Redis内部数据结构详解
Redis内部数据结构详解(1)——dict
2016-05-31
如果你使用过Redis,一定会像我一样对它的内部实现产生兴趣。《Redis内部数据结构详解》是我准备写的一个系列,也是我个人对于之前研究Redis的一个阶段 性总结,着重讲解Redis在内存中的数据结构实现(暂不涉及持久化的话题)。Redis本质上是一个数据结构服务器(data structures server),以高效的方式实现了多种现成的数据结构,研究它的数据结构和基于其上的算法,对于我们自己提升局部算法的编程水平有很重要的参考意义。
当我们在本文中提到Redis的“数据结构”,可能是在两个不同的层面来讨论它。
第一个层面,是从使用者的角度。比如:
- string
- list
- hash
- set
- sorted set
这一层面也是Redis暴露给外部的调用接口。
第二个层面,是从内部实现的角度,属于更底层的实现。比如:
- dict
- sds
- ziplist
- quicklist
- skiplist
第一个层面的“数据结构”,Redis的官方文档(http://redis.io/topics/data-types-intro)有详细的介绍。本文的重点 在于讨论第二个层面,Redis数据结构的内部实现,以及这两个层面的数据结构之间的关系:Redis如何通过组合第二个层面的各种基础数据结构来实现第一个层面的更 高层的数据结构。
在讨论任何一个系统的内部实现的时候,我们都要先明确它的设计原则,这样我们才能更深刻地理解它为什么会进行如此设计的真正意图。在本文接下来的讨论中,我们主要关注 以下几点:
- 存储效率(memory efficiency)。Redis是专用于存储数据的,它对于计算机资源的主要消耗就在于内存,因此节省内存是它非常非常重要的一个方面。这意味着Redis一定是非常精细地考虑了压缩数据、减少内存碎片等问题。
- 快速响应时间(fast response time)。与快速响应时间相对的,是高吞吐量(high throughput)。Redis是用于提供在线访问的,对于单个请求的响应时间要求很高,因此,快速响应时间是比高吞吐量更重要的目标。有时候,这两个目标是矛盾的。
- 单线程(single-threaded)。Redis的性能瓶颈不在于CPU资源,而在于内存访问和网络IO。而采用单线程的设计带来的好处是,极大简化了数据结构和算法的实现。相反,Redis通过异步IO和pipelining等机制来实现高速的并发访问。显然,单线程的设计,对于单个请求的快速响应时间也提出了更高的要求。
本文是《Redis内部数据结构详解》系列的第一篇,讲述Redis一个重要的基础数据结构:dict。
dict是一个用于维护key和value映射关系的数据结构,与很多语言中的Map或dictionary类似。Redis的一个database中所有key到v alue的映射,就是使用一个dict来维护的。不过,这只是它在Redis中的一个用途而已,它在Redis中被使用的地方还有很多。比如,一个Redis hash结构,当它的field较多时,便会采用dict来存储。再比如,Redis配合使用dict和skiplist来共同维护一个sorted set。这些细节我们后面再讨论,在本文中,我们集中精力讨论dict本身的实现。
dict本质上是为了解决算法中的查找问题(Searching),一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。我们平常使用的各种M ap或dictionary,大都是基于哈希表实现的。在不要求数据有序存储,且能保持较低的哈希值冲突概率的前提下,基于哈希表的查找性能能做到非常高效,接近O( 1),而且实现简单。
在Redis中,dict也是一个基于哈希表的算法。和传统的哈希算法类似,它采用某个哈希函数从key计算得到在哈希表中的位置,采用拉链法解决冲突,并在装载因子 (load factor)超过预定值时自动扩展内存,引发重哈希(rehashing)。Redis的dict实现最显著的一个特点,就在于它的重哈希。它采用了一 种称为增量式重哈希(incremental rehashing)的方法,在需要扩展内存时避免一次性对所有key进行重哈希,而是将重哈希操作分散到对于dict 的各个增删改查的操作中去。这种方法能做到每次只对一小部分key进行重哈希,而每次重哈希之间不影响dict的操作。dict之所以这样设计,是为了避免重哈希期间 单个请求的响应时间剧烈增加,这与前面提到的“快速响应时间”的设计原则是相符的。
下面进行详细介绍。
dict的数据结构定义
为了实现增量式重哈希(incremental rehashing),dict的数据结构里包含两个哈希表。在重哈希期间,数据从第一个哈希表向第二个哈希表迁移。
dict的C代码定义如下(出自Redis源码dict.h):
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
`
为了能更清楚地展示dict的数据结构定义,我们用一张结构图来表示它。如下。
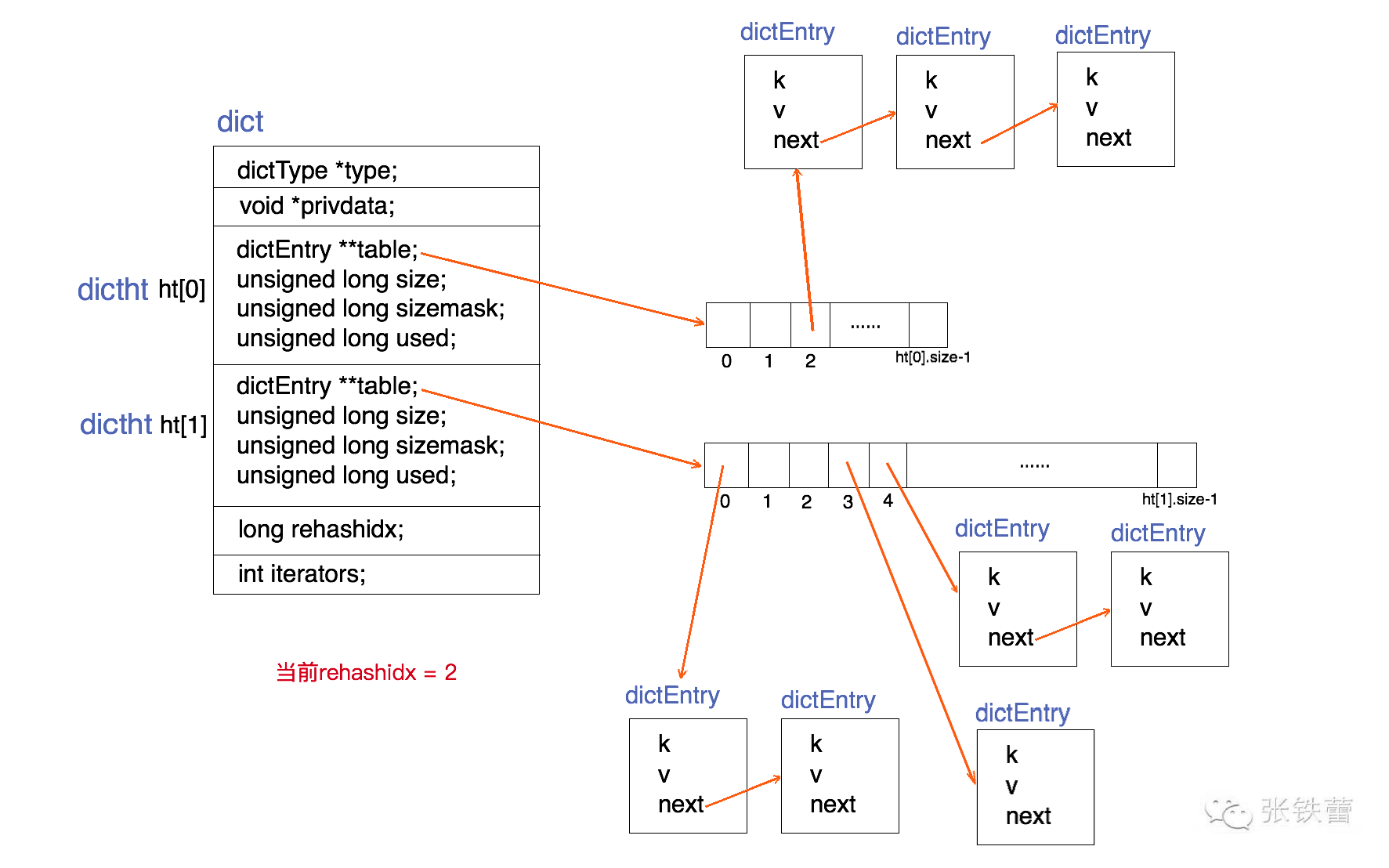
结合上面的代码和结构图,可以很清楚地看出dict的结构。一个dict由如下若干项组成:
- 一个指向dictType结构的指针(type)。它通过自定义的方式使得dict的key和value能够存储任何类型的数据。
- 一个私有数据指针(privdata)。由调用者在创建dict的时候传进来。
- 两个哈希表(ht[2])。只有在重哈希的过程中,ht[0]和ht[1]才都有效。而在平常情况下,只有ht[0]有效,ht[1]里面没有任何数据。上图表示的就是重哈希进行到中间某一步时的情况。
- 当前重哈希索引(rehashidx)。如果rehashidx = -1,表示当前没有在重哈希过程中;否则,表示当前正在进行重哈希,且它的值记录了当前重哈希进行到哪一步了。
- 当前正在进行遍历的iterator的个数。这不是我们现在讨论的重点,暂时忽略。
dictType结构包含若干函数指针,用于dict的调用者对涉及key和value的各种操作进行自定义。这些操作包含:
- hashFunction,对key进行哈希值计算的哈希算法。
- keyDup和valDup,分别定义key和value的拷贝函数,用于在需要的时候对key和value进行深拷贝,而不仅仅是传递对象指针。
- keyCompare,定义两个key的比较操作,在根据key进行查找时会用到。
- keyDestructor和valDestructor,分别定义对key和value的析构函数。
私有数据指针(privdata)就是在dictType的某些操作被调用时会传回给调用者。
需要详细察看的是dictht结构。它定义一个哈希表的结构,由如下若干项组成:
- 一个dictEntry指针数组(table)。key的哈希值最终映射到这个数组的某个位置上(对应一个bucket)。如果多个key映射到同一个位置,就发生了冲突,那么就拉出一个dictEntry链表。
- size:标识dictEntry指针数组的长度。它总是2的指数。
- sizemask:用于将哈希值映射到table的位置索引。它的值等于(size-1),比如7, 15, 31, 63,等等,也就是用二进制表示的各个bit全1的数字。每个key先经过hashFunction计算得到一个哈希值,然后计算(哈希值 & sizemask)得到在table上的位置。相当于计算取余(哈希值 % size)。
- used:记录dict中现有的数据个数。它与size的比值就是装载因子(load factor)。这个比值越大,哈希值冲突概率越高。
dictEntry结构中包含k, v和指向链表下一项的next指针。k是void指针,这意味着它可以指向任何类型。v是个union,当它的值是uint64_ t、int64_t或double类型时,就不再需要额外的存储,这有利于减少内存碎片。当然,v也可以是void指针,以便能存储任何类型的数据。
dict的创建(dictCreate)
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
`
dictCreate为dict的数据结构分配空间并为各个变量赋初值。其中两个哈希表ht[0]和ht[1]起始都没有分配空间,table指针都赋为NULL。这 意味着要等第一个数据插入时才会真正分配空间。
dict的查找(dictFind)
#define dictIsRehashing(d) ((d)->rehashidx != -1)
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
`
上述dictFind的源码,根据dict当前是否正在重哈希,依次做了这么几件事:
- 如果当前正在进行重哈希,那么将重哈希过程向前推进一步(即调用_dictRehashStep)。实际上,除了查找,插入和删除也都会触发这一动作。这就将重哈希过程分散到各个查找、插入和删除操作中去了,而不是集中在某一个操作中一次性做完。
- 计算key的哈希值(调用dictHashKey,里面的实现会调用前面提到的hashFunction)。
- 先在第一个哈希表ht[0]上进行查找。在table数组上定位到哈希值对应的位置(如前所述,通过哈希值与sizemask进行按位与),然后在对应的dictEntry链表上进行查找。查找的时候需要对key进行比较,这时候调用dictCompareKeys,它里面的实现会调用到前面提到的keyCompare。如果找到就返回该项。否则,进行下一步。
- 判断当前是否在重哈希,如果没有,那么在ht[0]上的查找结果就是最终结果(没找到,返回NULL)。否则,在ht[1]上进行查找(过程与上一步相同)。
下面我们有必要看一下增量式重哈希的_dictRehashStep的实现。
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
`
dictRehash每次将重哈希至少向前推进n步(除非不到n步整个重哈希就结束了),每一步都将ht[0]上某一个bucket(即一个dictEntry链表) 上的每一个dictEntry移动到ht[1]上,它在ht[1]上的新位置根据ht[1]的sizemask进行重新计算。rehashidx记录了当前尚未迁移( 有待迁移)的ht[0]的bucket位置。
如果dictRehash被调用的时候,rehashidx指向的bucket里一个dictEntry也没有,那么它就没有可迁移的数据。这时它尝试在ht[0]. table数组中不断向后遍历,直到找到下一个存有数据的bucket位置。如果一直找不到,则最多走n*10步,本次重哈希暂告结束。
最后,如果ht[0]上的数据都迁移到ht[1]上了(即d->ht[0].used == 0),那么整个重哈希结束,ht[0]变成ht[1]的内容,而ht[1]重置为空。
根据以上对于重哈希过程的分析,我们容易看出,本文前面的dict结构图中所展示的正是rehashidx=2时的情况,前面两个bucket(ht[0].tabl e[0]和ht[0].table[1])都已经迁移到ht[1]上去了。
dict的插入(dictAdd和dictReplace)
dictAdd插入新的一对key和value,如果key已经存在,则插入失败。
dictReplace也是插入一对key和value,不过在key存在的时候,它会更新value。
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* Compute the key hash value */
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return idx;
}
`
以上是dictAdd的关键实现代码。我们主要需要注意以下几点:
- 它也会触发推进一步重哈希(_dictRehashStep)。
- 如果正在重哈希中,它会把数据插入到ht[1];否则插入到ht[0]。
- 在对应的bucket中插入数据的时候,总是插入到dictEntry的头部。因为新数据接下来被访问的概率可能比较高,这样再次查找它时就比较次数较少。
- _dictKeyIndex在dict中寻找插入位置。如果不在重哈希过程中,它只查找ht[0];否则查找ht[0]和ht[1]。
- _dictKeyIndex可能触发dict内存扩展(_dictExpandIfNeeded,它将哈希表长度扩展为原来两倍,具体请参考dict.c中源码)。
dictReplace在dictAdd基础上实现,如下:
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will suceed. */
if (dictAdd(d, key, val) == DICT_OK)
return 1;
/* It already exists, get the entry */
entry = dictFind(d, key);
/* Set the new value and free the old one. Note that it is important
* to do that in this order, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
auxentry = *entry;
dictSetVal(d, entry, val);
dictFreeVal(d, &auxentry);
return 0;
}
`
在key已经存在的情况下,dictReplace会同时调用dictAdd和dictFind,这其实相当于两次查找过程。这里Redis的代码不够优化。
dict的删除(dictDelete)
dictDelete的源码这里忽略,具体请参考dict.c。需要稍加注意的是:
- dictDelete也会触发推进一步重哈希(_dictRehashStep)
- 如果当前不在重哈希过程中,它只在ht[0]中查找要删除的key;否则ht[0]和ht[1]它都要查找。
- 删除成功后会调用key和value的析构函数(keyDestructor和valDestructor)。
dict的实现相对来说比较简单,本文就介绍到这。在下一篇中我们将会介绍Redis中动态字符串的实现——sds,敬请期待。
Redis内部数据结构详解(2)——sds
2016-06-05
本文是《Redis内部数据结构详解》系列的第二篇,讲述Redis中使用最多的一个基础数据结构:sds。
不管在哪门编程语言当中,字符串都几乎是使用最多的数据结构。sds正是在Redis中被广泛使用的字符串结构,它的全称是Simple Dynamic String。与其它语言环境中出现的字符串相比,它具有如下显著的特点:
- 可动态扩展内存。sds表示的字符串其内容可以修改,也可以追加。在很多语言中字符串会分为mutable和immutable两种,显然sds属于mutable类型的。
- 二进制安全(Binary Safe)。sds能存储任意二进制数据,而不仅仅是可打印字符。
- 与传统的C语言字符串类型兼容。这个的含义接下来马上会讨论。
看到这里,很多对Redis有所了解的同学可能已经产生了一个疑问:Redis已经对外暴露了一个字符串结构,叫做string,那这里所说的sds到底和strin g是什么关系呢?可能有人会猜:string是基于sds实现的。这个猜想已经非常接近事实,但在描述上还不太准确。有关string和sds之间关系的详细分析,我 们放在后面再讲。现在为了方便讨论,让我们先暂时简单地认为,string的底层实现就是sds。
在讨论sds的具体实现之前,我们先站在Redis使用者的角度,来观察一下string所支持的一些主要操作。下面是一个操作示例:

以上这些操作都比较简单,我们简单解释一下:
- 初始的字符串的值设为”tielei”。
- 第3步通过append命令对字符串进行了追加,变成了”tielei zhang”。
- 然后通过setbit命令将第53个bit设置成了1。bit的偏移量从左边开始算,从0开始。其中第48~55bit是中间的空格那个字符,它的ASCII码是0x20。将第53个bit设置成1之后,它的ASCII码变成了0x24,打印出来就是’$’。因此,现在字符串的值变成了”tielei$zhang”。
- 最后通过getrange取从倒数第5个字节到倒数第1个字节的内容,得到”zhang”。
这些命令的实现,有一部分是和sds的实现有关的。下面我们开始详细讨论。
sds的数据结构定义
我们知道,在C语言中,字符串是以’\0’字符结尾(NULL结束符)的字符数组来存储的,通常表达为字符指针的形式(char *)。它不允许字节0出现在字符串中间,因此,它不能用来存储任意的二进制数据。
我们可以在sds.h中找到sds的类型定义:
typedef char *sds;
肯定有人感到困惑了,竟然sds就等同于char ?我们前面提到过,sds和传统的C语言字符串保持类型兼容,因此它们的类型定义是一样的,都是char。在有些情况下,需要传入一个C语言字符串的地方,也确实可以传入一个sds。但是,sds和char *并不等同。sds是Binary Safe的,它可以存储 任意二进制数据,不能像C语言字符串那样以字符’\0’来标识字符串的结束,因此它必然有个长度字段。但这个长度字段在哪里呢?实际上sds还包含一个header结 构:
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
sds一共有5种类型的header。之所以有5种,是为了能让不同长度的字符串可以使用不同大小的header。这样,短字符串就能使用较小的header,从而节 省内存。
一个sds字符串的完整结构,由在内存地址上前后相邻的两部分组成:
- 一个header。通常包含字符串的长度(len)、最大容量(alloc)和flags。sdshdr5有所不同。
- 一个字符数组。这个字符数组的长度等于最大容量+1。真正有效的字符串数据,其长度通常小于最大容量。在真正的字符串数据之后,是空余未用的字节(一般以字节0填充),允许在不重新分配内存的前提下让字符串数据向后做有限的扩展。在真正的字符串数据之后,还有一个NULL结束符,即ASCII码为0的’\0’字符。这是为了和传统C字符串兼容。之所以字符数组的长度比最大容量多1个字节,就是为了在字符串长度达到最大容量时仍然有1个字节存放NULL结束符。
除了sdshdr5之外,其它4个header的结构都包含3个字段:
- len: 表示字符串的真正长度(不包含NULL结束符在内)。
- alloc: 表示字符串的最大容量(不包含最后多余的那个字节)。
- flags: 总是占用一个字节。其中的最低3个bit用来表示header的类型。header的类型共有5种,在sds.h中有常量定义。
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
sds的数据结构,我们有必要非常仔细地去解析它。
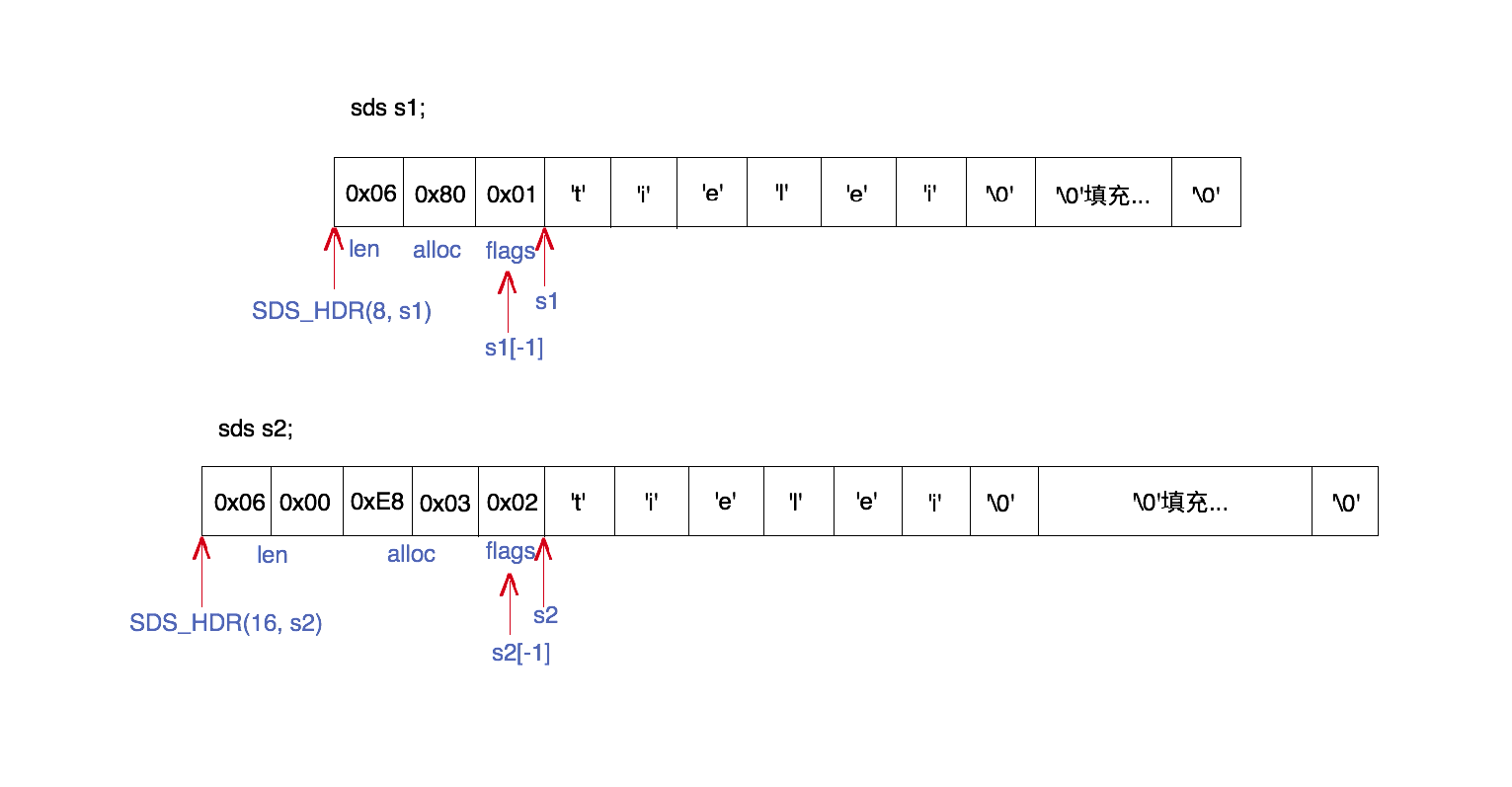
上图是sds的一个内部结构的例子。图中展示了两个sds字符串s1和s2的内存结构,一个使用sdshdr8类型的header,另一个使用sdshdr16类型的 header。但它们都表达了同样的一个长度为6的字符串的值:”tielei”。下面我们结合代码,来解释每一部分的组成。
sds的字符指针(s1和s2)就是指向真正的数据(字符数组)开始的位置,而header位于内存地址较低的方向。在sds.h中有一些跟解析header有关的宏 定义:
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
其中SDS_HDR用来从sds字符串获得header起始位置的指针,比如SDS_HDR(8, s1)表示s1的header指针,SDS_HDR(16, s2)表示s2的header指针。
当然,使用SDS_HDR之前我们必须先知道到底是哪一种header,这样我们才知道SDS_HDR第1个参数应该传什么。由sds字符指针获得header类型的 方法是,先向低地址方向偏移1个字节的位置,得到flags字段。比如,s1[-1]和s2[-1]分别获得了s1和s2的flags的值。然后取flags的最低3 个bit得到header的类型。
- 由于s1[-1] == 0x01 == SDS_TYPE_8,因此s1的header类型是sdshdr8。
- 由于s2[-1] == 0x02 == SDS_TYPE_16,因此s2的header类型是sdshdr16。
有了header指针,就能很快定位到它的len和alloc字段:
- s1的header中,len的值为0x06,表示字符串数据长度为6;alloc的值为0x80,表示字符数组最大容量为128。
- s2的header中,len的值为0x0006,表示字符串数据长度为6;alloc的值为0x03E8,表示字符数组最大容量为1000。(注意:图中是按小端地址构成)
在各个header的类型定义中,还有几个需要我们注意的地方:
- 在各个header的定义中使用了attribute ((packed)),是为了让编译器以紧凑模式来分配内存。如果没有这个属性,编译器可能会为struct的字段做优化对齐,在其中填充空字节。那样的话,就不能保证header和sds的数据部分紧紧前后相邻,也不能按照固定向低地址方向偏移1个字节的方式来获取flags字段了。
- 在各个header的定义中最后有一个char buf[]。我们注意到这是一个没有指明长度的字符数组,这是C语言中定义字符数组的一种特殊写法,称为柔性数组(flexible array member),只能定义在一个结构体的最后一个字段上。它在这里只是起到一个标记的作用,表示在flags字段后面就是一个字符数组,或者说,它指明了紧跟在flags字段后面的这个字符数组在结构体中的偏移位置。而程序在为header分配的内存的时候,它并不占用内存空间。如果计算sizeof(struct sdshdr16)的值,那么结果是5个字节,其中没有buf字段。
- sdshdr5与其它几个header结构不同,它不包含alloc字段,而长度使用flags的高5位来存储。因此,它不能为字符串分配空余空间。如果字符串需要动态增长,那么它就必然要重新分配内存才行。所以说,这种类型的sds字符串更适合存储静态的短字符串(长度小于32)。
至此,我们非常清楚地看到了:sds字符串的header,其实隐藏在真正的字符串数据的前面(低地址方向)。这样的一个定义,有如下几个好处:
- header和数据相邻,而不用分成两块内存空间来单独分配。这有利于减少内存碎片,提高存储效率(memory efficiency)。
- 虽然header有多个类型,但sds可以用统一的char *来表达。且它与传统的C语言字符串保持类型兼容。如果一个sds里面存储的是可打印字符串,那么我们可以直接把它传给C函数,比如使用strcmp比较字符串大小,或者使用printf进行打印。
弄清了sds的数据结构,它的具体操作函数就比较好理解了。
sds的一些基础函数
- sdslen(const sds s): 获取sds字符串长度。
- sdssetlen(sds s, size_t newlen): 设置sds字符串长度。
- sdsinclen(sds s, size_t inc): 增加sds字符串长度。
- sdsalloc(const sds s): 获取sds字符串容量。
- sdssetalloc(sds s, size_t newlen): 设置sds字符串容量。
- sdsavail(const sds s): 获取sds字符串空余空间(即alloc - len)。
- sdsHdrSize(char type): 根据header类型得到header大小。
- sdsReqType(size_t string_size): 根据字符串数据长度计算所需要的header类型。
这里我们挑选sdslen和sdsReqType的代码,察看一下。
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5)
return SDS_TYPE_5;
if (string_size < 1<<8)
return SDS_TYPE_8;
if (string_size < 1<<16)
return SDS_TYPE_16;
if (string_size < 1ll<<32)
return SDS_TYPE_32;
return SDS_TYPE_64;
}
跟前面的分析类似,sdslen先用s[-1]向低地址方向偏移1个字节,得到flags;然后与SDS_TYPE_MASK进行按位与,得到header类型;然后 根据不同的header类型,调用SDS_HDR得到header起始指针,进而获得len字段。
通过sdsReqType的代码,很容易看到:
- 长度在0和2^5-1之间,选用SDS_TYPE_5类型的header。
- 长度在2^5和2^8-1之间,选用SDS_TYPE_8类型的header。
- 长度在2^8和2^16-1之间,选用SDS_TYPE_16类型的header。
- 长度在2^16和2^32-1之间,选用SDS_TYPE_32类型的header。
- 长度大于2^32的,选用SDS_TYPE_64类型的header。能表示的最大长度为2^64-1。
注:sdsReqType的实现代码,直到3.2.0,它在长度边界值上都一直存在问题,直到最近3.2 branch上的commit 6032340 才修复。
sds的创建和销毁
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1);
if (!init)
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}
sds sdsempty(void) {
return sdsnewlen("",0);
}
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}
sdsnewlen创建一个长度为initlen的sds字符串,并使用init指向的字符数组(任意二进制数据)来初始化数据。如果init为NULL,那么使用全 0来初始化数据。它的实现中,我们需要注意的是:
- 如果要创建一个长度为0的空字符串,那么不使用SDS_TYPE_5类型的header,而是转而使用SDS_TYPE_8类型的header。这是因为创建的空字符串一般接下来的操作很可能是追加数据,但SDS_TYPE_5类型的sds字符串不适合追加数据(会引发内存重新分配)。
- 需要的内存空间一次性进行分配,其中包含三部分:header、数据、最后的多余字节(hdrlen+initlen+1)。
- 初始化的sds字符串数据最后会追加一个NULL结束符(s[initlen] = ‘\0’)。
关于sdsfree,需要注意的是:内存要整体释放,所以要先计算出header起始指针,把它传给sfree函数。这个指针也正是在sdsnewlen中调用s malloc返回的那个地址。
sds的连接(追加)操作
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
sds sdscatsds(sds s, const sds t) {
return sdscatlen(s, t, sdslen(t));
}
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
sdscatlen将t指向的长度为len的任意二进制数据追加到sds字符串s的后面。本文开头演示的string的append命令,内部就是调用sdscatl en来实现的。
在sdscatlen的实现中,先调用sdsMakeRoomFor来保证字符串s有足够的空间来追加长度为len的数据。sdsMakeRoomFor可能会分配新 的内存,也可能不会。
sdsMakeRoomFor是sds实现中很重要的一个函数。关于它的实现代码,我们需要注意的是:
- 如果原来字符串中的空余空间够用(avail >= addlen),那么它什么也不做,直接返回。
- 如果需要分配空间,它会比实际请求的要多分配一些,以防备接下来继续追加。它在字符串已经比较长的情况下要至少多分配SDS_MAX_PREALLOC个字节,这个常量在sds.h中定义为(1024*1024)=1MB。
- 按分配后的空间大小,可能需要更换header类型(原来header的alloc字段太短,表达不了增加后的容量)。
- 如果需要更换header,那么整个字符串空间(包括header)都需要重新分配(s_malloc),并拷贝原来的数据到新的位置。
- 如果不需要更换header(原来的header够用),那么调用一个比较特殊的s_realloc,试图在原来的地址上重新分配空间。s_realloc的具体实现得看Redis编译的时候选用了哪个allocator(在Linux上默认使用jemalloc)。但不管是哪个realloc的实现,它所表达的含义基本是相同的:它尽量在原来分配好的地址位置重新分配,如果原来的地址位置有足够的空余空间完成重新分配,那么它返回的新地址与传入的旧地址相同;否则,它分配新的地址块,并进行数据搬迁。参见http://man.cx/realloc。
从sdscatlen的函数接口,我们可以看到一种使用模式:调用它的时候,传入一个旧的sds变量,然后它返回一个新的sds变量。由于它的内部实现可能会造成地址 变化,因此调用者在调用完之后,原来旧的变量就失效了,而都应该用新返回的变量来替换。不仅仅是sdscatlen函数,sds中的其它函数(比如sdscpy、sd strim、sdsjoin等),还有Redis中其它一些能自动扩展内存的数据结构(如ziplist),也都是同样的使用模式。
浅谈sds与string的关系
现在我们回过头来看看本文开头给出的string操作的例子。
- append操作使用sds的sdscatlen来实现。前面已经提到。
- setbit和getrange都是先根据key取到整个sds字符串,然后再从字符串选取或修改指定的部分。由于sds就是一个字符数组,所以对它的某一部分进行操作似乎都比较简单。
但是,string除了支持这些操作之外,当它存储的值是个数字的时候,它还支持incr、decr等操作。那么,当string存储数字值的时候,它的内部存储还是 sds吗?实际上,不是了。而且,这种情况下,setbit和getrange的实现也会有所不同。这些细节,我们放在下一篇介绍robj的时候再进行系统地讨论。
Redis内部数据结构详解(3)——robj
2016-06-14
本文是《Redis内部数据结构详解》系列的第三篇,讲述在Redis实现中的一个基础数据结构:robj。
那到底什么是robj呢?它有什么用呢?
从Redis的使用者的角度来看,一个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个da tabase维护了从key space到object space的映射关系。这个映射关系的key是string类型,而value可以是多种数据类型,比如:string, list, hash等。我们可以看到,key的类型固定是string,而value可能的类型是多个。
而从Redis内部实现的角度来看,在前面第一篇文章中,我们已经提到过,一个database内的这个映射关系是用一个dict来维护的。dict的key固定用一 种数据结构来表达就够了,这就是动态字符串sds。而value则比较复杂,为了在同一个dict内能够存储不同类型的value,这就需要一个通用的数据结构,这个 通用的数据结构就是robj(全名是redisObject)。举个例子:如果value是一个list,那么它的内部存储结构是一个quicklist(quick list的具体实现我们放在后面的文章讨论);如果value是一个string,那么它的内部存储结构一般情况下是一个sds。当然实际情况更复杂一点,比如一个s tring类型的value,如果它的值是一个数字,那么Redis内部还会把它转成long型来存储,从而减小内存使用。而一个robj既能表示一个sds,也能表 示一个quicklist,甚至还能表示一个long型。
robj的数据结构定义
在server.h中我们找到跟robj定义相关的代码,如下(注意,本系列文章中的代码片段全部来源于Redis源码的3.2分支):
/* Object types */
#define OBJ_STRING 0
#define OBJ_LIST 1
#define OBJ_SET 2
#define OBJ_ZSET 3
#define OBJ_HASH 4
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
`
一个robj包含如下5个字段:
- type: 对象的数据类型。占4个bit。可能的取值有5种:OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH,分别对应Redis对外暴露的5种数据结构(即我们在第一篇文章中提到的第一个层面的5种数据结构)。
- encoding: 对象的内部表示方式(也可以称为编码)。占4个bit。可能的取值有10种,即前面代码中的10个OBJ_ENCODING_XXX常量。
- lru: 做LRU替换算法用,占24个bit。这个不是我们这里讨论的重点,暂时忽略。
- refcount: 引用计数。它允许robj对象在某些情况下被共享。
- ptr: 数据指针。指向真正的数据。比如,一个代表string的robj,它的ptr可能指向一个sds结构;一个代表list的robj,它的ptr可能指向一个quicklist。
这里特别需要仔细察看的是encoding字段。对于同一个type,还可能对应不同的encoding,这说明同样的一个数据类型,可能存在不同的内部表示方式。而 不同的内部表示,在内存占用和查找性能上会有所不同。
比如,当type = OBJ_STRING的时候,表示这个robj存储的是一个string,这时encoding可以是下面3种中的一种:
- OBJ_ENCODING_RAW: string采用原生的表示方式,即用sds来表示。
- OBJ_ENCODING_INT: string采用数字的表示方式,实际上是一个long型。
- OBJ_ENCODING_EMBSTR: string采用一种特殊的嵌入式的sds来表示。接下来我们会讨论到这个细节。
再举一个例子:当type = OBJ_HASH的时候,表示这个robj存储的是一个hash,这时encoding可以是下面2种中的一种:
- OBJ_ENCODING_HT: hash采用一个dict来表示。
- OBJ_ENCODING_ZIPLIST: hash采用一个ziplist来表示(ziplist的具体实现我们放在后面的文章讨论)。
本文剩余主要部分将针对表示string的robj对象,围绕它的3种不同的encoding来深入讨论。前面代码段中出现的所有10种encoding,在这里我们 先简单解释一下,在这个系列后面的文章中,我们应该还有机会碰到它们。
- OBJ_ENCODING_RAW: 最原生的表示方式。其实只有string类型才会用这个encoding值(表示成sds)。
- OBJ_ENCODING_INT: 表示成数字。实际用long表示。
- OBJ_ENCODING_HT: 表示成dict。
- OBJ_ENCODING_ZIPMAP: 是个旧的表示方式,已不再用。在小于Redis 2.6的版本中才有。
- OBJ_ENCODING_LINKEDLIST: 也是个旧的表示方式,已不再用。
- OBJ_ENCODING_ZIPLIST: 表示成ziplist。
- OBJ_ENCODING_INTSET: 表示成intset。用于set数据结构。
- OBJ_ENCODING_SKIPLIST: 表示成skiplist。用于sorted set数据结构。
- OBJ_ENCODING_EMBSTR: 表示成一种特殊的嵌入式的sds。
- OBJ_ENCODING_QUICKLIST: 表示成quicklist。用于list数据结构。
我们来总结一下robj的作用:
- 为多种数据类型提供一种统一的表示方式。
- 允许同一类型的数据采用不同的内部表示,从而在某些情况下尽量节省内存。
- 支持对象共享和引用计数。当对象被共享的时候,只占用一份内存拷贝,进一步节省内存。
string robj的编码过程
当我们执行Redis的set命令的时候,Redis首先将接收到的value值(string类型)表示成一个type = OBJ_STRING并且encoding = OBJ_ENCODING_RAW的robj对象,然后在存入内部存储之前先执行一个编码过程,试图将它表示成另一种 更节省内存的encoding方式。这一过程的核心代码,是object.c中的tryObjectEncoding函数。
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
/* Make sure this is a string object, the only type we encode
* in this function. Other types use encoded memory efficient
* representations but are handled by the commands implementing
* the type. */
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
/* We try some specialized encoding only for objects that are
* RAW or EMBSTR encoded, in other words objects that are still
* in represented by an actually array of chars. */
if (!sdsEncodedObject(o)) return o;
/* It's not safe to encode shared objects: shared objects can be shared
* everywhere in the "object space" of Redis and may end in places where
* they are not handled. We handle them only as values in the keyspace. */
if (o->refcount > 1) return o;
/* Check if we can represent this string as a long integer.
* Note that we are sure that a string larger than 21 chars is not
* representable as a 32 nor 64 bit integer. */
len = sdslen(s);
if (len <= 21 && string2l(s,len,&value)) {
/* This object is encodable as a long. Try to use a shared object.
* Note that we avoid using shared integers when maxmemory is used
* because every object needs to have a private LRU field for the LRU
* algorithm to work well. */
if ((server.maxmemory == 0 ||
(server.maxmemory_policy != MAXMEMORY_VOLATILE_LRU &&
server.maxmemory_policy != MAXMEMORY_ALLKEYS_LRU)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
if (o->encoding == OBJ_ENCODING_RAW) sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
}
}
/* If the string is small and is still RAW encoded,
* try the EMBSTR encoding which is more efficient.
* In this representation the object and the SDS string are allocated
* in the same chunk of memory to save space and cache misses. */
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
/* We can't encode the object...
*
* Do the last try, and at least optimize the SDS string inside
* the string object to require little space, in case there
* is more than 10% of free space at the end of the SDS string.
*
* We do that only for relatively large strings as this branch
* is only entered if the length of the string is greater than
* OBJ_ENCODING_EMBSTR_SIZE_LIMIT. */
if (o->encoding == OBJ_ENCODING_RAW &&
sdsavail(s) > len/10)
{
o->ptr = sdsRemoveFreeSpace(o->ptr);
}
/* Return the original object. */
return o;
}
这段代码执行的操作比较复杂,我们有必要仔细看一下每一步的操作:
- 第1步检查,检查type。确保只对string类型的对象进行操作。
- 第2步检查,检查encoding。sdsEncodedObject是定义在server.h中的一个宏,确保只对OBJ_ENCODING_RAW和OBJ_ENCODING_EMBSTR编码的string对象进行操作。这两种编码的string都采用sds来存储,可以尝试进一步编码处理。
#define sdsEncodedObject(objptr) (objptr->encoding == OBJ_ENCODING_RAW || objptr->encoding == OBJ_ENCODING_EMBSTR)
- 第3步检查,检查refcount。引用计数大于1的共享对象,在多处被引用。由于编码过程结束后robj的对象指针可能会变化(我们在前一篇介绍sdscatlen函数的时候提到过类似这种接口使用模式),这样对于引用计数大于1的对象,就需要更新所有地方的引用,这不容易做到。因此,对于计数大于1的对象不做编码处理。
- 试图将字符串转成64位的long。64位的long所能表达的数据范围是-2^63到2^63-1,用十进制表达出来最长是20位数(包括负号)。这里判断小于等于21,似乎是写多了,实际判断小于等于20就够了(如果我算错了请一定告诉我哦)。string2l如果将字符串转成long转成功了,那么会返回1并且将转好的long存到value变量里。
- 在转成long成功时,又分为两种情况。
- 第一种情况:如果Redis的配置不要求运行LRU替换算法,且转成的long型数字的值又比较小(小于OBJ_SHARED_INTEGERS,在目前的实现中这个值是10000),那么会使用共享数字对象来表示。之所以这里的判断跟LRU有关,是因为LRU算法要求每个robj有不同的lru字段值,所以用了LRU就不能共享robj。shared.integers是一个长度为10000的数组,里面预存了10000个小的数字对象。这些小数字对象都是encoding = OBJ_ENCODING_INT的string robj对象。
- 第二种情况:如果前一步不能使用共享小对象来表示,那么将原来的robj编码成encoding = OBJ_ENCODING_INT,这时ptr字段直接存成这个long型的值。注意ptr字段本来是一个void *指针(即存储的是内存地址),因此在64位机器上有64位宽度,正好能存储一个64位的long型值。这样,除了robj本身之外,它就不再需要额外的内存空间来存储字符串值。
- 接下来是对于那些不能转成64位long的字符串进行处理。最后再做两步处理:
- 如果字符串长度足够小(小于等于OBJ_ENCODING_EMBSTR_SIZE_LIMIT,定义为44),那么调用createEmbeddedStringObject编码成encoding = OBJ_ENCODING_EMBSTR;
- 如果前面所有的编码尝试都没有成功(仍然是OBJ_ENCODING_RAW),且sds里空余字节过多,那么做最后一次努力,调用sds的sdsRemoveFreeSpace接口来释放空余字节。
其中调用的createEmbeddedStringObject,我们有必要看一下它的代码:
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
o->lru = LRU_CLOCK();
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
createEmbeddedStringObject对sds重新分配内存,将robj和sds放在一个连续的内存块中分配,这样对于短字符串的存储有利于减少内存 碎片。这个连续的内存块包含如下几部分:
- 16个字节的robj结构。
- 3个字节的sdshdr8头。
- 最多44个字节的sds字符数组。
- 1个NULL结束符。
加起来一共不超过64字节(16+3+44+1),因此这样的一个短字符串可以完全分配在一个64字节长度的内存块中。
string robj的解码过程
当我们需要获取字符串的值,比如执行get命令的时候,我们需要执行与前面讲的编码过程相反的操作——解码。
这一解码过程的核心代码,是object.c中的getDecodedObject函数。
robj *getDecodedObject(robj *o) {
robj *dec;
if (sdsEncodedObject(o)) {
incrRefCount(o);
return o;
}
if (o->type == OBJ_STRING && o->encoding == OBJ_ENCODING_INT) {
char buf[32];
ll2string(buf,32,(long)o->ptr);
dec = createStringObject(buf,strlen(buf));
return dec;
} else {
serverPanic("Unknown encoding type");
}
}
这个过程比较简单,需要我们注意的点有:
- 编码为OBJ_ENCODING_RAW和OBJ_ENCODING_EMBSTR的字符串robj对象,不做变化,原封不动返回。站在使用者的角度,这两种编码没有什么区别,内部都是封装的sds。
编码为数字的字符串robj对象,将long重新转为十进制字符串的形式,然后调用createStringObject转为sds的表示。注意:这里由long转成的sds字符串长度肯定不超过20,而根据createStringObject的实现,它们肯定会被编码成OBJ_ENCODING_EMBSTR的对象。createStringObject的代码如下:
robj createStringObject(const char ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) return createEmbeddedStringObject(ptr,len); else return createRawStringObject(ptr,len);}
再谈sds与string的关系
在上一篇文章中,我们简单地提到了sds与string的关系;在本文介绍了robj的概念之后,我们重新总结一下sds与string的关系。
- 确切地说,string在Redis中是用一个robj来表示的。
- 用来表示string的robj可能编码成3种内部表示:OBJ_ENCODING_RAW, OBJ_ENCODING_EMBSTR, OBJ_ENCODING_INT。其中前两种编码使用的是sds来存储,最后一种OBJ_ENCODING_INT编码直接把string存成了long型。
- 在对string进行incr, decr等操作的时候,如果它内部是OBJ_ENCODING_INT编码,那么可以直接进行加减操作;如果它内部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把sds存储的字符串转成long型,如果能转成功,再进行加减操作。
- 对一个内部表示成long型的string执行append, setbit, getrange这些命令,针对的仍然是string的值(即十进制表示的字符串),而不是针对内部表示的long型进行操作。比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。而如果将字符串”32”按照内部的64位long型来解释,那么它是0x0000000000000020,在这个基础上执行setbit位操作,结果就完全不对了。因此,在这些命令的实现中,会把long型先转成字符串再进行相应的操作。由于篇幅原因,这三个命令的实现代码这里就不详细介绍了,有兴趣的读者可以参考Redis源码:
- t_string.c中的appendCommand函数;
- biops.c中的setbitCommand函数;
- t_string.c中的getrangeCommand函数。
值得一提的是,append和setbit命令的实现中,都会最终调用到db.c中的dbUnshareStringValue函数,将string对象的内部编码转 成OBJ_ENCODING_RAW的(只有这种编码的robj对象,其内部的sds 才能在后面自由追加新的内容),并解除可能存在的对象共享状态。这里面调用了前面提到的getDecodedObject。
robj *dbUnshareStringValue(redisDb *db, robj *key, robj *o) {
serverAssert(o->type == OBJ_STRING);
if (o->refcount != 1 || o->encoding != OBJ_ENCODING_RAW) {
robj *decoded = getDecodedObject(o);
o = createRawStringObject(decoded->ptr, sdslen(decoded->ptr));
decrRefCount(decoded);
dbOverwrite(db,key,o);
}
return o;
}
`
robj的引用计数操作
将robj的引用计数加1和减1的操作,定义在object.c中:
void incrRefCount(robj *o) {
o->refcount++;
}
void decrRefCount(robj *o) {
if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
if (o->refcount == 1) {
switch(o->type) {
case OBJ_STRING: freeStringObject(o); break;
case OBJ_LIST: freeListObject(o); break;
case OBJ_SET: freeSetObject(o); break;
case OBJ_ZSET: freeZsetObject(o); break;
case OBJ_HASH: freeHashObject(o); break;
default: serverPanic("Unknown object type"); break;
}
zfree(o);
} else {
o->refcount--;
}
}
`
我们特别关注一下将引用计数减1的操作decrRefCount。如果只剩下最后一个引用了(refcount已经是1了),那么在decrRefCount被调用后 ,整个robj将被释放。
注意:Redis的del命令就依赖decrRefCount操作将value释放掉。
经过了本文的讨论,我们很容易看出,robj所表示的就是Redis对外暴露的第一层面的数据结构:string, list, hash, set, sorted set,而每一种数据结构的底层实现所对应的是哪个(或哪些)第二层面的数据结构(dict, sds, ziplist, quicklist, skiplist, 等),则通过不同的encoding来区分。可以说,robj是联结两个层面的数据结构的桥梁。
本文详细介绍了OBJ_STRING类型的字符串对象的底层实现,其编码和解码过程在Redis里非常重要,应用广泛,我们在后面的讨论中可能还会遇到。现在有了ro bj的概念基础,我们下一篇会讨论ziplist,以及它与hash的关系。
后记(追加于2016-07-09): 本文在解析“将string编码成long型”的代码时提到的判断21字节的问题,后来已经提交给@antirez并合并进了unstable分支,详见commit f648c5a。
原文出处:Redis内部数据结构详解(4)——ziplist
Redis内部数据结构详解(4)——ziplist
2016-07-07
本文是《Redis内部数据结构详解》系列的第四篇。在本文中,我们首先介绍一个新的Redis内部数据结构——ziplist,然后在文章后半部分我们会讨论一下在robj, dict和ziplist的基础上,Redis对外暴露的hash结构是怎样构建起来的。
我们在讨论中还会涉及到两个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
本文的后半部分会对这两个配置做详细的解释。
什么是ziplist
Redis官方对于ziplist的定义是(出自ziplist.c的文件头部注释):
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time.
翻译一下就是说:ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进
制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供push和pop操作。
实际上,ziplist充分体现了Redis对于存储效率的追求。一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这 种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。而ziplist却是将表中每一项存放在前后连续的地址空间内,一个ziplist整体占用一大块内存 。它是一个表(list),但其实不是一个链表(linked list)。
另外,ziplist为了在细节上节省内存,对于值的存储采用了变长的编码方式,大概意思是说,对于大的整数,就多用一些字节来存储,而对于小的整数,就少用一些字节 来存储。我们接下来很快就会讨论到这些实现细节。
ziplist的数据结构定义
ziplist的数据结构组成是本文要讨论的重点。实际上,ziplist还是稍微有点复杂的,它复杂的地方就在于它的数据结构定义。一旦理解了数据结构,它的一些操 作也就比较容易理解了。
我们接下来先从总体上介绍一下ziplist的数据结构定义,然后举一个实际的例子,通过例子来解释ziplist的构成。如果你看懂了这一部分,本文的任务就算完成 了一大半了。
从宏观上看,ziplist的内存结构如下:
<zlbytes><zltail><zllen><entry>...<entry><zlend>
各个部分在内存上是前后相邻的,它们分别的含义如下:
<zlbytes>: 32bit,表示ziplist占用的字节总数(也包括<zlbytes>本身占用的4个字节)。<zltail>: 32bit,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。<zllen>: 16bit, 表示ziplist中数据项(entry)的个数。zllen字段因为只有16bit,所以可以表达的最大值为2^16-1。这里需要特别注意的是,如果ziplist中数据项个数超过了16bit能表达的最大值,ziplist仍然可以来表示。那怎么表示呢?这里做了这样的规定:如果<zllen>小于等于2^16-2(也就是不等于2^16-1),那么<zllen>就表示ziplist中数据项的个数;否则,也就是<zllen>等于16bit全为1的情况,那么<zllen>就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。<entry>: 表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构,这个稍后再解释。<zlend>: ziplist最后1个字节,是一个结束标记,值固定等于255。
上面的定义中还值得注意的一点是:<zlbytes>, <zltail>, <zllen>既然占据多个字节,那么在存储的时候就有大端(big
endian)和小端(little endian)的区别。ziplist采取的是小端模式来存储,这在下面我们介绍具体例子的时候还会再详细解释。
我们再来看一下每一个数据项<entry>的构成:
<prevrawlen><len><data>
我们看到在真正的数据(<data>)前面,还有两个字段:
<prevrawlen>: 表示前一个数据项占用的总字节数。这个字段的用处是为了让ziplist能够从后向前遍历(从后一项的位置,只需向前偏移prevrawlen个字节,就找到了前一项)。这个字段采用变长编码。<len>: 表示当前数据项的数据长度(即<data>部分的长度)。也采用变长编码。
那么<prevrawlen>和<len>是怎么进行变长编码的呢?各位读者打起精神了,我们终于讲到了ziplist的定义中最繁琐的地方了。
先说<prevrawlen>。它有两种可能,或者是1个字节,或者是5个字节:
- 如果前一个数据项占用字节数小于254,那么
<prevrawlen>就只用一个字节来表示,这个字节的值就是前一个数据项的占用字节数。 - 如果前一个数据项占用字节数大于等于254,那么
<prevrawlen>就用5个字节来表示,其中第1个字节的值是254(作为这种情况的一个标记),而后面4个字节组成一个整型值,来真正存储前一个数据项的占用字节数。
有人会问了,为什么没有255的情况呢?
这是因为:255已经定义为ziplist结束标记<zlend>的值了。在ziplist的很多操作的实现中,都会根据数据项的第1个字节是不是255来判断当
前是不是到达ziplist的结尾了,因此一个正常的数据的第1个字节(也就是<prevrawlen>的第1个字节)是不能够取255这个值的,否则就冲突了。
而<len>字段就更加复杂了,它根据第1个字节的不同,总共分为9种情况(下面的表示法是按二进制表示):
- |00pppppp| - 1 byte。第1个字节最高两个bit是00,那么
<len>字段只有1个字节,剩余的6个bit用来表示长度值,最高可以表示63 (2^6-1)。 - |01pppppp|qqqqqqqq| - 2 bytes。第1个字节最高两个bit是01,那么
<len>字段占2个字节,总共有14个bit用来表示长度值,最高可以表示16383 (2^14-1)。 - |10__|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes。第1个字节最高两个bit是10,那么len字段占5个字节,总共使用32个bit来表示长度值(6个bit舍弃不用),最高可以表示2^32-1。需要注意的是:在前三种情况下,
<data>都是按字符串来存储的;从下面第4种情况开始,<data>开始变为按整数来存储了。 - |11000000| - 1 byte。
<len>字段占用1个字节,值为0xC0,后面的数据<data>存储为2个字节的int16_t类型。 - |11010000| - 1 byte。
<len>字段占用1个字节,值为0xD0,后面的数据<data>存储为4个字节的int32_t类型。 - |11100000| - 1 byte。
<len>字段占用1个字节,值为0xE0,后面的数据<data>存储为8个字节的int64_t类型。 - |11110000| - 1 byte。
<len>字段占用1个字节,值为0xF0,后面的数据<data>存储为3个字节长的整数。 - |11111110| - 1 byte。
<len>字段占用1个字节,值为0xFE,后面的数据<data>存储为1个字节的整数。 - |1111xxxx| - - (xxxx的值在0001和1101之间)。这是一种特殊情况,xxxx从1到13一共13个值,这时就用这13个值来表示真正的数据。注意,这里是表示真正的数据,而不是数据长度了。也就是说,在这种情况下,后面不再需要一个单独的
<data>字段来表示真正的数据了,而是<len>和<data>合二为一了。另外,由于xxxx只能取0001和1101这13个值了(其它可能的值和其它情况冲突了,比如0000和1110分别同前面第7种第8种情况冲突,1111跟结束标记冲突),而小数值应该从0开始,因此这13个值分别表示0到12,即xxxx的值减去1才是它所要表示的那个整数数据的值。
好了,ziplist的数据结构定义,我们介绍了完了,现在我们看一个具体的例子。
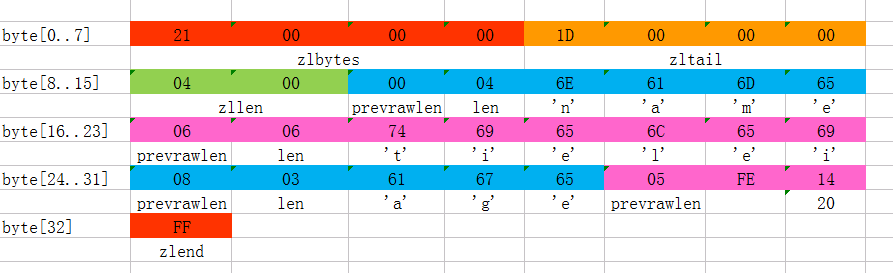
上图是一份真实的ziplist数据。我们逐项解读一下:
- 这个ziplist一共包含33个字节。字节编号从byte[0]到byte[32]。图中每个字节的值使用16进制表示。
- 头4个字节(0x21000000)是按小端(little endian)模式存储的
<zlbytes>字段。什么是小端呢?就是指数据的低字节保存在内存的低地址中(参见维基百科词条Endianness)。因此,这里<zlbytes>的值应该解析成0x00000021,用十进制表示正好就是33。 - 接下来4个字节(byte[4..7])是
<zltail>,用小端存储模式来解释,它的值是0x0000001D(值为29),表示最后一个数据项在byte[29]的位置(那个数据项为0x05FE14)。 - 再接下来2个字节(byte[8..9]),值为0x0004,表示这个ziplist里一共存有4项数据。
- 接下来6个字节(byte[10..15])是第1个数据项。其中,prevrawlen=0,因为它前面没有数据项;len=4,相当于前面定义的9种情况中的第1种,表示后面4个字节按字符串存储数据,数据的值为”name”。
- 接下来8个字节(byte[16..23])是第2个数据项,与前面数据项存储格式类似,存储1个字符串”tielei”。
- 接下来5个字节(byte[24..28])是第3个数据项,与前面数据项存储格式类似,存储1个字符串”age”。
- 接下来3个字节(byte[29..31])是最后一个数据项,它的格式与前面的数据项存储格式不太一样。其中,第1个字节prevrawlen=5,表示前一个数据项占用5个字节;第2个字节=FE,相当于前面定义的9种情况中的第8种,所以后面还有1个字节用来表示真正的数据,并且以整数表示。它的值是20(0x14)。
- 最后1个字节(byte[32])表示
<zlend>,是固定的值255(0xFF)。
总结一下,这个ziplist里存了4个数据项,分别为:
- 字符串: “name”
- 字符串: “tielei”
- 字符串: “age”
- 整数: 20
(好吧,被你发现了~~tielei实际上当然不是20岁,他哪有那么年轻啊……)
实际上,这个ziplist是通过两个hset命令创建出来的。这个我们后半部分会再提到。
好了,既然你已经阅读到这里了,说明你还是很有耐心的(其实我写到这里也已经累得不行了)。可以先把本文收藏,休息一下,回头再看后半部分。
接下来我要贴一些代码了。
ziplist的接口
我们先不着急看实现,先来挑几个ziplist的重要的接口,看看它们长什么样子:
unsigned char *ziplistNew(void);
unsigned char *ziplistMerge(unsigned char **first, unsigned char **second);
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where);
unsigned char *ziplistIndex(unsigned char *zl, int index);
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p);
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p);
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen);
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p);
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip);
unsigned int ziplistLen(unsigned char *zl);
我们从这些接口的名字就可以粗略猜出它们的功能,下面简单解释一下:
- ziplist的数据类型,没有用自定义的struct之类的来表达,而就是简单的unsigned char *。这是因为ziplist本质上就是一块连续内存,内部组成结构又是一个高度动态的设计(变长编码),也没法用一个固定的数据结构来表达。
- ziplistNew: 创建一个空的ziplist(只包含
<zlbytes><zltail><zllen><zlend>)。 - ziplistMerge: 将两个ziplist合并成一个新的ziplist。
- ziplistPush: 在ziplist的头部或尾端插入一段数据(产生一个新的数据项)。注意一下这个接口的返回值,是一个新的ziplist。调用方必须用这里返回的新的ziplist,替换之前传进来的旧的ziplist变量,而经过这个函数处理之后,原来旧的ziplist变量就失效了。为什么一个简单的插入操作会导致产生一个新的ziplist呢?这是因为ziplist是一块连续空间,对它的追加操作,会引发内存的realloc,因此ziplist的内存位置可能会发生变化。实际上,我们在之前介绍sds的文章中提到过类似这种接口使用模式(参见sdscatlen函数的说明)。
- ziplistIndex: 返回index参数指定的数据项的内存位置。index可以是负数,表示从尾端向前进行索引。
- ziplistNext和ziplistPrev分别返回一个ziplist中指定数据项p的后一项和前一项。
- ziplistInsert: 在ziplist的任意数据项前面插入一个新的数据项。
- ziplistDelete: 删除指定的数据项。
- ziplistFind: 查找给定的数据(由vstr和vlen指定)。注意它有一个skip参数,表示查找的时候每次比较之间要跳过几个数据项。为什么会有这么一个参数呢?其实这个参数的主要用途是当用ziplist表示hash结构的时候,是按照一个field,一个value来依次存入ziplist的。也就是说,偶数索引的数据项存field,奇数索引的数据项存value。当按照field的值进行查找的时候,就需要把奇数项跳过去。
- ziplistLen: 计算ziplist的长度(即包含数据项的个数)。
ziplist的插入逻辑解析
ziplist的相关接口的具体实现,还是有些复杂的,限于篇幅的原因,我们这里只结合代码来讲解插入的逻辑。插入是很有代表性的操作,通过这部分来一窥ziplis t内部的实现,其它部分的实现我们也就会很容易理解了。
ziplistPush和ziplistInsert都是插入,只是对于插入位置的限定不同。它们在内部实现都依赖一个名为__ziplistInsert的内部函数 ,其代码如下(出自ziplist.c):
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipPrevEncodeLength(NULL,prevlen);
reqlen += zipEncodeLength(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
/* Store offset because a realloc may change the address of zl. */
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
zipPrevEncodeLength(p+reqlen,reqlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
p += zipPrevEncodeLength(p,prevlen);
p += zipEncodeLength(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
我们来简单解析一下这段代码:
- 这个函数是在指定的位置p插入一段新的数据,待插入数据的地址指针是s,长度为slen。插入后形成一个新的数据项,占据原来p的配置,原来位于p位置的数据项以及后面的所有数据项,需要统一向后移动,给新插入的数据项留出空间。参数p指向的是ziplist中某一个数据项的起始位置,或者在向尾端插入的时候,它指向ziplist的结束标记
<zlend>。 - 函数开始先计算出待插入位置前一个数据项的长度
prevlen。这个长度要存入新插入的数据项的<prevrawlen>字段。 - 然后计算当前数据项占用的总字节数
reqlen,它包含三部分:<prevrawlen>,<len>和真正的数据。其中的数据部分会通过调用zipTryEncoding先来尝试转成整数。 - 由于插入导致的ziplist对于内存的新增需求,除了待插入数据项占用的
reqlen之外,还要考虑原来p位置的数据项(现在要排在待插入数据项之后)的<prevrawlen>字段的变化。本来它保存的是前一项的总长度,现在变成了保存当前插入的数据项的总长度。这样它的<prevrawlen>字段本身需要的存储空间也可能发生变化,这个变化可能是变大也可能是变小。这个变化了多少的值nextdiff,是调用zipPrevLenByteDiff计算出来的。如果变大了,nextdiff是正值,否则是负值。 - 现在很容易算出来插入后新的ziplist需要多少字节了,然后调用
ziplistResize来重新调整大小。ziplistResize的实现里会调用allocator的zrealloc,它有可能会造成数据拷贝。 - 现在额外的空间有了,接下来就是将原来p位置的数据项以及后面的所有数据都向后挪动,并为它设置新的
<prevrawlen>字段。此外,还可能需要调整ziplist的<zltail>字段。 - 最后,组装新的待插入数据项,放在位置p。
hash与ziplist
hash是Redis中可以用来存储一个对象结构的比较理想的数据类型。一个对象的各个属性,正好对应一个hash结构的各个field。
我们在网上很容易找到这样一些技术文章,它们会说存储一个对象,使用hash比string要节省内存。实际上这么说是有前提的,具体取决于对象怎么来存储。如果你把 对象的多个属性存储到多个key上(各个属性值存成string),当然占的内存要多。但如果你采用一些序列化方法,比如Protocol Buffers,或者Apache Thrift,先把对象序列化为字节数组,然后再存入到Redis的string中,那么跟hash相比,哪一种更省内存,就不一定了。
当然,hash比序列化后再存入string的方式,在支持的操作命令上,还是有优势的:它既支持多个field同时存取(hmset/hmget),也支持
按照某个特定的field单独存取(hset/hget)。
实际上,hash随着数据的增大,其底层数据结构的实现是会发生变化的,当然存储效率也就不同。在field比较少,各个value值也比较小的时候,hash采用z iplist来实现;而随着field增多和value值增大,hash可能会变成dict来实现。当hash底层变成dict来实现的时候,它的存储效率就没法跟那 些序列化方式相比了。
当我们为某个key第一次执行 hset key field value
命令的时候,Redis会创建一个hash结构,这个新创建的hash底层就是一个ziplist。
robj *createHashObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
上面的createHashObject函数,出自object.c,它负责的任务就是创建一个新的hash结构。可以看出,它创建了一个type =
OBJ_HASH但encoding = OBJ_ENCODING_ZIPLIST的robj对象。
实际上,本文前面给出的那个ziplist实例,就是由如下两个命令构建出来的。
hset user:100 name tielei
hset user:100 age 20
每执行一次hset命令,插入的field和value分别作为一个新的数据项插入到ziplist中(即每次hset产生两个数据项)。
当随着数据的插入,hash底层的这个ziplist就可能会转成dict。那么到底插入多少才会转呢?
还记得本文开头提到的两个Redis配置吗?
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
这个配置的意思是说,在如下两个条件之一满足的时候,ziplist会转成dict:
- 当hash中的数据项(即field-value对)的数目超过512的时候,也就是ziplist数据项超过1024的时候(请参考t_hash.c中的
hashTypeSet函数)。 - 当hash中插入的任意一个value的长度超过了64的时候(请参考t_hash.c中的
hashTypeTryConversion函数)。
Redis的hash之所以这样设计,是因为当ziplist变得很大的时候,它有如下几个缺点:
- 每次插入或修改引发的realloc操作会有更大的概率造成内存拷贝,从而降低性能。
- 一旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更大的一块数据。
- 当ziplist数据项过多的时候,在它上面查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
总之,ziplist本来就设计为各个数据项挨在一起组成连续的内存空间,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存realloc,可能导致内存 拷贝。
原文出处:Redis内部数据结构详解(5)——quicklist
本文是《Redis内部数据结构详解》系列的第五篇。在本文中,我们介绍一个Redis内部数据结构 ——quicklist。Redis对外暴露的list数据类型,它底层实现所依赖的内部数据结构就是quicklist。
我们在讨论中还会涉及到两个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
list-max-ziplist-size -2
list-compress-depth 0
我们在讨论中会详细解释这两个配置的含义。
注:本文讨论的quicklist实现基于Redis源码的3.2分支。
quicklist概述
Redis对外暴露的上层list数据类型,经常被用作队列使用。比如它支持的如下一些操作:
lpush: 在左侧(即列表头部)插入数据。rpop: 在右侧(即列表尾部)删除数据。rpush: 在右侧(即列表尾部)插入数据。lpop: 在左侧(即列表头部)删除数据。
这些操作都是O(1)时间复杂度的。
当然,list也支持在任意中间位置的存取操作,比如lindex和linsert,但它们都需要对list进行遍历,所以时间复杂度较高。
概况起来,list具有这样的一些特点:它是一个有序列表,便于在表的两端追加和删除数据,而对于中间位置的存取具有O(N)的时间复杂度。这不正是一个双向链表所具有的特点吗?
list的内部实现quicklist正是一个双向链表。在quicklist.c的文件头部注释中,是这样描述quicklist的:
A doubly linked list of ziplists
它确实是一个双向链表,而且是一个ziplist的双向链表。
这是什么意思呢?
我们知道,双向链表是由多个节点(Node)组成的。这个描述的意思是:quicklist的每个节点都是一个ziplist。ziplist我们已经在上一篇介绍过。
ziplist本身也是一个有序列表,而且是一个内存紧缩的列表(各个数据项在内存上前后相邻)。比如,一个包含3个节点的quicklist,如果每个节点的ziplist又包含4个数据项,那么对外表现上,这个list就总共包含12个数据项。
quicklist的结构为什么这样设计呢?总结起来,大概又是一个空间和时间的折中:
- 双向链表便于在表的两端进行push和pop操作,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
- ziplist由于是一整块连续内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发一次内存的realloc。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
于是,结合了双向链表和ziplist的优点,quicklist就应运而生了。
不过,这也带来了一个新问题:到底一个quicklist节点包含多长的ziplist合适呢?比如,同样是存储12个数据项,既可以是一个quicklist包含3个节点,而每个节点的ziplist又包含4个数据项,也可以是一个quicklist包含6个节点,而每个节点的ziplist又包含2个数据项。
这又是一个需要找平衡点的难题。我们只从存储效率上分析一下:
- 每个quicklist节点上的ziplist越短,则内存碎片越多。内存碎片多了,有可能在内存中产生很多无法被利用的小碎片,从而降低存储效率。这种情况的极端是每个quicklist节点上的ziplist只包含一个数据项,这就蜕化成一个普通的双向链表了。
- 每个quicklist节点上的ziplist越长,则为ziplist分配大块连续内存空间的难度就越大。有可能出现内存里有很多小块的空闲空间(它们加起来很多),但却找不到一块足够大的空闲空间分配给ziplist的情况。这同样会降低存储效率。这种情况的极端是整个quicklist只有一个节点,所有的数据项都分配在这仅有的一个节点的ziplist里面。这其实蜕化成一个ziplist了。
可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?这可能取决于具体应用场景。实际上,Redis提供了一个配置参数
list-max-ziplist-size,就是为了让使用者可以来根据自己的情况进行调整。
list-max-ziplist-size -2
我们来详细解释一下这个参数的含义。它可以取正值,也可以取负值。
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。
当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
- -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
另外,list的设计目标是能够用来存储很长的数据列表的。比如,Redis官网给出的这个教程:Writing a simple Twitter clone with PHP and Redis,就是使用list来存储类似Twitter的timeline数据。
当列表很长的时候,最容易被访问的很可能是两端的数据,中间的数据被访问的频率比较低(访问起来性能也很低)。如果应用场景符合这个特点,那么list还提供了一个选项,能够把中间的数据节点进行压缩,从而进一步节省内存空间。Redis的配置参数list-compress-depth就是用来完成这个设置的。
list-compress-depth 0
这个参数表示一个quicklist两端不被压缩的节点个数。注:这里的节点个数是指quicklist双向链表的节点个数,而不是指ziplist里面的数据项个数。实际上,一个quicklist节点上的ziplist,如果被压缩,就是整体被压缩的。
参数list-compress-depth的取值含义如下:
- 0: 是个特殊值,表示都不压缩。这是Redis的默认值。
- 1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
- 2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
- 3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
- 依此类推…
由于0是个特殊值,很容易看出quicklist的头节点和尾节点总是不被压缩的,以便于在表的两端进行快速存取。
Redis对于quicklist内部节点的压缩算法,采用的LZF——一种无损压缩算法。
quicklist的数据结构定义
quicklist相关的数据结构定义可以在quicklist.h中找到:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
quicklistNode结构代表quicklist的一个节点,其中各个字段的含义如下:
- prev: 指向链表前一个节点的指针。
- next: 指向链表后一个节点的指针。
- zl: 数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF结构。
- sz: 表示zl指向的ziplist的总大小(包括
zlbytes,zltail,zllen,zlend和各个数据项)。需要注意的是:如果ziplist被压缩了,那么这个sz的值仍然是压缩前的ziplist大小。 - count: 表示ziplist里面包含的数据项个数。这个字段只有16bit。稍后我们会一起计算一下这16bit是否够用。
- encoding: 表示ziplist是否压缩了(以及用了哪个压缩算法)。目前只有两种取值:2表示被压缩了(而且用的是LZF压缩算法),1表示没有压缩。
- container: 是一个预留字段。本来设计是用来表明一个quicklist节点下面是直接存数据,还是使用ziplist存数据,或者用其它的结构来存数据(用作一个数据容器,所以叫container)。但是,在目前的实现中,这个值是一个固定的值2,表示使用ziplist作为数据容器。
- recompress: 当我们使用类似lindex这样的命令查看了某一项本来压缩的数据时,需要把数据暂时解压,这时就设置recompress=1做一个标记,等有机会再把数据重新压缩。
- attempted_compress: 这个值只对Redis的自动化测试程序有用。我们不用管它。
- extra: 其它扩展字段。目前Redis的实现里也没用上。
quicklistLZF结构表示一个被压缩过的ziplist。其中:
- sz: 表示压缩后的ziplist大小。
- compressed: 是个柔性数组(flexible array member),存放压缩后的ziplist字节数组。
真正表示quicklist的数据结构是同名的quicklist这个struct:
- head: 指向头节点(左侧第一个节点)的指针。
- tail: 指向尾节点(右侧第一个节点)的指针。
- count: 所有ziplist数据项的个数总和。
- len: quicklist节点的个数。
- fill: 16bit,ziplist大小设置,存放
list-max-ziplist-size参数的值。 - compress: 16bit,节点压缩深度设置,存放
list-compress-depth参数的值。
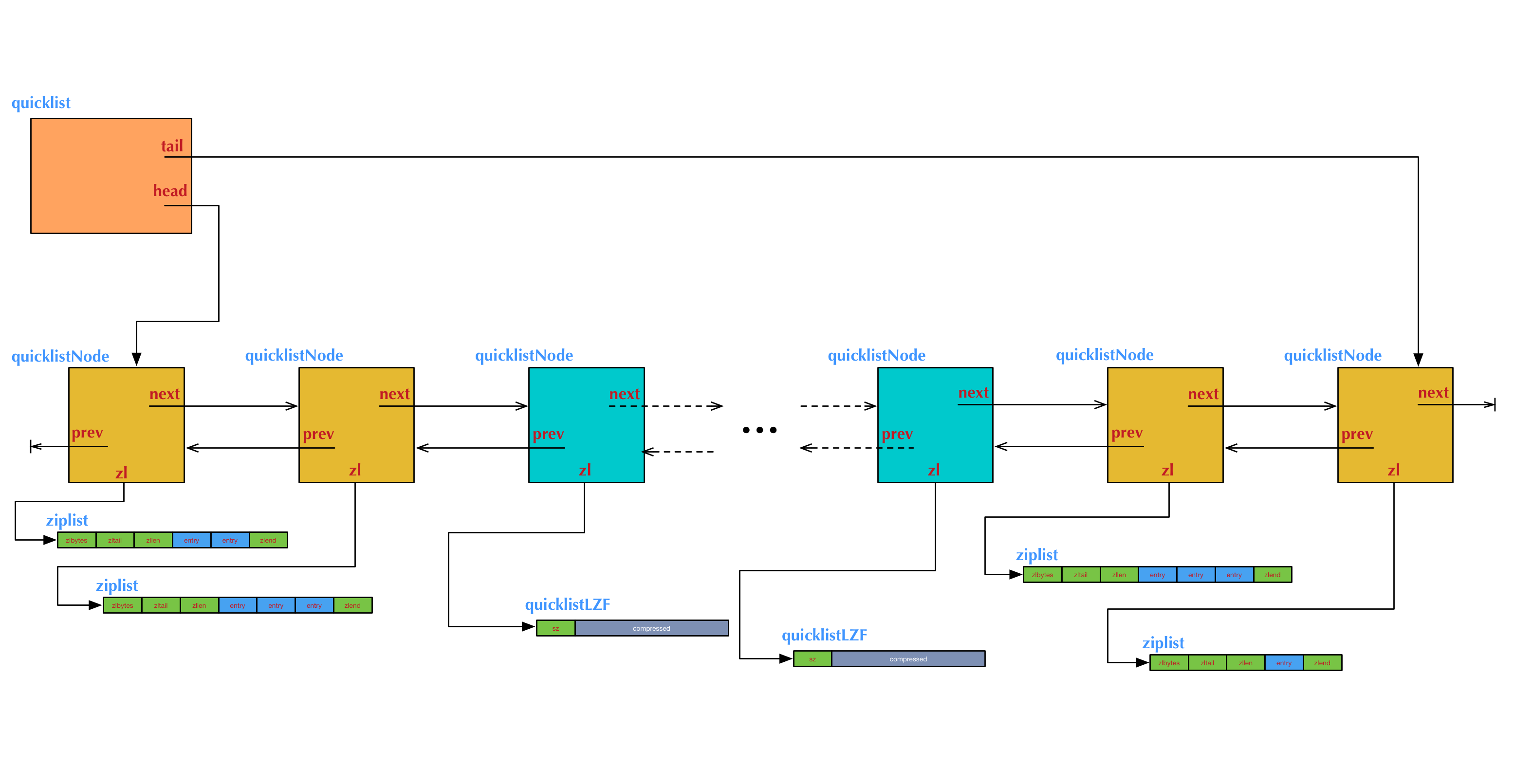
上图是一个quicklist的结构图举例。图中例子对应的ziplist大小配置和节点压缩深度配置,如下:
list-max-ziplist-size 3
list-compress-depth 2
这个例子中我们需要注意的几点是:
- 两端各有2个橙黄色的节点,是没有被压缩的。它们的数据指针zl指向真正的ziplist。中间的其它节点是被压缩过的,它们的数据指针zl指向被压缩后的ziplist结构,即一个quicklistLZF结构。
- 左侧头节点上的ziplist里有2项数据,右侧尾节点上的ziplist里有1项数据,中间其它节点上的ziplist里都有3项数据(包括压缩的节点内部)。这表示在表的两端执行过多次
push和pop操作后的一个状态。
现在我们来大概计算一下quicklistNode结构中的count字段这16bit是否够用。
我们已经知道,ziplist大小受到list-max-ziplist-size参数的限制。按照正值和负值有两种情况:
- 当这个参数取正值的时候,就是恰好表示一个quicklistNode结构中zl所指向的ziplist所包含的数据项的最大值。
list-max-ziplist-size参数是由quicklist结构的fill字段来存储的,而fill字段是16bit,所以它所能表达的值能够用16bit来表示。 - 当这个参数取负值的时候,能够表示的ziplist最大长度是64 Kb。而ziplist中每一个数据项,最少需要2个字节来表示:1个字节的
prevrawlen,1个字节的data(len字段和data合二为一;详见上一篇)。所以,ziplist中数据项的个数不会超过32 K,用16bit来表达足够了。
实际上,在目前的quicklist的实现中,ziplist的大小还会受到另外的限制,根本不会达到这里所分析的最大值。
下面进入代码分析阶段。
quicklist的创建
当我们使用lpush或rpush命令第一次向一个不存在的list里面插入数据的时候,Redis会首先调用quicklistCreate接口创建一
个空的quicklist。
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
return quicklist;
}
在很多介绍数据结构的书上,实现双向链表的时候经常会多增加一个空余的头节点,主要是为了插入和删除操作的方便。从上面quicklistCreate的代码可以
看出,quicklist是一个不包含空余头节点的双向链表(head和tail都初始化为NULL)。
quicklist的push操作
quicklist的push操作是调用quicklistPush来实现的。
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
quicklistPushTail(quicklist, value, sz);
}
}
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
/* Add new entry to tail node of quicklist.
*
* Returns 0 if used existing tail.
* Returns 1 if new tail created. */
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->zl =
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(quicklist->tail);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
}
quicklist->count++;
quicklist->tail->count++;
return (orig_tail != quicklist->tail);
}
不管是在头部还是尾部插入数据,都包含两种情况:
- 如果头节点(或尾节点)上ziplist大小没有超过限制(即
_quicklistNodeAllowInsert返回1),那么新数据被直接插入到ziplist中(调用ziplistPush)。 - 如果头节点(或尾节点)上ziplist太大了,那么新创建一个quicklistNode节点(对应地也会新创建一个ziplist),然后把这个新创建的节点插入到quicklist双向链表中(调用
_quicklistInsertNodeAfter)。
在_quicklistInsertNodeAfter的实现中,还会根据list-compress-depth的配置将里面的节点进行压缩。它的实现比较繁琐,我们这里就不展开讨论了。
quicklist的其它操作
quicklist的操作较多,且实现细节都比较繁杂,这里就不一一分析源码了,我们简单介绍一些比较重要的操作。
quicklist的pop操作是调用quicklistPopCustom来实现的。quicklistPopCustom的实现过程基本上跟quicklistPush相反,先从头部或尾部节点的ziplist中把对应的数据项删除,如果在删除后ziplist为空了,那么对应的头部或尾部节点也要删除。删除后还可能涉及到里面节点的解压缩问题。
quicklist不仅实现了从头部或尾部插入,也实现了从任意指定的位置插入。quicklistInsertAfter和quicklistInsertBefore就是分别在指定位置后面和前面插入数据项。这种在任意指定位置插入数据的操作,情况比较复杂,有众多的逻辑分支。
- 当插入位置所在的ziplist大小没有超过限制时,直接插入到ziplist中就好了;
- 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小没有超过限制,那么就转而插入到相邻的那个quicklist链表节点的ziplist中;
- 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小也超过限制,这时需要新创建一个quicklist链表节点插入。
- 对于插入位置所在的ziplist大小超过了限制的其它情况(主要对应于在ziplist中间插入数据的情况),则需要把当前ziplist分裂为两个节点,然后再其中一个节点上插入数据。
quicklistSetOptions用于设置ziplist大小配置参数(list-max-ziplist-size)和节点压缩深度配置参数(list-compress-depth)。代码比较简单,就是将相应的值分别设置给quicklist结构的fill字段和compress字段。
原文出处:Redis内部数据结构详解(6)——skiplist
本文是《Redis内部数据结构详解》系列的第六篇。在本文中,我们围绕一个Redis的内部数据结构——skiplist展开讨论。
Redis里面使用skiplist是为了实现sorted set这种对外的数据结构。sorted set提供的操作非常丰富,可以满足非常多的应用场景。这也意味着,sorted set相对来说实现比较复杂。同时,skiplist这种数据结构对于很多人来说都比较陌生,因为大部分学校里的算法课都没有对这种数据结构进行过详细的介绍。因此,为了介绍得足够清楚,本文会比这个系列的其它几篇花费更多的篇幅。
我们将大体分成三个部分进行介绍:
- 介绍经典的skiplist数据结构,并进行简单的算法分析。这一部分的介绍,与Redis没有直接关系。我会尝试尽量使用通俗易懂的语言进行描述。
- 讨论Redis里的skiplist的具体实现。为了支持sorted set本身的一些要求,在经典的skiplist基础上,Redis里的相应实现做了若干改动。
- 讨论sorted set是如何在skiplist, dict和ziplist基础上构建起来的。
我们在讨论中还会涉及到两个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
我们在讨论中会详细解释这两个配置的含义。
注:本文讨论的代码实现基于Redis源码的3.2分支。
skiplist数据结构简介
skiplist本质上也是一种查找结构,用于解决算法中的查找问题(Searching),即根据给定的key,快速查到它所在的位置(或者对应的value)。
我们在《Redis内部数据结构详解》系列的第一篇中介绍dict的时候,曾经讨论过:一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。但skiplist却比较特殊,它没法归属到这两大类里面。
这种数据结构是由William Pugh发明的,最早出现于他在1990年发表的论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》。对细节感兴趣的同学可以下载论文原文来阅读。
skiplist,顾名思义,首先它是一个list。实际上,它是在有序链表的基础上发展起来的。
我们先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):

在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:

- 23首先和7比较,再和19比较,比它们都大,继续向后比较。
- 但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
- 23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是3,那么就把它链入到第1层到第3层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个skiplist的过程:
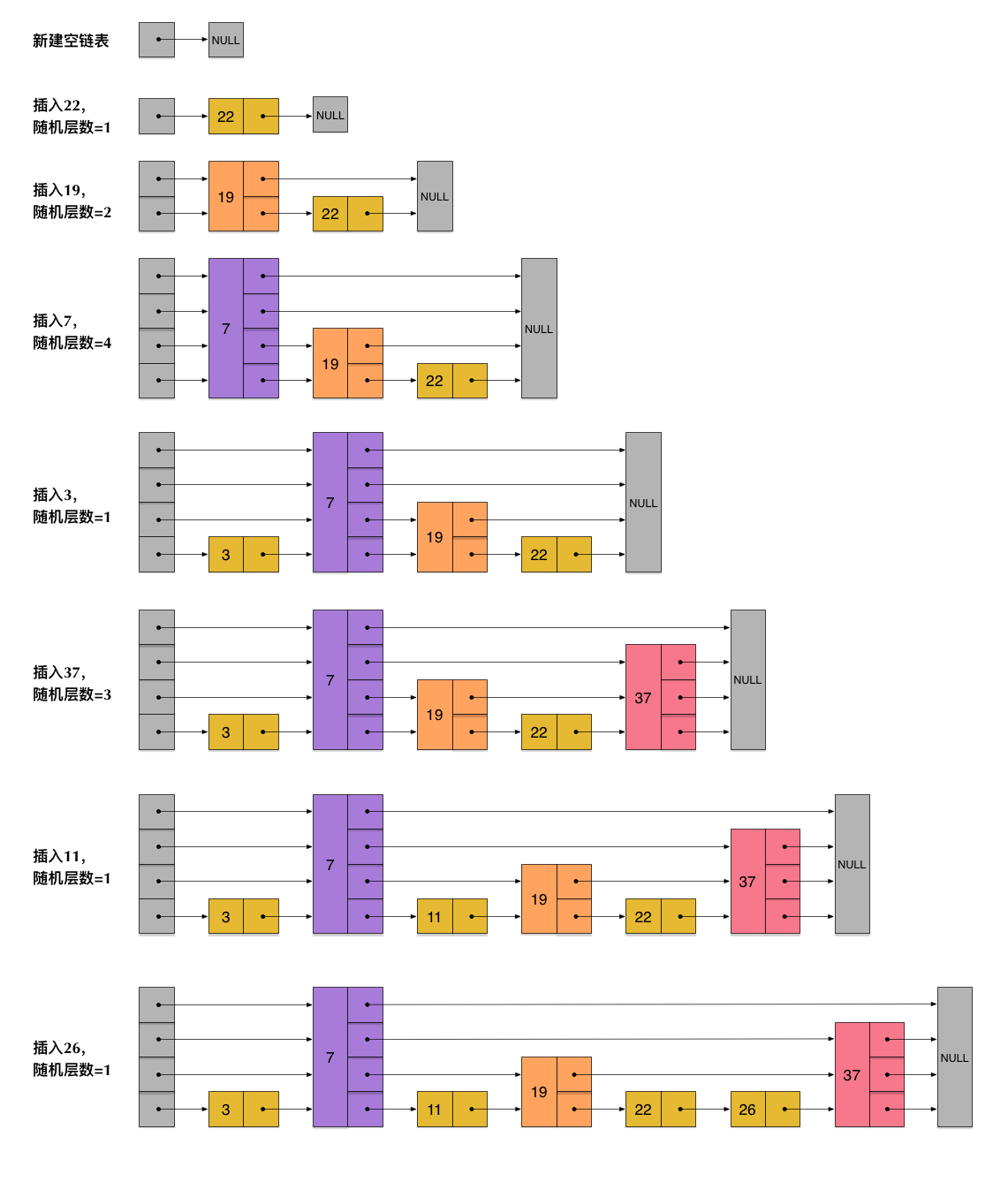
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。这在后面我们还会提到。
根据上图中的skiplist结构,我们很容易理解这种数据结构的名字的由来。skiplist,翻译成中文,可以翻译成“跳表”或“跳跃表”,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链 表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
刚刚创建的这个skiplist总共包含4层链表,现在假设我们在它里面依然查找23,下图给出了查找路径:
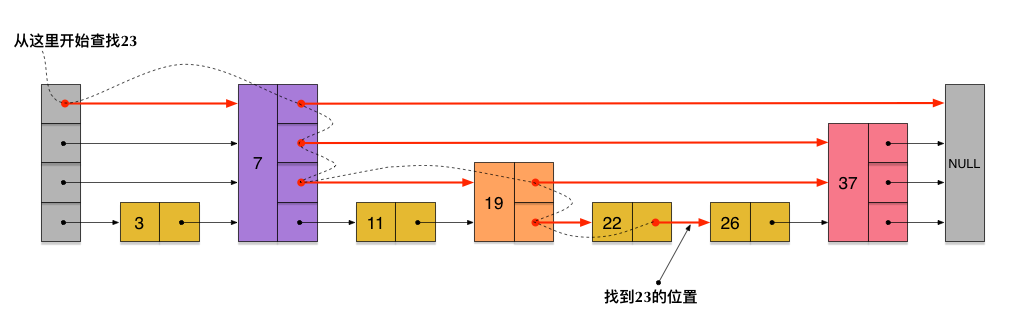
需要注意的是,前面演示的各个节点的插入过程,实际上在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
至此,skiplist的查找和插入操作,我们已经很清楚了。而删除操作与插入操作类似,我们也很容易想象出来。这些操作我们也应该能很容易地用代码实现出来。
当然,实际应用中的skiplist每个节点应该包含key和value两部分。前面的描述中我们没有具体区分key和value,但实际上列表中是按照key进行排序的,查找过程也是根据key在比较。
但是,如果你是第一次接触skiplist,那么一定会产生一个疑问:节点插入时随机出一个层数,仅仅依靠这样一个简单的随机数操作而构建出来的多层链表结构,能保证 它有一个良好的查找性能吗?为了回答这个疑问,我们需要分析skiplist的统计性能。
在分析之前,我们还需要着重指出的是,执行插入操作时计算随机数的过程,是一个很关键的过程,它对skiplist的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
- 首先,每个节点肯定都有第1层指针(每个节点都在第1层链表里)。
- 如果一个节点有第i层(i>=1)指针(即节点已经在第1层到第i层链表中),那么它有第(i+1)层指针的概率为p。
- 节点最大的层数不允许超过一个最大值,记为MaxLevel。
这个计算随机层数的伪码如下所示:
randomLevel()
level := 1
// random()返回一个[0...1)的随机数
while random() < p and level < MaxLevel do
level := level + 1
return level
randomLevel()的伪码中包含两个参数,一个是p,一个是MaxLevel。在Redis的skiplist实现中,这两个参数的取值为:
p = 1/4
MaxLevel = 32
skiplist的算法性能分析
在这一部分,我们来简单分析一下skiplist的时间复杂度和空间复杂度,以便对于skiplist的性能有一个直观的了解。如果你不是特别偏执于算法的性能分析,那么可以暂时跳过这一小节的内容。
我们先来计算一下每个节点所包含的平均指针数目(概率期望)。节点包含的指针数目,相当于这个算法在空间上的额外开销(overhead),可以用来度量空间复杂度。
根据前面randomLevel()的伪码,我们很容易看出,产生越高的节点层数,概率越低。定量的分析如下:
- 节点层数至少为1。而大于1的节点层数,满足一个概率分布。
- 节点层数恰好等于1的概率为1-p。
- 节点层数大于等于2的概率为p,而节点层数恰好等于2的概率为p(1-p)。
- 节点层数大于等于3的概率为p2,而节点层数恰好等于3的概率为p2(1-p)。
- 节点层数大于等于4的概率为p3,而节点层数恰好等于4的概率为p3(1-p)。
- ……
因此,一个节点的平均层数(也即包含的平均指针数目),计算如下:

现在很容易计算出:
- 当p=1/2时,每个节点所包含的平均指针数目为2;
- 当p=1/4时,每个节点所包含的平均指针数目为1.33。这也是Redis里的skiplist实现在空间上的开销。
接下来,为了分析时间复杂度,我们计算一下skiplist的平均查找长度。查找长度指的是查找路径上跨越的跳数,而查找过程中的比较次数就等于查找长度加1。以前面图中标出的查找23的查找路径为例,从左上角的头结点开始,一直到结点22,查找长度为6。
为了计算查找长度,这里我们需要利用一点小技巧。我们注意到,每个节点插入的时候,它的层数是由随机函数randomLevel()计算出来的,而且随机的计算不依赖于其它节点,每次插入过程都是完全独立的。所以,从统计上来说,一个skiplist结构的形成与节点的插入顺序无关。
这样的话,为了计算查找长度,我们可以将查找过程倒过来看,从右下方第1层上最后到达的那个节点开始,沿着查找路径向左向上回溯,类似于爬楼梯的过程。我们假设当回溯到某个节点的时候,它才被插入,这虽然相当于改变了节点的插入顺序,但从统计上不影响整个skiplist的形成结构。
现在假设我们从一个层数为i的节点x出发,需要向左向上攀爬k层。这时我们有两种可能:
- 如果节点x有第(i+1)层指针,那么我们需要向上走。这种情况概率为p。
- 如果节点x没有第(i+1)层指针,那么我们需要向左走。这种情况概率为(1-p)。
这两种情形如下图所示:

用C(k)表示向上攀爬k个层级所需要走过的平均查找路径长度(概率期望),那么:
C(0)=0
C(k)=(1-p)×(上图中情况b的查找长度) + p×(上图中情况c的查找长度)
代入,得到一个差分方程并化简:
C(k)=(1-p)(C(k)+1) + p(C(k-1)+1)
C(k)=1/p+C(k-1)
C(k)=k/p
这个结果的意思是,我们每爬升1个层级,需要在查找路径上走1/p步。而我们总共需要攀爬的层级数等于整个skiplist的总层数-1。
那么接下来我们需要分析一下当skiplist中有n个节点的时候,它的总层数的概率均值是多少。这个问题直观上比较好理解。根据节点的层数随机算法,容易得出:
- 第1层链表固定有n个节点;
- 第2层链表平均有n*p个节点;
- 第3层链表平均有n*p2个节点;
- …
所以,从第1层到最高层,各层链表的平均节点数是一个指数递减的等比数列。容易推算出,总层数的均值为log1/pn,而最高层的平均节点数为1/p。
综上,粗略来计算的话,平均查找长度约等于:
- C(log1/pn-1)=(log1/pn-1)/p
即,平均时间复杂度为O(log n)。
当然,这里的时间复杂度分析还是比较粗略的。比如,沿着查找路径向左向上回溯的时候,可能先到达左侧头结点,然后沿头结点一路向上;还可能先到达最高层的节点,然后沿着最高层链表一路向左。但这些细节不影响平均时间复杂度的最后结果。另外,这里给出的时间复杂度只是一个概率平均值,但实际上计算一个精细的概率分布也是有可能的。详情还请参见William Pugh的论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》。
skiplist与平衡树、哈希表的比较
- skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
- 在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
- 查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
- 从算法实现难度上来比较,skiplist比平衡树要简单得多。
Redis中的skiplist实现
在这一部分,我们讨论Redis中的skiplist实现。
在Redis中,skiplist被用于实现暴露给外部的一个数据结构:sorted set。准确地说,sorted set底层不仅仅使用了skiplist,还使用了ziplist和dict。这几个数据结构的关系,我们下一章再讨论。现在,我们先花点时间把sorted set的关键命令看一下。这些命令对于Redis里skiplist的实现,有重要的影响。
sorted set的命令举例
sorted set是一个有序的数据集合,对于像类似排行榜这样的应用场景特别适合。
现在我们来看一个例子,用sorted set来存储代数课(algebra)的成绩表。原始数据如下:
- Alice 87.5
- Bob 89.0
- Charles 65.5
- David 78.0
- Emily 93.5
- Fred 87.5
这份数据给出了每位同学的名字和分数。下面我们将这份数据存储到sorted set里面去:

对于上面的这些命令,我们需要的注意的地方包括:
- 前面的6个zadd命令,将6位同学的名字和分数(score)都输入到一个key值为algebra的sorted set里面了。注意Alice和Fred的分数相同,都是87.5分。
- zrevrank命令查询Alice的排名(命令中的rev表示按照倒序排列,也就是从大到小),返回3。排在Alice前面的分别是Emily、Bob、Fred,而排名(rank)从0开始计数,所以Alice的排名是3。注意,其实Alice和Fred的分数相同,这种情况下sorted set会把分数相同的元素,按照字典顺序来排列。按照倒序,Fred排在了Alice的前面。
- zscore命令查询了Charles对应的分数。
- zrevrange命令查询了从大到小排名为0~3的4位同学。
- zrevrangebyscore命令查询了分数在80.0和90.0之间的所有同学,并按分数从大到小排列。
总结一下,sorted set中的每个元素主要表现出3个属性:
- 数据本身(在前面的例子中我们把名字存成了数据)。
- 每个数据对应一个分数(score)。
- 根据分数大小和数据本身的字典排序,每个数据会产生一个排名(rank)。可以按正序或倒序。
Redis中skiplist实现的特殊性
我们简单分析一下前面出现的几个查询命令:
- zrevrank由数据查询它对应的排名,这在前面介绍的skiplist中并不支持。
- zscore由数据查询它对应的分数,这也不是skiplist所支持的。
- zrevrange根据一个排名范围,查询排名在这个范围内的数据。这在前面介绍的skiplist中也不支持。
- zrevrangebyscore根据分数区间查询数据集合,是一个skiplist所支持的典型的范围查找(score相当于key)。
实际上,Redis中sorted set的实现是这样的:
- 当数据较少时,sorted set是由一个ziplist来实现的。
- 当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
这里sorted set的构成我们在下一章还会再详细地讨论。现在我们集中精力来看一下sorted set与skiplist的关系,:
- zscore的查询,不是由skiplist来提供的,而是由那个dict来提供的。
- 为了支持排名(rank),Redis里对skiplist做了扩展,使得根据排名能够快速查到数据,或者根据分数查到数据之后,也同时很容易获得排名。而且,根据排名的查找,时间复杂度也为O(log n)。
- zrevrange的查询,是根据排名查数据,由扩展后的skiplist来提供。
- zrevrank是先在dict中由数据查到分数,再拿分数到skiplist中去查找,查到后也同时获得了排名。
前述的查询过程,也暗示了各个操作的时间复杂度:
- zscore只用查询一个dict,所以时间复杂度为O(1)
- zrevrank, zrevrange, zrevrangebyscore由于要查询skiplist,所以zrevrank的时间复杂度为O(log n),而zrevrange, zrevrangebyscore的时间复杂度为O(log(n)+M),其中M是当前查询返回的元素个数。
总结起来,Redis中的skiplist跟前面介绍的经典的skiplist相比,有如下不同:
- 分数(score)允许重复,即skiplist的key允许重复。这在最开始介绍的经典skiplist中是不允许的。
- 在比较时,不仅比较分数(相当于skiplist的key),还比较数据本身。在Redis的skiplist实现中,数据本身的内容唯一标识这份数据,而不是由key来唯一标识。另外,当多个元素分数相同的时候,还需要根据数据内容来进字典排序。
- 第1层链表不是一个单向链表,而是一个双向链表。这是为了方便以倒序方式获取一个范围内的元素。
- 在skiplist中可以很方便地计算出每个元素的排名(rank)。
skiplist的数据结构定义
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
这段代码出自server.h,我们来简要分析一下:
- 开头定义了两个常量,ZSKIPLIST_MAXLEVEL和ZSKIPLIST_P,分别对应我们前面讲到的skiplist的两个参数:一个是MaxLevel,一个是p。
- zskiplistNode定义了skiplist的节点结构。
- obj字段存放的是节点数据,它的类型是一个string robj。本来一个string robj可能存放的不是sds,而是long型,但zadd命令在将数据插入到skiplist里面之前先进行了解码,所以这里的obj字段里存储的一定是一个sds。有关robj的详情可以参见系列文章的第三篇:《Redis内部数据结构详解(3)——robj》。这样做的目的应该是为了方便在查找的时候对数据进行字典序的比较,而且,skiplist里的数据部分是数字的可能性也比较小。
- score字段是数据对应的分数。
- backward字段是指向链表前一个节点的指针(前向指针)。节点只有1个前向指针,所以只有第1层链表是一个双向链表。
- level[]存放指向各层链表后一个节点的指针(后向指针)。每层对应1个后向指针,用forward字段表示。另外,每个后向指针还对应了一个span值,它表示当前的指针跨越了多少个节点。span用于计算元素排名(rank),这正是前面我们提到的Redis对于skiplist所做的一个扩展。需要注意的是,level[]是一个柔性数组(flexible array member),因此它占用的内存不在zskiplistNode结构里面,而需要插入节点的时候单独为它分配。也正因为如此,skiplist的每个节点所包含的指针数目才是不固定的,我们前面分析过的结论——skiplist每个节点包含的指针数目平均为1/(1-p)——才能有意义。
- zskiplist定义了真正的skiplist结构,它包含:
- 头指针header和尾指针tail。
- 链表长度length,即链表包含的节点总数。注意,新创建的skiplist包含一个空的头指针,这个头指针不包含在length计数中。
- level表示skiplist的总层数,即所有节点层数的最大值。
下图以前面插入的代数课成绩表为例,展示了Redis中一个skiplist的可能结构:
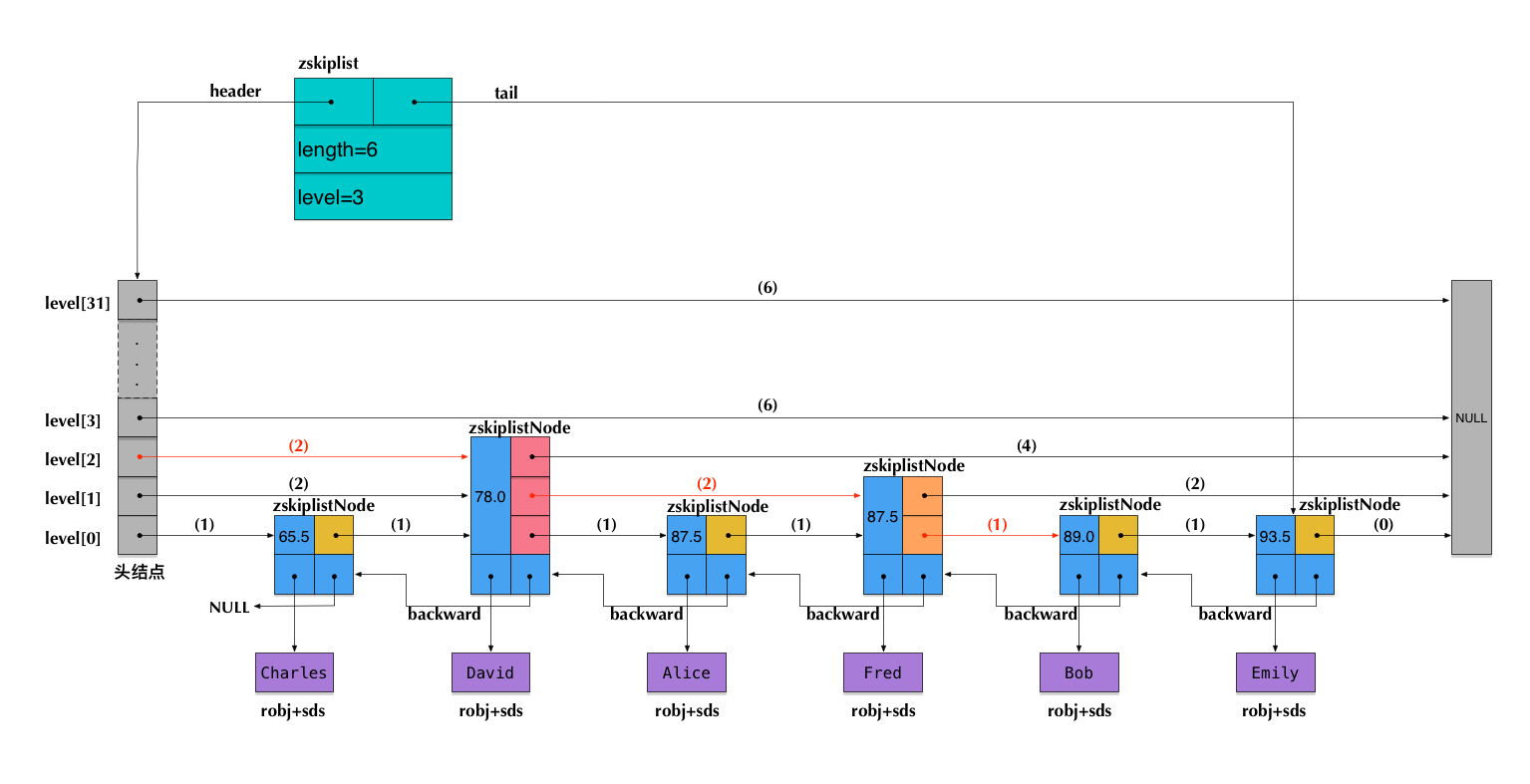
注意:图中前向指针上面括号中的数字,表示对应的span的值。即当前指针跨越了多少个节点,这个计数不包括指针的起点节点,但包括指针的终点节点。
假设我们在这个skiplist中查找score=89.0的元素(即Bob的成绩数据),在查找路径中,我们会跨域图中标红的指针,这些指针上面的span值累加起来,就得到了Bob的排名(2+2+1)-1=4(减1是因为rank值以0起始)。需要注意这里算的是从小到大的排名,而如果要算从大到小的排名,只需要用skip list长度减去查找路径上的span累加值,即6-(2+2+1)=1。
可见,在查找skiplist的过程中,通过累加span值的方式,我们就能很容易算出排名。相反,如果指定排名来查找数据(类似zrange和zrevrange那样),也可以不断累加span并时刻保持累加值不超过指定的排名,通过这种方式就能得到一条O(log n)的查找路径。
Redis中的sorted set
我们前面提到过,Redis中的sorted set,是在skiplist, dict和ziplist基础上构建起来的:
- 当数据较少时,sorted set是由一个ziplist来实现的。
- 当数据多的时候,sorted set是由一个叫zset的数据结构来实现的,这个zset包含一个dict + 一个skiplist。dict用来查询数据到分数(score)的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
在这里我们先来讨论一下前一种情况——基于ziplist实现的sorted set。在本系列前面关于ziplist的文章里,我们介绍过,ziplist就是由很多数据项组成的一大块连续内存。由于sorted set的每一项元素都由数据和score组成,因此,当使用zadd命令插入一个(数据,score)对的时候,底层在相应的ziplist上就插入两个数据项:数据在前,score在后。
ziplist的主要优点是节省内存,但它上面的查找操作只能按顺序查找(可以正序也可以倒序)。因此,sorted set的各个查询操作,就是在ziplist上从前向后(或从后向前)一步步查找,每一步前进两个数据项,跨域一个(数据, score)对。
随着数据的插入,sorted set底层的这个ziplist就可能会转成zset的实现(转换过程详见t_zset.c的zsetConvert)。那么到底插入多少才会转呢?
还记得本文开头提到的两个Redis配置吗?
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
这个配置的意思是说,在如下两个条件之一满足的时候,ziplist会转成zset(具体的触发条件参见t_zset.c中的zaddGenericCommand相关代码):
- 当sorted set中的元素个数,即(数据, score)对的数目超过128的时候,也就是ziplist数据项超过256的时候。
- 当sorted set中插入的任意一个数据的长度超过了64的时候。
最后,zset结构的代码定义如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
Redis为什么用skiplist而不用平衡树?
在前面我们对于skiplist和平衡树、哈希表的比较中,其实已经不难看出Redis里使用skiplist而不用平衡树的原因了。现在我们看看,对于这个问题,R edis的作者 @antirez 是怎么说的:
There are a few reasons:
1) They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
这段话原文出处:
这里从内存占用、对范围查找的支持和实现难易程度这三方面总结的原因,我们在前面其实也都涉及到了。
Redis内部数据结构详解(7)——intset
Redis里面使用intset是为了实现集合(set)这种对外的数据结构。set结构类似于数学上的集合的概念,它包含的元素无序,且不能重复。Redis里的set结构还实现了基础的集合并、交、差的操作。与Redis对外暴露的其它数据结构类似,set的底层实现,随着元素类型是否是整型以及添加的元素的数目多少,而有所变化。概括来讲,当set中添加的元素都是整型且元素数目较少时,set使用intset作为底层数据结构,否则,set使用dict作为底层数据结构。
在本文中我们将大体分成三个部分进行介绍:
- 集中介绍intset数据结构。
- 讨论set是如何在intset和dict基础上构建起来的。
- 集中讨论set的并、交、差的算法实现以及时间复杂度。注意,其中差集的计算在Redis中实现了两种算法。
我们在讨论中还会涉及到一个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
set-max-intset-entries 512
注:本文讨论的代码实现基于Redis源码的3.2分支。
intset数据结构简介
intset顾名思义,是由整数组成的集合。实际上,intset是一个由整数组成的有序集合,从而便于在上面进行二分查找,用于快速地判断一个元素是否属于这个集合。它在内存分配上与ziplist有些类似,是连续的一整块内存空间,而且对于大整数和小整数(按绝对值)采取了不同的编码,尽量对内存的使用进行了优化。
intset的数据结构定义如下(出自intset.h和intset.c):
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
各个字段含义如下:
encoding: 数据编码,表示intset中的每个数据元素用几个字节来存储。它有三种可能的取值:INTSET_ENC_INT16表示每个元素用2个字节存储,INTSET_ENC_INT32表示每个元素用4个字节存储,INTSET_ENC_INT64表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。length: 表示intset中的元素个数。encoding和length两个字段构成了intset的头部(header)。contents: 是一个柔性数组(flexible array member),表示intset的header后面紧跟着数据元素。这个数组的总长度(即总字节数)等于encoding * length。柔性数组在Redis的很多数据结构的定义中都出现过(例如sds, quicklist, skiplist),用于表达一个偏移量。contents需要单独为其分配空间,这部分内存不包含在intset结构当中。
其中需要注意的是,intset可能会随着数据的添加而改变它的数据编码:
- 最开始,新创建的intset使用占内存最小的INTSET_ENC_INT16(值为2)作为数据编码。
- 每添加一个新元素,则根据元素大小决定是否对数据编码进行升级。
下图给出了一个添加数据的具体例子(点击看大图)。
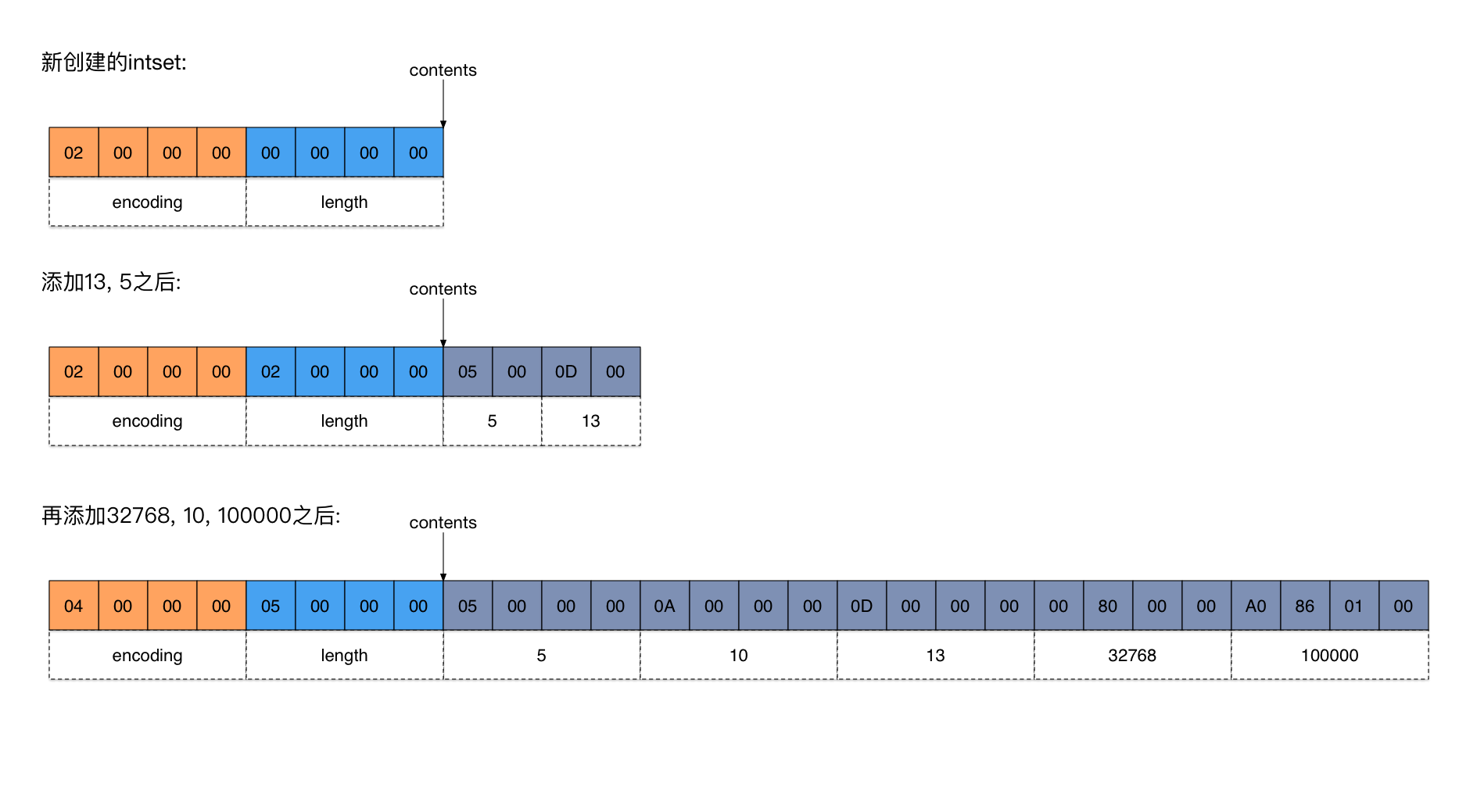
在上图中:
- 新创建的intset只有一个header,总共8个字节。其中
encoding= 2,length= 0。 - 添加13, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以
encoding不变,值还是2。 - 当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此
encoding必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。 - 在添加每个元素的过程中,intset始终保持从小到大有序。
- 与ziplist类似,intset也是按小端(little endian)模式存储的(参见维基百科词条Endianness)。比如,在上图中intset添加完所有数据之后,表示
encoding字段的4个字节应该解释成0x00000004,而第5个数据应该解释成0x000186A0 = 100000。
intset与ziplist相比:
- ziplist可以存储任意二进制串,而intset只能存储整数。
- ziplist是无序的,而intset是从小到大有序的。因此,在ziplist上查找只能遍历,而在intset上可以进行二分查找,性能更高。
- ziplist可以对每个数据项进行不同的变长编码(每个数据项前面都有数据长度字段
len),而intset只能整体使用一个统一的编码(encoding)。
intset的查找和添加操作
要理解intset的一些实现细节,只需要关注intset的两个关键操作基本就可以了:查找(intsetFind)和添加(intsetAdd)元素。
intsetFind的关键代码如下所示(出自intset.c):
uint8_t intsetFind(intset *is, int64_t value) {
uint8_t valenc = _intsetValueEncoding(value);
return valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,NULL);
}
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
/* The value can never be found when the set is empty */
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} else {
/* Check for the case where we know we cannot find the value,
* but do know the insert position. */
if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}
关于以上代码,我们需要注意的地方包括:
intsetFind在指定的intset中查找指定的元素value,找到返回1,没找到返回0。_intsetValueEncoding函数会根据要查找的value落在哪个范围而计算出相应的数据编码(即它应该用几个字节来存储)。- 如果
value所需的数据编码比当前intset的编码要大,则它肯定在当前intset所能存储的数据范围之外(特别大或特别小),所以这时会直接返回0;否则调用intsetSearch执行一个二分查找算法。 intsetSearch在指定的intset中查找指定的元素value,如果找到,则返回1并且将参数pos指向找到的元素位置;如果没找到,则返回0并且将参数pos指向能插入该元素的位置。intsetSearch是对于二分查找算法的一个实现,它大致分为三个部分:- 特殊处理intset为空的情况。
- 特殊处理两个边界情况:当要查找的
value比最后一个元素还要大或者比第一个元素还要小的时候。实际上,这两部分的特殊处理,在二分查找中并不是必须的,但它们在这里提供了特殊情况下快速失败的可能。 - 真正执行二分查找过程。注意:如果最后没找到,插入位置在
min指定的位置。
- 代码中出现的
intrev32ifbe是为了在需要的时候做大小端转换的。前面我们提到过,intset里的数据是按小端(little endian)模式存储的,因此在大端(big endian)机器上运行时,这里的intrev32ifbe会做相应的转换。 - 这个查找算法的总的时间复杂度为O(log n)。
而intsetAdd的关键代码如下所示(出自intset.c):
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
} else {
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}
is = intsetResize(is,intrev32ifbe(is->length)+1);
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
关于以上代码,我们需要注意的地方包括:
intsetAdd在intset中添加新元素value。如果value在添加前已经存在,则不会重复添加,这时参数success被置为0;如果value在原来intset中不存在,则将value插入到适当位置,这时参数success被置为0。- 如果要添加的元素
value所需的数据编码比当前intset的编码要大,那么则调用intsetUpgradeAndAdd将intset的编码进行升级后再插入value。 - 调用
intsetSearch,如果能查到,则不会重复添加。 - 如果没查到,则调用
intsetResize对intset进行内存扩充,使得它能够容纳新添加的元素。因为intset是一块连续空间,因此这个操作会引发内存的realloc(参见http://man.cx/realloc)。这有可能带来一次数据拷贝。同时调用intsetMoveTail将待插入位置后面的元素统一向后移动1个位置,这也涉及到一次数据拷贝。值得注意的是,在intsetMoveTail中是调用memmove完成这次数据拷贝的。memmove保证了在拷贝过程中不会造成数据重叠或覆盖,具体参见http://man.cx/memmove。 intsetUpgradeAndAdd的实现中也会调用intsetResize来完成内存扩充。在进行编码升级时,intsetUpgradeAndAdd的实现会把原来intset中的每个元素取出来,再用新的编码重新写入新的位置。- 注意一下
intsetAdd的返回值,它返回一个新的intset指针。它可能与传入的intset指针is相同,也可能不同。调用方必须用这里返回的新的intset,替换之前传进来的旧的intset变量。类似这种接口使用模式,在Redis的实现代码中是很常见的,比如我们之前在介绍sds和ziplist的时候都碰到过类似的情况。 - 显然,这个
intsetAdd算法总的时间复杂度为O(n)。
Redis的set
为了更好地理解Redis对外暴露的set数据结构,我们先看一下set的一些关键的命令。下面是一些命令举例:
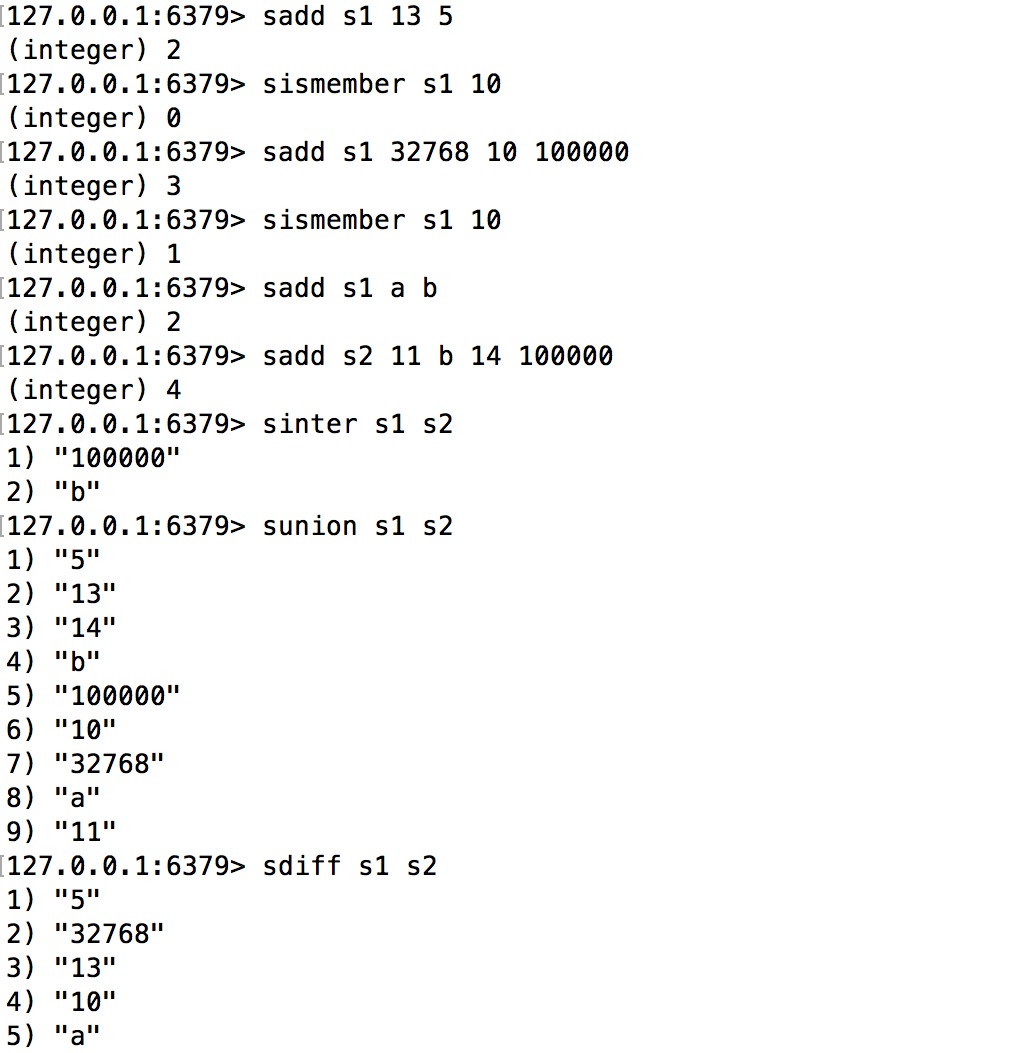
上面这些命令的含义:
sadd用于分别向集合s1和s2中添加元素。添加的元素既有数字,也有非数字(”a”和”b”)。sismember用于判断指定的元素是否在集合内存在。sinter,sunion和sdiff分别用于计算集合的交集、并集和差集。
我们前面提到过,set的底层实现,随着元素类型是否是整型以及添加的元素的数目多少,而有所变化。例如,具体到上述命令的执行过程中,集合s1的底层数据结构会
发生如下变化:
- 在开始执行完
sadd s1 13 5之后,由于添加的都是比较小的整数,所以s1底层是一个intset,其数据编码encoding= 2。 - 在执行完
sadd s1 32768 10 100000之后,s1底层仍然是一个intset,但其数据编码encoding从2升级到了4。 - 在执行完
sadd s1 a b之后,由于添加的元素不再是数字,s1底层的实现会转成一个dict。
我们知道,dict是一个用于维护key和value映射关系的数据结构,那么当set底层用dict表示的时候,它的key和value分别是什么呢?实际上,ke y就是要添加的集合元素,而value是NULL。
除了前面提到的由于添加非数字元素造成集合底层由intset转成dict之外,还有两种情况可能造成这种转换:
- 添加了一个数字,但它无法用64bit的有符号数来表达。intset能够表达的最大的整数范围为-264~264-1,因此,如果添加的数字超出了这个范围,这也会导致intset转成dict。
- 添加的集合元素个数超过了
set-max-intset-entries配置的值的时候,也会导致intset转成dict(具体的触发条件参见t_set.c中的setTypeAdd相关代码)。
对于小集合使用intset来存储,主要的原因是节省内存。特别是当存储的元素个数较少的时候,dict所带来的内存开销要大得多(包含两个哈希表、链表指针以及大量的其它元数据)。所以,当存储大量的小集合而且集合元素都是数字的时候,用intset能节省下一笔可观的内存空间。
实际上,从时间复杂度上比较,intset的平均情况是没有dict性能高的。以查找为例,intset是O(log n)的,而dict可以认为是O(1)的。但是,由于使用intset的时候集合元素个数比较少,所以这个影响不大。
Redis set的并、交、差算法
Redis set的并、交、差算法的实现代码,在t_set.c中。其中计算交集调用的是sinterGenericCommand,计算并集和差集调用的是sunionDiffGenericCommand。它们都能同时对多个(可以多于2个)集合进行运算。当对多个集合进行差集运算时,它表达的含义是:用第一个集合与第二个集合做差集,所得结果再与第三个集合做差集,依次向后类推。
我们在这里简要介绍一下三个算法的实现思路。
交集
计算交集的过程大概可以分为三部分:
- 检查各个集合,对于不存在的集合当做空集来处理。一旦出现空集,则不用继续计算了,最终的交集就是空集。
- 对各个集合按照元素个数由少到多进行排序。这个排序有利于后面计算的时候从最小的集合开始,需要处理的元素个数较少。
- 对排序后第一个集合(也就是最小集合)进行遍历,对于它的每一个元素,依次在后面的所有集合中进行查找。只有在所有集合中都能找到的元素,才加入到最后的结果集合中。
需要注意的是,上述第3步在集合中进行查找,对于intset和dict的存储来说时间复杂度分别是O(log n)和O(1)。但由于只有小集合才使用intset,所以可以粗略地认为intset的查找也是常数时间复杂度的。因此,如Redis官方文档上所说(http://redis.io/commands/sinter),sinter命令的时间复杂度为:
O(N*M) worst case where N is the cardinality of the smallest set and M is the number of sets.
并集
计算并集最简单,只需要遍历所有集合,将每一个元素都添加到最后的结果集合中。向集合中添加元素会自动去重。
由于要遍历所有集合的每个元素,所以Redis官方文档给出的sunion命令的时间复杂度为(http://redis.io/commands/sunion):
O(N) where N is the total number of elements in all given sets.
注意,这里同前面讨论交集计算一样,将元素插入到结果集合的过程,忽略intset的情况,认为时间复杂度为O(1)。
差集
计算差集有两种可能的算法,它们的时间复杂度有所区别。
第一种算法:
- 对第一个集合进行遍历,对于它的每一个元素,依次在后面的所有集合中进行查找。只有在所有集合中都找不到的元素,才加入到最后的结果集合中。
这种算法的时间复杂度为O(N*M),其中N是第一个集合的元素个数,M是集合数目。
第二种算法:
- 将第一个集合的所有元素都加入到一个中间集合中。
- 遍历后面所有的集合,对于碰到的每一个元素,从中间集合中删掉它。
- 最后中间集合剩下的元素就构成了差集。
这种算法的时间复杂度为O(N),其中N是所有集合的元素个数总和。
在计算差集的开始部分,会先分别估算一下两种算法预期的时间复杂度,然后选择复杂度低的算法来进行运算。还有两点需要注意:
- 在一定程度上优先选择第一种算法,因为它涉及到的操作比较少,只用添加,而第二种算法要先添加再删除。
- 如果选择了第一种算法,那么在执行该算法之前,Redis的实现中对于第二个集合之后的所有集合,按照元素个数由多到少进行了排序。这个排序有利于以更大的概率查找到元素,从而更快地结束查找。
对于sdiff的时间复杂度,Redis官方文档(http://redis.io/commands/sdiff)只给出了第二种算法的结果,是不准确的。
系列下一篇待续,敬请期待。