LevelDB源码剖析1
原文出处:开篇:初学乍练——LevelDB初识
开篇:初学乍练——LevelDB初识
LevelDB是一个键值对数据库,是一个持久化的有序的Map,由Google传奇工程师Jeff Dean和Sanjay Ghemawat开发并开源。LevelDB实际上不是一个功能完备的数据库,而只是一个数据库函数库,提供了接口来操作数据库。LevelDB的代码只有1万多行,精致优雅,可读性高,是LSM Tree的一种实现方式,值得学习。
LevelDB非常简单,实际工程中使用不多,一般会选择RocksDB,它对LevelDB进行了改进,比LevelDB更加强大,比如TiDB就使用了RocksDB作为了底层存储引擎。但是LevelDB技术架构更加简单清晰易于理解,非常适合学习使用。
本系列将介绍LevelDB的内部实现,包括源码分析、工作原理,通过这个系列的学习,可以了解LSM Tree的一些概念,一种实现方式,了解LevelDB的工作原理。
本系列分为4个部分:
- 概述部分:介绍LevelDB有哪些功能,基本工作原理,编译安装等;
- 基础部分:介绍LevelDB用到了哪些基础组件,这些组件的实现方式;
- 存储部分:介绍LevelDB存储数据相关,包括SSTable、MemTable、WAL和Iterator等,重点阐述数据的存储方式;
- 数据库部分:介绍数据插入、删除和更新接口的实现,以及版本管理和Compaction的实现。
LevelDB的特点
作为一个函数库,LevelDB有以下特点:
- 键和值都是任意的字节数组;
- 数据以键的顺序存储;
- 可以使用定制的比较器定义排序的方式;
- 基本操作是
Put(key,value)、Get(key)、Delete(key); - 一个原子的Batch中可以做多个改变;
- 支持Snapshot,用户可以建立一个一致性的视图;
- 可以正向和反向迭代;
- 支持snappy压缩数据;
- 操作系统相关操作被抽象,跨平台时可以定制这些接口;
- 同一时间只能由一个进程访问数据库,但是支持多线程访问。
编译安装函数库
要使用LevelDB,必须先要编译安装函数库。LevelDB使用了cmake,需要安装cmake,可以根据需要,安装snappy、crc32c和tcmalloc。
通过执行以下几个步骤,就可以安装函数库了:
mkdir -p build && cd build
cmake -DCMAKE_BUILD_TYPE=Release .. && cmake --build .
make install
写个测试:
// hello.cc
#include <assert.h>
#include <string.h>
#include <leveldb/db.h>
#include <iostream>
using namespace leveldb;
int main(){
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
// 打开一个数据库,不存在就创建
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
assert(status.ok());
// 插入一个键值对
status = db->Put(leveldb::WriteOptions(), "hello", "LevelDB");
assert(status.ok());
// 读取键值对
std::string value;
status = db->Get(leveldb::ReadOptions(), "hello", &value);
assert(status.ok());
std::cout << value << std::endl;
delete db;
return 0;
}
编译执行:
g++ hello.cc -o hello -L. -I./include -lpthread -lleveldb
./hello
用Python来操作LevelDB
LevelDB是一个C++函数库,测试的时候,需要使用C++编码读取和写入,非常不方便。我们使用一般的数据库的时候,都有shell来操作数据库。好在有Python库可以用来操作LevelDB,达到和shell相同的效果,可以交互式地使用LevelDB。
我们使用plyvel,可以使用pip来安装。
>>> import plyvel
>>> db = plyvel.DB('/tmp/testdb/', create_if_missing=True)
>>> db.put(b'key', b'value')
>>> db.get(b'key')
'value'
这样可以像使用其它数据库一样,交互式地使用LevelDB,非常方便。
项目结构
项目根目录下面有几个主要的目录:
include: 函数库的头文件
port: 可移植性相关的功能
util: 项目用到的一些功能函数
table: SSTable的实现
db: 数据库实现,版本管理,Compaction,WAL和MemTable实现
LevelDB作为函数库,对外提供的接口文件及功能如下:
cache.h: 缓存接口,提供了默认的LRU缓存,也可以自己实现缓存
comparator.h: 定以数据库比较器的接口,用来比较键,可以使用默认的基于字节的比较,可以定义自己的比较器
dumpfile.h: 以可读文本形式导出一个文件,调试使用
export.h: 可移植性相关
iterator.h: 迭代器接口
slice.h: 实现一个字符串,存储指针和长度,指向字符串
table_builder.h: 构造一个SSTable
write_batch.h: 实现批量写入的接口
c.h: 实现C语言相关的接口
db.h: 操作数据库的主要接口
env.h: 定义操作系统相关的功能,如读写文件之类的
filter_policy.h: 定义布隆过滤器接口
options.h: 配置选项
status.h: 定义数据库操作的返回状态
小结
这一篇我们简单介绍了LevelDB的特点、编译方式、使用方式和项目结构。
项目结构非常清晰,基本可以望文生义,大家可以先翻翻源代码目录熟悉一下项目的布局以及每个文件的用处,方便以后快速找到源代码。
下一节将会介绍LevelDB的功能特性。
使用:授人以渔——LevelDB的功能特性
本篇将全面介绍LevelDB的功能特性,我们将用原生的C++描述接口,也可以使用plyvel库来交互式的测试LevelDB。
打开数据库
LevelDB每一个数据库有一个name,对应一个目录,所有的数据库文件都在这个目录里。通过Open可以打开或者新建一个数据库,得到数据库的引用,通过这个引用来操作数据库。
可以这样打开一个数据库:
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
name指定数据库目录,options指定了打开数据库的选项,db获取了数据库的引用。这里使用了create_if_missing选项,当数据库不存在时会创建数据库。
关闭
只需要delete数据库实例即可:
delete db
基础API
LevelDB的基础API有三个,分别是Get、Put和Delete,表示查询一个键、插入一个键和删除一个键。LevelDB没有更新操作,因为更新就是简单地插入一个Kv,会覆盖之前的值。
db->Put(leveldb::WriteOptions(), "hello", "LevelDB");
std::string value;
db->Get(leveldb::ReadOptions(), "hello", &value);
db->Delete(leveldb::WriteOptions(), "hello");
同步写
数据库系统经常要抉择的一个问题:性能还是可靠性。如果每次写入,都调用类似于sync的操作,能保证写入的数据不会丢失,但是这是一个耗时的操作,会大大地降低吞吐量。如果不使用同步写的话,虽然吞吐量会很高,但是系统宕机可能会丢数据。
这就需要根据自己的场景进行抉择了。LevelDB默认不使用同步写,将数据write后,不调用sync就返回了,数据很有可能还在缓冲区里。可以手动开启同步写:
leveldb::WriteOptions options;
options.sync = true;
leveldb::DB* db;
db->Put(options, "hello", "LevelDB");
原子更新
有时候需要一些更新同时生效,也就是要支持多个操作的原子性。比如写key1,再写入key2,如果在写入key1时宕机了,就没有key2了,这时候可以使用原子更新:
leveldb::WriteBatch batch;
batch.Delete(key1);
batch.Put(key2, value);
s = db->Write(leveldb::WriteOptions(), &batch);
可以把Delete和Put加入到一个WriteBatch中,一次性写入数据库。
原子更新除了提供原子性外,还可以提高性能,因为可以将多个操作批量写入。
并发
当一个进程打开一个LevelDB数据库时,会获取这个数据库的一个文件锁,其它进程就没法获取这个文件锁了。所以一个LevelDB数据库只支持一个进程同时访问,但是这一个进程里面可以同时有多个线程并发访问。对于leveldb::DB里的很多方法,都是线程安全的,在这些方法内都有加锁的步骤。但是对于其它的一些对象,比如WriteBatch,如果多线程并发访问,需要自己同步。
迭代器
LevelDB里大量使用了迭代器,可以对Data Block、SSTable、MemTable和整个数据库进行迭代。
比如可以迭代整个数据库:
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid(); it->Next()) {
cout << it->key().ToString() << ": " << it->value().ToString() << endl;
}
或者迭代[start, limit)这个范围:
for (it->Seek(start);
it->Valid() && it->key().ToString() < limit;
it->Next()) {
...
}
比较器
LevelDB实际上是一个SortedMap,需要定义键之间比较的规则。前面使用了默认的比较规则,也就是基于字节串的比较。也可以提供自己的比较规则:
CaseInsensitiveComparator cmp;
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
options.comparator = &cmp;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
这里定义了一个不区分大小写的比较规则,然后打开数据库。打开一个已存在的数据库时的比较规则需要和创建时的比较规则相同或者兼容,这个很好理解,如果两次不兼容,那么排序对于第二次就是不对了。LevelDB新建数据库时,会向MANIFEST写入一个比较器的名称,下次打开时会检查名称是否相同,来判断兼容性。
Snapshot
LevelDB支持快照功能。快照是一个一致性视图,当创建一个快照时,就给那个时刻的数据库状态打了个快照,以后的更新插入删除在这个快照下是不可见的,类似于MVCC的功能。
leveldb::ReadOptions options;
options.snapshot = db->GetSnapshot();
... 对db做一些修改 ...
leveldb::Iterator* iter = db->NewIterator(options);
... 使用的是还是快照创建的时候的状态 ...
delete iter;
db->ReleaseSnapshot(options.snapshot);
注意快照不再使用时,需要马上释放,防止不需要的数据长久被占用,无法清理。
数据块
LevelDB将相邻的数据存储到一个Data Block里,多个Data Block组成一个SSTable。LevelDB里压缩、读取和缓存的单位都是Data Block。默认的块大小是4K,块越大,顺序读效率越高,块越小,随机读效率越高。
leveldb::Options options;
options.block_size = 8192;
leveldb::DB* db;
leveldb::DB::Open(options, name, &db)
压缩
压缩是以CPU时间换取IO时间的一种方式。压缩以后,数据变小,磁盘IO就变小了,而LevelDB采用的snappy压缩速度很快,CPU占用不多。默认情况下,压缩是开启的,很少有情况不需要开启压缩。
leveldb::Options options;
options.compression = leveldb::kNoCompression;
leveldb::DB* db;
leveldb::DB::Open(options, name, &db)
缓存
SSTable里的Data Block要被访问时,需要先从磁盘读取出来,然后解压缩。LevelDB提供了缓存,可以缓存解压后的Data Block,减少磁盘IO。
LevelDB提供了一个LRU Cache,给缓存设置一定的空间大小,并且缓存最近使用的Data Block。也可以提供自己的缓存策略,只需要实现Cache接口就行。LevelDB默认情况下使用了一个8MB的LRU Cache。
leveldb::Options options;
options.block_cache = leveldb::NewLRUCache(100 * 1048576); // 100MB cache
leveldb::DB* db;
leveldb::DB::Open(options, name, &db);
当迭代整个数据库时,会把所有的热数据都淘汰出缓存,这时候可以选择迭代的时候,不将数据加入到缓存中:
leveldb::ReadOptions options;
options.fill_cache = false;
leveldb::Iterator* it = db->NewIterator(options);
for (it->SeekToFirst(); it->Valid(); it->Next()) {
...
}
布隆过滤器
除了缓存可以提高读取的效率,布隆过滤器也可以提高读取的效率。当需要读取一个键时,就算这个键不在一个Data Block,依然需要读出这个Data Block,才知道这个键是否存在。有了布隆过滤器,可以先读取布隆过滤器,如果告诉说这个键不存在,就不再需要读取这个Data Block了。
leveldb::Options options;
options.filter_policy = NewBloomFilterPolicy(10);
leveldb::DB* db;
leveldb::DB::Open(options, "/tmp/testdb", &db);
NewBloomFilterPolicy参数10表示,每个键将使用10bit的空间构造布隆过滤器。10bit的情况下,如果布隆过滤器说一个键不存在,那么这个键一定不存在,如果说这个键存在的话,99%的概率是存在的,1%的概率是不存在的,假阳率是1%。10是个比较好的参数,这时布隆过滤器不需要占据太多空间,但是假阳率也比较低,继续提高对假阳率的改善并不显著。
布隆过滤器的数据是要写入SSTable的,当一个SSTable打开后,布隆过滤器的数据是常驻内存的,直到SSTable被关闭。布隆过滤器也是一种空间换时间的方式。
数据校验
可以在打开一个数据库时做校验:
leveldb::Options options;
options.paranoid_checks = true;
leveldb::DB* db;
leveldb::DB::Open(options, "/tmp/testdb", &db);
也可以在读取数据时做校验:
leveldb::ReadOptions options;
options.verify_checksums = true;
std::string value;
小结
这一篇详细介绍了LevelDB的能力,也就是LevelDB可以做什么。这样就可以在选型时确定LevelDB是否合适,LevelDB可以提供哪些功能供我们使用。
了解了What以后,将了解Why,下一节将介绍LevelDB的工作原理。
原理:知其然知其所以然——LevelDB基本原理
我们经常会听说LSM Tree适合写多的场景,但是这到底是为什么呢? LevelDB作为LSM Tree的一种实现方式,可以帮助理解LSM Tree。LevelDB实现了一个高性能的、持久化的、有序的Kv数据库接口。
架构
LevelDB按照存储来分,可以分为三个组件:
- MemTable;
- SSTable;
- WAL。
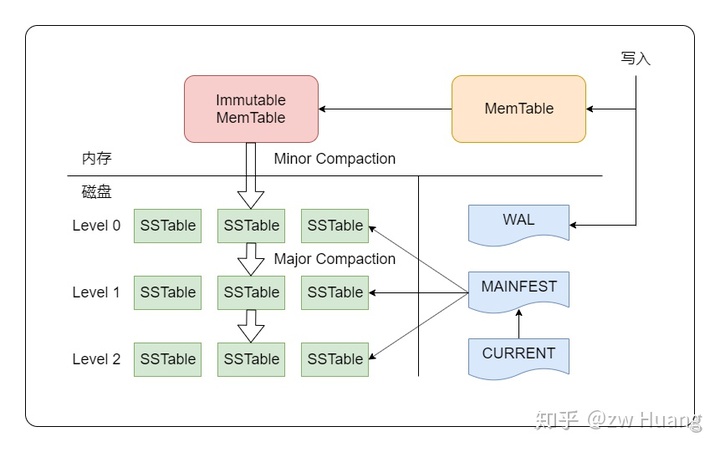
MANIFEST是用来管理SSTable的,保存了SSTable的元信息。
MemTable
MemTable是一个内存数据结构,简单说它就是一个SortedMap:
- MemTable是一个
Map,提供了Get接口,也就是可以快速地根据键查找到值,也可以使用Put接口插入Kv; - MemTable是Sorted,也就是里面存储的键都是有序的,可以按照键的顺序迭代
Map,或者做范围查询。
有了MemTable提供的Get和Put,就有了一个简单的内存Kv数据库,可以实现Kv的查询,插入和范围查询。
因为MemTable是内存数据结构,不需要磁盘IO,所以读写的速度非常快,所以就达到了场景需求:高效的写性能。然而这会有个问题,当数据库实例崩溃、宕机或者停机维护的时候,存储的数据就会丢失,这时候需要持久化数据。
WAL
为了不丢失数据,需要持久化的功能。把数据持久化到磁盘上,最常用的技术就是日志技术,也就是当修改数据时,先把对数据的修改写到磁盘上,然后在MemTable里做修改。因为日志记录了每个操作,只要对日志进行重放便可以恢复MemTable,这样就做到了数据库实例崩溃、宕机或者停机维护的时候数据不丢失。
这种日志技术在数据库里面很常用(Redis里的Aof,Innodb里的Redo Log都是这样的技术),一般称为WAL (Write Ahead Log),正如名字一样,就是在写入前先写入日志的意思。
因为日志的写入都是Append的,也就是顺序写,所以写磁盘也是顺序写,虽然磁盘的随机写效率比较低,但是顺序写效率还是很高的,所以就算加入了日志,写效率还是很高,依然可以满足写多的场景。
另外可以通过控制日志写同步的策略在性能和可靠性之间做折中:
- 每次写入都做一次
sync,可靠性最高,不会丢数据,但是性能最低; - 每次写入,但是不
sync,数据库崩溃不会丢数据,但是机器崩溃会丢数据,性能高; - 每次写入,不
sync,但是每1s做一次sync,数据库崩溃不会丢数据,但是机器崩溃丢最多1s的数据,性能较高。
有了MemTable和WAL,就有了一个功能比较完备的数据库了,类似于一个简化版的Redis。然而这又引入了新的问题:
- 如果日志量很大,每次重启数据库时,恢复的时间非常长;
- 内存的容量是有限的,所以当数据量太大,MemTable的大小超过内存容量时,就没法写入数据了。
这时候不仅仅需要将日志写入到磁盘,也需要定时将MemTable的镜像写入磁盘,并且清空MemTable。
SSTable
将MemTable的镜像写入到磁盘有一个要求:需要具有快速地在磁盘上查询一个键的功能。
最先想到的就是B+ Tree,这是一种古老的磁盘数据结构,现在很多数据库依然在采用,具有很好的读取性能。B+ Tree其实是一种多级索引,设计成这样是为了支持快速读取,同时也支持更新,但是B+ Tree更新的开销会比较大。如果将一个MemTable写入磁盘的方式是将数据原地更新磁盘上已存在的镜像,那么其实就是使用了类似于B+ Tree,这样会有很大的更新开销。所以LevelDB不更新磁盘镜像,每次都将MemTable写入一个新镜像。
对于不更新的磁盘数据结构,并不需要使用B+ Tree。LevelDB使用了SSTable(Sorted String Table),意思是数据按照键的顺序存储在磁盘上。键是有序的,查找键可以采用二分搜索。但是磁盘的二分搜索会读取多个磁盘块。这时候只需要给每个磁盘块一个索引,告诉这个磁盘块里面存储键的范围,那么在查找时,可以先通过对索引进行二分搜索找到键所在的磁盘块,只需要读取这个磁盘块,便可以找到这个键。索引是一个稀疏索引,比较小,可以放在内存中缓存。
定时将MemTable的镜像写入磁盘中的一个SSTable,数据就会分为两个部分:一部分是内存中的MemTable里的数据,一部分是磁盘中SSTable的数据。当写入数据时,还是写入MemTable和日志,而后台线程定时将MemTable的镜像写入磁盘的SSTable中,如果很好的控制后台线程的写入频率,或者SSTable和日志不在同一个磁盘,那么写入依然是比较符合顺序写的,可以有很高的写性能。写入SSTable后,之前的日志就可以被淘汰了,因为之前的数据已经持久化到磁盘上了。这就同时解决了上面的两个问题,恢复时间和数据库容量。
使用定期写入MemTable镜像的方式,解决了恢复和数据库容量的问题,并且数据库具有持久化的功能,在满足这些条件的情况下,数据库依然有很高的写性能,符合LSM Tree的写多的场景。
但是,这又引入了一个新的问题:读变慢了。以前读的时候,只需要读取MemTable,现在还需要读取SSTable。随着SSTable不断地写入,SSTable会越来越多,当查找一个键时,可能需要读取多个SSTable,这就涉及了多次随机读,读取效率会很低。
如果把多个SSTable合并成一个大的SSTable,那么查找时,就不需要读取多个小的SSTable,而只需要读取一个大的SSTable,磁盘IO就会减少。
Compaction
将多个小SSTable合并成一个大SSTable,可以解决查找的效率问题。但是,如果不断地有新的小SSTable进来,这些小SSTable都需要和这个大的SSTable进行合并,不管多大的SSTable来合并,都需要读取所有的磁盘数据,并且写入所有的磁盘数据。
大的SSTable是按键顺序存储的,可以将大SSTable进行分割,分割成多个小SSTable,每个SSTable都包含一段键的范围,而每个SSTable键的范围是不重复的,并且是按顺序排列的。这时候物理上存在多个SSTable文件,但是逻辑上依然是有一个大的SSTable。在查找的时候只需要多做一步,根据每个小的SSTable包含键的范围,可以做一个二分搜索,就可以找到实际的键在哪个小SSTable文件里。这样依然只需要读取一个SSTable,但是却使用了多个小文件代替一个大文件。这样的好处就是当有新SSTable需要合并到这个逻辑上的大SSTable时,只需要找到和新SSTable的键范围有重合的小SSTable的物理文件进行合并,这样就可以降低合并需要读取的数据量。
这样磁盘文件实际上分为两部分:一部分是MemTable直接写入的SSTable,另一部分是逻辑上的大SSTable。这实际上就是LevelDB里面的Level 0和Level 1。Level 0文件的键范围可能有重叠,而Level 1不会有重叠。而读取的时候,要读取Level 0和Level 1的数据,如果限制Level 0的文件数量,磁盘的读IO依然可以控制在一个常数范围内。
随着数据越写越多,Level 1越来越大,此时就算Level 0的SSTable很小,依然可能会和Level 1很多的SSTable文件重合,那么读写量依然很大。
这时候还需要改进,需要控制Level 1里所有文件的大小,那么多出的文件该怎么办呢?可以将它们再推到更高的一层Level 2中。Level 2里总文件大小设置为Level 1的10倍,在生成Level 1的SSTable时,控制大小使得最多与10个Level 2的SSTable重叠。如果需要将Level 1的一个SSTable合并到Level 2,需要读取的SSTable的数据量依然是一个常数级,是可控的。如果Level 2满了,可以将SSTable继续推向Level 3。因为每一Level的大小都是指数增长的,所以不需要几层,就可以放大量数据了。
这就是LevelDB名字的由来了,SSTable是分层存储的,Level 0的SSTable之间是重叠的,而Level 0以上的SSTable是有序不重叠的。SSTable在各Level之间移动的过程叫做Compaction,意思是让文件变得更加紧凑,易于查询。Level 0的SSTable会Compaction到Level 1,而Level 1的SSTable会Compaction到Level 2,随着Level的增大,每一层的文件总大小会以10倍增大,这样不但可以有大量的存储空间,而且每一次Compaction涉及的SSTable的数量都是可控的。Compaction实际上就是对输入的多个SSTable进行多路归并的过程。
随着Level的增多,读取更复杂了。要先读取MemTable,再读取Level 0的文件,Level 0可能有多个文件的键范围包括这个查找键,还需要读取Level 0以上的文件,每一Level最多有一个文件的键范围包括查找键。不过Level的数量有限,Level 0的文件数量也有限,所以需要读取的SSTable的数量依然是常数级,配合缓存、布隆过滤器等优化技术,可以提高读的性能。这是在读取性能和后台操作性能之间的折中,为了让写操作成为顺序写,而做的牺牲。
磁盘上有多个SSTable,需要知道每个SSTable属于哪一层,每一个SSTable的键范围,这些信息都存储在内存中。但是如果数据库重启了,就丢失了这些元信息,所以需要将它们持久化到磁盘。
MANIFEST
对于当前数据有哪些SSTable,这些SSTable属于哪一层,每一个SSTable的键范围和文件大小等信息,需要持久化到磁盘上,下一次打开数据库的时候,就可以从磁盘上读取到这些元数据,恢复内存里的数据结构,这个持久化数据就存储在MANIFEST文件中。
随着Compaction的进行, 元数据会改变,所以每次还需要将改变的元数据写到MANIFEST中。恢复元数据时,使用初始的元数据和各个改变恢复出最终的元数据。但是如果改变太多,MANIFEST太大,恢复就会太耗时,这时可以将当前的元数据写入到有一个新的MANIFEST中,而舍弃旧的MANIFEST。而CURRENT文件则存储了当前使用的MANIFEST文件是哪一个,写完MANIFEST后, 需要将CURRENT指向新的MANIFEST。
小结
以上便是LevelDB的整体架构和工作原理了,我们从零开始逐步添加部件,最终达到目标。LevelDB的LSM Tree的实现是对原始的LSM Tree实现的一种改进,实际上现在的结构中并没有Tree。通过以上的学习,可以大概地掌握LevelDB有哪些部件,是怎么实现的,读写是怎么操作的,为什么适合写多的场景。
LevelDB提高写性能方式主要就是和读性能进行折中,读性能的些许降低,大大提高了写性能。
有了这三篇的热身,接下来我们将深入LevelDB实现的细节。
原文出处:基础1:中庸之道——arena内存管理
基础1:中庸之道——arena内存管理
数据库内存分配非常重要,尤其是插入一个键值对时,需要分配内存给这个键值对。如果直接使用malloc/free或者new/delete碰到很小的键值对时,每个调用平均的开销比较大,而且会产生很多内存碎片。
LevelDB只有一处使用了自己的内存管理,就是MemTable,MemTable使用一个Skiplist存储最新插入的键值对。LevelDB为每个MemTable都绑定了一个Arena来管理内存,其它地方则直接使用malloc/free,因为这些地方都使用了比较大块的内存或者新建销毁不频繁。
设计思想
内存分配经常采用的一种方式,就是首先使用new预分配一块比较大的内存,需要使用小块内存时,从这块大内存里面继续分配,这时候分配可能只是移动指针或者更新变量的事情了,非常高效。
arena内存管理就使用了这种思想,解决了小块内存频繁调用new的开销和内存碎片的问题,但是却可能浪费一些内存。
arena的内存分配如下图所示:
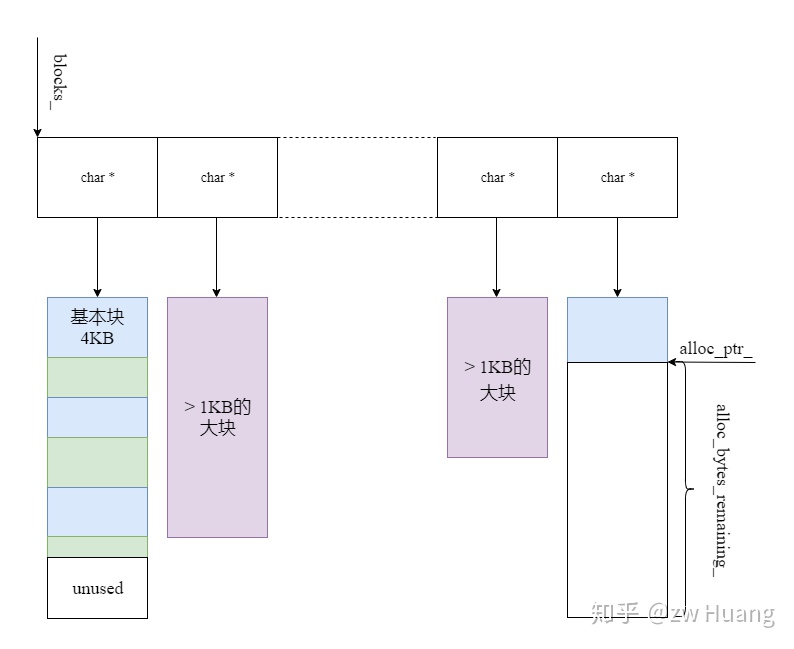
- 使用一个
char *的vector保存每个块; - 当需要分配一块内存时,查看
alloc_bytes_remaining_(就是当前块还有多少内存未分配)是否大于等于所需内存; - 如果大于等于,直接分配,这时候只需要移动指针即可;
- 如果小于,要分两种情况,看所需要分配的内存是否大于1KB;
- 如果大于1KB,直接分配相应大小的块,并且插入到
vector中; - 如果小于等于1KB,则分配一个4KB的块,插入到
vector中,从4KB的块上分配相应的内存; - 上一个块里没有分配的内存就浪费了。
arena使用一个Arena类来定义,将数据存储在std::vector<char*> blocks_变量里,依次存储,每个数组项存储一个内存块,使用alloc_ptr_和alloc_bytes_remaining_来跟踪当前块分配的状态。
// util/arena.h util/arena.cc
static const int kBlockSize = 4096;
// 首先是Arena的定义
class Arena {
private:
...
char* alloc_ptr_; // 指向当前块第一个free的字节
size_t alloc_bytes_remaining_; // 当前块还有多少字节free的内存
std::vector<char*> blocks_; // 用new分配的内存块的数组
...
};
// 分配内存的函数
inline char* Arena::Allocate(size_t bytes) {
// 如果当前块剩余的内存足够,更新free指针,返回内存指针
if (bytes <= alloc_bytes_remaining_) {
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
// 否则退化的方式分配
return AllocateFallback(bytes);
}
char* Arena::AllocateFallback(size_t bytes) {
// 如果分配的内存大于1KB,直接分配一个块
if (bytes > kBlockSize / 4) {
char* result = AllocateNewBlock(bytes);
return result;
}
// 如果内存小于等于1KB,分配一个4KB的块,更新指针
alloc_ptr_ = AllocateNewBlock(kBlockSize);
alloc_bytes_remaining_ = kBlockSize;
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
这样的思路对于大块的内存会直接调用new分配,对于小块的内存会在大块内存的基础上分配。如果需要分配的内存刚好大于当前块剩余的大小,那么当前块剩余的内存空间就浪费了。这里采用简单化的处理,牺牲了内存使用率。大块的内存直接分配一个块,而不是分配一个4KB的块,可以减少内存的浪费。
对于释放内存,arena不支持单独释放某个块,而是只能销毁整个arena。这是和arena的使用场景有关的,arena存储的是内存中的键值对,对于Level DB来说,只有插入操作,没有实际的删除操作,所以不需要释放一块内存。而当一个arena里的数据dump到SSTable后,只需要释放arena里所有的内存。
参考源码
util/arena.h util/arena.cc:arena实现代码
小结
LevelDB的内存分配策略非常简单,这和使用场景有关的。如果Kv数量很多,而且比较小的情况下,采用这种分配方式会非常高效,内存的浪费也可以控制在相对理想的水平,这些浪费的内存在MemTable写满后,就会释放了。
原文出处:基础2:动静结合——编码
基础2:动静结合——编码
编码说的是内存里的整数和字符串是怎么存储到磁盘上的。对于整数,主要是有Big Endian 和Little Endian的区分,还有变长整数和定长整数的区别。
对于LevelDB,有以下几点:
- 整数分为32位整数和64位整数;
- 整数分为定长整数和变长整数;
- 整数采用Little Endian的方式存储;
- 字符串采用长度前缀编码的方式存储,所以字符串里面可以出现任何字符,包括
\0。
存储方式
定长整数
定长整数的存储非常简单,比如一个32位整数,把低8位的字节编码到第一个字节位置,低9-16位的字节放在第二个字节位置,以此类推。
变长整数
一些小的整数,比如可能频繁使用100以内的整数(比如字符串的长度编码),如果使用定长编码,至少需要4个字节,容易造成空间的浪费,所以LevelDB里面有一种变长整数的编码方式。对于32位整数使用1-5个字节进行编码,而对于64位整数使用1-10个字节进行编码。
这种编码方式的原理就是只使用一个字节的低7位存储数据,而高位用来做标识,高位为1的时候表示需要继续读取下一个字节,高位为0的时候表示当前字节已是最后一个字节。存储也是采用Little Endian的方式,拿出第一个字节的低7位作为数字的低7位,如果最高位为1,则拿出第二个字节的低7位作为数字的8-14位,以此类推。
以32位整数为例,如图:
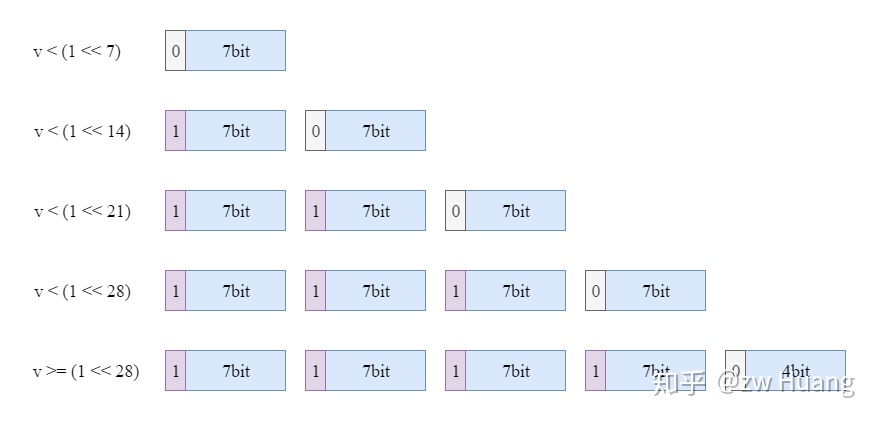
如果编码值 v < 1 << 7,只需要7位即可编码,可使用0 + v的方式;
- 如果编码值
1 << 7<= v <1 << 14,需要两个字节编码,第一个字节使用1 + v的低7位,表示需要查看下一个字节,下一个字节使用0 + v的高7位,表示不需要查看下一个字节; - 以此类推。
// util/coding.cc
char* EncodeVarint32(char* dst, uint32_t v) {
uint8_t* ptr = reinterpret_cast<uint8_t*>(dst);
// 设置字节最高位的掩码
static const int B = 128;
// 只需要1字节
if (v < (1 << 7)) {
*(ptr++) = v;
} else if (v < (1 << 14)) {
// 低7位放在低字节,最高位置1
*(ptr++) = v | B;
// 7-14位放在第二个字节,最高位置0
*(ptr++) = v >> 7;
} else if (v < (1 << 21)) {
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = v >> 14;
} else if (v < (1 << 28)) {
...
} else {
...
}
return reinterpret_cast<char*>(ptr);
}
字符串
字符串的编码使用了前面32位变长整数来编码字符串长度,编码长度后跟字符串的实际值。因为采用长度前缀编码,所以不需要根据字符串里的\0来判断字符串的结束,字符串里面可以是任何值。
// util/coding.cc
void PutLengthPrefixedSlice(std::string* dst, const Slice& value) {
PutVarint32(dst, value.size()); // 首先以变长的方式编码长度
dst->append(value.data(), value.size()); // 添加内容到长度后面
}
void PutVarint32(std::string* dst, uint32_t v) {
char buf[5];
char* ptr = EncodeVarint32(buf, v);
dst->append(buf, ptr - buf);
}
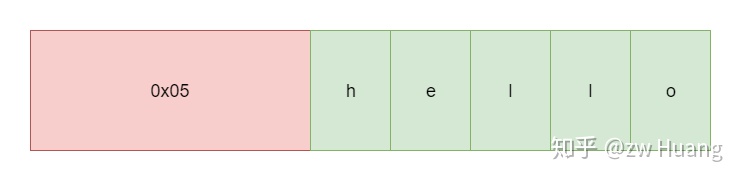
假如需要编码字符串hello,因为长度是5个字节,所以长度的编码就是0x05,后面跟字符串实际值,所以最终的编码就是 05 48 45 4C 4C 4F,需要6个字节。
这种编码有以下好处:
- 字符串里面可以包含任何字符;
- 字符串的长度可以预先知道,读取文件的时候更加方便;
- 采用变长编码字符串长度,对于大多数的小字符串只需要1个字节。
参考源码
util/coding.h util/coding.cc:编码实现的源代码
小结
LevelDB里面整数和字符串编码的方式很常见,我们经常可以在其它地方看到,这种方式简单高效紧凑。
原文出处:基础3:以不变应万变——字符串Slice
基础3:以不变应万变——字符串Slice
LevelDB里面主要用到的字符串类型不是C语言的char [],也不是C++的string对象,而是自己封装的一个简单的数据结构Slice。
Slice是一个简单的对象,只包含了指向字符串的指针和字符串的长度。为什么使用Slice而不使用char []或者string呢?有以下原因:
- 相对于拷贝string,拷贝Slice会轻量级很多,只需要拷贝指针和长度;
- char []无法保存二进制字节,而Slice则没有这个问题;
- Slice的底层可以是char,也可以是string;
- 多个Slice可以指向同一个字符串。
原理
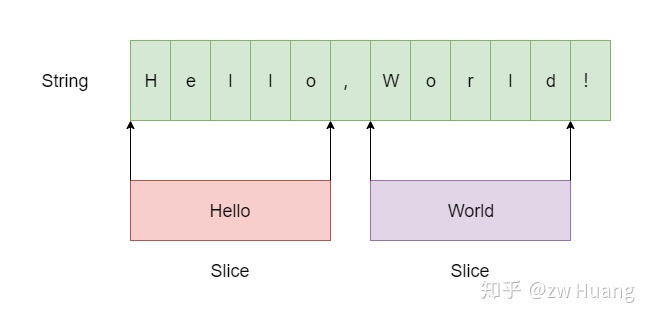
Slice有一个字段char * data保存字符串的指针,另一个字段`size_t size`表示字符串的长度,也就是Slice指向另外一个字符串。
// include/leveldb/slice.h
class LEVELDB_EXPORT Slice {
...
private:
const char* data_;
size_t size_;
}
使用Slice需要特别小心,使用者需要确保底层引用的字符串没有被销毁。
鉴于以上特点,Slice对字符串的修改非常简单,比如要取一个子串,只需要改变data_和size_的值即可,不需要进行子串的拷贝,开销非常低,非常高效。真正做到了底层字符串不变,但是上层却可以高效地随意改变。
而Slice和string以及char []之间的转换也非常简单。
// include/leveldb/slice.h
class LEVELDB_EXPORT Slice {
// 转换为字符串
std::string ToString() const { return std::string(data_, size_); }
// 去掉前缀
void remove_prefix(size_t n) {
data_ += n;
size_ -= n;
}
}
参考源码
include/leveldb/slice.h:Slice实现
小结
LevelDB的代码里面大量使用了Slice来代替字符串进行参数传递和返回,好处显而易见,避免了大量的字符串拷贝,提高了效率。
原文出处:基础4:添砖加瓦——Comparator,Status ,Env和Options
基础4:添砖加瓦——Comparator,Status ,Env和Options
这一篇是一个大杂烩,把一些常用的组件做一个简单的介绍,包括:
- Comparator 定义排序的规则;
- Status定义函数执行的结果信息;
- Env封装系统相关的调用,比如文件操作,线程操作;
- Options指定数据库选项。
Comparator
LevelDB是一个SortedMap,既然是一个SortedMap,键与键的顺序肯定是要有一个比较的规则。有很多的比较规则:
- 基于二进制字节序的比较;
- 基于某个字符集的比较;
- 基于某个字符集不区分大小写的比较;
- ...
LevelDB没有规定比较的规则,只是定义了一个Comparator接口,用户可以提供自己的规则实现这个接口。
// include/leveldb/comparator.h
class LEVELDB_EXPORT Comparator {
public:
virtual ~Comparator();
virtual int Compare(const Slice& a, const Slice& b) const = 0;
virtual const char* Name() const = 0;
virtual void FindShortestSeparator(std::string* start, const Slice& limit) const = 0;
virtual void FindShortSuccessor(std::string* key) const = 0;
};
Compare函数实现了比较的规则,根据大小返回-1,0,1;Name定义了比较器的名称,这个为了兼容用的,比如用某一个比较器创建了一个数据库,但是如果用一个不兼容的比较器打开这个数据库,可能就会出错,而根据Name来检查这个不匹配;FindShortestSeparator将start更改为一个位于[start, limit)里的最短的字符串。这主要是为了优化SSTable里的Index Block里的索引项的长度,使得索引更短。因为每一个Data Block对应的索引项大于等于这个Data Block的最后一个项,而小于下一个Data Block的第一个项,通过这个函数可以减小索引项的长度;FindShortSuccessor将key更改为大于key的最短的key,这也是为了减小索引项的长度,不过这是优化一个SSTable里最后一个索引项的。
LevelDB定义了一个默认的比较器BytewiseComparatorImpl,实现了基于二进制字节的比较,这个比较器的Name是leveldb.BytewiseComparator。
参考源码
leveldb/include/comparator.h:Comparator接口定义
util/cmparator.cc:默认BytewiseComparatorImpl实现
Status
Status定义很多操作的返回码,很多操作需要通过返回的status来判断下一步的行为。
Status由Status类来定义:
// include/leveldb/status.h
class LEVELDB_EXPORT Status {
public:
static Status OK() { return Status(); }
static Status NotFound(const Slice& msg, const Slice& msg2 = Slice()) {
return Status(kNotFound, msg, msg2);
}
...
bool ok() const { return (state_ == nullptr); }
bool IsNotFound() const { return code() == kNotFound; }
...
// 定义了错误码的种类
enum Code {
kOk = 0,
kNotFound = 1,
kCorruption = 2,
kNotSupported = 3,
kInvalidArgument = 4,
kIOError = 5
};
Code code() const {
// 提取错误码,在第4个字节
return (state_ == nullptr) ? kOk : static_cast<Code>(state_[4]);
}
// state_[0..3] 消息长度
// state_[4] 错误码
// state_[5..] 消息
const char* state_;
}
Status的状态都由一个私有变量char * state_定义:
- 如果状态为
OK,则此变量为null; - 否则,状态由一个状态码
code和一个message组成; state_[0..3]是message的长度;state_[4]第4个字节是code的值,预先定义了一些状态,由enum Code定义;state_[5..]就是message的值了,从构造函数看出,可以同时提供两个msg,这两个msg会通过:分隔;- 另外为每个
enum Code都定义了两个快捷函数,一个是生成一个这个错误的status,一个是判断是否是某个错误。
参考源码
leveldb/include/status.h util.status.cc: Status定义
Env
LevelDB是一个数据库函数库,数据库总是需要操作文件和线程,这就需要做很多系统调用。各个操作系统的系统调用方式不一样,为了跨平台支持,LevelDB对这些系统调用做了一层封装,提供了统一的接口来操作,并且提供了Posix和Windows两种实现,如果需要实现其他的系统,只需要根据系统实现相应的Env即可。
- Posix通过文件
env_posix.cc和posix_logger.h两个文件来实现; - Wondows通过文件
env_windows.cc和windows_logger.h两个文件来实现; - 通过cmake来选择相应的实现。
具体的实现比较简单,参考代码即可,没有太多可以讲的。
参考源码
include/leveldb/env.c:env相关的接口定义
util/env_posix.cc:Posix系统相关的封装,包括文件操作,文件锁,后台线程创建
util/posix_logger.h:Posix写日志
util/env_windows.cc util/windows_logger.h: Windows相关的实现
Options
Options定义了操作数据库的选项,定义了3个struct来操作:
Options定义打开数据库的选项;ReadOptions定义读操作相关的选项;WriteOptions定义写操作相关的选项。
这些选项就是简单的属性,可以根据源文件来看具体什么作用。
参考源码
leveldb/include/options.h:定义这三个Struct
小结
以上是一些基础组件的简单介绍,比较简单,涉及的代码文件也比较少,可以很容易看懂。
基础介绍完毕后,接下来将深入LevelDB的底层存储,看看数据是怎么存储的。