Java源码分析系列
原文出处:Java源码分析之HashMap和SparseArray
Java源码分析之HashMap和SparseArray
SparseArray是Google为了提高性能替换HashMap
HashMap是hash函数+拉链法实现,SparseArray则使用的是有序数组+二分查找实现。HashMap的性能影响主要体现:占用内存过大,插入过程内存动态增长的扩容操作代价,hash冲突时的链表遍历。SparseArray的性能影响主要体现:查找时的二分查找,插入时为了维护有序数组的数组的移位操作。
性能对比:
1,内存占用
插入100万条数据,SparseArray占内存40M,HashMap占内存80M,一倍的差距
2,升序插入
插入100万条数据,插入的数值是升序的,SparseArray耗时1.1秒,HashMap耗时2.0秒,看起来还不错,后面分析源码的时候会解释,如果是升序的,那么SparseArray基本没有维护有序数组的开销,所以升序的时候,SparseArray性能是最好的。
3,降序插入
插入10万条数据,插入的数值是降序的,SparseArray耗时25.0秒,HashMap耗时0.2秒,性能差100倍,降序是SparseArray的最差效果,相当于每次插入,都必须对整个数组做拷贝。
4,随机插入
插入10万条数据,插入的数值是随机序的,SparseArray耗时10.5秒,HashMap耗时0.27秒,性能差50倍,差距正好介于升序和降序之间。所以如果你的key值插入如果是接近于升序的话,那么用SparseArray的性能是极好的。HashMap是hash算法,和key的值大小并无相关,所以不管key是什么样的顺序,耗时都差不多。
5,查询操作
100万次查询,SparseArray耗时300毫秒左右,HashMap耗时1000毫秒左右,HashMap是SparseArray的3倍。这是因为SparseArray的查询就是二分,而HashMap由于有内存限制,所以会导致出现hash冲突,拉链法占了些时间,所以虽然理论上HashMap是O(1)的,实际上比二分要差,如果内存足够的话会逼近O(1)
数据分析完毕,我们来分析HashMap和SparseArray的源码,解释一下以上出现的现象。先从HashMap入手:
HashMap的核心数据结构是HashMapEntry
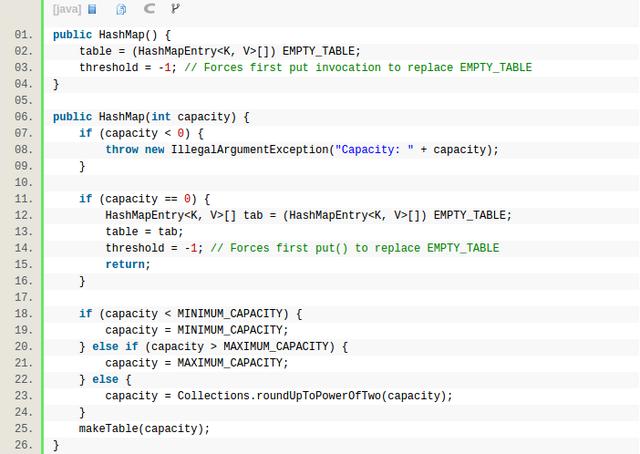
makeTable除了新建capacity大小的table数组之外,还会将threshold设置为3/4的capicity,threshold是一个阈值,当HashMap的size达到这个阈值以后,就会调用doubleCapacity函数对HashMap进行扩容,顾名思义capacity增长一倍,扩容会将当前的table的数据copy到新的table里。扩容是比较耗时的,需要避免扩容的次数。
doubleCapacity的源码我们稍后再分析,先看HashMap的基本操作get/put/remove。先看put操作:
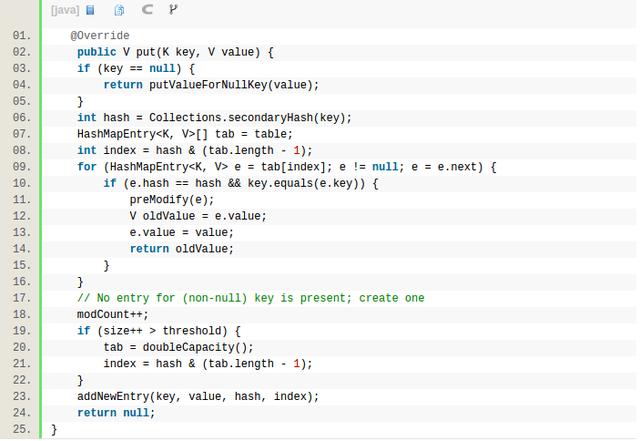
首先调用Collections.secondaryHash函数计算key的hash值,secondaryHash函数就不分析了,就是用key的hashcode计算hash值。接着通过hash值来计算桶的下标index = hash & (tab.length - 1),从这也可以看出capacity越大,hash冲突的可能性就越小,复杂度也会越逼近O(1)。capacity的值一定是2的幂次,所以hash和tab.length - 1的与,其实就等于求模,所以index的大小是 < tab.length的,去index号的桶,里面放了hash冲突的entry的链表,再遍历该key的entry是否存在,存在则用新的value替换oldValue,不存在则新增进链表。每次push的时候,如果新增一个entry,size会自增,需要判断是否超过threshold,超过则需要doubleCapacity。
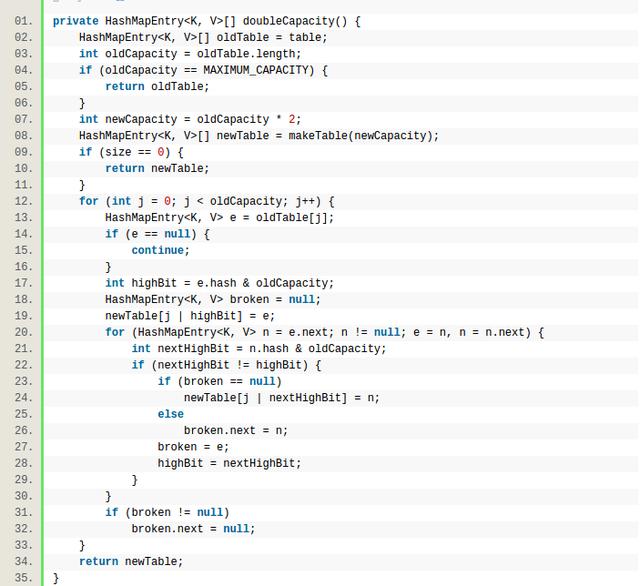
MAXIMUM_CAPACITY是最大的capacity,超过就不增了。否则newCapacity就增长一倍,增长之后,还需要把oldTable的entry都copy到newTable,所以需要遍历oldTable, for (int j = 0; j < oldCapacity;j++),对每个桶的所有entry,做重新hash。因为capacity变了,而之前entry的index由hash & (capacity - 1)也会变,新的newTable的index算法如下:由于newCapacity是增长一倍,newTable的index相当于比oldTable的index增加了一个最高位,而e.hash & oldCapacity其实就是拿到最高位,因此j|nextHighBit就是newTable的index,同理对这个桶的链表都做rehash。由此可见doubleCapacity相当于对所有entry都遍历了一遍。同样HashMap有ensureCapacity函数,可以提前申请内存,这样能减少doubleCapacity的次数。
接着看HashMap.get函数的实现:

看了put,再看get,就相当简单,直接计算hash,并根据hash & (tab.length - 1)来查找链表项。get的性能完全取决于hash的冲突率,冲突得越多,就表示链表项越多,耗时也就越多。而冲突率主要是看hash函数的均匀性,entry的个数为size,而size是小于< threshold的,threshold是capacity的3/4,所以entry的个数是小于当前的table数组大小,一来浪费了内存,另一方面增加了额外的链表遍历。从另一个角度看的话,HashMap理论上完成可以做到无冲突,这完全取决于hash函数,如果能设计个牛逼的hash函数,既可以降低内存使用,也同时提升了查询的性能。由之前 的数据可知,HashMap的内存占用比SparseArray多一倍,查询的性能也是SparseArray的三倍。
最后分析remove函数:
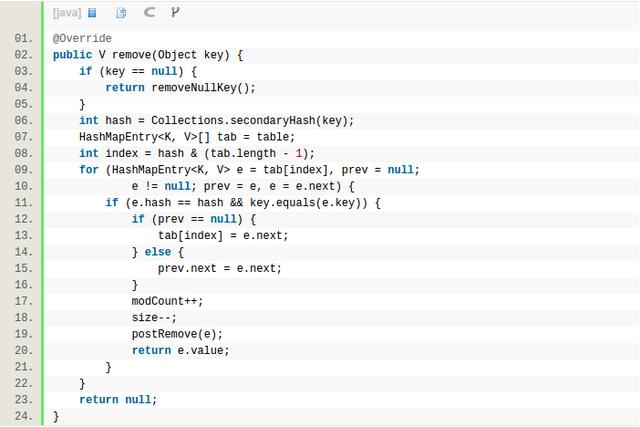
HashMap的remove操作和get差不多,只不过查询到之后会把entry从链表里移除,并对size自减1,而HashMap的table内存并不调整,因此HashMap一旦涨了内存,就降不下来了。
分析完了HashMap,我们再看SparseArray,SparseArray的key和value是分两个数组存放的,int[]mKeys,Object[] mValues。mKeys是个有序的数组,mKeys的下标和mValues的下标是对应的,比如entry(key = 3,value = 1),3在mKey的下标是5,那么mValues[5]的值就是value = 1。构造函数就不说了,可以设置初始容量。我们先看put操作:
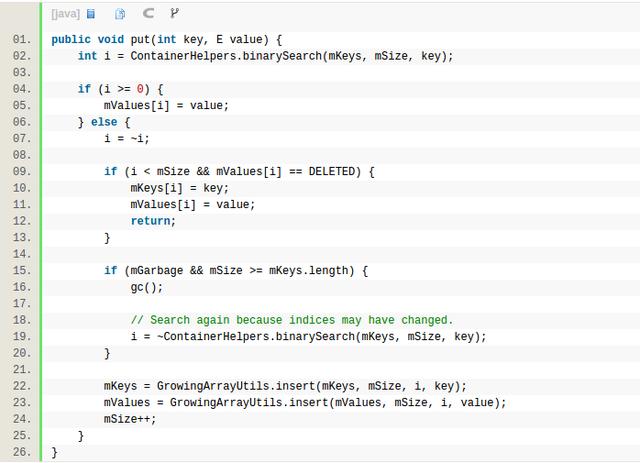
首先二分查找key值在mKeys的下标,如果命中那么直接对mValues赋值。如果没找到,ContainerHelpers.binarySearch没找到的情况下,返回的值取反,刚好是将要插入的位置,如果这个将要插入的位置是空的(DELETED),那么可以直接复用,否则就需要调用 GrowingArrayUtils.insert和GrowingArrayUtils.insert插入新的key和value,插入的时候,如果数组的capacity不够了,同样是按照double来扩容,同时使用System.arraycopy来移数组,从而保证mKeys还是升序数组。从这就可以解释之前的性能测试结果,如果插入顺序也是升序的话,那么插入的位置就在最后,就可以省了System.arraycopy,如果是降序的话,那么每次插入都在第一个,那么每次都对整个数组做移动。SparseArray还有一个append函数,他对key比mKeys的所有元素都大的插入case做了优化,省了无用的binarySearch。综上,SparseArray对于插入非常频繁的场景,其实并不太适合。
SparseArray.get:
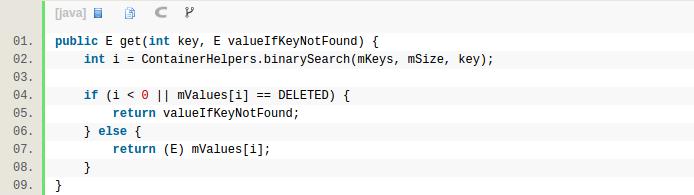
get简单,就是一次二分查找。
SparseArray.delete:
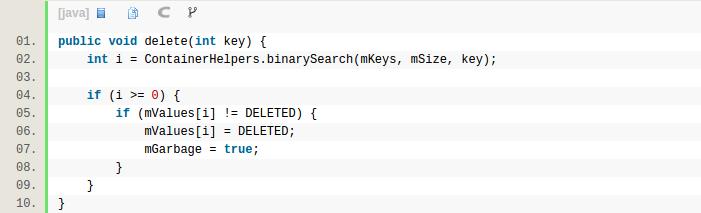
delete同样就一次binarySearch,delete操作做了lazy delete,先置DELETED标识位,等到entry的size大于mKeys数组的大小的时候,就可以把标识为DELETED的entry删除了。
总结:
SparseArray在内存占用、查询、删除方面,有比较好的性能,但在于插入方面表现较差。
HashMap主要问题在于内存使用上,在查询、删除、插入上的性能比较均衡。如果要再提升性能只能设计更牛逼的hash函数。
原文出处:Java源码分析之ArrayList和LinkedList
Java源码分析之ArrayList和LinkedList
开发过程中,总会使用各种类库,如ArrayList,LinkedList等,用得虽多,但对于其实现细节却了解甚少,我们从源码的角度分析一下各种Java类库的实现细节。
List是个接口,其继承自Collection<?>,标准接口咱就不说了,List的实现有两个,ArrayList和LinkedList,前者是数组实现,后者是链表。
ArrayList只有两个成员变量array,size。array是个Object[] 表示List的元素数组,size是元素个数,这里可能有人要问,Object[]不是自带length吗,为什么还需要个size呢?这是为了提高ArrayList的add性能,数组的内存空间会比实际List的元素的个数大,这样在add的时候,不用每次都重新分配内存,并进行arraycopy。
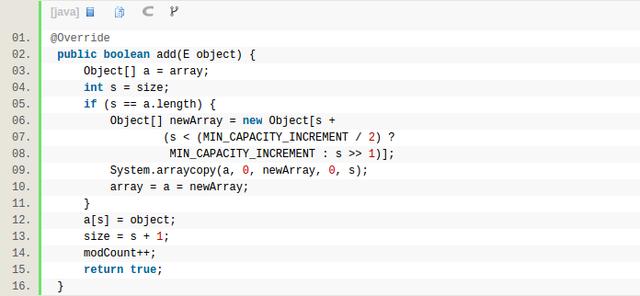
以上就是ArrayList的add函数源码,如果当前的元素的个数已经达到数组内存的大小,那么当前这个待add的object就没有空间了,所以需要扩容,ArrayList的扩容的算法是当前的size 的 2倍,为了避免元素少的时候增长太慢,于是设置了一个最小的扩容值12(MIN_CAPACITY_INCREMENT),也就是说如果当前size如果是1的话,那么ArrayList add之后,array的内存大小就扩大到12,而不是1 × 2。这是add到最后的情况,那么如果是add到某个指定位置 add(int index, E object)呢?
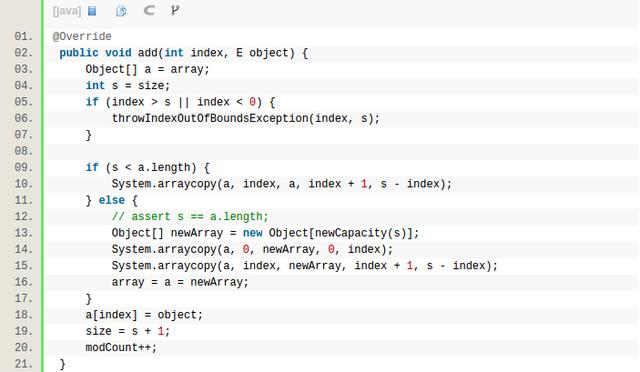
从上面的代码可以看出,如果当前元素的size还未达到内存的上限(s < a.length),那么要做的就是arraycopy,其时间复杂度可是O(n),越往前插越慢。而如果当前元素的size达到上限,那么先需要扩容,然后再挪内存。由此看来,如果你的需求有很多的往数组中间插入的操作,那么ArrayList的性能会比较差,应尽量避免这种操作。
这是add单个元素的情况,对于addAll添加一个数组的情况也是一样的逻辑,添加之后元素的个数是newSize = s + newPartSize,如果newSize没有超过内存上限,就只需要arrayCopy先挪内存元素,以便新的Collection的元素都能插入进来。否则先扩容,新的size为newCapacity函数给出,这时候的算法并不是翻倍,而是newSize的基础上增加50%,这主要是避免扩容扩太快。
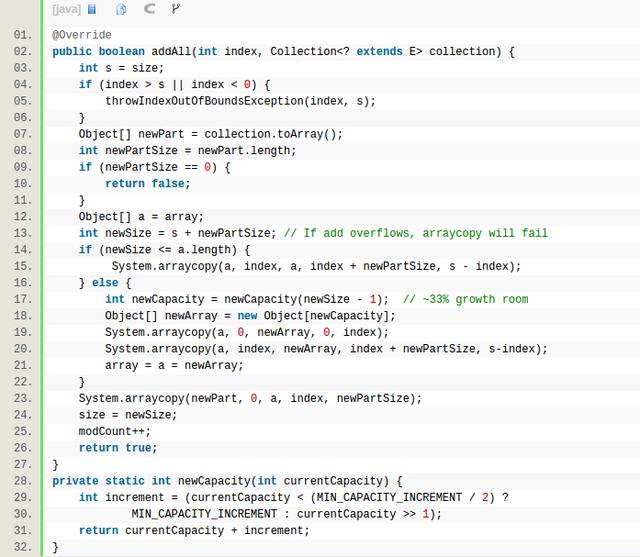
可见ArrayList的容量是动态扩展的,有时为了避免扩容造成的性能损失,可以先调用ensureCapacity来提前分配内存,这种方法主要适用于对自己未来的内存占用量有个提前预估。
以上是add的情况,remove的操作则会更加简单一些,remove由于内存没有扩容,因此和add比,没有扩容部分,只有挪元素的部分。
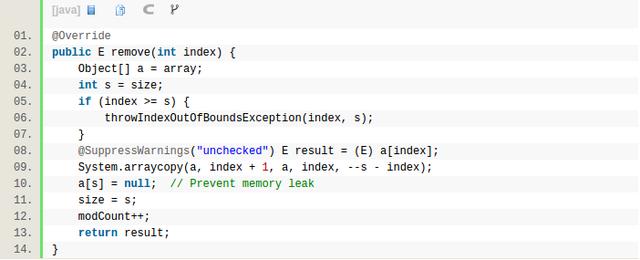
先把[index + 1, s)的元素前移。a[s] = null的目的是避免hold住前移之前的最后一个元素的对象,从而后续造成内存泄漏。同理,ArrayList的clear函数,除了只把size置0之外,还需要把array的元素置空,从这个角度看,clear的时间复杂度其实是O(n)的。
以上便是ArrayList的实现细节,是不是很简单。
LinkedList是链表实现的,他也有两个成员变量,voidLink,size。voidLink是个Link对象,表示链表的表头,size则是元素大小,size的目的主要是优化LinkedList.size函数,不用每次都遍历链表来数个数。
LinkedList的Link是个双链表,有next也有previous,双链表比单链表好处是删除方便,单链表的删除需要找到他的previous,不好的地方就是多了一个previous对象,多占了内存。LinkedList的链表还是个循环列表,voidLink表头的previous是指向最后一个元素的,目的是了add操作,链表没法随机访问,如果不是循环链表的话,那么就需要遍历整个链表,找到最后一个节点,才能插入。
我们看一下LinkedList的几个基本函数:

get函数是随机访问,这个不是链表的长处。如果是前半部分,那么就从表头开始往后找,如果是后半部分,就从表头往前找。所以如果你的使用场景是随机访问比较多的话,建议用ArrayList,而不是LinkedList,LinkedList适合那种插入操作比较多的场景。另外一个注意的地方就是,遍历的时候,LinkedList千万别用for + get实现,这样复杂度非常高,需要用iterator来实现。
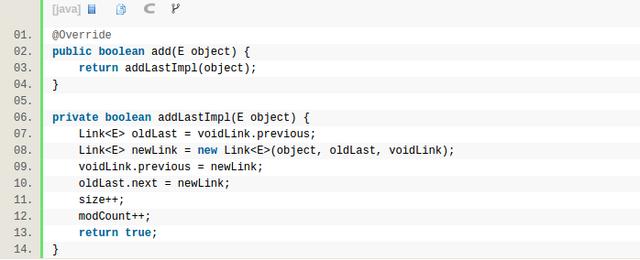
这是LinkedList添加元素到最后的实现,链表很方便,O(1),同理addFirst也一样。往中间插就不一样了,如下,需要先找到location所在的节点。虽然都是O(n),但LinkedList这个复杂度比ArrayList的System.arraycopy要高,ArrayList挪内存用的arraycopy是native实现的,并且是连续内存,是有优化的。
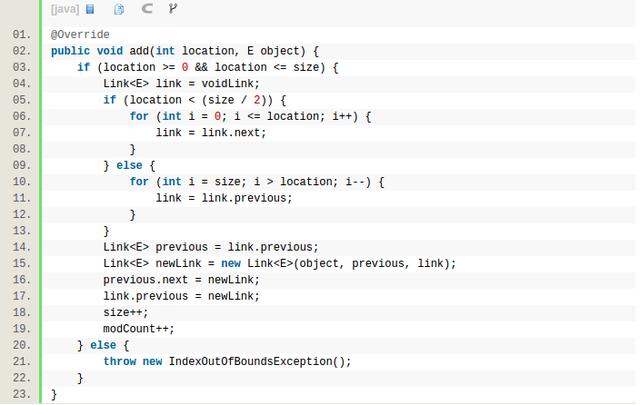
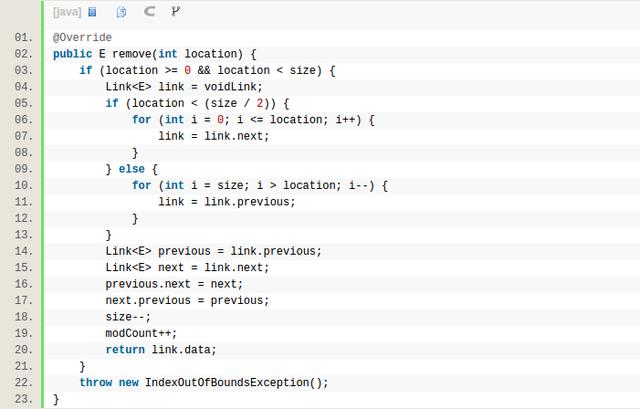
LinkedList的remove需要先找到节点,比如remove(int location),需要先找到这个元素,然后删除。remove(Object object)也是一样的,两种case都是随机删除,这都不是LinkedList擅长的,如果如果你的使用场景,如果是这种随机插入、删除的场景特别多的话,那么LinkedList是不适合的。
细心的读者可能发现了,不管是ArrayList还是LinkedList都有一个modCount字段,这个是用来干什么的呢?
LinkedList和ArrayList都不是线程安全的,modCount在每次元素有改动的时候都会++,这个就是为了检查是否有改动,而使用的地方就是在Iterator里,不管是ArrayList还是ArrayList都实现自己的Iterator,用来遍历数组的元素。在每次Interator实例化的时候,也就是准备遍历数组元素的时候,都会保存当前的modCount到迭代器的expectedModCount字段,然后在做遍历操作的时候,会检查expectedModCount和modCount的值,如果这个值不一样,就说明有其他线程在这次遍历期间,对List的元素做过改动,就会抛出ConcurrentModificationException异常,用来提示多线程竞争了。ConcurrentModificationException是不是很熟悉,如果你遇到这个异常,就说明在多个线程里对一个线程不安全的容器做了改动,很可能会造成数据的不一致,不止是ArrayList、LinkedList,HashMap、Hashtable都一样,都是在使用了迭代器的时候会碰到这个异常。