滑多方瞬时速率的不匹配特征!我以丁字路口为例:
不管哪里为应对瞬时到达率而加入的”缓存“,都是第二类缓存,这类缓存的目的是临时缓存瞬时到达过快的数据或者车流,这就是统计复用的分组交换网节点缓存的本质!然而一旦这些缓存被误用了,拥塞就一定会发生!误用行为很多,比如UDP毫无节制的发包,比如TCP依靠填满它而发现拥塞,讽刺的是,很大程度上,拥塞是TCP自己造成的,要想发现拥塞,就必须要先制造拥塞。
本节完!
2.突发特征与pacing
这里仅仅提一点,那就是突发最容易造成排队!这也是可以从泊松到达的排队论中推导出来的。为了不被人认为我在这里装逼,就不展示过程了,需要的请私下联系我。
解决突发问题的方法有两种,一种就是边缘网络路由器上设置整形规则,这有效避免了汇聚层以及核心层路由器的排队。另外一种更加有效的方法就是直接在端主机做Pacing。Linux在3.12内核以后已经支持了FQ这个sched模块,它基于TCP连接发现的Pacing Rate来发送数据,取代了之前一窗数据突发出去的弊端。
Pacing背后的思想就是尽量减少网络交换节点处队列的排队!通过上一节的最后,我们知道,交换节点出口的速率恒定,而入口可能会面临突发,虽然在统计意义上,出入口的处理能力匹配即可,然而即便大多数时候到达速率都小于出口速率,只要有一瞬间的突发就可能冲击队列到爆满!事实上队列缓存存在的理由就是为了应对这种情况!
传统意义上,TCP拥塞控制逻辑仅仅计算一个拥塞窗口,TCP发送按照这个拥塞窗口发送适当大小的数据,但这些数据几乎是一次性突发出去的,Linux 3.9之后的patch出现了TCP Pacing rate的概念,可以将一窗数据按照一定的速率平滑发送出去,然而TCP本身并没有实现实际的Pacing发送逻辑,Linux 3.12内核实现了FQ这个schedule,TCP可以依靠这个schedule来实现Pacing了。
为什么不在TCP层实现这个Pacing,原因在于TCP层并不能控制严格的发送时序,它是属于软件层的。Pacing必须在数据包被发送到链路之前进行才比较有效,因为这时的Pacing是真实的!切记,Pacing目前可以通过TC来配置,要想Pacing起作用,在其之后就不能再有别的队列,否则,FQ的Pacing Rate就可能会被后面的队列给冲掉!
...
我们继续谈BBR算法的收敛特性。
3.BBR算法的收敛性
BBR算法的收敛性与之前基于加性增乘性减的算法的收敛性完全不同,比之前的更加优美!欲知如何,我先展示加性增乘性减的收敛图:
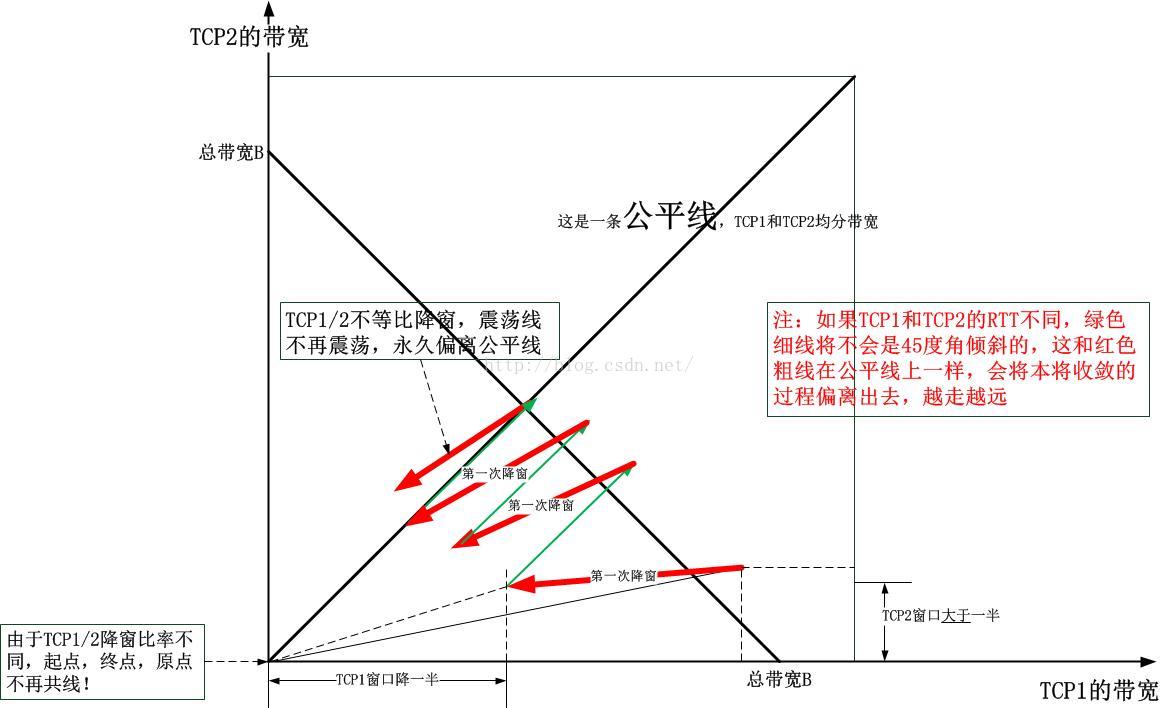
以下是根据上图总结出来的一幅抽象图:
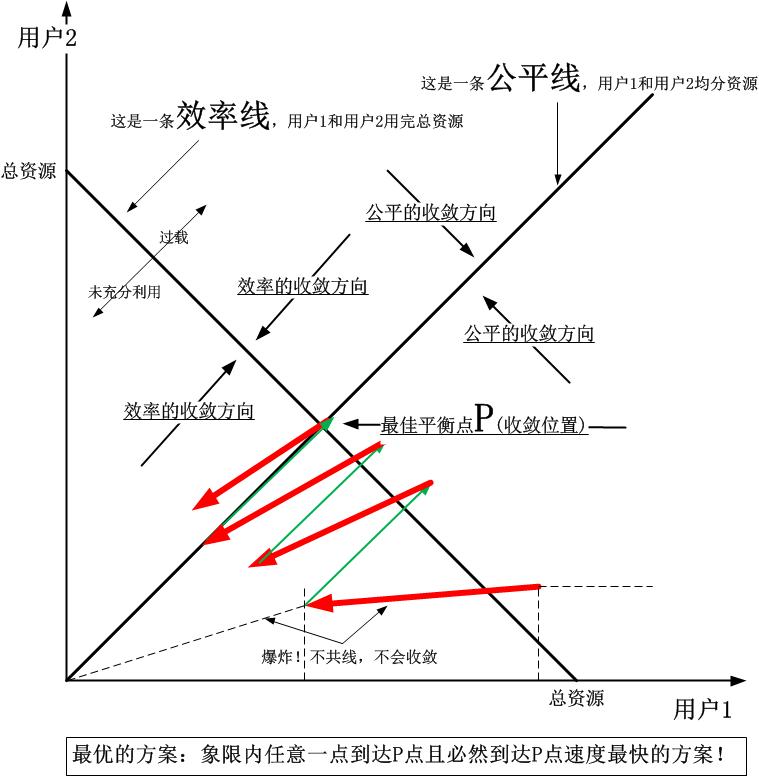
这个图之前贴过,这个图来自于控制论的理论,每个连接是独立地向最终的收敛点去收敛,大家彼此不交互,只要都奔着平衡收敛点走就行。
当我们认识BBR收敛性的时候,我们要换一种思路。即BBR收敛过程并不是独立的,它们是配合的,BBR算法根本就没有定义收敛点,只是大家互相配合,满足其带宽之和不超过第一类缓存的大小,即真正BDP的大小,在这个约束条件下,BBR最终自己找到了一个稳定的平衡点。
在展示图解之前,为了简单起见,我们先假设BBR在PROBE_BW状态,讨论在该状态的收敛过程。我们先看一下PROBE_BW状态的增益系数数组:
static const int bbr_pacing_gain[] = {
// 占据带宽,在带宽满之前,一直运行。效率优先,尽可能处在这里久一些...
BBR_UNIT * 5 / 4, /* probe for more available bw */
// 出让带宽,只要带宽不满了,则进入稳定状态平稳运行。兼顾公平,尽可能离开这里...
BBR_UNIT * 3 / 4, /* drain queue and/or yield bw to other flows */
// 一方面平稳运行,一方面等待出让的带宽不被自己重新抢占!
BBR_UNIT, BBR_UNIT, BBR_UNIT, /* cruise at 1.0*bw to utilize pipe, */
BBR_UNIT, BBR_UNIT, BBR_UNIT /* without creating excess queue... */
};
仔细看这个数组,就会发现,bbr_pacing_gain[0],bbr_pacing_gain[1]以及后面的元素安排非常巧妙!bbr_pacing_gain[0]表明,BBR有机会获取更多的带宽,而bbr_pacing_gain[1]则表明,在获取了足够的带宽后,在需要的情况下要出让部分带宽,然后在出让了部分带宽后,循环6个周期,等待其它连接获取出让的带宽。那么,BBR如何安排以上三类增益系数的使能周期长度呢?
很显然,BBR希望连接尽可能多的使用带宽,因此bbr_pacing_gain[0]的使能时间尽可能久些,其退出条件是:
已经运行超过了一个最小RTT时间并且要么发生了丢包,要么本次ACK到来前的inflight的值已经等于窗口值了。
虽然BBR希望一个连接尽可能占用带宽,但是BBR的原则是不能排队或者起码减少排队,当另一个连接发起时,额外的带宽占用会让处在正增益的连接inflight发生满载,因此bbr_pacing_gain[0]会让位给bbr_pacing_gain[1],进而出让带宽给新连接,随后进入长达6个RTT周期的平稳时期,等待出让的带宽被利用。总之,总结一点就是:
如果没有其它连接,一个连接会一直试图占满所有带宽,一旦有新连接,则老连接尽量一次性或者很短时间内出让部分带宽,然后在这些带宽被利用之前,老连接不再抢带宽,如果超过6个RTT周期之后,老连接重新开始新一轮抢占,出让,等待被利用的过程,从而和其它的连接一起收敛到平衡点。
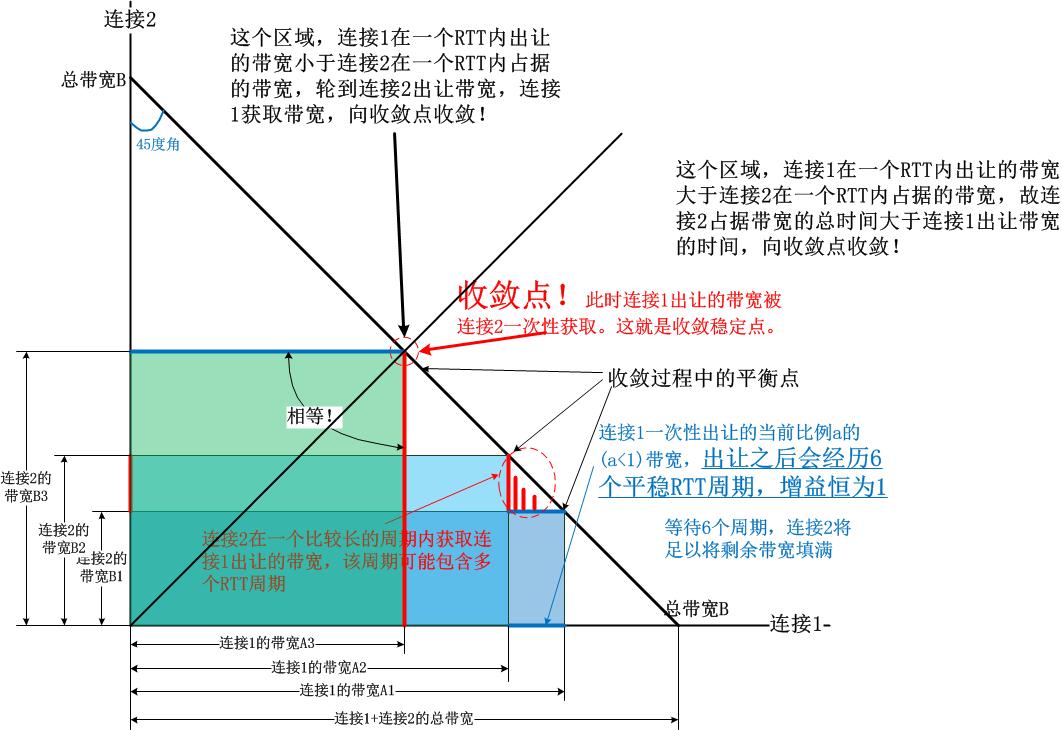
因此,和加性增乘性减的独立收敛方案不同,BBR一开始就是考虑到对方存在的收敛方案。我们看一个简单的例子,描述一下大致的收敛思想:
初始状态
连接1:10 & 连接2:0
1>.连接1在一个RTT出让1/4带宽,稳定6个RTT,带宽为7.5 & 连接2以4个RTT为一个PROBE周期分别的带宽为:1.25,1.55,1.95,2.4
2>.连接1在bbr_pacing_gain[0]占据带宽失败,继续出让带宽,稳定在5.6 &连接2以3个RTT为一个PROBE周期分别的带宽为3.0,3.75,4.6
3>.完成收敛。
最后,我们可以看一下BBR的收敛图了:
根据Google的测试,其收敛效果如下图:
通过上图以及bbr_pacing_gain数组,我们知道了是什么保证了收敛。假设连接1和连接2在网络中的RTT相同(这种假设是合理的,因为在BDP计算中,可以将RTT作为一种权值看待),那么根据PROBE_BW状态内部增益在bbr_pacing_gain数组中转换的规则:
- 1).BBR_UNIT * 5 / 4的增益要保持多个最小RTT(非滑动的时间内)的时间,直到填满带宽(但要避免排队!所以只要触及带宽即可,即上一次的inflight等于本次的窗口估值)
- 2).BBR_UNIT * 3 / 4的增益保持的时间要短,最多一个最短RTT时间就退出,在不到RTT时间内,如果排空了部分网络资源也退出。
- 3).BBR_UNIT的增益紧接在BBR_UNIT * 3 / 4之后,并且持续6个最小RTT的时间。
- 4).在1)和2)表示的获取和出让之间,保持等比例平衡,默认为当前带宽1/4的获取和出让。
我们来根据以上规则描述上图中的收敛:
- 1).在上图的右下边,连接1带宽大于连接2,以上的规则使得连接1一次出让的带宽大于连接2一次获取,因此连接2多个RTT周期内维持在BBR_UNIT * 5 / 4增益,平衡点向沿着带宽线向左上收敛。
- 2).在上图的左上方,连接2的带宽大于连接1,连接1即使再出让带宽,即便连接2获取了,那连接2回赠的带宽还是大于连接1的出让,使得连接1比较久维持在BBR_UNIT * 5 / 4增益,向右下收敛。
4.BBR的公平收敛性与调优
关于收敛和性能调优的话题,这里还要多说几句。
首先,虽然收敛是必然的,上文已经分析,但是收敛速度如何呢?BBR在Linux实现的目前是第一个版本,其带宽出让环节和带宽获取环节中,增益系数中有一个定值,即3/4和5/4,这两个值的算术平均值为1,这里的意义在于保持一个比例上的平衡。如果将出让系数3/4调大,比如调到1/2,那么获取带宽的增益系数就要调整为3/2,这会让收敛速度更快些。
我着手要做的就是参数化这个bbr_pacing_gain数组:
static const int bbr_pacing_gain[] = {
BBR_UNIT * a, // 1<a<2
BBR_UNIT * (2-a),
BBR_UNIT, BBR_UNIT, BBR_UNIT,
BBR_UNIT, BBR_UNIT, BBR_UNIT,
BBR_UNIT, BBR_UNIT, BBR_UNIT // 新增2个周期
};
这里列举几个典型的a值:6/5,5/4,4/3,3/2。所需要的就是将a参数化。
其次,由于以上的讨论都是基于PROBE_BW稳定状态这种理想化场景的,然而现实中你无法忽略STARTUP,DRAIN等状态,为了在测试中找到状态瓶颈,包括带宽利用最大化,收敛公平性,我们把BBR的状态机看作是一个马尔科夫链:
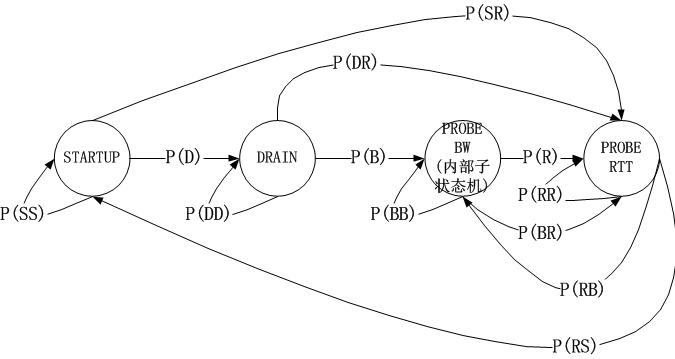
之所以可以建立这样的模型,是因为BBR全权接管了所有计算窗口和带宽的逻辑,因此这个转换图是闭合且不受外部干扰的。在得到各种转换概率后,我们基本就可以看出网络的行为了。
比如,调优的目标是尽可能让BBR系统运行在PROBE_BW状态,且在PROBE_BW内部,也有一个状态机,我们希望尽可能的稳定在系数为1的增益上运行。
获取了各种概率数据后,BBR的参数化调优方案就有了基调了。
在上一节,我们描述了BBR算法在稳定的PROBE_BW状态的收敛性。现在,我们来看一个异常的但是有普遍意义的场景,那就是发生拥塞的时候,BBR如何表现,如何收敛。由于BBR本身的宗旨就是消除队列,我们假设某个或者某些连接刚启动时,在STARTUP状态填充了队列的一部分,此时在其进入DRAIN状态之前,队列一直是存在的,由于队列已经开始被填充,那么已有的连接会在相当长的时间内无法采集到更小的RTT,最终,它们几乎会同时进入PROBE_RTT状态!看BBR的PROBE_RTT实现,就知道在这个状态中,cwnd会被瞬间缩减到4个MSS的大小!这会导致大量的网络资源被腾出,而这些腾出的资源会被新连接共享,这就是STARTUP和PROBE_RTT状态的公平性!
但是,如果和CUBIC共享资源怎么办?!
很遗憾,BBR无法识别CUBIC的存在!当BBR将cwnd缩减的时候,CUBIC会继续填充第二类缓存,直到透支掉最后的那一个字节。随后,也许你会认为CUBIC会执行乘性减来缩减cwnd,是的,确实如此,然而即使这样,也不能指望它们会腾出带宽,因为CUBIC的行为是各自独立的,你无法假设它们会同时进入乘性减窗,因此几乎可以肯定,共享链路上的缓存总是趋向与被填满的状态,这都是CUBIC的所为。然而怎能怪它呢,毕竟它的基础就是填满所有两类缓存为止,决不降速(不同于BBR的发现排队之前绝不减速的特性)。因此,BBR和CUBIC共存的时候,很有可能会出现全盘皆输的局面。
怎么缓解?!
事实上,BBR没必要对CUBIC过分谦让。只要满足自己不排队即可(因为排队于人于己均无好处!)。因此大可不必将窗口降到4个MSS,直接降到一半即可,这也是沿袭了传统乘性减的规则!此外,在PROBE_RTT阶段,也不要在这个状态运行过久,时间减半意思意思就好!为此,很容易更改代码:
0).定义一个新的fast_probe模块参数
1).bbr_set_cwnd的修改:
if (bbr->mode == BBR_PROBE_RTT) { /* drain queue, refresh min_rtt */
if (fast_probe)
tp->snd_cwnd = max(tp->snd_cwnd >> 1, bbr_cwnd_min_target); // 取cwnd/2!
else
tp->snd_cwnd = min(tp->snd_cwnd, bbr_cwnd_min_target);
}
2).bbr_update_min_rtt的修改:
...
if (!bbr->probe_rtt_done_stamp && tcp_packets_in_flight(tp) <= bbr_cwnd_min_target) {
bbr->probe_rtt_done_stamp = tcp_time_stamp +
msecs_to_jiffies(fast_probe?(bbr_probe_rtt_mode_ms>>1):bbr_probe_rtt_mode_ms);
...
}
这样会不再过分对CUBIC低头示弱。通过上一节描述的BROBE_BW状态的收敛过程,这种强势的行为并不影响多个同时运行BBR算法的TCP流之间公平性,它们之间的公平收敛,留到PROBE_BW状态慢慢玩吧。至于和CUBIC之间的竞争,你不仁,我便不义了!
最后,我们看一下STARTUP和DRAIN的增益系数,它们互为倒数,怎么填充就怎么清空,完美回退。
/* We use a high_gain value of 2/ln(2) because it's the smallest pacing gain
- that will allow a smoothly increasing pacing rate that will double each RTT
- and send the same number of packets per RTT that an un-paced, slow-starting
- Reno or CUBIC flow would:
/
static const int bbr_high_gain = BBR_UNIT 2885 / 1000 + 1;
/* The pacing gain of 1/high_gain in BBR_DRAIN is calculated to typically drain- the queue created in BBR_STARTUP in a single round:
/
static const int bbr_drain_gain = BBR_UNIT 1000 / 2885;
我们来尝试调整这参数,可以是不对称的缓慢Drain,这是基于在降速排空队列的过程中,可能已经有别的连接出让了带宽!
5.CUBIC更改前奏-实现NCL(非拥塞丢包 Non-congestion Loss)
CUBIC还算是迄今比较伟大的算法,它不会轻易被BBR取代,但是它需要被改进。
首先,在没有AQM时,加性增乘性减本身并没有错,一般的丢包都是尾部拥塞丢包,这对于TCP拥塞控制而言,基于丢包的拥塞探测太容易做了,但是尾部丢包会带来一系列的问题,为了解决这些问题,出现了AQM,比如RED之类的丢包算法,这样一来就无法区别RED丢包,尾部丢包,线路噪声丢包,乱序未丢包这几类现象了。问题的严重性是由拥塞算法对丢包的敏感性造成的,只要有丢包,或者说仅仅是按照自己的逻辑检测到了可能的丢包,就好像出了大事一般,窗口会大幅度下降!!然而,噪声丢包和乱序并不是拥塞,所以如果能过滤掉这两类,CUBIC的效率一定会有大的提高!
事实上,CUBIC算法没有任何问题,问题出在Linux的TCP实现(其它系统估计也好不到哪去,大家都是仿照BSD实现的)的问题,造成很多时候,CUBIC心有余而力不足,好不容易探测到一个合适的拥塞窗口,被dubious的ACK调用tcp_fastretrans_alert的PRR算法一下子拉下去了,或者直接被定时器超时事件给拉下去...BBR之所以优秀,并不是说其算法优秀,其独到之处在于一切都是它自己来决定的,没有谁能拉低BBR算出来的窗口和发送带宽,除了它自己!所以说,BBR的优秀更多的指的是其框架的优秀。
我不对CUBIC本身进行任何的改造,我只是解放它。首先要做的就是排除假拥塞丢包,要确保进入PRR逻辑的丢包都是由于导致第二类缓存被填满的拥塞避免引起的。至于说非拥塞丢包,继续进入CUBIC逻辑,让CUBIC获取更多的权力。
这里介绍的一种方法是NCL机制。详细文档请参见《TCP-NCL: A Unified Solution for TCP Packet Reordering and Random Loss》。其基本思想就是,将重传与拥塞控制Alert(即主动的拥塞控制逻辑调用,在Linux中表现为tcp_fastretrans_alert以及tcp_enter_loss)逻辑分离,在确认真的拥塞之前不进入拥塞控制Alert逻辑。NCL是怎么做到的呢?很简单:
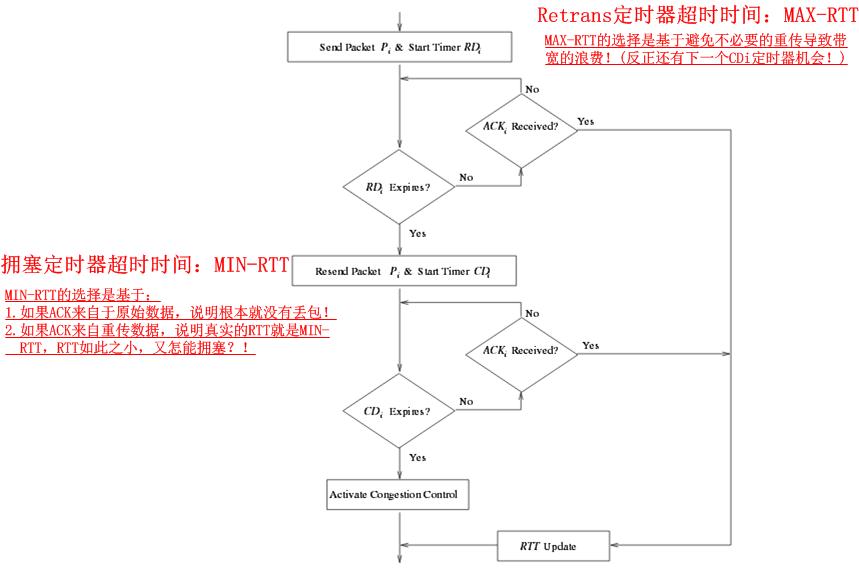
其各个例程的示意图如下:
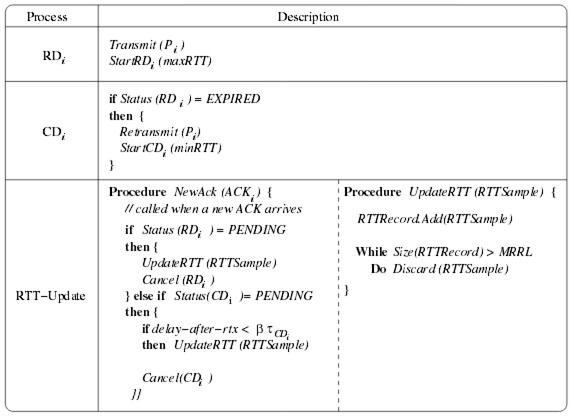
NCL的设计巧妙之处就是相当于为丢包的拥塞探测设置了一个时间窗口,在标准的Linux TCP拥塞控制实现中,只要程序逻辑判定发生了丢包,就会惊恐地呻吟着进入拥塞控制Alert阶段,退出Open状态,进入Recovery状态PRR降窗,或者进入LOSS状态窗口掉底。而NCL分离了丢包的性质判断和拥塞控制Alert的调用,在以往,重传定时器超时就意味着拥塞已经发生,然而NCL中却可以有一次过滤机会,即第一个RD定时器仅仅处理重传逻辑,重传后启动的CD定时器超时后才会判断为拥塞。其巧妙之处还在于RD,CD两个定时器的超时时间选择,其思想都在图示的注释里。
...
接下来,tcp_time_to_recover的修改就手到擒来了!
爆炸!
原文出处:BBR_v2.0真的要来了!
昨天google在BBR论坛上发布了,BBR算法小组的最新进展。链接如下
BBR Congestion Control Work at Google IETF 102 Updates:https://datatracker.ietf.org/meeting/102/materials/slides-102-iccrg-an-update-on-bbr-work-at-google-00
BBR Congestion Control:IETF 102 Update: BBR Startup:https://datatracker.ietf.org/meeting/102/materials/slides-102-iccrg-bbr-startup-behavior-01
修改的内容主要包括以下一个方面:
提高与基于丢包的拥塞算法(Reno/Cubic)的共存能力。降低BBR算法的抢占性,提高不同算法之间的公平性。
- 减小排队丢包和排队时延的情况。 这里主要根据丢包率和标记ECN比例来设置inflight的两个门限值,inflight_hi和inflight_lo。
- 加快min_rtt的收敛性,增加是将进入Probe_RTT模式的频率由10s设置到2.5s。
- 减小Probe_RTT模式带来的带宽的波动,进入到Probe_RTT不在是等待in_flight小于等于4。
BBR_v2.0对Start_up、Probe_bw以及Probe_RTT模式都做了相应的修改,改动最大的是PROBE_BW模式中的探测部分。下面分别对各个模式所做的修改进行介绍。
BBR_v1.0的Start_up模式的退出条件是进行连续三轮探测,最大带宽没有增加25%,探测出来的带宽值趋于平稳。而BBR_v2.0在BBR_v1.0的基础上增加了一个退出路径。当某一轮的丢包率超过1%并且丢包个数超过8个,或者某一轮中收到路由器标记ECN的比例超过50%,则可以退出Start_up模式,并且将inflight_hi更新为最大in_flight值。
Start_up模式的其他修改是将拥塞窗口增益由2.89改为2,并考虑到ack聚合情况下,会增加一些额外的窗口值。BBR作者也在BBR论坛中说过为什么pacing_gain是2.89,是为了确保pacing_rate能够每隔一轮RTT增加一倍,理论理想值计算出来的pacing_gain为2.77左右,而cwnd_gain的设置是为了能让cwnd能每隔一轮RTT增加一倍,只要每次收到ack确认几个包,拥塞窗口就能增加几个包,也就是设置的cwnd_gain计算出来的target_cwnd要超过当前的in_flight值,如果出现ack聚合现象,探测出来的带宽就会偏小,不能连续增加,target_cwnd就会限制cwnd的增加。因此将cwnd_gain设置为2时,需要考虑ack聚合情况增加额外窗口。
BBR_v1.0版本中,Probe_RTT是个BBR公平性的体现,但是min_rtt收敛的速度许需要20-30s的时间,并且每次进入到Probe_RTT模式,都会带来吞吐率大幅降低,因为这时将拥塞窗口降低到4,保证了链路的通畅不出现排队,才能探测出准确的min_rtt。因此,估计很多厂商都直接不进入到Probe_RTT或者将进入到Probe_RTT的频率调低。
v2.0版本则将进入到Probe_RTT模式进入的条件改为2.5s没探测到更小的min_rtt,并且Probe_RTT模式是从in_flight小于0.75BDP开始算起。通过这种“暴饮暴食”到“少食多餐”变化,避免了过大的带宽波动,以及更好的收敛性。
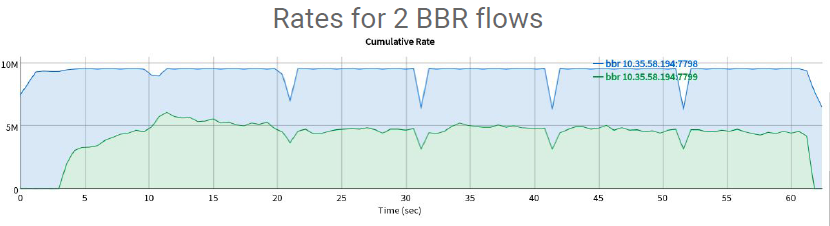
BBR_v1.0两条流的竞争情况
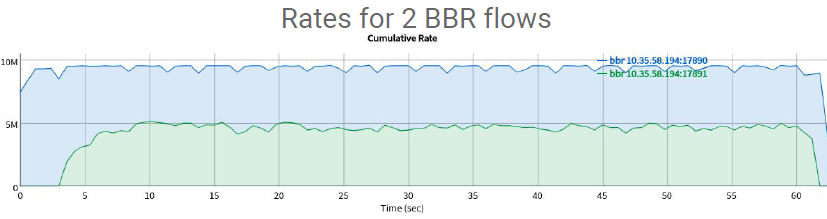
BBR_v2.0两条流的竞争的情况
从上面两图可以看到,BBR_v2.0可以让两条流更快的到达平均共享10M链路带宽,并且进入到Probe_RTT带来的网络整体的吞吐量降低的幅度更小。
Probe_Bw模式的改动较大,v1.0中是将Probe_Bw以min_rtt为基准分为8个周期,第一个周期为探测周期,pacing_gain设置为1.25,第二周期为清空周期,pacing_gain设置为0.75,之后六个周期为平稳周期,将pacing_gain设置为1.0,平稳发送。更大的带宽探测是通过第一周期加快了发送速率带来的探测。各个探测周期的退出条件分别为:
- 探测周期:in_flight > 1.25*BDP或者发生丢包 并且 需要时间超过min_rtt.
- 清空周期:in_flight <= BDP 或者 时间超过min_rtt.
- 平稳周期:时间超过min_rtt.
BBR_v2.0中也类似将Probe_Bw模式分为三个周期,UP周期、DOWN周期以及CRUISE周期,并且增加了两个门限值,inflight_hi以及inflight_lo,inflight_hi用于UP周期,inflight_lo用于CRUISE周期。
UP周期中类似BBR_v1.0探测周期,用于探测出一个更大的带宽,但探测的过程中分为平稳探测和指数增加探测两个部分,主要区分是in_flight 是否大于inflight_hi。平稳探测阶段为v1.0中方式,通过控制发送速率的增加来增加in_flight的值,当in_flight大于inflight_hi之后进入指数探测阶段,in_flight的值每轮增加1,2,4,8...直到退出UP周期。

UP周期退出条件为 in_flight超过1.25*BDP,某一轮丢包率超过1%并且丢包个数超过8或者某一轮标记ECN的数据包个数超过50% 。
DOWN周期与v1.0没有多大区别,只是退出条件变为了in_flight 小于BDP。
CRUISE周期类似v1.0的平稳周期,为了让出部分带宽,增加了inflight_lo,进入时初始化为min(BDP, 0.85*inflight_hi)最小值,inflight_hi为之前估算管道最多缓存的数据包个数,乘以一个0.85是让出一部分的管道缓存让其他流来探测。并且inflight_lo值也会根据丢包和标记某一轮标记ECN数据包比例来动态调整。退出条件为时间。

Probe_Bw周期的时长不在是8倍min_rtt,而是两个时间min(T_bbr, T_reno)的最小值,T_bbr是时间范围为2-5s,如何计算不得而知,T_reno是min(BDP, 50)*RTT的时长。Bw过期时间不在是过去的十轮,而是更长的2个Probe_Bw周期时长。
BBR_v2.0与BBR_v1.0相比,改动较大,但整体方向是往保守的方向进行改动,尤其是Probe_Bw阶段的改动,为了照顾Reno/Cubic这类算法增长较为慢的问题,整个探测周期较大的延长了,不在是每隔8*min_rtt时间进行一次探测,并且中国这种浮躁的环境下,改激进变得有侵略性,各个厂商肯定能马上推进,之前BBR_v1.0出来后,组里都各种加班加点,争取早日用上这种高大上的算法。而BBR_v2.0这种为CUBIC算法让出带宽,"我为人人"的拥塞算法,除了用于降低重传比,降低成本可能会使用,真的能替换BBR_v1.0算法吗?