架构之路
原文出处:架构之路:前言目录
终于决心再一次开始这个系列的博客了。之所以说再一次,是因为我之前曾经试着写过这样一个系列,但中途却不得已停了下来。我总记得"之前"就是一两年前,查看 博客后才发现原来那居然已经是三年前了!不禁感慨岁月如梭,时间都去哪儿了?大概我转行做软件开发的时候,我的小女儿也开始孕育。如今,她已经是亭亭玉立的一个小姑娘 ,天真浪漫;而我这六七年的收获呢?
我学计算机学开发,目的很明确,就是奔着"架构"来的。当然,最初我不知道这个名词,我以为我就是去学"做网站"的。什么时候能够学会?最开始我以为三个月应该够了, 然后延期到六个月,再延期到一年、两年……直到现在。在这个过程中, 我算是深刻的体会到"学无止境",或者"学得越多越觉无知"是什么意思。
三年前觉得自己应该有资格可以显摆一下了,但到中途却越来越迷茫困惑,所以不得已再去摸索实践。没想到,这一摸索实践,又是三年过去了!三年过去了,实事求是的说,我 比三年前更心虚了:一些以前深信不疑的观点变得犹豫起来,一些从未有过的想法时不时的蹦了出来,新的技术猛烈的冲击着旧有的体系……我会不会还是误人子弟而已?
思前想后,我还是下定决心,重新开始这个系列。因为我百分百的相信,即使再过三十年,我也不会成为一个完美的架构师拥有一个完美的架构。所以,没有必要等到"完美", 也不可能有真正的"完美"。就在现在吧,把我的所学所思所得都展示出来,和大家一起交流碰撞,于人于己,都善莫大焉。
架构太难了!准确的说,是把架构做好太难了。
我曾经把技能分为两类:会和好。比如:"我会写字"和"我字写得好",这完全是两种不同的境界。"会"其实很容易,而"好"则很难。而很不幸,架构就是一个专注于"好 "而不是"会"的技能领域。任何一个系统,无论大小好坏,都有架构;所以只要能开发出一个系统,就已经"会"架构了。但我们的关注点,显然在于如何进行"好"的架构。 这个问题如此难以问答,以至于我还没有发现过一本专门论述该问题的书籍。被奉为经典的《企业应用架构模式》更像是一个架构汇编,告诉我们有哪些哪些架构模式而已(当然 ,我们不能否定它的巨大价值);其他类似的书籍实际上也未能给出明确的答案。在网上,相关的问题通常最后演变成一场"口水战",让人眼花缭乱最终不知该何去何从。
我实在查不到这段话的出处,但大意是:为什么讲解架构这么难(比如为什么要分层要抽象要封装)?因为如果没有一个足够复杂逻辑的例子,就无法展示这样做的好处;但如果 给出一个足够复杂逻辑的例子,就不得不花费大量的篇幅首先讲明这一堆复杂的逻辑,而读者在晕头转脑的理解这些复杂业务逻辑之后,很难再有精力来思考架构的技术问题本身 。
所以我最后决定采用这种方式来学习:自己去搭建一个有足够复杂业务逻辑的系统,在实践中一步步的学习领会各种架构知识。这是一个很笨的方法,但确是一个很有效的方法。 伴随着系统的不断开发完善,书上的很多说法得以印证,我之前的很多想法得以改变。每写一行代码,我都能感觉到我的一分进步!软件开发是一门实践艺术,坐而论道往往不如 身体力行,正应了那句话,"纸上得来终觉浅,绝知此事要躬行"。
所以,接下来我将以两个目前仍在开发的项目(详见:英雄帖:开源项目招募英才)为例,一步一步的讲解,如何通过领域驱动和测试驱动,进行敏捷开发,构建一个面向对象的B/S系统。
原文出处:架构之路(一):目标
标准来源于目标
前文说过,评价架构好坏是一个很主观的东西。既然大家写 出来的程序都能跑,凭什么就说你架构好,我的架构就差?拿出来大家评评理,张三说好,李四说不行,王五说将就……究竟谁说了算?现在已经不是一个迷信权威的时代了,所 以不管你多少光环加持,你都得说出子丑寅卯来,都得服众才行。
我觉得,这种现象的产生,抛开"同行相轻"和"流派之争"之类无厘头的东西,一个很重要的原因就是没有明确判断标准。所以在网上,常常就出现这样一种很热闹很 奇葩很无奈的现象:我和你说性能,你跟我说安全;我跟你说安全,你跟我说扩展;我跟你说扩展,你跟我说维护;我跟你说维护,你跟我说成本……
这是一个很简单的道理,没有标准,就无法进行评判!所以,如果不能统一一个评判架构优劣的标准,我们永远无法达成一致。你说有标准啊,性能安全可扩展……但这样还是不 行,标准过多,一样等同于没有标准。假设以100分为满分,性能占多少分?安全占多少分?可扩展又占多少分?因为要想提高性能,就可能就要牺牲可扩展性;要想安全,就 会牺牲性能;要想……就会……;哪一方面更重要,哪一些可以牺牲?如果不是胸有成竹的话,最后还是会左支右绌手忙脚乱,乱成一锅粥。
所以我再提出一个观点:以是否实现架构师的设计目标为标准。如果说一个系统的架构,最终实现了架构师的设计目标,我们就可以说这是一个好架构;如果说没有能实 现架构师的目标,这就是一个不那么好的架构。
"等一下等一下",你要是反应够敏锐的话,肯定会跳起来,"这是不是太主观(儿戏)了?我随便一堆烂代码,然后告诉你,'是啊,我设计的目的就是让他烂,越难越好', 按你的逻辑,这样也行?"(⊙_⊙),嗯,你要是这样玩儿我还真没办法。但是话又说回来,要让一堆代码能跑又还够"烂",也还不是一件容易的事,你觉得呢?
总之,我希望大家能明白我的意思:架构师开始一个新项目,应当设立一个适当的设计目标;然后通过架构,努力实现其预定目标。如果最终系统的运行,符合其设计预期,我们 就可以说:这个架构不错还行!反正,架构就出了问题。
我们的目标
软件行业有各种各样的系统,每一种系统的开发都可能会有不同的目标。比如导弹发射的系统,我们可以想象,目标(甚至是基本要求)肯定是:1、稳定(绝对不能走火);2 、迅速反应(不允许按下发射按钮后一分钟导弹才开始发射)。你可能觉得这种要求很好啊!任何系统不都是应该满足这样要求的吗?比如我在淘宝买T恤,结果给我发一条丁字 裤,这怎么行?一个网页半天打不开还有理了?我还真得答一句,它就是有理了。"存在即合理",这里的合理,合理在成本。我们目前日常使用到的绝大部分软件,都是有bu g的,而且是一堆的bug,但我们仍然在使用它们。如果你想使用像"导弹发射"一样稳定精确迅捷的软件,可能最后的结果只有一个:你用不起。(请自行脑补)
所以,其实我们是做了一个妥协,"便宜点,将就用吧"。我们为了达到我们的基本目的,牺牲掉一些"无关紧要"的东西。对于很多追求卓越的程序员来说,这种牺牲妥协是难 以接受的。"白玉微瑕,你让我怎么能够接受?"---- 但很多时候,你必须接受。这个问题这个观点,我们会在整个系列中不断的提及。请试着接受;如果你暂时还不能接受,请牢记:没有牺牲,就没有胜利!
那么,我们的策略是:特色突出、整体均衡。说得更直白一点:有亮点,没硬伤。这就够了!而我们的亮点就是:可维护性。(注意:不是可扩展,可维护性包 含可扩展,但不仅仅是可扩展)
为什么是可维护性
幸或者不幸,我进入软件行业之后,绝大部分的工作是几乎所有程序员都不齿厌恶的维护。我曾经维护过一个有十年历史的、糅合了C、VB、java、C#各种语言在内的一 个物流系统的部件。我在那家公司工作了一年多,说实话,直到我离职,对整个系统,我连边都没摸到---- 这个系统太大了,而且连我们公司都只是其主营公司众多外包公司中的一个。
在我花了两周的时间找到一个bug的位置之后,我以为我终于明白了为什么会说:"维护和开发的花费比是80:20"。但这只是我以为----现实更加残忍:差不多一个 月后,我又花了一个星期的时间,找到了另外一个bug的根源,正是我fix前一个bug所产生的。我泪流满面,有没有?脑子里一下就蹦出个词:"按下了葫芦浮起了瓢" !总之,如果fix前一个bug就会导致后一个bug;如果fix后一个bug,就会导致前面的bug。我忘了最后是怎么处理这个问题的,依稀记得是让项目经理去和稀 泥去了。因为这不是一个很关键很常用的功能,所以最后大概是不了了之吧。
后来我了解到,很多的开发项目,是这样一个流程:一群人根据文档开始开发,几个月后通过验收上线;然后开发团队解散,留下一两个项目组里最菜的菜鸟做"维护"。Gam e Over!皆大欢喜。这种现象,在各种外包团队(尤其是以项目计价的廉价外包团队)中更加的突出(这或许也是大家普遍歧视外包公司的一个原因?)
既然是这样一种开发模式,很多开发人员根本体会不到维护的痛苦。在他们看来,"维护嘛,修修补补,加一两个if...else而已,让我们开发人员做更高大上的工作吧 !"但他们也不是总这么幸运,有时候,他们会被抓去"填坑"。据说最通常的做法,就是在"老坑"周围再挖一堆"新坑",填平之前的老坑即可。周而复始,直到有一天," 受不了啦!我们重写吧!"----等等,为什么不重构?呵呵,好问题,你觉得呢?
需求变更
很多程序员把这种困境归咎于"需求变更"。如果不是那些傻逼客户一天到晚的改需求,我一定会做出一个完美的作品!
或许是因为我是半路出家的原因,和很多程序员相反,我觉得:不是需求变更驱动着软件的不断更改,而是"软件可以随意更改"的这种特性刺激了不断的需求变更。你 装修好的房子,是不是住一段时间之后就会觉得这里那里不合适?这里少了一个插座,阳台上该加一个龙头,橱柜用着不顺手……"要是能改改就更好了!",只是这样的改动太 费力,所以大多数时间我们都还是算了。但软件可以!理论上怎么改都可以。想想软件真的是一种很特殊的商品----它是可以交付"半成品"的。你先用着,如果有问题我再 改改,有新需求我再改改,一直可以改到面目全非。没有在其他传统行业里待过的程序员无法理解,"可以随意更改"是一种多么出色的特质。这意味着产品可以自我进 化,应对各种变化,可以永生!想象这样一台"汽车",开始可以在马路上跑,过段时间改一下就可以在水里游,再拆装一下可以当摩托拉风,堵车的时候展开翅膀……这是什么 样一种屌爆天的体验啊?
所以,"拥抱变化"绝不是一句口号,这是一种胸怀。
作为示例的这两个系统,我是希望能用他们一辈子的。但我甚至无法想象一年之后他们会是什么样子---- 他们需要接受市场的检验,应对技术的升级换代,会有各种想象不到的变化。所以,可维护性无疑是必须放到首位的。
为了可维护
明确了架构的首要目标,我们就可以做一些基础的选择了。比如开发语言,可是是面向对象的C#,不需要"性能卓越"的C。
说道"面向对象",可能有些同学就会比较high,脑子里就会冒出"抽象"、"封装"、"设计模式"等各种高大上的东西出来。但我不得不提醒你们:首先,这些都是微观 层面考虑的东西,而架构是宏观的;然后,这些都不是架构,而是润滑黏合支持架构的东西;最后,在其他条件不变的情况下,系统中这些东西用得越少,说明架构越好。
我们以"设计模式"为例。大家在学习设计模式的过程中有没有这样一种困惑,"这样继承封装多态乱七八糟的绕来绕去的干嘛?"我花了很长一段时间才明白,要理解设计模式 ,必须要明白三个字:"不得已"。是迫不得已,才用设计模式来解决一些特定的问题,而不是说正常的代码就应该这样写!这种迫不得已,有很多种原因。个人觉得最 容易理解的就是"适配器模式",因为出现了接口的冲突,所以我们不得不进行适配。但一个很自然的问题就是:为什么不直接改接口让他们自然融洽呢?这不是一种更自然更直 观的解决方案吗?答案很有可能就是因为架构---- 大的架构已经确立,局部必须服从整体。那么,如果一个完全理想化的架构,是不是根本就不应该出现这种问题接口冲突的问题,因而根本就不需要这种设计模式?
所以,我说设计模式之类的东西是润滑剂是黏合剂,他们的作用是弥补架构的局部缺陷,更好的支撑架构。更极端的一种说法可以送给痴迷于设计模式的同学:设计模式是药,没病就不要吃药!
那么,为了可维护性,架构中究竟应该注意些什么?这是一个很大的话题,开篇我们只说一点。
模块划分
模块有大有小,大可以是一个分层一个项目,小可以是一个方法一个类。我们通常的做法是由大到小,逐步细分。
模块的划分是相当的考验架构能力的。良好的模块划分,能够让我们方便的安排人手、合理的组织项目进度、迅速的定位代码……各种好处说都说不完。所以还是说说不好的模块 划分有什么问题更容易一些,嗯,这个好像根本就不要说,想想你在一堆乱七八糟的代码里不断的F11的情形吧!
我个人认为,模块划分的难度在于"整齐"和"灵活"之间取舍。通常来说,大的模块我们都是"一刀切",着重强调的是"整齐",比如口熟能详的UI层、BLL层和DAL 层,但这种"一刀切"的做法,更多的是一种无奈。我们的人类的思维局限决定了我们在考虑复杂问题时无法深入到每一个细节,所以只能先"大而化之"的把一个复杂问题先进 行简单化。这样带来的一个严重的副作用就是,限制了代码的灵活性;而灵活性,正是应对复杂变化的有效武器。所以,在更小一些的模块(比如说:类)里,我们引入了丰富多 彩的抽象继承设计模式等一系列充满各种灵活性的机制,以弥合"一刀切"造成的问题。这一松一紧一张一弛中"度"的掌握,就只能说是一种艺术了。
模块划分,笼统的说教用处不大,我们将在后面的文章中结合具体情况逐一说明。但我希望大家能够明白:模块划分是必须的----这种必须,是一种无可奈何的选择。所以, 喜欢从页面直接写sql到数据库的同学,老大让你把你的代码拆成几段放到不同地方的时候,不要嫌麻烦;喜欢把一个简单项目切成七层的同学,先仔细想不想这样做是不是真 的有必要。
代码之外
为了代码能够长期有效的维护,我们还需要做很多工作,比如良好的文档、完善的项目管理流程。但我想说的,还是不是这个,而是代码之外的因素对项目架构的影响。比如开发 团队的背景能力偏好,一群C#程序员,你一定要整个node.js,这纯粹是给自己找不痛快。除了这些稍稍用脑袋想一想就能明白的东西,有一件事,很多程序员并没有意 识到。
架构的一个天然目的就是:让代码更智能让程序员更傻瓜。换一张说法就是,架构要"创造便利,让程序员更关注业务"。
这可能是一个让程序员感到悲哀的事实。正如机械师不停的发明,让机器变得越来越聪明,取代流水线上的工人,最终取代了他们自己。从某种意义上说,我们都是自掘坟墓的人 。一个良好的架构,就应该是让每一个普通开发人员,都是一个个尽量廉价随时可以替换的螺丝钉,这样才能保证系统永远健康正常的运行下去。告诉你这个事实可能让你一整天 都不开心,但接受这个事实之后能帮助你在工作中变得更加的"心平气和"。螺丝钉就要有螺丝钉的觉悟;更何况,当好一颗螺丝钉也不是一件很容易的事。
原文出处:架构之路(二):性能
我们在上一篇博客中设定了架构的目标,只有一个,就是可维护性。完全没有提性能,这是故意的。
似乎程序员都是急性子,或许是被windows冗长的开机时间折磨够了,有可能是因为提升性能的效果是最显而易见的……总之,我发现,绝大部分程序员对性能的关注和热 情是无与伦比的!
- C#刚刚推出的时候,就有人摇头晃脑的说,"嗯,自动垃圾回收,性能不行吧?"
- DataSet横空出世,马上有很多人写代码,在DataSet里插入几百万条数据,证明DataSet的性能问题
- Linq当然更要被骂了,尼玛用反射?反射是什么,同学们知道么?性能大老虎呀!更不用说那些自动生成的sql了,有我手写的高效么?
- ……
所以直到今天,我仍然看到很多程序员无怨无悔的用存储过程来构建他们的系统,一个存储过程可以有几千行!然后,他们很无辜的问,"业务层有什么用?究竟能干些什么呢? "
在带团队的时候,我最怕讲的就是性能有关的问题。你要是不谈性能呢,那代码有时候真心看不下去;你要是强调性能呢,不知道他会给你整出什么幺蛾子出来。其实这就是一个 "度"的掌握,所以非常难以用语言予以表示清楚。所以无数次挫败之后,我只好咬牙切齿的说,"你的代码,只有一个评判标准,可维护性。性能的问题先不管!"这 个答案似乎并不能服众----尤其是对有上进心的程序员而言。
所以,我先专篇讲性能,希望能帮助大家更清楚的认识这个问题。
一、性能不是不重要,而是他没有可维护性重要。要理解这一点,首先要理解可维护性的重要(请再读上一篇我花数周找bug的段子);然后要明白:解决性能问题,我们可以有很多代码以外行之有效的方法,而可维护性基本上就只能 靠代码了;最后,还是要牢记:没有牺牲,就没有胜利!
二、所以,在绝大多数情况下,当性能和可维护性相冲突的时候,性能让位于可维护性。我们采用其他办法来弥补代码性能不够高的问题。
空洞的说教没有意义。我们还是举例来说明吧!
破坏可读性
前段时间我review代码的时候发现,这个程序员用Linq之后老是用First()而不是Single(),我就奇怪了,按业务逻辑,返回的值就应该是一个,难道 可能会是多个,多个应报异常,不应该取First()就完事了呀?想了一会儿,问这个程序员,他的回答让我瞬间一种无力感,"First()性能更高呀!"以下为对话 实录:
"你怎么知道First()性能更高呢?"我问。
"First()嘛,取了第一个合格的值就返回,就不会继续查下去了;Single()的话,就会一直查,查出所有数据,然后再取其中的一个。"
"你确定?你知道有一种东西叫做索引不?"
"啊?……"
然后我简单的告诉他,索引是一种树状结构,可以让查询更快等等。
"但我还是觉得应该用First()",他想了一会儿,还是很坚定。
"为什么?",我不明白了。
"就算有索引加快了查询速度,但用First()在加快了速度上更快呀!更快总是没错的吧?"
"……",我真不知道该怎么说了,最后突然灵光一闪,"好吧,那你说说,微软为什么要搞一个Single()方法出来呢?就为了搞出来误导你们?让用First()的 产生优越感,嘲笑用Single()的?"
他陷入了沉思。
评论里还在纠结Single()/First()的同学,请大声的吼三遍:可读性!可读性!!可读性!!!
发现同学们还在纠结这个细节。好吧,再解释一下:
1、你怎么知道数据库用的就是MSSQL呢?你怎么知道就是用的关系数据库呢?NoSQL不行么?所以,你怎么就知道Single()/First()具体是怎么执行 的呢?比如我就要写个Linq实现,把所有的数据全取出来,然后再在内存里排序,最后取First呢?
2、这里我们考虑可读性,意思是:读代码时,看到Single()就能瞬间知道coder的意思是取唯一的一个;看到First()就知道coder的意思是 要取第一个。和性能没关系,如果一定要纠缠性能,那好:你要确定唯一性,当然要做检查(包括不唯一时抛异常),这个性能损失是应该的呀;你要取第一个,当然要 进行排序,排序也会有性能损失呀!
我刚入行的时候,还很是收藏了几篇文章,比如《高性能编程的十大准则》之类的,里面的内容大致就是,"总是使用StringBuilder,不要使用'+';总是使用 ……,不要使用……"。这类文章下面总是有一堆人叫好,"不错!","谢谢分享!"但慢慢的,我就对这些文章产生了怀疑(也应该感谢园子里的老赵,csdn里 面的sp1234之类的大神);直到很后来,我才明白为什么这种说法是肤浅的;而只有通过上面的对话,我才能清晰的把我的理解说出来。
所有这些牺牲性能的简单封装,都是有其目的的;而其中一个很重要的目的,就是为了提高可读性。你为了性能,故意不使用这些现成的封装,通常,丧失的就是可读性。
想当然
继续上面这个例子。最开始的时候,这个程序员关于性能的考虑其实是想当然的。这种想当然的情形很多,大致有这几种:
- 自己的理解完全就是错的
- 自己的理解不能算错,但实际上底层已经对该问题做了优化
- 自己的理解没错,底层也没优化
第1、2种比较好理解,第3种为什么也说他"想当然"呢?因为没有和硬件环境相契合。
最简单的例子就是"缓存"。比如面试的时候,问你一个问题,"缓存能不能提高性能?"请注意,这是一个陷阱。答案应该是:"不一定"。几乎所有的人都认为,缓存可以迅 速改善性能,是因为今天计算机的CPU和磁盘运行速度,远跟不上内存的发展。但即使如此,无节制的缓存,一样可以拖垮整个系统。
类似的例子还有很多。你沾沾自喜,我节约了一次磁盘读写的时候,你同时增加了CPU的负荷;你优化了算法,减少了CPU的运算,但其实增加了内存的压力……天下没有免 费的午餐。同样的代码,随着数据的增加,硬件的改变,会呈现出截然不同的性能表现。
所以,开发过程中,很多的"优化",其实只是你的想当然。与其这样想当然的优化,不如在拿到性能测试结果之后再有的放矢的进行优化。这时候,又回到了我们之前说的,是 不是代码的可读性更重要?这样你才能迅速的找到该优化的瓶颈啊!否则,一堆乱七八糟看都看不懂的代码,你怎么去优化,你连该优化的点都找不到。
难以维护
另一个搞笑的例子是关于我自己的。创业家园项目里有一个功能:显示博客正文的同时提供一个上一页下一页的链接。惯 常的做法就是直接在数据库里查就是了,但我总觉得不对,这样做两次查询有必要么?能不能优化?于是我想到了一个"绝妙"的点子:为什么不直接在博客里存储上一篇和下一 篇的Id呢?这样我一次性数据往返就能取到所有数据了嘛!各位同学是不是觉得我这个主意很棒?
噩梦由此开始了。
首先,我们是想在发布博客的时候,设置他的上一篇和下一篇。但是,上一篇好设置,下一篇呢?还没有啊!怎么弄,就只好在博客发布的时候,设置他的前一篇,同时设置他前 一篇的后一篇。
然后,我们新添加了一个功能,除了上一篇下一篇以外,还需要在当前博客所在分类中的上一篇和下一篇。怎么办?再加字段呗。所以,博客里就有了Previous, PreviousInCategory, Next, NextInCategory。这时候,就感觉到有点不妥,但还可以接受。
接着,出现了一个问题,上一篇下一篇博客被删除了,怎么办?这个过程,就相当于从一个双向链表里移出一个节点一样麻烦。头开始有点大了。
再接着,博客除了发布删除以外,还有各种其他状态,比如被屏蔽。而且被屏蔽之后,能否显示和当前用户又有关系。当前用户是普通用户,不能阅读;当前用户是作者自己,就 能够阅读。怎么办?首先,屏蔽的时候,要设置上一篇下一篇;屏蔽取消的时候,还是要设置上一篇下一篇。然后,上一篇下一篇得根据当前用户不同变化的这个问题,基本上就 傻眼了……
最后流着泪把辛辛苦苦折腾了好久的代码全改回来,就通过数据库查呗,多么清晰简洁的逻辑啊!性能问题?首先,这样做造成了性能问题么?然后,就算有问题,用一个缓存能 解决不?
#
合理浪费堆硬件
说了这么多,不知道有没有引起同学们的反思。可能大家还是过不去心里那道坎:明明有一种性能更高的方法我们为什么不用?
因为浪费呗!
什么?你有没有搞错?我的代码,至少省了一块内存条!那是你还没从"穷学生"的角色里转换过来。你花一周的时间对代码进行了优化(就先不考虑你的优化带来的维护成本增加了),为老板省下了一块内存条的钱。你以为老板会拍着你的肩膀表扬你么?老板打不死你!
兄弟,账不是你那样算的。当你是学生的时候,你的时间成本是0;但你进入工作岗位,每一天都是要发工资的。
通过代码来调高性能,是一种无奈----对硬件性能不够的妥协(参考:80年代游戏开发者的辛苦困境。这样写性能就高,但为什么现在没有谁再这么写代码了?)。否则,绝大多数情况下,堆硬件比优化代码的效果好得多,而且便宜得多。硬件的成本按摩尔定律往 下降,我们程序员的工资也能按摩尔定律减么?
明明window 10 比window 95更耗性能,为什么今天没人用window 95?为什么VS 2013要10G的空间我们都还屁颠屁颠的赶紧装上?为什么现在大家都用C#,没人用汇编?我们站在人类文明积累的今天,就应该理所当然的享受这一切成果。有打火机你不用,你要钻木取火。如果你是因为要学贝爷荒野求生装逼,可以理解;如果你说你是因为怕浪费天然气,我……我……我怎么说你呢?"给做打火机的一条活路,行不?"同样的,程序员大神同学,你就当做好事,给下面写底层做硬件的一条活路吧!你的代码都是010001000010000001010101……了,你让其他人怎么活啊?
最后,我突然想到的一个程序员为什么对性能如此敏感疯狂,对可维护性毫不在意的一个可能原因:
- 性能很好理解,卡得要死和跑得飞快;可维护性很不好理解,至少得跑个两三年才能体现,那时候,谁知道爷在哪里偷着乐呢
- 性能上不来,程序员只有羞愧的低着头,都是我的错;需求有变更,开口就骂,"哪个SB又要改……";
大家觉得是不是这样的?所以,愿意把代码百炼成钢绕指柔的人少。想来,是一种莫名的悲哀和凄凉。
最后最后,有一些我能想到的名言警句供大家参详:
- 过早的优化是万恶之源
- 优化首先需要找到性能"瓶颈"。否则,任何人都可以随手一指,"这段代码需要优化"。
- 可读性更强的代码总是更好优化
- 硬件永远比软件便宜
忘了说我的项目了。目前主要集中在创业家园项目的开发上,正试图从svn转成git源代码控制。不太懂Git, 说起来都是泪,懂的同学帮帮忙吧!
原文出处:架构之路(三) 单元测试
实事求是的讲,写《【野生程序员】:优先招聘》的时候,是带着情绪的。其后也有反思,是不是我杞人忧天了?尤其是下面开始的几条评论,如"都是混口饭吃的不容易","何以内外之分,中华儿女非山倾河泄而不能一气前指,千年亦是如此"等,让我感觉可能是我过于敏感了。但随后一些人长篇大论,让我明白,这篇博客还是有意义的。
想一想,招聘启示里,你们要求"计算机专业本科以上学位",我"无计算机专业相关专业文凭"优先;然后,你们就炸了!我们没有歧视,你这才是歧视!你自卑你愤青你酸你难成大器……我无力反驳,只是想说,每个人的言行都是他心灵的镜子。谢谢你们!
其实,我没有想挑起科班/非科班之争(虽然可能结果会超出我的预料),我的本意是想给"非科班"的同学鼓气,缓解他们身上的压力,让他们看到希望,给他们力量,让他们相信,完全可以在更艰苦的环境下自学成才,而且结果不会比"科班"的差!但你一定要委下身段踏踏实实的去学,一步一个脚印的去做,自卑自大争吵辩驳都无助于你的成长。请牢记:言语没有力量!
另外,愿意听一句的"科班"同学,"无计算机专业相关专业文凭"优先,并非完全出于义愤。都是筑基,你是名门大派用资源用丹药堆出来的,他是一路苦修战斗领悟突破的,你觉得谁更有潜力?所以啊,放下那些虚荣骄傲,真正的去战斗吧!毕业三年以后,是没人再看你的学历的。
另外声明一点,对老赵没有任何意见,除了景仰。他针对的是培训机构我完全明白,但仍然不能赞同。所以我说,"每一次看到这一段文字,我的心里就会有一种难以言表的复杂情绪",至于如何复杂,不是说了吗?难以言表啊。
======================
好,心平气和之后我们继续讨论技术问题。在带队的过程中,性能的问题还比较好解决,最消极的想法,"好啊,多一事不如少一事,你让我不管还不简单?",但要求写测试代码,那就炸锅了!以我的经历,"测试驱动"是一个最具争议的话题,没有之一。吹捧者和反对者泾渭分明,而且都有大量的论据和证明。记得博客园曾经有一篇文章,大意是:"公司付钱给你不是让你写测试代码的",下面一片狂赞。
在我自己的项目开始的时候,我是放弃了测试驱动的(呵呵,还找到了原文),里面总结得很准确,最大的原因是"懒"。但最后让我下定决心开始"测试驱动"实践的,是我一次花了两天一夜都没调出一个Bug,垂头丧气筋疲力尽之后,无可奈何的接受了这个现实:测试还是很有用的----即使是自己写的代码。我之前的系列博客,也已经反复的强调,架构是一种"无奈",是现实是问题驱使你去做一些其实你本来不想做的事情。你无法理解一些看起来像"脱了裤子放屁"一样的行为,通常只是因为你没有遭遇过那些现实那些问题。(看看,大学能教你这些东西么?)
即使你没有多少开发经验,你也应该能够想象,单元测试最大的问题,就是它需要花时间花精力去写,那么这个花费是否值得呢?这还是由你架构的目标决定的,或者你的需求决定的。如果系统是一次成型交付使用,此后几乎不会更改的 ,那么一次性的手工测试就够了;但如果你的系统是会被"千锤百炼"的不断折腾修改的,那么这个测试就是很有必要的。最简单的考虑:每一次更改,我都要手工测试一次;那还不会如我多花点时间,弄个"自动化"的东西出来。单元测试,其实就可以理解为一种自动化的测试工具。
但是"自动化"的理由还远远不够。因为你马上想到的,每一次需求变更代码调整,测试代码也得相应的改呀?没有测试代码,我就只需要改开发代码;现在有了单元测试,我还得再改测试代码。本来我只维护一套代码,现在我凭空增加了一套代码也需要维护,这不是增加了维护成本,不是和你"可维护性"的架构目标背道而驰了么?是一套代码好维护呢,还是两套代码更好维护?
这是一个非常好的问题,适用于很多情景(比如分层架构,你说分层解耦,实际上还不是一改就得从UI层改到数据库,每一层都得改?)。我能给出的回答大概有:
一、无论有无单元测试,开发代码进行修改之后,是不是都要进行测试?没有单元测试,并不代表你的代码就不需要测试了,只不过是你手工的去测试了一遍而已。切记:你的工作并不只是把代码写出来而已!
二、进行手工测试,和更改单元测试,两者的耗费比,会根据测试重用的次数而变化。一次手工测试可能需要5分钟跑完,更改单元测试代码可能需要20分钟,但如果这测试会 跑100遍,单元测试完胜手工测试。
三、你说,哪里哟?什么功能会改100遍?我没说你的功能会改100遍,我说的是测试会跑100遍。有区别么?你可能还在犯迷糊,是吧?好吧,我们讲个故事。
有一个小伙子,他很不情愿写测试代码。老板拿他没辙啊,也没那么多精力和他磨牙,于是老板自己写单元测试。这小伙子的代码提交之前要review,老板总能一次次的找出它代码的问题。他改的是登录,老板告诉他积分系统被他改出了问题;他又去改积分,老板又告诉他消息通知系统被他改坏了;他又去改消息系统,老板告诉他登录还是有问题……于是他崩溃了,"这TM什么一个烂系统"?最终他终于回过神来了,为什么老板总能知道这里的改动会影响那里呢?老板的思维有这么严谨?老板躲在一旁偷笑,就不告诉你,"其实我就是跑了一遍单元测试而已"。
这个老板就是我。我故意的,就不一次性的告诉他所有的问题,就要这样一次次的折磨他,让他的痛苦能刻入骨子里去。最后,我还要问他:
- 你现在对你的代码是不是还那么自信?
- 如果没有我的review(我也是靠单元测试),你能不能发现这些问题?
- 如果我们的项目已经部署到生产环境,而且你的改动带来的破坏没有被发现就上线了,会带来什么样的后果?
这一次,他服气了。后来他用NUnit用得麻溜麻溜的。每一次改动,如果有意想不到的未通过test case,他都会很激动的给我张截图,顺便发发牢骚。我微笑不语,那种满屏绿灯通过的踏实,和意外爆出红灯之后的惊喜,没有经历过的人,是无法体会的。
所以其实当对象间的关系变得越来越错综复杂,像一张密密麻麻的网一样之后,一个局部的改动就很有可能会触发极其复杂的连锁反应。所以为了保险起见,所有可能相关的组件都应该进行测试(所谓的"回归测试")。这时候如果只有纯粹的手工测试,会面临两个问题:
- 难以确定测试的边界(那些部分可能会被影响),这得我们脑袋凭空硬想啊,兄弟!
- 极大的测试耗费。而且这种耗费是相当的无聊繁琐伤人心的----没人愿意做这种事。据说所知,现在很多公司测试人员的工资已经比开发人员还高了。为什么?简单枯燥无聊,没人愿意做啊!
好的,我假设你已经认识到了单元测试的重要性,并开始摩拳擦掌,跃跃欲试。接下来我得给你泼一大瓢冷水:单元测试不是那么好写的!从某种程度上讲,写单元测试比写开发代码还难。难得我工作的所有公司,没有一家有过成功的案例。
大概是几年前,我在公司修bug,老大告诉我,"你这个功能比较核心,跑一下单元测试吧"。
"哇塞!我们有单元测试?"一种高大上的感觉迅速弥漫全身,终于见到传说中的Unit了!
捣鼓了一会,能跑了,试试看----我的个妈呀?怎么这么多红灯?我真被吓住了,这都是我的改动造成的?
老大就是老大,不慌不忙,"数一下有多少个通不过?"
"啊?"我以为我听错了,数多少个通不过有什么用?得把他们全部弄通过啊?!
搞了一会儿,才终于弄明白了,把我改动前后的代码分别跑一遍,对照一下通过失败是不是一样的,只要是一样的,就OK了。比如,以前是8个通不过,现在还是8个通不过,这样就可以了!
我一直不明白,为什么不把那8个通不过的单元测试给弄成通过呢?这样摆着究竟算什么?直到我自己开始写单元测试。坑爹啊!到处都是坑,跳出小坑进大坑,大坑下面还连着小坑,前面是坑后面是坑,一堆一堆的连环坑……
单元测试写出来容易跑过难!而且跑不过的原因还不是你的开发代码逻辑错了,而是测试环境/数据出问题。要测试,一定要有数据,这个数据的构建,完全不是我们所想象的那 么简单。以我们创业家园项目里的积分系统为例,假设一个简单的需求:博客被点赞,博客的作者应该获得一定积分,该积分数量是由点赞人目前所有的可用币转换而得来的(已简化,具体可参考文档:积分)。要准备的数据就有:博客一篇,要有作者,作者已有积分;点赞人一名,有一定数量可用币。如果只是这样,还可以接受,但其实下面会有一堆的问题:
- 作者的积分从哪里来?我们的开发代码,出于封装的考虑,用户的积分是只读的,你单元测试怎么设这个值?
- 要么写代码,模拟作者通过其他行为(发布文章回答问题等)获得积分,这将开启新一轮噩梦;
- 如果用Mock或者反射强行设置,事实上省略了作者获得积分的历史,所以用户"积分历史"为null,之后对其"加积分"时,就会报异常。
- 更坑的是,你以为你什么都处理好了的时候,你突然悲哀的发现,这个博客得首先"被发布",而博客一经发布,其作者就获得了一定数量的积分,所以你以前设置的积分又变了!
- ……
- 点赞人的可用币,同样可能遇到类似的问题。可用币怎么设置,设置之后会不会在跑测试时被意外更改?
- 点赞的行为,被封装成一个方法,运行这个方法,会检查点赞人之前是否已经对该文章点过赞,所以还应该有一个"点赞历史记录",哪怕是空的,都得new一个,否则就空异常
- ……
反正当时是写得我直接摔了鼠标!写得憋屈啊!而且我还是完全隔绝了数据库的,真不知道那些要从数据库里取数据来跑单元测试的,是怎么做的?这时候我一下子就明白了,实际工作中加班赶进度,一个接一个的填坑,连重构的时间都没有,怎么可能还挤得出时间来写单元测试?就算开始雄心勃勃的写了,随着系统日益复杂,维护单元测试的成本也与日俱增,甚至复杂度更甚开发,所以放弃也就成了绝大多数项目的唯一选择。
在公司上班么,大多数人都是这样的,能推就推。我们开发写完了代码,基本上能跑了,就该交给测试人员了呀!天经地义的嘛,是不是?而且测试的时间是不会计算到我的项目开发时间里的,我总算是按时完成了开发任务。累坏了,休息一下,让测试的忙活去吧,哈哈……
但我是个光杆司令,我没测试人员啊!曾经有那么一两个时候,我真准备招一两个测试人员的。但好在我天生的节俭美德(也就是"抠"啦)让我冷静下来。我就想啊:测试只能告诉你出了bug,不能告诉你根源啊。没有单元测试,我单步调试,不也折腾了两天了么?这是系统本身的复杂性,或者代码组织的不合理造成的,不能归咎于单元测试。不还是有这么多开源代码都有详尽的单元测试么?他们是怎么做到的呢?在单元测试上的付出,最终一定会获得超值回报!想想没有单元测试的公司,那超级庞大的测试团队,或者四处冒烟的系统,你愿意走这么一条路么?
所以我不断的告诫自己,不要着急,冷静细致。终于一步步抽丝剥茧,把这一团乱麻一点点的归纳整理,最终还真被我找到了一条路子,一个个的单元测试都慢慢完成通过了,开发代码里潜在的一些问题也浮出水面,被我一个个的消灭。最后再跑一遍单元测试,一路绿灯,哈哈!更奇迹的是,困扰我两天的bug不知道什么时候消失了?
后来,我看到这样一种说法:可测试的代码不一定是好代码,但坏代码几乎是不可能被测试的。深以为然!深度耦合的代码,写他们的单元测试,难于上青天;但反过来,我们可以以可测试为标准,不断的完善重构开发代码,只要这样坚持下来,最终代码的质量怎么都不会差到哪里去。
所以,于我而言,单元测试是否有价值的争论可以休矣!不如换个角度,想一想,怎样才能把单元测试坚持下去。
最后,如果有心的同学就会注意到,我一直用的是"单元测试",而不是"测试驱动"。因为测试驱动是一个更广阔的概念,是一个更崭新的天地!单元测试只是其中的一小部分,在下一篇博客,我会讲解我是如何试着将测试驱动的概念运用到项目开发管理中去的。这里,需要强调的一点:先写测试。
一上手就写开发代码,写完了才写单元测试。这是很多开发人员的习惯,我也经常犯这样的毛病,一不留神就忘了。这样做最大的问题就是,没有真正实现"测试驱动"。你实际上还是由开发在驱动,那么很自然的,测试照着开发的if...else...写一遍,有什么意义呢?这样做下去,就会不断的强化"测试无用累赘"的印象,因为测试就是简单的把开发代码重写一遍而已。我开的药方是:
- 单元测试代码和开发代码由不同的人员编写
- 如果做不到上面一点,先写单元测试
- 如果连上面一点也做不到,直到出了bug了再写单元测试
第三条可能有同学无法理解,不是说单元测试很重要么?为什么要等到出了bug才写?答案是:偷懒呗!记住,我们程序员是世界上最懒的人,没意义的事从来不做! 你先写开发代码再写测试真的没意义,没意义就干脆不要做了。但你可以开启"乐观模式"(或者"Lazy模式"?),先乐观的认为,我的代码没问题,或许真的就没问题呢,是吧?如果真出了问题,做一个补救,这个时候就应该用单元测试把这个问题表现出来,因为他根据墨菲定律,它这里出了问题,以后就很有可能继续出问题。这个时候,就不要再偷懒了。
(未完待续)
老规矩,说说我的项目进度。
创业家园 里添加了"个人资料"功能,可以展示个人所在城市、技能特长等信息,修复了一些小bug。
创业家园 还没空打理。大家不要再喷它的美工了,美工其实就是在下。以后(现在还没用)采用bootstrap,应该会好看一些。
前面写了这么多,很大程度上就是为了这一章做准备。面向对象或者领域驱动,最重要的一点就是要忘记数据库!我花了很长很长的时间,才理解了这一点,从而真正的迈向一个崭新的天地;而后,我又花了很长很长的时间,才勉强做到这一点;我希望,有一天,这将不再是一个问题,我不需要考虑这一点……
为什么业务层这么薄
三层架构流行起来之后,我们很清楚的知道UI层负责页面交互并调用下一层,也知道DAL层就是和数据库打交道。但BLL层?什么才算是"业务逻辑"?有各种各样的解释,但这些不都是sql做的么?对于绝大多数的应用系统而言,除了对数据库进行"增删改查"以外,实在不知道还能做些什么?更何况,不是还有超级强大的存储过程么!
所以,很多系统,即使勉强弄出一个业务层,也"薄"得不像话,像一层塑料薄膜一样,让人有一种把它立即撕掉的强烈的冲动。
为什么会是这样呢?
这得从.NET阵营从历史说起。.NET阵营的同学知道三层架构,多半是从PetShop开始,这被奉为三层架构的经典,很多项目甚至是直接复制其架构。在当时,它是一种了不起的进步。那时候,还是从ASP向ASP.NET转型的过程,很多asp项目,sql代码都还是写在html里面的!所以,UI和DAL的分离,无疑具有明细的示范效应。
但微软的步子,不大不小,刚好扯着蛋。
步子小一点,做成两层架构,估计一点问题都没有,大家都能接受;步子再大一点,就得上ORM,可惜微软当时还没条件支持。所以就搞出了这么个不明不白稀里糊涂的概念出来,折磨了我好久好久……
长期以来,.NET的阵营,在应用级层面,其实是"面向数据库"的。从DataSet、DataGrid、DataSourceBinder之类的,都可以看出来。即使是Entity Framework,最开始也是从数据库的表向.NET的类进行映射。这些,都极大的制约了.NET阵营同学面向对象的思维拓展。
好在我终于跳出来了。
面向数据库
为了说明,我们举一个最简单的例子。
需求是:记录文章(Article)的浏览数(ViewCount)。每当文章被阅读(View)一次,浏览数加一。
看到这个需求,你首先想到的是什么?是不是:
Update Article set ViewCount = ViewCount + 1;
如果是这样的话,恭喜你,你还牢牢的守住了"面向数据库"的阵地。
/*
面向数据库并不是不可接受的,面向对象也并不一定比面向数据库"高级"。
这只是两条道路的选择,如果你愿意看一看另外一条路的风景,就请继续;否则,就此打住吧。
*/
面向对象
那么,面向对象或者领域驱动应该是怎么做的呢?
public void View()
{
//从数据库中取出Article
Article article = session.Load<Article>(articleId);
//改变Article的ViewCount属性
article.ViewCount += 1;
//将改变后的Article再存入数据库
session.Save(article);
}
有什么感觉?眼前一亮,还是不可思议?想得更深一点的,是不是觉得这是多此一举,一句sql就能解决的问题,搞得这么复杂?
我当年,考虑最多的,最不能接受的,是性能问题。
- 这必须利用ORM,即使不考虑ORM生成的sql高不高效,就这生成sql的开销,应该就不低吧?
- 这样做,取数据,打开一次数据库连接;存数据,又打开一次数据库连接。就算有连接池,但能省一点就省一点不是更好?
所以,如果你也和我一样,倒回去看我之前的博客吧!
这样做,还有其他很多具体的技术问题,我们后续博客会逐一展开说明。
为什么
我们还是回到大方向上来,为什么要这么做?换言之,"面向数据库"有什么问题,或者说"面向对象"有什么好处?
我觉得,"抽象"、"解耦"、"复用"之类的说法,都还没有触及根本。最根本的原因,还在于我们的大脑,我们的大脑不适应于把这个世界抽象成一张一张的表,而更适应于一个一个的对象。随着系统日趋复杂,这种现象就表现得越明显。
我曾经参与过一个项目,它的数据库结构打印出来,得用地图那么大一张纸(我不知道算A几了),密密麻麻的全是表,各种线条交错其中,我看着就头皮发麻。部门里面像个宝贝一样把这张表供着,因为公司没法打印也没法复印啊!(我不知道他们最开始是怎么得来的,估计肯定麻烦)
如果你一边读一边在想,就会发现,"不对呀,有多少表就有多少类,类图不是一样复杂吗?"
是的,而且由于抽象,类很可能比表还要多。但是,有于抽象,在我们进行架构、设计、沟通的时候,可以暂时的抛弃很多细节。比如,我们可以说,"文章被评论之后,文章作 者的积分加10分",这个时候,我们就不考虑文章有很多种:博客、新闻、问答、评论……,也不考虑积分增加是直接改积分总分呢,还是添加一条积分记录,或者还要同步… …。如果只有表,你怎么说?
当然,表的结构也可以设计成类似于继承的样子(类的继承关系也最终会映射成表结构),但是,在交流沟通中,你如何表明这种抽象关系呢?
单纯从程序的角度上说,使用ORM,面向对象,还增加了系统的复杂性。毕竟多了一道工作,而且把对象映射到数据库不是一件简单的工作,尤其是你还要考虑性能问题的时候 。
那为什么我们还要这样做?委托,换言之,把复杂性往其他地方推。我记得我反复讲过这一点,架构的一个重要工作,就是把复杂性进行拆分和推诿。拆分估计大家好理解,但"推诿"是个什么意思,推给谁呢?管它呢,我只做我分类的事,其他的,UI推给BLL,BLL推给DAL,DAL推给DBA,DBA推给采购部……
写在这里很搞笑,但事实就是这样的。在性能篇,我说,你要写高性能的代码,你就是抢了人家的饭碗,就这个意思。UI都把DBA的活儿干了,人家吃什么?你代码都写成01001010101010二进制了,别说做汇编的,估计做CPU的都活不下去了。
我们这里,就是把复杂度推给了Map团队、ORM工具开发商和DBA。
因为我们要和客户谈需求啊,典型的是领域驱动,要和客户/领域专家找到"共同的语言",这共同的语言是什么?是表结构?估计如果开发的是一个财务会计系统,这还是可行的----估计早期的系统大多就是财务报表类系统?说不定还真是这样。为什么面向对象从Java开始流行,Java是虚拟机,可以用在微波炉报警器之类上面的,底层数据结构可以完全脱离数据库啊!.NET做什么起家的,就报表啊!呵呵。
总之,发展到今天,随着系统复杂性的增加。在系统的架构设计中,我们不得不将现实世界首先映射成一个一个可以封装、具有继承多态特性的对象,并且将重心放在这些对象关系功能的维护上。
数据库?就先不管它吧。
只有脱离了数据库的束缚,我们才能自由的翱翔在面向对象的世界里!
忘不掉
"问题是我忘不掉啊!"
"我只要看到需求,脑子里马上就是数据库就是表。"
"没有数据库,我都不知道怎么开始写代码了。"
……
是的,忘掉数据库是很难很难----尤其是对于我们这些老人来说。已经浸淫sql数十年的高手,你让我忘掉它?你以为写小说啊,张无忌学太极啊?
我只能说说我是怎么做到的,希望能给你一些参考。
我就假设我的系统不是用"关系数据库"存储数据,不是mysql,不是oracle;我用nosql,我用xml文件存储,行不行?nosql,怎么用?不知道啊,我十窍通了九窍。但我就要在我还不知道nosql怎么用的时候,就开始构建我的BLL/领域层。而且我只设定几个最简单的假设:
- 所有的对象都可以直接从硬盘Load()出来
- 所有的对象都可以直接Save()到硬盘
- 对象之间用1:1、1:n、n:n建立关联即可
究竟怎么从硬盘里存取(所谓的"持久化"),以后再说。我连用什么进行持久化都不知道,现在怎么考虑?但有一条,反正不会用关系数据库,估计是用nosql吧……
最终的期望
真正的对象数据库!快出来啊,求你了……
惯例说我的项目进展:
1、写文档写到吐……
2、重构累成了狗……
本计划发布了新版本再写这篇博客的,但实在不能再拖了。博客系列接下来,就进入项目的具体开发了,代码还乱成一堆,啊……
原文出处:架构之路(六):把框架拉出来
写技术文档的难度太大了!数次删改,都没能满意,所以我还决定,先写出来,以后再逐步整理完善---- 否则可能这个系列都没办法写下去了。这也算是借鉴了敏捷的思路,先写再改,不断迭代重构吧!
前面的几篇博客反响还不错,但还有一个硬伤,"说了这么多理论,能不能实践?"讲类似概念的文章不算多,但也不少了,但我一直没能从中收获太多的东西,反而更是云里雾里的糊涂了。估计这主要是两方面的原因造成的:我智商低,却爱较真!
你说得得天花乱坠,我只信一点,眼见为实,"是骡子是马,牵出来溜溜?"
按照你说的架构,把系统搭起来,跑起来,需求改上个几百上千遍,高并发大流量冲一冲……咦,这样一番折腾下来,没被砸跨,系统千锤百炼之后,还百炼成钢绕指柔。那我才竖起大拇指,真是不错!
我相信,按照DDD、TTD、敏捷开发之类的理念,一定有成功的案例,不然他们不会被站在巅峰的技术大牛们交相称赞。但很遗憾,我这个野生程序员,没机会融入那个圈子。
所以我就用了一个最蛮最笨的方法:我自己做一个系统,严格按照我自己对于这些概念的理解进行开发,看最后这条路能不能走出来?历经五年甚至更多时间的摸索和实践,我觉得我基本上是走出来了。
所以,如果你愿意,就静下心来,听我细细道来吧。
尴尬
在确定了忘记数据库的大原则之后,我们理应从业务层入手开始系统的搭建。
/*
为什么不是从UI层开始?不要笑,我还真记得,有看到过对这种做法的总结和推荐,还有一个什么专有名词,大概就是"页面驱动"之类的。
而且你静下心想一想,我们很多的开发实际上就是这样做的!确定方案之后,美工出效果图,前台切图出静态页面,程序员改成动态的,一页一页的做。
任务考核就大概是这样的,"我们今天把某个页面做完"。
这种做法的好坏利弊我们就不展开了。但如果你一定要一个不从UI层开始的理由,我觉得最有力的就是:我们系统要做三个版本,电脑桌面页面、手机页面和手机APP。
*/
业务层里,通常我们就把需求里的一些名词拎出来,做成一个一个的类,以创业家园为例,就应该有一个博客类(Blog),博客里还有方法,比如GetBlog(int Id),或者GetBlogs(int pageIndex, int pageSize),如下所示:
class Blog
{
string Title { get; set; }
string Body { get; set; }
Blog Get(int Id)
{
return new Blog();
}
IList<Blog> GetBlogs(int pageIndex, int pageSize)
{
return new List<Blog>() { };
}
}
这是我最开始接触三层架构时业务层类的样子,写在书上的。
但我就感觉这种做法特别别扭!一个博客对象取出10篇博客,一辆汽车具有提供十辆汽车的能力。这都是些什么乱七八糟的东西?不通啊……
我曾经想过将所有的Get()方法设置成静态的,这样从逻辑上说稍微通畅一点:通过博客类可以获取一些博客实例。但还是不爽,类的静态方法就丧失了对象的继承多态等特性。比如,取10篇文章,和取10篇博客就无法重用。
后来我才慢慢明白了,这种做法其实还是来自于"数据库驱动"的思想。Blog类其实代表的是数据库中Blog表,一个Blog实例就代表着一行数据,然后通过该表取到一些行,这些行又被封装成Blog类(细究起来还是很乱,是吧?)。估计当初微软DataSet的流行加剧了这一现象,当然DataSet本身没有问题,它的逻辑是自 洽的;然而有很多开发人员不认可DataSet,说它性能低,要用DataReader,自己"封装",结果不知怎么的,就搞成了上面那种样式的"四不像"。
Entity
上述传统的业务层架构,除了逻辑上的混乱以外,还有一个很大的问题:难以测试!和数据库搅在一起,怎么测试?我是头都大了。我得去做一个小型数据库啊?而且这个数据库还得insert/update之类 的,测试的基准数据就会变,所以每一次单元测试都得tear down(回到基准测试环境),这个又怎么搞?
//当然,后来我还是找到了混合数据库的测试方法,但我很高兴当时我对数据库的测试完全绝望的状态。因为这促成了我的"忘记数据库"的构想和实践
所以我就在想,能不能把数据库的操作隔离出来?这个时候,我应该是已经开始接触ORM了,他们的操作方式给了我启迪:关系数据库的"增删改查"中"改"没了。改(update)被"异化"成:取出(Load) -> 修改 -> 再存储(Savae)的过程(可参考《忘记数据库》中的例子)。所以,我们是不是就可以首先把"改"独立出来?通过不断的演化,我最后形成了一个Entity的project,负责且仅负责对象状态的改变,而完全不涉及对象的加载存储等功能。
这样做最大的好处,就是解决了Entity的单元测试的问题。由于(至少是暂时)不再需要考虑这些对象和存储问题,那么在测试的时候,我需要一个对象,只需要直接new一个就行了,而不是从数据库里取,这多方便啊!
Query(Repository)
那么,对象的增删查怎么办?从技术层面来讲,我们只能依靠ORM工具了,我用的是NHibernate。简单的说,通过NHibernate,我们可以在对象和数据库结构中建立关系(映射)。然后,可以通过NHibernate的session,调用session.Save(), session.Delete(),session.Load()和session.Query()等方法将对象存储、删除或者加载/检索到内存(C#项目)中使用。
/// 为什么是NHibernate?
/// 1、我的项目开始得比较早,好几年前了,应该是。当时Entity Framework还很不成熟,所以没有办法,只能选择NHibernate
/// 2、我想看一看微软框架以外的世界。其实后来我就知道了,在Java世界,我的这些做法已经差不多是主流了,所谓的SSH之类的。当然,对Java世界我也研究不深,可能也有差异。我的这个框架是自己摸索出来的,觉得够用就好。
但从系统架构层面讲,有另外一种提法:Repository模式。
Repository,从字面意义上理解,就是仓库。这个概念我觉得很贴切,就像汽车存放在库房里,我们通过仓库管理员,取出一辆或多辆汽车。这就有"代码映射真实世界",一种逻辑自洽的感觉;而不是之前,一辆汽车取出十辆汽车的样子。
具体到代码层面,就大概是这个样子:
class BlogRepository
{
IList<Blog> GetBlogs(int pageIndex, int pageSize)
{
return new List<Blog>() { };
}
Blog Get(int Id)
{
return new Blog();
}
}
但Repository的理解和使用都有争议,主流的大概有两种:
- 认为Repository是类似于集合,或者一种封装集合的对象。所以还是把它放到了Entity中使用。
- 认为Repository是"聚合根"的一种,和取出/存储对象并列,应该置于Entity之外。
我连Repository都没有显式的使用,所以就不进行这种关于概念的抽象讨论了。后面有机会我们穿插着讲一讲吧。
我们"增"和"删"直接利用了NHibernate的session机制,只是把"查(select)"给单独抽象了出来,也单独的抽象成一个名为Query的project。
Service
好了,现在我们可以回头归纳一下。对系统数据的操作,我们脑海中应该是这样一个概念:
- 前提:所有的对象平时都是直接的存储在磁盘里,然后:
- 我们需要某个/些对象时,就把他们从磁盘里取出来,加载到内存中
- 进行一些操作修改
- 最后再存储到磁盘中
那么问题来了,上面这些步骤,由"谁"来做呢?注意我们现在所说的这些东西,都是在业务层的范畴。所以,按照三层架构的思路,应该是UI层调用BLL层,而我们的UI层,采用的是MVC,所以,这样工作,是不是应该在Controller里面做?
但是,阅读我们的源代码,你就会发现,我们在UI层和BLL层之间加了一个Service层。实际上是由Service层来做的这些加载、修改和存储的工作。我非常同意这么一个观点:绝不能为了分层而分层。那么,Service层存在的意义是什么?
主要是为了前后端分离。早期的开发过程中,我设想过招聘一个专门的前端开发人员,他/她不管后台的具体业务逻辑、和数据库的交互,只管页面的呈现和交互。那么这里就有一个问题,我不想她只是一个单纯的美工,画出效果图切片弄成一个html的静态页面就完了,我希望她一样的用VS进行开发,用Razor做成view,还负责页面的交互和跳转,所以她还得在Controller里建Action,在Action里写代码。所以她在Action里写代码,是要得到数据用以呈现的,是需要根据页面回发的数据调用不同的业务逻辑的。那么,这些数据这些调用怎么得来?等着后台开发人员完成了之后再做?这无疑是很不经济的。
所以我们抽象了一个ServiceInterface,前台和后台开发人员可以先确立一系列的接口,然后各自去完成自己的实现。于是就有了:
- UIDevService:前台开发人员的"模拟"实现,看源代码就可以发现,里面是一些非常简单粗暴的逻辑。比如需要一个ViewModel对象,就直接给new一个就可以了。
- ProdService:真正的业务逻辑实现,是一直连到数据库的。
这其实就有一点"面向接口"的意思,前台后台都依赖于ServiceInterface的接口,而不管其具体的实现。
// 从这里我们就可以看出来,复杂的架构是一种无奈的选择。
// 如果我们的所有开发人员都是全栈级别的,可以从效果图一直插到数据库,我们可能就根本不需要这么麻烦。
// 而现实的情况是,而大部分的开发人员,都有他们的专攻方向;全栈程序员毕竟太少了。
当然,这样隔离出UIDevService之后,还附带了其他一些好处,比如更便利的单元测试。这些我们都以后再说。
上张图吧。先看看,看不懂也就算了,实在是我画得不咋的。以后还会详细讲的:
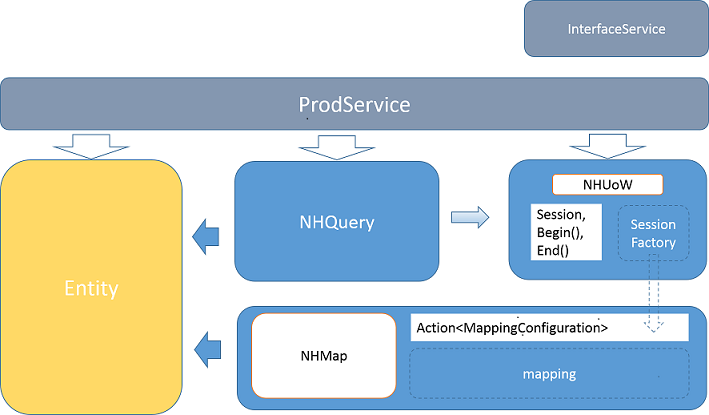
ViewModel
我们项目中还有一个ViewModel,我们的开发人员曾不止一次的提出来:为什么不能直接使用Entity呢?
我非常理解他的疑惑,一次次的把一个Entity里面的Article的属性取出来,再一条条的放到一个ArticleViewModel里面去,这多闹心啊?吃饱了撑的?
其实,我也是开发人员,这框架是我一个字母一个字母敲出来的,能偷懒的我肯定都会偷懒!就像前面我没采用Repository一样,我甚至都还弄过两层架构,但最后都没有好下场,才一步步走到今天。简单的说,ViewModel存在的原因主要有两个:
第一、前后端分离的要求。如果直接使用Entity,前台开发人员是不是又得等着后台开发人员把Entity先建好?是不是Entity一有变动就会立马影响前台开发?有兴趣的同学可以观察我们的ui.task.zyfei.net.sln解决方案,BLL层里的所有project是根本就没有包括在里面的,我们彻底的做到了物理隔绝!
第二、ViewModel和Entity其实是不能100%对应的。尝试过的同学都应该明白。比如我们创业家园项目里有"最新发布博客"的列表小方块,它是一个博客的集合,你怎么弄?你说我可以使用IList
最后,我们其实应该跳出来,从架构的角度来思考这个问题。ViewModel究竟是什么?它说承载的职责应该是什么?应该由谁来构建它?……
我认为:ViewModel本质上就是一个用于页面呈现的数据容器(DTO),所以他不应该具有任何内在逻辑,而且应该由前端开发人员来构建它。前端开发人员应该彻底的摆脱业务层中的Entity的束缚,根据页面的呈现规律,大胆的进行各种抽象组合,使得ViewModel真正的绽放它的光彩!
MVC
说完了上面这些,MVC其实也就没什么好说的了。就是Controller调用Service,得到ViewModel供View使用这样一个流程。当然,里面有很多值得细讲的内容,比如mvc route的测试、使用Autofac切换Service的实现、Session PerRequest进行性能优化等。我们在之后的分则里细讲。
这里还是上一张我制作的PPT吧,丑了点,先将就看吧!
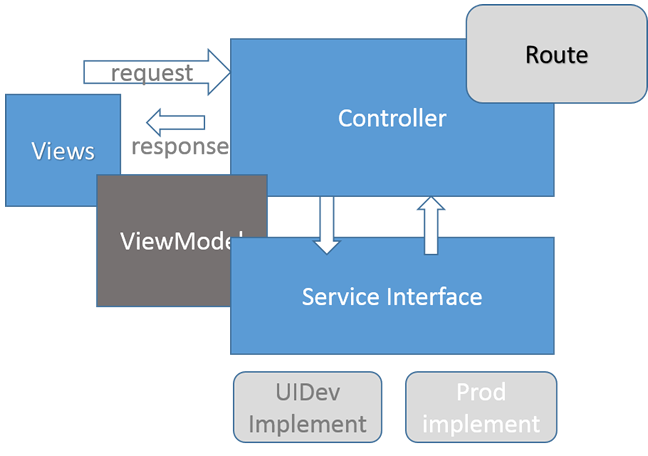
Tool
看过源代码的同学肯定也注意到了项目里有一个Tool的项目文件夹。里面最重要的,就是BuildDatabase项目。这个项目,肩负了构建开发和集成测试数据库的双重责任,还有帮助生成环境数据库更新的作用,是测试驱动的有力保证。可参考(文档可测试化)
要填的坑
框架就这么拉出来了,但其实里面的坑还有很多,趁着有思路,先挖出来,以后慢慢填:
1. UI
- CurrentUser的处理:也是一个相当头痛的东西,因为会大量使用,那么就想着要重用,要想重用就伤脑筋
- Get-Post-Redirct模式:里面也是一堆的坑。因为Http是无状态的,所以Redirect的时候就面临着一个传递数据的问题
- MVC Route:曾经伤心欲绝,当页面复杂之后,url就跳不到指定的action;或者稍一改动,以前的route规则就就崩溃了
- Partial View、EditTemplate和Child Action:在里面不知道晕了多久
- 单元测试
- 其他性能优化
2. Service
- 提高性能:SessionPerRequest。这个必须放在最前面说,因为它深刻的影响了我们下面提到的页面架构的很多东西
- UIDev和Prod的切换:利用Autofac
- SessionPerRequest的具体实现,和UI和NHibernate都搅在一起,真不知道该放在哪里说
- 为什么不使用Repository模式而采用Query
- ViewMode的Map:使用Automapper
- 单元测试:Query又要搅到数据库,唉……
3. BLL
- Entity大集合的性能问题。由于对象间的1:n的关系映射,造成一不小心,就扯出一堆集合数据出来,比如一个Author的所有Article,一个Article的所有Comment、Agree和Disagree。要这样弄的话,再多的内存也吃不消。
- Entity的多态应用。超级大坑,简直是要出人命的感觉,我觉得我能爬出来都是个奇迹
- Entity的单元测试。由于Entity之间复杂的对象关系,其单元测试简直就是一场灾难
- Entity的NHMap单元测试。Entity里都没问题了,但你怎么保证Entity的数据库映射时正确的?只能做单元测试,还是绕不开数据库!
4. Tool
- BuildDatabase:超级繁琐超级难
- 其他清理统计工具等
呵呵,原来有这么多坑!
这又让我不由得想起我烦躁咆哮,扯头发摔鼠标的那些日日夜夜,我也不止一次的怀疑过,我是不是走错道了?这些乱七八糟的MVC、测试驱动、面向对象……根本就没有让我更高效顺畅的开发,好像只是不断的在扯我的后腿。我就用传统的办法,拖控件增删改查数据库又怎么啦?不是一样能用?而且说不定早就开发完了!……
但一次又一次解决问题的喜悦,一不小心窥视到另一个世界的惊奇,让我欲罢不能。这可能就是技术路,人生路,大抵也如此吧?
最近沉溺于知乎,耽搁了正事。实在是惭愧啊!无论如 何,从本篇博客开始,我又回来了!回来继续苦逼的填坑……
原文出处:架构之路(七)MVC点滴
我们目前正在开发中的是任务管理系统,一个前端复杂的项目,所以我们先从MVC讲起吧。
WebForm
随着ASP.NET MVC的兴起,WebForm已成昨日黄花,但我其实还很想为WebForm说几句。
没有经历过从ASP向ASP.NET转变的同学,是很难理解当WebForm出现时,程序猿世界的欢呼雀跃的。事实上,我也是在Razor出现之后,才勉勉强强的转向MVC,因为看见<% %>这个东西就怕。我曾经参加过一个升级ASP到ASP.NET的项目,ASP里面乱七八糟的代码看得我眼睛又酸又胀红通通的流泪,一辈子都记得!
WebForm最后生成的html可能会臃肿难看,但其代码页面(.aspx)是相当清爽漂亮的。
既然我们都已经决定采用MVC了,WebForm的不足就不用再多说了。但我们应该努力的学习和借鉴它优秀的地方,这些也是在MVC的开发中会用到的:
- 呈现和页面逻辑相分离。WebForm里由于它的框架本来就显式的区分了aspx和aspx.cs,所以大多数时候我们不会担心这个事情。但MVC里面,我们很容易就在view里面利用ViewModel数据进行运算,模糊Controller和View之间的逻辑界限。这个问题我们将在CurrentUser的时候详细讲解。
- 良好的页面封装和重用。当我们发现页面又反复出现的、大同小异的"部件"时,我们肯定就会想到重用。这就是考验我们功力的时候。我先提一点我想到的:有时候我们宁愿重复不愿重用!这是我得出来的血泪教训。应该是在创业家园项目的评论页面部分,我曾经试图重用所有评论的PartialView,结果惨不忍睹,最后放弃重用,反而海阔天空。其实有一个更好的例子就是WebForm中的GridView和Repeater,从实践上看,反而是简单封装的Repeater更受欢迎,"大而全"的GridView却少有人用。所以封装和重用有一个度的问题。
RouteTest
Route功能是MVC的一个重大突破,也是一个重要缺陷。由于没有良好的自动检查机制,在实际的开发过程中,非常容易出错!相信有过开发经验的同学都有体会,有时候老半天都报错:找不到View找不到Action,查来查去就一个拼写错误;有时候新增一条RouteConfig,一会儿其他同事叫起来了,"考!原来是你的设置把我的覆盖了。查了我一下午!"
把时间浪费在这些地方实在是可惜,所以我们解决这个问题的办法是使用单元测试,在PCTest的project中引入了RouteTest。每一次新增RouteConfig,跑一遍单元测试:自己的能过,也不影响别人的,就OK了。
这是单元测试在我们项目的UI层最成功的例子。照理说,MVC的最大的一个好处就是"可测试",其他地方也应该广泛引入单元测试的,但本人偷懒,另外HttpContext的sealed限制也限制了单元测试的实施(MVC5应该解决了这个问题),所以目前UI层的单元测试还没有展开。但估计这个工作迟早都得做,现在已经出现了一些手工测试繁琐费事易遗漏的问题了。
URL/View层级
MVC现目前的另一个问题是,View很难按多层级组织。比如,我可能需要的View是这样组织的:
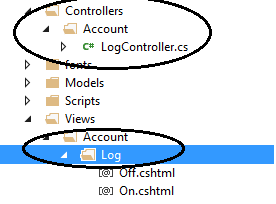
注意Controller也有层级关系设置。我始终觉得这样会更清晰整洁,但如果MVC的框架不能这样进行"层级对应"。如果一定要这样把View分层组织起来,在A ction中就必须写出View的全部路径,比如:
public class LogController : Controller
{
//
// GET: /Account/Log/On
public ActionResult On()
{
return View("~/Views/Account/Log/On.cshtml");
}
}
还得专门配置RouteConfig,这也太麻烦了一点。所以,我们就还是尽量按MVC的框架,从URL的设计开始,就尽量是/{Controller}/{action}/{route-parameter}的样式,View也同样,放在Contoller对应的文件夹下即可。
Partial/ChildAction/EditorTemplate
当我们需要重用某些"页面片段"时,我们就面临了以上这几种选择。切入的点有很多,我们就只结合我们项目,抽取其最鲜明最容易辨认的特点,直接讲述他们的使用场景:
首先是EditorTemplate。它的特点最明显,是和Post相关的。也就是,当一个"页面片段"的数据,还需要再Post回服务器的时候,我们就必须使用EditorTemplate;如果不使用EditorTemplate,就ViewModel的数据就无法传回(参考:任务管理系统代码中/Views/Task/EditorTemplates)。为什么呢?和MVC的ViewModel绑定机制有关,EditorTemplate中的html控件呈现时,会在其name上加上所属父Model的前缀,以便于MVC自动解析post数据并绑定到ViewModel。
如果"页面片段"不需要POST,只负责呈现即可,又该如何选择呢?我们的原则是:
- 如果"页面片段"不需要和服务器端交互,所需要的数据都能从父Model中获得,使用Partial;
- 否则,如果"页面片段"说需要的数据还需要从服务器获得,那就只能使用ChildAction了。
HtmlHelper
除了上述几种页面片段的重用,还有通过创建HtmlHelper的扩展方法,自定义一种"页面片段"的呈现方式。这种方式一般是PartialView的一种替代方式,我们通常把"很小很小"(比如一个链接、一个下拉列表等),用处"很多很多"(甚至于跨项目)的可重用html片段用HtmlHelper封装起来。可参考:
- 任务管理系统项目中的DocumentLink:封装一个总是使用doc.zyfei.net域名的html链接
- Global项目(还未上传源代码)中的EnumDropDownListFor:封装一个使用dropdownlist,该dropdownlist由enum填充,使用enum上的[Description]作为呈现文本
AJAX
观察我们的Action就可以发现,我们为Ajax提供的Action始终是返回的ActionResult,而不是使用"更先进"的WebApi机制(直接返回int等简单类型)。这主要是因为我们使用了SessionPerRequest机制(主要是为了提高性能),我们让一个Request请求只使用一个session(可先简单的理解为一个数据库连接),亦即:
- 当MVC获得一个Request,需要使用session时,Service生成一个session;
- 然后,在这个Request的整个请求过程中,使用的都将是这个已经生成的session(类似于"单例模式");
- 当Request结束后,释放这个session,将所有改动同步到数据库
好了,这里我们的关键点就是什么时候算"Request结束"?我们更进一步的定义它为View呈现完毕的时候,所以利用了Filter机制,在OnResultEx ecuted()时同步数据库,代码如下:
public class SessionPerRequest : ActionFilterAttribute
{
public override void OnResultExecuted(ResultExecutedContext filterContext)
{
#if PROD
FFLTask.SRV.ProdService.BaseService.EndSession();
#endif
base.OnResultExecuted(filterContext);
}
}
所以,即使Ajax调用,也必须经历一个"View呈现完毕"的过程,才能完成数据同步。
UIDevService切换
进行前台开发,不需要连接后台数据库的同学,只需要在MVC项目编译时,输入UIDEV即可(如果要真正的连接数据库,使用PROD),如下所示:
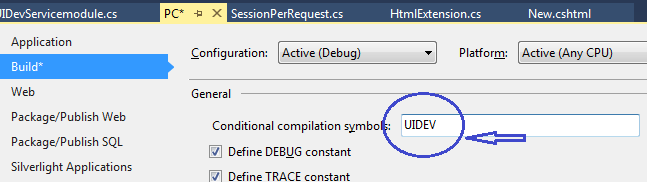
那么,这究竟是如何实现的呢?
总体上来说,我们借用了autofac这个类库,实现了所谓的"依赖倒置"
所以,在MVC的Controller中,我们只使用ServiceInterface而不管其具体实现,如下所示:
private IAuthroizationService _authService;
public AuthController(IAuthroizationService authService)
{
_authService = authService;
}
最后,在Global.asax.cs中我们通过条件编译符if...else来确定究竟使用哪一种Service实现:ProdServiceModule,或者UIDevServicemodule
void ResolveDependency()
{
var builder = new ContainerBuilder();
builder.RegisterControllers(Assembly.GetExecutingAssembly());
builder.RegisterFilterProvider();
#if PROD
builder.RegisterModule(new ProdServiceModule());
#endif
#if UIDEV
builder.RegisterModule(new UIDevServicemodule());
#endif
container = builder.Build();
DependencyResolver.SetResolver(new AutofacDependencyResolver(container));
}
最后,不要忘了,新引入一个Service时,在ProdServiceModule.cs或者UIDevServicemodule.cs中添加:
builder.RegisterType<RegisterService>().As<IRegisterService>();
这一章就差不多了吧。下一章我们再讲CurrentUser,并由此引出我们的原则:如何在View、Controller、Service和ViewModel之间划分逻辑(或者责任)。
CurrentUser,也就是当前用户,这是我们系统中大量使用的一个概念。
确认当前用户
当然,我们利用的是cookie:用户的ID存放在cookie中,服务器端通过cookie中的Id,查找数据库,得到需要的用户信息。
那么,这里就有一个安全问题,如何防止cookie的伪造或篡改?我们采用了以下方法:
首先,cookie中除了存放用户Id,还存放了一个加密过后的验证码,其来源如下:
- 未加密的验证码在用户生成时由系统随机产生,并存储在数据库中,如:287653;
- 它会被使用MD5加密成我们看不懂的字符串,如:
49b5f37dff119cf81fcb2b4e6077e17;
所以,当服务器端使用cookie中的用户Id时,会先检查加密过后的验证码是否有效。捏造的验证码是不会通过审核的。
还有一点需要说明的是,我们不考虑一个有效的cookie(连同验证码)被盗窃的情形。因为这就相当于你的电脑被别人使用了一样,我们确实无法判断使用你电脑的是不是你本人。
为什么没有使用session
可能有同学会想到,每次取cookie再查数据库,是不是会增加数据库负担,为什么不考虑session呢?两个方面的原因:
- session有定时清理机制。不管时间长短,session总有可能被清理掉的时候,这个时候不能让用户再重新登录啊!多麻烦,是不是?你可以if(session["userInfo"]== null),再通过cookie取数据再装到session里,但何苦呢?
- session难以同步更新,维护起来非常麻烦。比如当前用户发表一篇文章,积分增加了,你就得既改session又改数据库,这个同步过程是比较容易出问题的。
- 上面两个问题,NHiernate的cache已经做得很好了,不会增加数据库负担,这个以后会讲。
CurrentUser的ViewModel
CurrentUser最麻烦的一件事情是:很多页面是根据不同的当前用户,显示不同的内容的。以"任务编辑"页面为例,当前用户是该任务的发布人,发布栏可编辑;否则,发布栏仅仅是可读的。
所以,最初我们的方案很简单,也封装一个CurrentUserModel就可以了呀!
但后来我们发现:
- 需要判断的东西越来越多,比如还要判断当前用户是不是管理员、当前用户有没有验收权限、当前用户的上一次操作……把这些所有的信息都装到一个ViewModel里肯定是不合适的。怎么办呢?想到的自然就是拆分类,但CurrentUser还怎么拆分呢?
- 页面的判断逻辑也变得复杂起来,比如当前用户有没有某种权限得查他的申请历史和批准情况,并且还得看当前文章是那种类型及其作者的权限等。这些大段大段的逻辑就写在View里面么?关键是有些数据是单个View取不到的,需要从其他地方(比如url parameter中)获取,这些都进一步的增加了复杂性。让我们不得不考虑,我们是不是应该把这些逻辑移到Controller中,然后直接将结果告诉View,保持View的干净清爽?
在MVC架构中,Controller将Model传递给View,其实可能有两种情况:
- View直接呈现Model的数据,比如直接显示CurrentUser的用户名
- View还可以利用Model中的数据进行运算,然后予以呈现,比如比较CurrentUser和当前任务的承接人
我曾经计划禁止掉第2种情形,也就是说:在View里面不需要任何计算,只负责呈现。用代码表示就是:
@if (Model.CurrentUserIsAccepter)
{
//CurrentUserIsAccepter的值在controller中获取
}
而不是之前的:
@if (Model.CurrentUser.Id == Model.Accepter.Id)
{
}
但我们最终放弃了,因为实现起来太臃肿了。我们可以想象,这样的话,我们首先就至少需要三个Is属性:
public class EditModel
{
public bool IsAccepter { get; set; }
public bool IsOwner { get; set; }
public bool IsPublisher { get; set; }
}
有点怪,但好像还可以接受,但后来情况发生了变化,我们还得考虑当前用户即是发布人又是承接人,或者即是承接人又是验收人,或者既是……又是……的情形:
public class EditModel
{
public bool IsAccepter { get; set; }
public bool IsOwner { get; set; }
public bool IsPublisher { get; set; }
public bool IsBothAccepterAndOwner { get; set; }
public bool IsBothAccepterAndPublisher { get; set; }
public bool IsBothPublisherAndOwner { get; set; }
//......
}
这代码给人的感觉就是有病了。关键是,谁知道以后还来不来一个"是…和…但不是……"的逻辑呢?到时候又该怎么办呢?
//任务编辑页面(/Task/Edit/{taskId})是一个页面呈现逻辑比较复杂的典型例子,我们前后大改了三次,才形成今天所使用的代码格局。
//我以前说我带的一个妹纸看着代码哭,哭的就是这里,呵呵
//有兴趣的同学可以研究一下。
所以,取巧是不行了,我们还是得面对这个问题:
如何划分Controller和View之间的逻辑/责任?
更直白一点的讲,哪些事该Controller做,哪些事该View做?这个问题真的超级虐心。我想来想去,只能说:"能Controller做的,尽量让Controller做"。我自己对这个问题都相当不满意,但实在是没有办法啦。
具体到CurrentUser的ViewModel,我们提出以下两个原则:
- 不包含需要和其他对象交互运算才能得到的数据,比如当前用户是不是当前任务的发布人,需要和"当前任务的发布人"做比较,就不能包含进来
- 只能是需要多个View共用的数据,才能放进来。比如用户名,很多View都需要,就放进来好了。
为什么需要明确这些原则
可能你耐着性子看了上面的分析,最后却只得到一个似是而非又蛋疼的原则,会忍不住的问,"为什么一定需要/讲解这些原则?让程序员根据实际情况,自由发挥,不行么?"
浅层次的原因是要保证代码的可读性。阅读别人的代码是一件非常累的事情。但如果所有的代码都像一个人写的,而且这个人的思路自始至终都是非常清晰的,这样,我们会稍稍轻松一点。代码不是文学作品,在绝大多数情况下,不能天马行空自由发挥!
我们很多开发人员都已经开始注意代码的规范,但大多数还停留在缩进、换行、命名之类的细节(当然,这些也很重要)上;而架构师应站在一个更全局的高度,来"规范"所有的开发行为。
所以,其实更深层次的原因是:所有的代码都必须规范化。既然要规范化,那么首先就要有规范!先可以不管好坏,但至少要有。那么怎么制定完善这个规范呢?我分享一下我的经验:
- 按规范文档,做入职培训,培训可以着重讲道理,强化开发人员代码规范化的思维;
- 所有代码都必须review。review要往"挑刺"的方向靠,所以不规范的代码其实是很容易被发现的;
- 开发人员不服review的结果,review的人员要拿出依据(规范文档)来;
- 规范文档中如果还没有相关的规定,立即补充,并照此执行,包括改正以前不合规范的代码
这样不断的迭代,基本上就能不断的提高代码的规范性,并得到一份不错的规范文档。
好像写跑题了,又是项目管理方向的东西。就先这样吧!前台的架构,想想,剩下的应该就是单元测试(都还没做,所以暂时也讲不了),还有可能其他一些细节了,以后查漏补缺吧。接下来希望参与到项目的前台开发的同学就可以开始联系我了。博客系列我们将接着讲Service层。
原文出处:架构之路(九)Session Per Request
前面的两篇反应很差:没评论没赞。很伤心啊,为什么呢?搞得我好长一段时间都没更新了---- 呵呵,好吧,我承认,这只是我的借口。不过,还是希望大家多给反馈。__没有反馈,我就只能猜了:前面两篇是不是写得太"粗"了一点?所以这一篇我们尽量详细点吧。
Session Per Request是什么
这是一个使用NHibernate构建Web项目惯用的模式,相关的文章其实很多。我尽量用我的语言(意思是大白话,但可能不精确)来做一个简单的解释。
首先,你得明白什么是session。这不是ASP.NET里面的那个session,初学者在这一点上容易犯晕。这是NHibernate的概念。
- 如果你对它特别感兴趣的话,你可以首先搜索"Unit Of Work"关键字,了解这个模式;然后逐步明白:session其实是NHibernate对Unit Of Work的实现。
- 如果你只想了解一个大概,那么你可以把它想象成一个临时的"容器",装载着从数据库取出来的entity,并一直记录其变化。
- 如果你还是觉得晕乎,就先把它当成一个打开的、活动的数据库连接吧。
我们都知道数据库连接的开销是很大的,为此.NET还特别引入了"连接池"的概念。所以,如果能有效的降低数据库的连接数量,对程序的性能将有一个巨大的提升作用。经 过观察和思考,大家(我不知道究竟是谁最先提出这个概念的)觉得,一个HTTP request分配一个数据库连接是一个很不错的方案。于是Session Per Request就迅速流行起来,几乎成为NHibernate构建Web程序的标配。
为什么又要考虑性能了
我《性能》篇发布了以后,虽然赞数很多,但评论区中争议也还是很大的。但一是评论区后来歪楼了,二是一句话翻来覆去的讲太没意思了,所以我没有再分辨。但Session PerRequest就是一个很好的例子,可以说明什么叫做"性能让位于可维护性":
- 如果为了性能,破坏了代码的可维护性,那么我们宁愿不要性能;
- 在能够保证可维护性的前提下,我们当然应该努力的提高性能;
- 较之于在局部(非性能瓶颈处)纠结发力,不如在架构的层面上保证/促进整体性能的提高。
我说提到的"性能的问题先不管",以及"忘记数据库"等,是基于矫枉必须过正的出发点,希望能够有振聋发聩的效果。但结果看来不是很好,评论里我还是 看到了"SELECT TOP 1 * FROM TABLE WHERE ID>CURRRID"之类的东西。这说明什么?关系数据库不但已经在你脑子里扎根,而且 已经把你脑子都塞满了。不是说这样不行,只是这样的话,实在没办法和你谈论面向"对象"。
Session Per Request就是一个已经被广泛采用,行之有效的,能在架构层面提升性能的一个设计。
#
UI还是Service
我们仅从Session Per Request的定义,什么Http啊,Request啊,凭直觉就能想到UI层的范畴吧?
网上的很多示例都确实是这么写的。在Application里BuildSessionFactory,在HttpModule中配置:一旦HTTP request到达,就生成一个session;Http request结束,就调用session.flush()同步所有更改。
但是,我们在架构中就已经确立了这样一个原则:UI层不涉及数据库操作。更直观的看,UI层的project连NHibernate.dll的引用都没有。那怎么办呢 ?
现在想来很好笑,当年我可是费了不少的脑细胞:其实只需要在Service层封装相关的操作,然后在UI层调用Service层即可。
那些把我绕晕了的不靠谱的想法大家可以不用去理会了。如果确实有兴趣,可以思考一下:NHibernate中session是有上下文环境(context)的,我们 这里当然应该设置成web,但Service最后会被编译成一个dll,这个dll里能取到HttpContext么?
但在Service里怎么封装,也是一件值得斟酌的事。
变异,些许的性能提高
我最后采用的方案是引入BaseService:
首先,在BaseService中设置一个静态的sessionFactory;而且,在BaseService的静态构造函数中给sessionFactory赋值 (Build SessionFactory)。这样,就可以保证SessionFactory只生成一次,因为生成SessionFactory是一个开销很大的过程。
public class BaseService
{
private static ISessionFactory sessionFactory;
static BaseService()
{
string connStr = ConfigurationManager.ConnectionStrings["dev"].ConnectionString;
sessionFactory = Fluently.Configure()
.Database(
MySQLConfiguration.Standard.ConnectionString(connStr).Dialect<MySQL5Dialect>())
.Mappings(ConfigurationProvider.Action)
.Cache(x => x.UseSecondLevelCache().ProviderClass<SysCacheProvider>())
.ExposeConfiguration(
c => c.SetProperty(NHibernate.Cfg.Environment.CurrentSessionContextClass, "web"))
.BuildSessionFactory();
}
引入sessionFactory
其次,在BaseService中暴露一个静态的EndSession()方法,在Request结束时将数据的变化同步到持久层(数据库)。所以当UI层调用时,不 需要实例化一个BaseService,只需要BaseService直接调用即可:
public class BaseService
{
public static void EndSession()
{
}
}
EndSession
然后,我们回头看看前面的说法:"一旦HTTP request到达,就生成一个session;",所以理论上需要一个InitSession()的方法,生成/提供一个session。但我突然有了点小聪明:有些页面可能是不需要数据库操作的,比如帮助、表单呈现,或者其他我们暂时想不到的页面。那我们无论如何总是生成一个session,是不是浪费了点?
越想越觉得是这么一回事,所以左思右想,弄出了一个方案:按需生成session。大致的流程是:
- 尝试获取session;
- 如果"当前环境"中已有一个session,就直接使用该session;
- 否则就生成一个session,使用该session,并将其存入当前环境中。
看来NHibernate支持这种思路,所以提供了现成的接口,可以很方便的实现上述思路:
protected ISession session
{
get
{
ISession _session;
if (!CurrentSessionContext.HasBind(sessionFactory))
{
_session = sessionFactory.OpenSession();
CurrentSessionContext.Bind(_session);
}
else
{
_session = sessionFactory.GetCurrentSession();
}
return _session;
}
}
按需获取session
其中CurrentSessionContext就是上文所谓的"当前环境",在我们的系统中国就是一个HttpContext;我们使用GetCurrentSession()就总是能够保证取出的session是当前HttpContext中已有的session。所有的Service都继承自BaseService,直接调用BaseService中的session,这样就可以有效的保证了Session Per Request的实现。
同学们,这下知道了吧?其实我骨子里还是一个很"抠"性能的人。但这样做究竟值不值?我也不太确定,毕竟这样做一定程度上增加了代码的复杂性,而所获得的性能提升其实有限。
总是使用显性事务
如果同学们查看源代码,就会发现,我们的session总是启用了事务。
protected ISession session
{
get
{
//......
if (!_session.Transaction.IsActive)
{
_session.BeginTransaction();
}
return _session;
}
}
public static void EndSession()
{
if (CurrentSessionContext.HasBind(sessionFactory))
{
//.......
using (sessionFromContext.Transaction)
{
try
{
sessionFromContext.Transaction.Commit();
}
catch (Exception)
{
sessionFromContext.Transaction.Rollback();
throw;
}
}
}
}
总是使用事务
在我们传统的观念中,使用"transaction",会增加数据库的开销,降低性能。但实际上并不是这样的,至少我可以保证在NHibernate和Mysql中不是这样的。
大致的原因有几点:
- 即使不显式的声明事务,数据库也会显式的生成一个事务;
- NHibernate的二级缓存需要事务做保证
详细的介绍请参考:Use of implicit transactions is discouraged
其实,既然使用了Session PerRequest模式,我们即使从业务逻辑上考虑,也应该总是使用"事务":很多时候一次表单提交要执行多个数据库操作,一些步骤执行了一些报了异常,数据不完整咋办?
没有Session.Save()和Update()
前面已经反复说过,在Service中,没有数据库的Update操作。我们是通过:Load()数据 -> 改变其属性 ->然后在Save()到数据库来实现的。
但同学们查看我们的源代码的时候会发现:"咦?怎么没有Session.Save()这样一个过程?"
首先,大家应该了解NHibernat中的Update()不是我们大多数同学想象的那样,对应着sql里的update语句。它实际上用于多个session交互时的场景,我们目前的系统是永远不会使用的。
然后,NHibernate也不是使用session.Save()来同步session中的数据到数据库的。我们系统中只是偶尔使用session.Save()来暂时的获得entity的Id。
最后,NHibernate中实际上是使用session.Flush()来最终"同步"内存(session)中的数据到数据库的。而我们代码中使用的是session.Transaction.Commit(),这会自动的调用session.Flush()。
因为Session Per Request模式,我们在UI层中,总是会在request结束时调用EndSession(),所以在Service的代码中,看起来就没有了"存储"数据的过程。
UI层的调用
那么,在UI层的哪里调用EndSession()呢?(因为按需生成session,已经不需要BeginSession()了)
大致来说,有两种方案,一种是使用HttpModule,另一种是利用ASP.NET MVC的filter机制。
我们采用了后者,一则是这样更简单,另一方面是因为:当引入ChildAction之后,从逻辑上讲,Session PerAction更自洽一些。比如一个Request可能包含多个Child Action,将多个ChildAction放在一个session里,可能出现难以预料的意外情况。
当然,这样做的不利的一面就是会消耗更多的session,但好在session的开销很小,而且我们使用的"按需生成session"可以降低一些session生成情景。
代码非常简单,如下:
public class SessionPerRequest : ActionFilterAttribute
{
public override void OnResultExecuted(ResultExecutedContext filterContext)
{
#if PROD
FFLTask.SRV.ProdService.BaseService.EndSession();
#endif
base.OnResultExecuted(filterContext);
}
}
调用EndSession()
if
PROD的使用是为了前后端分离(后文详述):只有当调用ProdService时才使用以上代码,UI开发人员使用UIDevService时不需要改项操作。
同时,为了避免反复的声明,我们提取出BaseController,由所有Controller继承,并BaseController上声明SessionPerRequest即可:
[SessionPerRequest]
public class BaseController : Controller
{
}
SessionPerRequest声明
其他
由于我们在Action呈现后实现数据的同步(session.Transaction.Commit()),所以我们所有的Ajax调用,没有使用WebAPI,而是继承自ActionResult的JsonResult。否则,不会触发OnResultExecuted事件,也无法同步数据库。
public JsonResult GetTask(int taskId)
{
string title = _taskService.GetTitle(taskId);
return Json(new { Title = title });
}
AJAX返回JsonResult
综上,我们实际上是借鉴了SessionPerRequest的思路,实际上采用了按需生成Session、且一个Action使用一个session的实现。可以描述成:SessionPerActionIfRequire,呵呵。
通过SessionPerRequest,我们可以发现架构的一个重要作用:将系统中"技术复杂"的部分封装起来,让开发人员可以脱离复杂琐碎的技术,而专注于具体业务的实现。事实上,采用我们的系统,即使一个不怎么懂NHibernate的普通开发人员,经过简单的介绍/培训,也可以迅速的开始业务领域代码的编写工作。
+++++++++++++++++++++++++++++
应该是2016年春节前最后一篇《架构之路》的更新了,先预祝大家新春快乐,万事如意!
另外,欢迎各种留言评论(包括拍砖)。
O(∩_∩)O~