声音与压缩编码
原文出处:认识声音
认识声音
前面我们分析完Opus的编解码api使用,封装原理等,接下来我们准备分析Opus编码原理.Opus编码是一个复杂的工作,我们需要做一些基本铺垫,包括认识声音,压缩编码基础. 认识音频有助于我们了解音频特征,不仅对语音有助于我们理解编码技术,同时在语音识别,TTS等场景提供帮助
音频信号及其心里特征
人类能够感知客观世界的两个重要途径就是听觉和视觉,而听觉所感受到的信息就是声音.声音是一种波,其本质是机械振动或气流扰动引起周围弹性媒介发生波动饿现象.声波可以在空气中传播,也可以在液体和固体中传播.
声压级
为了定量描述声音的强弱,人们采用了多种描述方式,其中声压和声压级就是其中的两种形式.声压用P来表示,它是指在声场中某处由声波引起的压强的变化值,单位是“帕斯卡”(Pa)。当然声压越大,声音也就越大。但是人耳对声音强弱的感觉与声压的大小并非成线性关系,而是大体上与声压有效值的对数成正比。为了适应人类听觉的这一特性,将声压的有效值取对数来表示声音的强弱,这种表示方式称为声压级,用SPL表示,单位是“分贝”(dB).它们的表达式如下:

在上式中,Prms是计量点的声压有效值,Pref是人为定义的零声压级的参考声压值,国际协议规定Pref=2乘以10的负5次Pa(帕),这个值是一般具有正常听力的年轻人对 1 kHz的单一频率信号(称为简谐音)刚刚能察觉到它的存在时的声压值。
在电声工程中通常用声级计来测量声压级的大小。 应该注意的是,无论是声压还是声压级都属于客观物理量,它们都是对客观事物的真实描述。
人对于声音频率的感觉表现为音调的高低,在音乐中简称音高。 音高与声音频率的关系也大体上呈对数关系。实际上音乐里的音阶就是按频率的对数取等分来确定的。 在音乐中每增高或降低一个八度音,其声音的频率就升高或降低一倍,十二平分律等程音阶正是在一个倍频程的频率范围内按频率的对数分成十二个等份划分音阶的,其中相邻的两个音阶称为一个半音,相隔的一个音称为一个全音。
人类的听觉特征决定了人对同样强度,但不同频率的声音主观感觉的强弱是不同的,即人类听觉的频率响应不是平直的。 对于高于20kHz和低于20Hz的声音,无论其强度多高,一般人都不会听到。因此可以认为20 Hz~20kHz是人类的听觉频带,而20Hz~20kHz的信号称为“音频信号”,高于20kHz的声音称为超音,低于20Hz的声音称为次音
此外在音频范围内,人对相同声压级而不同频率声音的敏感程度也不同,人耳对3kHz~5kHz的声音信号比高频和低频声音信号更敏感,也就是说,幅度(声压级)很低的中频信号都能被人耳听到,而低音或高音信号能被人耳听到的幅度要高得多。因此,为了更全面地表示人类的听觉频响特性,人们又定义了响度级这个主观物理量,单位用“方”(Phon)表示,响度级数是以1 kHz信号的声压级数定义的。对应同一响度级上的不同频率信号所对应的声压级也不同,但对人耳来说其声响的程度是相等的,因此将这些具有等响度的不同频率的点连接起来构成的一条条曲线被称为等响度曲线,如图所示。这些曲线是对大量具有正常听力的年青人进行大量测量并取其平均值得到的.
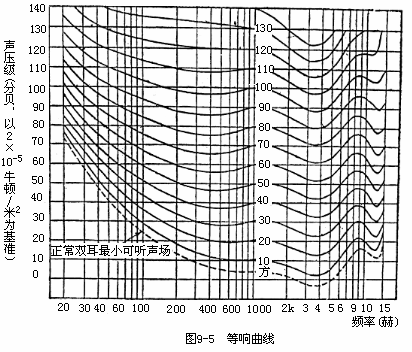
- 曲线0代表可听阈。低于此线之下不可闻。
- 响度级低时,各频率声压级相差很大。可差50dB以上。
- 当响度级别较高时,等响曲线近似水平(高保真放声在高声时,高低音都丰厚)。
- 在高频段曲线间隔相同,说明声压级变化时,响度级变化几乎相同。在低频段等响曲线间隔小,等响曲线对声压变化很灵敏。如80Hz,声压从60dB~80 dB,响度从30~70方。 响度级只反映不同频率的声音的等响感觉,不能表示一个声音比另一个声音响多少倍的主观感觉。响度级为0方的等响度曲线一下的声音一般为听不见的,因此该曲线可称为闻阈或绝对听阈,它是重要的心理学声学模型之一,也是音频信号压缩的重要依据.当声音响度超过120方时,人耳会感到痛痒,因此120方的等响度曲线可称为痛阈.
响度:是描述声音大小的主观感觉量,响度的单位是"宋"(sone)。
定义:1000Hz纯音,声压级为40dB时的响度为1宋;2宋的声音是40方声音响度的2倍;4宋为40方声音响度的4倍。多次人平均,响度级每增10方,响度增加一倍。也就是说,声压级增加10dB,响度增加一倍。如:10把小提琴同时演奏,比一把声强增加10倍,相应声压级增加10 dB,响度级也增加了10方,而主观响度只增加1倍。
人耳对响度的感觉随声压级变化。声压级低时,分辨率差;声压级高,分辨率提高。声压级在50dB以上,人耳的声压、响度变化最小,大约1dB。 小于40dB时,声压级要1~3dB以上才觉察出来。一个乐队演奏时,假如低、高音都以100 dB的声压级录音,此时等响线曲差不多平直,低高音听起来有差不多的响度。如果重放时声压级较低,假如50dB,这时50Hz的低音刚能听到,而1000Hz的声音却有50dB,高音也同时听上去很弱,结果原有的音色都改变了。这时要想让50Hz的声音听起来与1000Hz的声音有大致相同的响度,必须将其提升20dB左右。因此声音以低于原始声(录音时)的声压级重放,必须通过均衡器(Equalizer)来提升低音和高音以保持原有音色平衡。
掩蔽效应
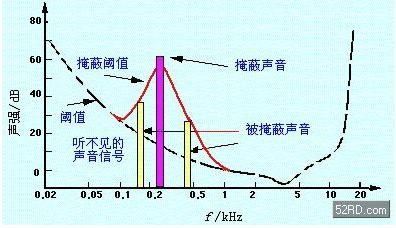
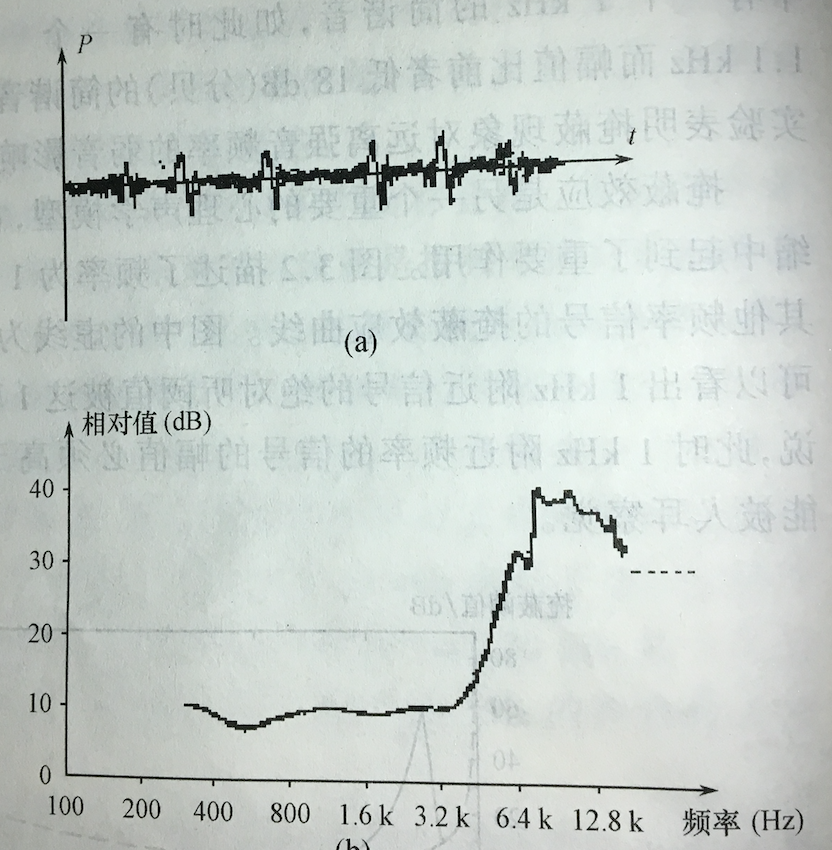
实验证明,声场中的一个强音能掩蔽与之同时发生的附近频率的弱音,这种现象称为掩蔽效应.也就是说,一种声音的出现可能是另一种声音难于听清.例如,在声场中有一个1kHz的简谐音,如果此时有一个1.1kHz而幅值比前者低18dB(分贝)的简谐音,则人们只能听到1kHz的声音.
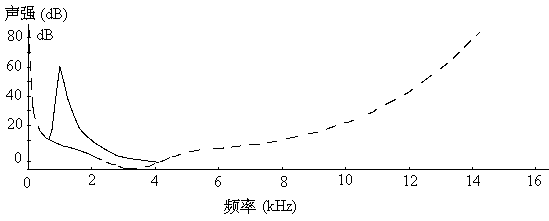
掩蔽效应是另一个重要的心理声学模型,它与绝对听阈相呼应,在音频数据压缩中起到了重要作用.下图描述了频率为1kHz,声压级为60dB的声音信号对其他频率信号的掩蔽效应曲线.图中的虚线为音频信号的绝对听阈曲线.从图中可以可出1kHz附近信号的绝对听阈被这1kHz的强音改变成了尖锋状,也就是说,此时1kHz附近频率的信号的幅值必须高于尖峰状曲线所对应的分贝值时才能被人耳察觉.
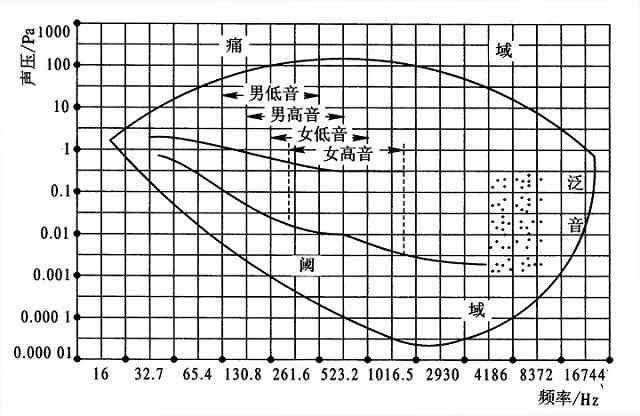
动态范围是衡量声音强度变化的重要参数,它是指某个声音的最强音与最弱音的强度差,并用分贝(dB)表示.在音乐中,动态范围小则给人以平淡,枯燥的感觉,而动态范围大则给人以生动,细腻,表现力强的感受.
为了记录,分析,处理声音信息,人们采用拾音器设备(麦克风)进行声-电转换,以实现将声音信号转换为电信号的目的.与此相反为了将音频电信号还原和重放,人们又采用了扩音设备(如放大器,扬声器等)进行电-声转换,以实现将电信号转换为声音信号的目的.
声音的周期性
声音可以分为周期信号与非周期信号两大类.根据傅里叶(Fourier)变换原理,周期信号可以用傅氏级数的形式表示,即该种信号可以分解成按傅氏级数规律排列的一系列单一频率信号(称为简谐波)的组合.它所对应的频谱为线状频谱,这种声音信号又称为有调音,如下图所示:
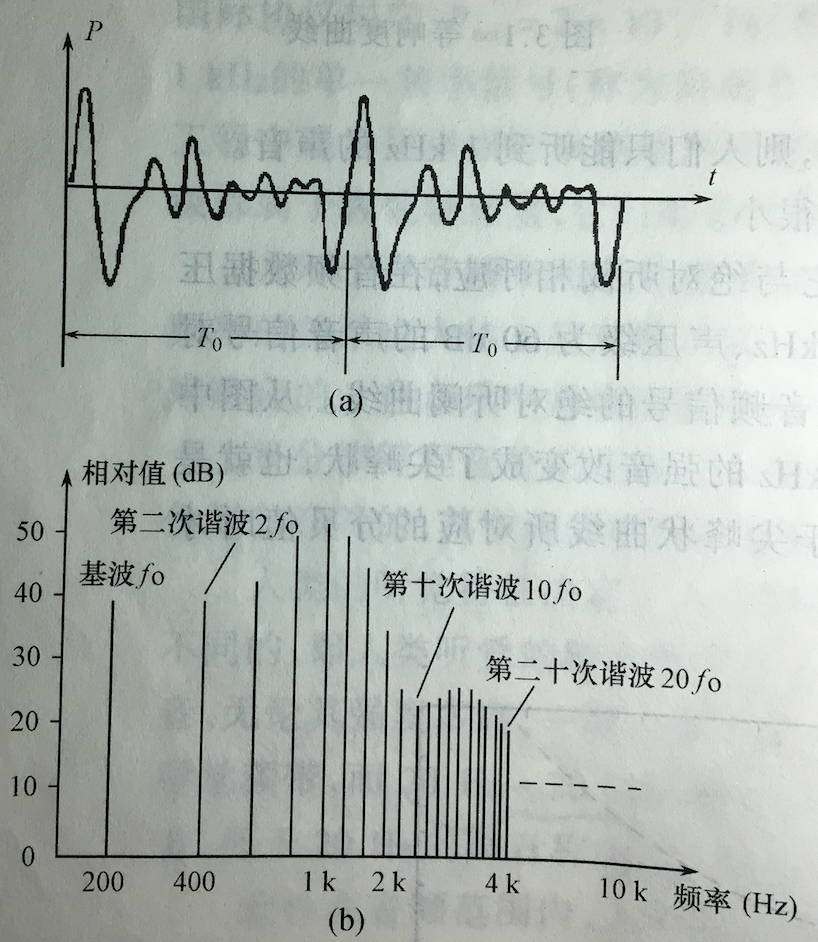
非周期信号可以用傅氏积分表示,该种信号包含一定频带的所有频率分量.因此它所对应的频谱为连续频率,如下图所示.因此可见,同一音频信号即可以在时间域中描述,也可以在频率与中表述,不同的域有不同的的特点,这有助于对信号的研究与处理.
原文出处:压缩编码
压缩编码
只有在保持信号质量的前提下,设法降低码率及数据量,才能使标准得到应用。而这种降低码率的过程,被称为压缩编码或新源编码. 这节介绍一些基础的压缩编码思想与方法,为后面Opus语音编码做基础准备. 压缩编码又可以分为无损压缩,有损压损,混合压缩 无损压缩编码有:
- 莫尔斯
- 哈夫曼
- 游程编码RLC
- 算术编码
- 香农-费诺编码
- Lempel-Zir编码
视频编码比语音编码描述更直观,本文以视频编码示例讲解主要的压缩编码原理.
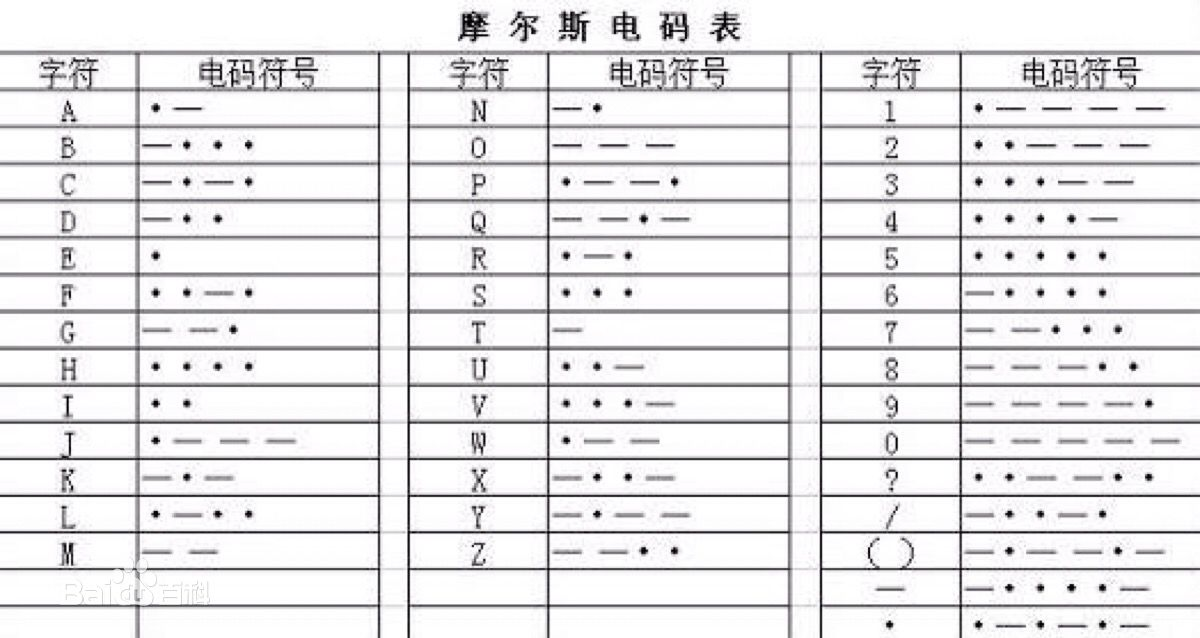
1.莫尔斯码
莫尔斯码就是大家熟悉的电报码,它的发明为人类做出了巨大的贡献.该码采用"."和"-"来表示26个英文字母,这实质上还是二进制码(点为"0",而杠为"1"),但是它没有采用固定字长的编码方式,而是采用了常用字母用短码表示(如E用"."表示,T用"-"表示),不常用字母用长码表示(如Z用"--.."表示,j用"-..-"表示)的变长编码方式.通过对英文单词进行大量统计,找出各字母的概率,最后确定有12个字母出现概率最低,用4bit数字表示,有8个字母出现概率较低,用3bit数字表示;有4个字母出现概率较高,用2bit数字表示;有两个字母出现概率最高,用1bit表示,共26个字母.
- 其中出现概率最低的12个字母共需12*4bit = 48bit
- 其中出现概率较低的8个字母共需8*3bit = 24bit
- 其中出现概率较高的4个字母共需4*2bit = 8bit
- 其中出现概率最高的两个字母共需2*1bit = 2bit
这样可以算出26个字母中每个字母的平均码长为: (48+24+8+2)/26 = 3.15位/字母
而要用固定码长方式则需要2的五次方=32,即5bit来表示.显然平均码长减低了近2/5,达到了压缩的目的,而这种压缩对于信息无任何损坏,属于无损压缩.
由此看来改变吗的规律是:先找出统计规律,然后对出现概率打的用短码,反之用长码,从而使码率降低. 其实我们后面的文字编码标准也采用了这种思想,像UTF-8中数字占1个字节、英文字母占1个字节,常用中文字符占用3个字节(大约2万多字),但超大字符集中的更大多数汉字要占4个字节(在unicode编码体系中,U+20000开始有5万多汉字)。
再附上一张莫尔斯编码表吧!
2.预测编码
2.1 差值编码
根据莫尔斯码编码规律的两个重要原则,先对视频图像信号的空间相关性(帧内相关性)进行统计分析. 原始图像数据在空间上存在着很大的冗余度,存在大量无频传送的多余信息,即空间相关性很强,可以把一帧图像看成是由像块,轮廓,细节3部分构成的.像块是指图像中成片相同像素组成的块,这种信号的频率小于2MHz,它的空间相关性最强.轮廓指的是像块间的分界,这种信号的频率大约在2MHz~3.5MHz左右,它的相关性较差.而细节则是图像中相关性最小,变化最频繁的细节描述,其信号频率大约在3.5MHz以上.通过大量的统计表明:像块要占用图像中绝大部分约90%以上,而轮廓和细节只占较少的部分,不到10%,换句话说,在视频信号中国低频部分占绝大多数,而高频部分则所占比例较小.
另一方面,视频信号不仅具有空间相关性,它还具有在时间轴上,以场帧和帧频为扫描周期的时空形结构,因此它还应觉有时间相关性,也就是帧间相关性.特别是对应那些静止的画面,其帧间相同位置的样值则100%相同.而那些非静止的画面中,相邻帧不同的部分也只是运动物体,只占较小的比例.
根据以上分析,可以设想,在对视频信号的数字化过程中,发送端处理货传输的不同图像中当前样值本身,而是该样值与前一个(相邻)样值的差值,则这些差值绝大部分是很小的或者为零,可以用短码来表示,而对那些出现概率较低的较大差值,用长码来表示,则可是总体码数下降.这种采用对相邻样值差值进行变长编码方式成为差值编码,又称为差分脉冲调制(DPCM).在接收端,将已得到的前一样值与刚收到的差值相加,就可还原出所要的当前样值.
从另一个角度看,可以把前一个样值看成是当前样值的的预测值,并与当前样值相减,得到一个差值(预测错误).该差值可以看成是当前要传送的样值对于预测值的修正值,并对该差值编码,传送,这样在接收端,可以将已得到的前一个样值加上这一解码后的修正值,就得到了一个正确的当前样值.因此差值编码也可以称为预测编码
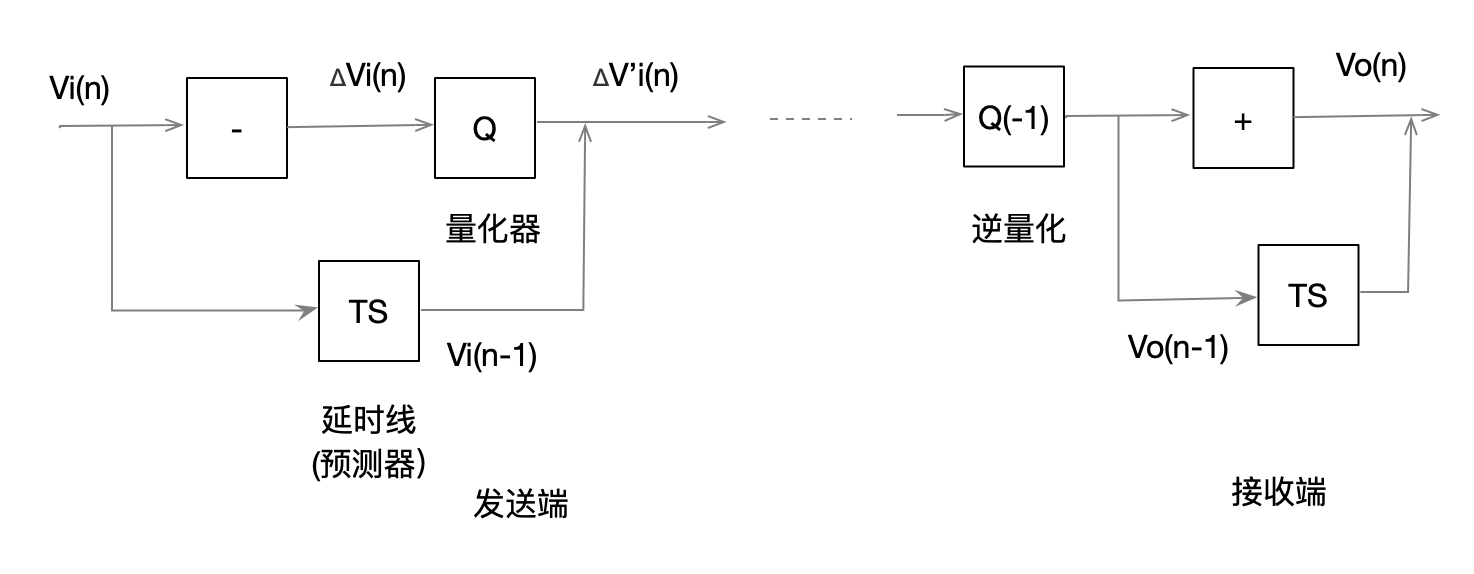
从图中可以看出,在信号的发送端,当前样值Vi(n)一路直接送入减法器,而另一路则送入延时线TS(预测器),其延迟时间定为一个采样周期,此时,从TS输出的出二样值的差值(预测误差),该预测误差应为: ΔVi(n)=Vi(n)-Vi(n-1)经过量化器Q量化后,ΔVi'(n)为ΔVi(n)+ε(n).其中ε(n)为量化误差或称量化噪声. 在信号接收端,差值信号(预测误差)ΔVi(n)+ε(n)经过逆量化器Q(-1)的D/A变换后,把该信号(包括ε(n))送入加法器,并经过延时线TS延迟一个采样周期的前一个输出样值(预测值)Vo(n-1)相加,从而又得到当前样值Vo(n). 从以上过程可以看出,发送端输出的是当前样值与前一样值的差值,而接收端将该项预测误差与前一输出样值相加,又还原为当前样值,因此差值编码是可以实现图像信号的压缩,传输与还原的.
2.2预测编码
预测编码是数字视频信号信源编码的主要方式之一.它也称为查分脉冲编码调制(DPCM).前面介绍的差值编码,只是预测编码中的一维预测,即只用同一行中当前样值的前一样值当做当前样值的预测值,这样的预测器可以对水平和表面给出非常好的效果,但对于垂直方向的效果并不理想.因此人们采用了二维或三维的预测方法.
3.霍夫曼(Huffman)编码
在前面的讲述中,是根据图像的相关性以及大量统计,找出了图像像素样值的预测规律.这为去除相关性,进行差值传输,提供了依据,打下了基础,然而这只是信源编码中的一个方面,另一个方面则是对差值信息(预测误差)进行熵编码(Entropy Coding),而不是普通意义上的数值编码.
熵编码是一类无损编码,它是因为编码后的平均码长接近信源的熵而得名.在熵编码中,一般多采用可变字长编码方式.其基本思想是对信源中出现概率大的对象用短码表示,而出现概率较小的对象用长码表示,从而统计上获得较短的平均码长.其中所指对象并没有规定是某种模拟或数字信息,它只是一个欲编码的对象或符号.熵编码要求所编的码应是即时可译码,短码不应与长码的码首重复,各码之间无需附加信息便可自然分开.
与莫尔斯码类似,霍夫曼码也属于熵编码.它是在数字视频中应用的一类可变长编码.其编码的具体方法是:
- 首先将欲编码的信源对象(在预测编码中应是量化后的预测误差),按出现的概率由大到小排成一列
- 找出最小的两个概率点,大的用码元"1"表示,小的用码元"0"表示(如概率相等,可自行确认"0"和"1"分配方式
- 再将这两个概率点的概率相加,生成一新的概率点,随后在新的概率点和余下的概率点中选出两个最小的概率点比较,大着为"1",小者为"0".
- 再将这两个概率点的概率相加,生成一个新的概率点,
- 以此类推,直至新的概率点的概率为1为止.
- 最后沿着由对象符号到概率为1的路劲,将该路径上的"1"和"0"记录下来,便得到了各信源对象的霍夫曼编码.
下图是7个信源"对象x1~x7的霍夫曼编码图:
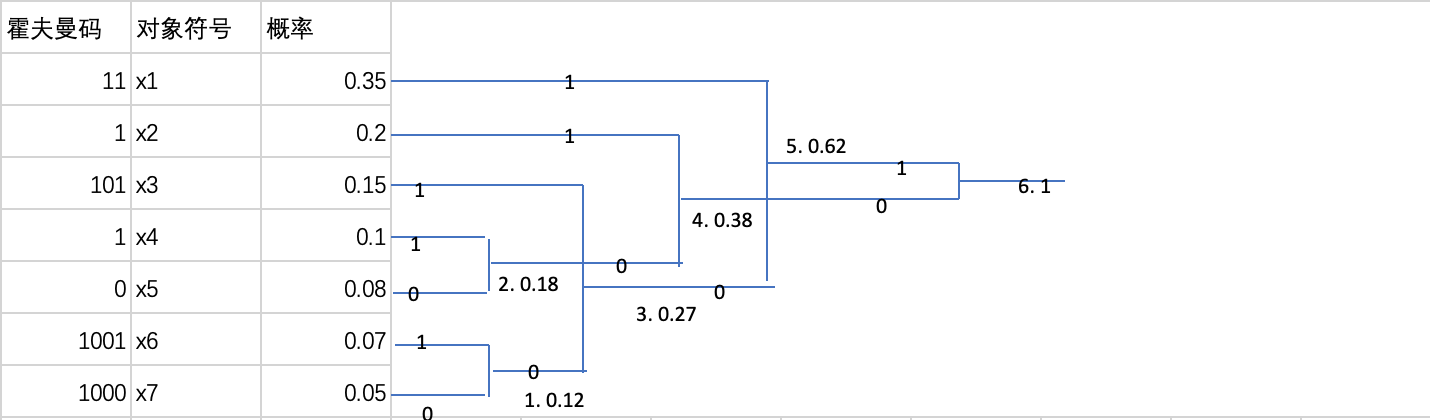
上图示出了霍夫曼编码过程,如果采用固定码长的编码方式,此例中7个对象需3位码长,而采用了霍夫曼编码后,其平均码长为:

上式中P(XN)wei XN的出现概率,L(XN)为XN的码长.可见比固定码长编码时的3bit要短,压缩了码位
在实际应用中,往往是将霍夫曼编码以查找表的形式,预先将对象与码值一一对应的存储在只读存储器(ROM)中.编码时,以对象为地址读出相应的霍夫曼编码;解码时,以霍夫曼为地址读出相应的对象,从而满足了即时编译的要求.
霍夫曼编码实际上是一种映射码,其与被编码对象的物理参数无关,是根据"对象"出现的概率而编制的.一旦编成,则霍夫曼码与对象是一一对应的,而与概率无关.
4.变换编码
在多媒体数字视频信源编码中,变换编码是实现图像数据压缩的主要手段之一.变换编码值的是正交变换编码,它将空间域的视频图像信号变换到由正交矢量定义的变换域中,以便去除其空间相关性,并对变换域中的系数采用适当的量化和编码方法,已达到数据压缩的目的.离散余弦变化(DCT),就是正交变换中的一种.他是把图像从空间域变换到频率域的一种变换形式.其目的在于找出图像在频域中的相关规律及特点,以便从频域的角度去除图像的相关性,达到图像压缩的目的.
4.1 离散余弦变换
在前面介绍了图像在空间域中的一种压缩算法,即预测编码.它是巧妙的利用了视频图像在空间域中具有较强的相关性这一特点设计的.然而人们发现,对于那些十分复杂的图像而言,空间相关性并不十分明显.因此预测编码就显得有些力不从心.经过进一步研究人们认识到,图像的相关性不仅表现在空间域中,它在其他域中,如频率域中也表现了很强的相关性.
DCT是英文Discrete Consine Transform的缩略语,意思是离散余弦变化,它是一种傅里叶变化,任何连续的实对称函数,采用傅里叶变换后,就只含余弦项.本片我们不讨论离散讨论傅里叶变化的数学证明等(具体可以参考:傅里叶分析之掐死教程(完整版)更新于2014.06.06,是描述离散余弦变换在压缩编码中步骤.
视频图像的DCT变换,是对每个单独的彩色图像分量进行的,先把整个分量图像分成许多8_8=64个样点组成的像块.并对其采样,然后再对这8_8=64个样值逐一进行FDCT(正向DCT)变换,将视频图像信号由空间域变换到频率域.如下图
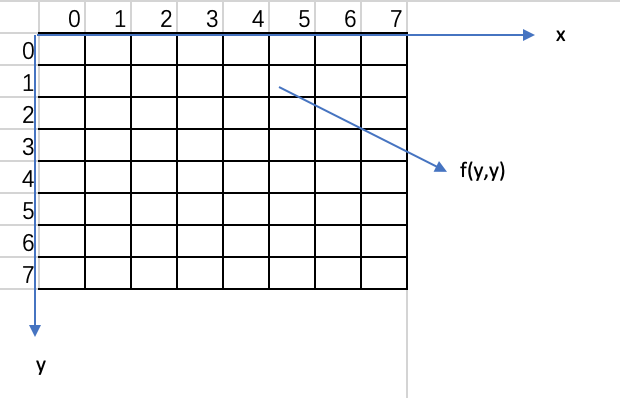
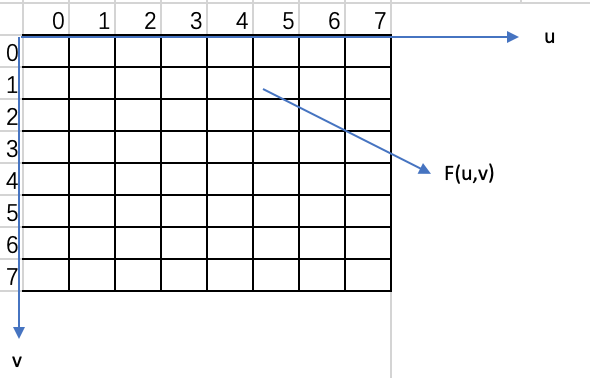
图中f(x,y)表示空间位置(x,y)点的样值函数(x,y=0,1,2....7),F(u,v)为频率域中对应于频率位置(u,v)点的DCT系数(u,v=0,1,2...7),沿u,v方向频率增加.在空间域中8_8的样值矩阵,经FDCT变换后,成为了频率域中8_8FDCT系数矩阵.图中F(u,v)的频域图中的右下角对应高频部分,而在左上角对应低频部分,其中F(0,0)对应直流分量,成为DC系数.其他63个对应交流分量的系数成为AC系数.
由于视频数字化采用8bit量化,即最大幅值对应256级(量化级).所以F(0,0)的变化范围为256的64/8倍,即可能取值为0~2047之间,而交流系数的变化范围应为-1024-1023.在F(u,v)系数矩阵中,低频系数的值大,而高频系数的值小,下表为一组实际的,变换前后的8*8样值矩阵和DCT系数矩阵.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 150 | 170 | 132 | 185 | 147 | 190 | 215 | 220 |
| 165 | 185 | 130 | 190 | 175 | 195 | 223 | 199 |
| 155 | 163 | 180 | 220 | 202 | 173 | 197 | 170 |
| 143 | 154 | 160 | 170 | 211 | 185 | 190 | 166 |
| 130 | 140 | 172 | 190 | 193 | 150 | 180 | 140 |
| 135 | 164 | 198 | 180 | 177 | 141 | 172 | 135 |
| 170 | 190 | 163 | 140 | 165 | 132 | 160 | 140 |
| 160 | 200 | 145 | 135 | 170 | 199 | 190 | 129 |
DCT变换是在信号发送端所做的一种图像信息压缩的前期操作,在接收端则可以通过逆变换(IDCT),将频率域中的DCT系数矩阵变换为空间域中的图像样值矩阵,使图像得以还原.
4.2 DTC系数量化
从上表可以看出矩阵f中各值的相关性较差,而经过DCT变换后的F矩阵中的各DCT系数间的相关性已经显现出来了,即左上角的系数值大,而右下角的系数值小,为数据压缩创造了必要条件.但是这种相关性还不是十分明显,要最终实现数据压缩,还需要进一步降低非"0"系数的幅值,以及增加"0"值系数的数目,从而进一步提高F矩阵的相关性.为此还要对变换后的DCT系数进行量化,也就是按照某种要求将F矩阵中的各系数值按不同的比例减少,显然量化是图片质量下降的最主要原因.
对DCT系数的量化是基于限失真(Finite Distortion)编码理论进行的.它允许DCT系数经量化后,对图像造成一定的失真,但这种失真应在人的视觉所能接收的容限之内.
根据FDCT系数矩阵的不同区域,分配不同的量化步长的量化方法,称为区域滤波法.
4.3 Zig-Zag扫描
量化后的DCT系数仍然是二维系数矩阵,要进行数据传输,还需要将其变为一维数据序列.Zig-Zag扫描采用的是Z字形扫描方式.这主要是因为,在量化后的DCT系数矩阵中,非0的数据主要集中于矩阵的左上角.从直流分量DC开始进行Z字形扫描,可以增加连续0系数的个数,也就是增加0的游程长度.这样对传输中的数据压缩十分有利.
4.4 游程编码(RLC)
量化后的DCT系数矩阵,经过Zig-Zag扫描后变变为了以为数组序列,然后这一数组序列的尾部都是连续的0数据,这些连续0数据的个数称为游程.为了避免在数据传输中,逐个第传送0数据,进一步实现数据压缩,需要对这一维数组进行游程编码. 游程编码的方法是将扫描得到的一维数组序列,转换为一个由二元数组(num,level)组成的数组序列,其中num表示连续0的长度,level表示这串连续0之后出现的一个非零值,后面所有剩余的连续0,用符号EOB来表示.
4.5 熵编码
在编码中不是根据被编码数据的数值大小进行编码,而是根据被编码数据在所有数据中出现的概率来编码.概率大的用短码,反之用长码,从而进一步提高熵值,降低传输信息的平均码长.霍夫曼编码就是一种在视频数据压缩中,被广泛采用的熵编码.
在变换编码中,经过游程编码后的字符对数组序列,并不直接作为用于传输的数据,还要对其进行霍夫曼编码,以进一步提高数据压缩率.在发送端,将根据每一字符对出现的概率进行霍夫曼编码,并形成一个码表(霍夫曼码表)存储在编码器的ROM中,数据传输时,将严格按照码表,把每一个字符变换为霍夫曼码.在数据接收端,则必须采用同样的霍夫曼码表解码.