GFS、Mapreduce、Bigtable、Chubby
博客地址:GFS、Mapreduce、Bigtable、Chubby
1. Introduction
本文是读GFS论文的总结,收录在我的github中papers项目,papers项目旨在学习和总结分布式系统相关的论文。
全文主要分为以下几方面:
- Design Motivation
- Architecture
- System Interactions
- Master Operation
- Fault Tolerance and Diagnose
- Discussion
2. Design Motivation
google对现有系统的运行状态以及应用系统进行总结,抽象出对文件系统的需求,主要分为以下几个方面。
- 普通商用的机器硬件发生故障是常态
- 存储的问题普遍比较大,几个G的文件很常见
- 大部分的文件操作都是在追加数据,覆盖原来写入的数据的情况比较少见,随机写几乎不存在
- 读操作主要包括两种,large streaming read和small random read
- 为了应用使用方便,多客户端并行地追加同一个文件需要非常高效
- 带宽的重要性大于时延,目标应用是高速读大块数据的应用,对响应时间没有过多的需求
3. Architecture
本部分讨论gfs的总体架构,以及在此架构上需要考虑的一些问题。
3.1 Overview
GFS的整体架构如下图:
->string
如上所示,key为row:string, column:string, time:int64, value为string
以一个例子来说明该映射关系,如下图:

如上图所示,表名为WebTable,以URL为row key,网页各方面属性为column name,其中网页内容存储在contents:列中,通过时间戳可以区分列的数据版本。
2.1 Rows
Row key可以是任意的字符串,大小不超过64KB。每次针对单行的操作都是原子操作。
Bigtable按照row key的字典序对数据排序,每张表按照row key的排序范围动态划分。每个划分的row范围称作是tablet,是数据分布和负载均衡的单元。客户端可以根据这个特性,来把需要一起读的数据尽可能的安排在一起。例如,对于WebTable,如果需要同一个域名下的网页尽量放在一起的话,可以把域名maps.google.com/index.html按照row keycom.google.maps/index.html来存储。
2.2 Column Families
Column Key按照column family分组存储,访问控制信息也是按照column family为单元来设置的。一般来讲,期望的是所有存储在column family的列的数据类型是一样的,因为bigtable是按照column family进行压缩的。
在进行列存储前,column family必须要先创建,一旦创建好,任何在此family下的column key都可以使用。bigtable期望的是一张表的column family的schema几乎是不变的,且一张表的column family数量较小(最多几百个),但是,列的数量是无限制的。
Column key的表现形式为family:qualifier,对于family必须是可打印的字符串,对于qualifier可以是任意的字符串。以column faimilyanchor为例,每个column key都代表一个anchor,例如anchor:cnnsi.com。
2.3 Timestamp
Bigtable会对每个单元格的数据存储多个版本,版本按照时间戳排序。Bigtable timestamp是64位整数,可以由bigtable内部生成或者client端指定。
为了方便client指定需要存储多少个版本的数据,bigtable可以针对每个column family来设置,例如可以设定只存储最新的n个版本或者最近n天的数据。
对于WebTable,timestamp为爬取网页内容的时间戳,设定为只存储最新三个版本的数据。
3. API
Bigtable API提供了创建和删除表、column family的API,还提供了设置集群、表、column family元数据的API,例如改变访问控制权限。
写和删除的例子

遍历数据的例子

4. Building Blocks
Bigtable使用了其他的一些系统来构建服务:
- 使用了GFS来存储日志和数据文件
- 集群管理系统来负责分配管理资源,监控机器状态等
4.1 SSTable
Bigtable底层使用SSTable文件格式来存储数据。一个SSTable是存储多个K/V数据,数据按照KEY排序并且不能修改。对SSTable可以执行的操作包括,按照指定Key查找,按照Key Range遍历。
在SSTable内部,包含一些列的block(一般每个block是64KB,但也是可以配置的),在SSTable的尾部存储了block的索引,方便快速查找Key在哪个block内。当SSTable文件打开时,是会把block的索引加载到内存中去的。对于一次查找一般会有一次磁盘开销,先从内存中定位到在哪个block,然后把block从磁盘中读出来。
4.2 Chubby
Bigtable里面另一个依赖比较重的服务是Chubby。Chubby是一个分布式的锁服务,一般五副本冗余存储,其中一个会被选为主,只要五副本中的大多数是正常状态,chubby就可以保持可用。
Chubby提供一个包含目录或文件的命名空间,每个目录或者文件都可以当作是锁服务来使用,对单个文件的读或者写都是原子的。Chubby Client Library提供Chubby文件的缓存,每个Chubby Client和Chubby服务端通过一个session保持链接。一个Client的Session会在其无法在lease过期时间内续约而到期。当一个Client的session到期后,它会丢失所有的锁和handle。Chubby client可以在文件或者目录下注册回调事件,当文件或目录发生变化是会通知相应的client。
在Bigtable中,使用到Chubby的地方如下:
- 发现tablet server和tablet server挂掉
- 存储bigtable schema信息,主要是column family信息,以及存储访问控制信息
备注:如果chubby挂掉或者chubby和bigtable之间通信断掉,那么bigtable服务将不可用。
5. Implementation
Bigtable中有三大组件,包括client,单master和许多的tablet server。可以根据负载的情况,动态的加入或者删除机器。
master的工作
- 分配tablet到tablet server
- 检测tablet server的加入和过期
- 均衡tablet server的负载
- garbage collection GFS中的文件
- schema变更,包括表和column family的创建等
由于master不存储tablet location信息,因此,client基本上从来不会与master通信,master不会成为系统的瓶颈。
tablet server的工作
- 管理一组tablet
- 处理tablet的读写请求
- 分裂过大的tablet
每个Bigtable集群存储多张表,每张表包含多个tablet。初始的时候,一张表只有一个tablet,当表数据量增加时,会自动分裂成多个tablet。
5.1 Tablet Location
tablet location采用三层的存储层次,如下图:
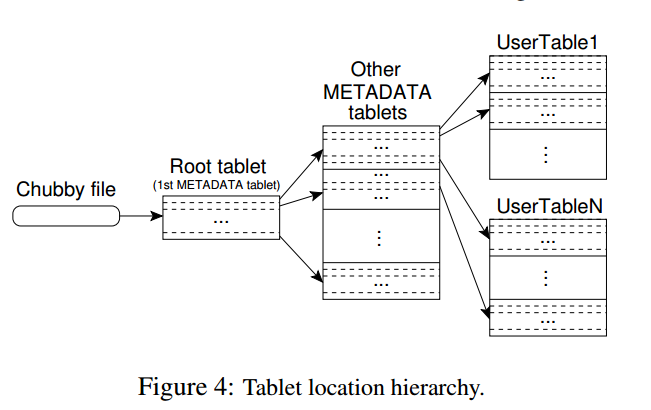
- Chubby file存储Root tablet的location
- Root tablet存储othter MetaData tablet的location,root tablet不能分裂,需要保证三层结构
- 每个Metadata tablet存储一组user tablet的location
Metadata tablet的每行存储user tablet的row range的开始行和结束行等信息。
对于Client端,会缓存tablet location。如果客户端发现它的tablet location为空或者不正确,会从最上层开始查找和比较。对于为空的情况,需要三次网络开销来读取信息;对于不正确的情况,最坏需要六次网络开销,因为可能对于三层结构都出错了,每次都要试一次错,再读一次正确的数据。为了提升性能,client端一次会预取多个tablet的location并缓存。
tablet location信息应该都是存储在tablet server上的。
5.2 Tablet Assignment
master负责跟踪活着的tablet server和tablet到tablet server的分配,包括哪些tablet没有分配。当一个tablet没有被分配,并且一个tablet server可以容纳下该tablet,master给该tablet server发送请求告诉其load该tablet。
问题:这里的sufficient room指的是什么指标?
Chubby用来跟踪tablet server状态
- 当一个tablet server启动的时候,它会在Chubby指定目录创建一个文件,并获取一把锁
- master通过监控目录来发现新加入的tablet server
- tablet server在锁丢失时停止服务
- 当其所创建的文件还存在的情况下,tablet server会尝试重新获取锁
- 如果其创键的文件不存在,tablet server会停止进程
- 当tablet server终止时,会释放锁,然后master可以跟快速的来重新分配tablet
master的工作
master的工作包括两方面
- 检测停止服务的tablet server
- 尽快的重新分配tablet到tablet server
master周期性和tablet server通信来询问其锁的状态,如果是
- tablet server汇报其已经丢失了锁
- master多次重试无法和tablet server通信,接着master尝试和chubby通信,获取该server的文件所,根据结果分为两种情况:第一是master可以获得锁,那么说明tablet server挂掉或者其与Chubby无法通信,那么,master可以确信它无法提供服务了,因此立即删除Chubby上的文件,然后,把这台tablet server上的tablet都设置成未分配状态;第二是master无法获得锁,说明master和Chubby通信有问题,master会停止进程。
问题:master重新分配tablet的时机是? 问题:为什么master不直接和tablet server维持租约? 问题:为什么master不直接看chubby上的锁状态来确定tablet server的状态?有可能tablet server和chubby可以连接,但master和tablet server连不上。
master启动时,需要先检测当前的tablet分配情况,然后才能改变分配情况,启动步骤如下
- 从Chubby获取唯一的
master的锁,防止出现多个master - master扫描Chubby指定目录,发现活的tablet server
- master和活的tablet server通信,来获取它们已经分配了哪些tablet
- master扫描metadata table,去获取所有的tablet,当扫描发现有没有分配的tablet,把它加入到未分配的tablet中
其中有个问题是扫描metadata table之前,需要metadata的tablets都被分配了。因此,在扫描之前,需要先把root tablet加入到未分配的tablet中,这样root table在后面就会被分配了。因为root tablet中,有所有的metadata的tablets的信息,然后可以通过这些信息来确定哪些metadata的tablet未分配,然后把它们分配到相应的tablet server。
tablet发生改变的时机
- tablet创建或删除
- tablet分裂,或者tablet合并
tablet分裂
tablet分裂是由tablet server发起的,tablet最终会把分裂信息写入到metadata table中,然后通知master。为了防止通知丢失,当master让一个tablet server去load刚刚分裂的tablet时,master检测到新的tablet。tablet server会告诉master分裂的情况,因为,tablet会发现master要求load的tablet是几个tablet的和。
master让tablet server去load tablet的时机一般不是启动的时候?还有就是检测到没有分配的时候?
目前猜测master会有后台任务定期的扫描未分配的tablet。
5.3 Tablet Serving
tablet的存储最终持久化到GFS,其中包括SSTable数据和commit log。最近的commit log会在内存中存储,并持久化tablet log中,之前的commit log可能会dump到GFS中,以SSTable来存储。
tablet recovery
读取最近一次dump到SSTable中的commit log,然后再此之上,把之后的commit log的操作replay内存中。
write
写操作首先会检查语法是否出错以及是否有权限写,检查权限通过一个chubby file来获取(通常在client端有cache)。合法的操作就被持久化到commit log中,然后插入到memtable里面。为了优化性能,会采用group commit机制来组合提交多次写操作的log。
read
读操作首先会检查语法是否出错以及是否有权限读。最终读出的数据是一些列的SSTable和Memtable合并后的数据,因为它们都是按照key排序的,合并效率是比较高的。
读写操作可以在tablet合并或者分裂的时候进行。
5.4 Compactions
bigtable中compaction分为minor compaction,merging compaction和major compaction。
minor compaction
当memtable达到一定大小限制时,冻结的memtable会被转换成SSTable,存储到GFS中。
minor compaction的目标主要有
- 减少tablet server的内存使用
- 减少tablet recovery的时间
merging compaction
每次minor compaction都会生成一个新的SSTable。如果minor compaction较多,会生成一批SSTable,每次读操作都会需要合并这些SSTable的数据。为了提升读性能,bigtable限制这些文件的个数,会定时的执行merging compaction,来合并部分SSTable和memtable,然后生成一个新的SSTable。
major compaction
major compaction将所有的SSTable合并成一个SSTable。major和非major的区别在于,major compaction后的SSTable不包含任何的已经删除的数据,而非major compaction有可能会包含。
6. Refinements
本部分讨论一些提升系统性能、可用性和可靠性的方法和技术。
6.1 Locality groups
client可以指定多个column family到一个locality group,每个locality group会单独指定一个SSTable,这样读单个locality group的数据会更高效。例如,在WebTable中page meta放到一个locality group,而content可以放到另一个locality group。这样读page meta的时候,就不需要去读page content信息了。备注:可能的坏处时,如果需要读多个locality group的数据的时候,这样就会比较低效,需要应用控制好locality group的划分,适合业务特征。
另外,locality group中的SSTable可以配置放到内存中,采用延迟加载的方法,一旦放入内存后,下次读SSTable的时候就可以从内存中查找数据了。例如,metadata table的数据被配置成这种方式。
6.2 Compression
按照locality group来进行压缩,client可以配置具体的压缩算法。具体地压缩的时候,对每个SSTable的block来进行压缩的,这样的好处是,读SSTable的数据的时候,不需要解压整个文件。在google应用中,需要client采用两级压缩的方法,先采用Bentley and McIlroy方法压缩长公共字符串,接着采用一个快速压缩算法,按照16KB为块来进行压缩。在WebTable中把同一个host的内容放在一起,可以提升压缩比例,并且,row key的取名也比较重要。
6.3 Caching for read performance
采用两级cache,其中Scan Cache用来存储访问过的K/V对,对重复读某些数据的性能的应用比较友好;Block Cache缓存从GFS中读取的SSTable block,对读附近的数据的应用比较友好。
6.4 Bloom filters
在bigtable中,经常需要从多个SSTable中合并出数据,返回给client。如果SSTable不在内存中,将会有比较多的磁盘I/O。Bloom filter可以帮助过滤掉大部分那些SSTable中没有某行数据的,以减少访问SSTable的次数。
6.5 Commit-log implementation
commit log可以有两种实现方式,第一种是每个tablet一个log文件,第二种是一个tablet server一个log文件。
如果采用第一种方式实现,每个写操作都要去写对应的文件,需要大量的disk seek去写到不同的物理文件中。并且,对于group commit的优化会减弱,只有同一个tablet的才会形成一个group。
采用第二种方式实现会改善上面两种操作的效率,但是对于tablet recovery不友好。当一个tablet server宕机后,其上的tablet会被多个不同的其他tablet server加载上。这些tablet server只需要该tablet server的某些tablet的commit log,而不是需要所有的,解决方案是,先把commit log按照
写日志的时候,有可能会碰到GFS的写操作延迟比较大,例如碰到要写入的副本宕机等情况,bigtable采用的解决方案是,用两个线程来写日志,每个写入自己的文件。同一时刻,只有一个线程在工作,如果当前线程的写入性能比较差,那么切换到另一个进程。
问题:最终的commit log应该是两个线程写入的文件内容去重后合并的结果?
6.6 Speeding up tablet recovery
把一个tablet从某个tablet server A迁移到另一个tablet server B的流程
- A上对该tablet做一次minor compaction,以减少replay log的时间
- A对该tablet停止服务,需要再做一次minor compaction,因为从上次做minor compaction到停止服务期间可能有新的写入操作
- 在B上一次加载这两次minor compaction的内容到内存中
问题:中间停止服务的时间应该是从步骤二开始到步骤三结束,大约时间需要多少?
6.7 Exploiting immutability
对于SSTable,由于SSTable是不可修改的,因此,对于SSTable文件的访问可以并行,无需要进行同步。对于分裂操作,也可以让分裂后的tablet共享原来的SSTable。
对于memtable,采用的是copy on write机制,保证读和写可以并行。即先拷贝一份数据出来,修改后,再写入到memtable中。
对于已删除的数据,是放到SSTable文件的清理来做的,master采用mark-and-sweep机制来清理。
/gfs_architecture.png)
(图片来源:gfs论文)
GFS中有四类角色,分别是
- GFS chunkserver
- GFS master
- GFS client
- Application
3.1.1 GFS chunkserver
在GFS chunkserver中,文件都是分成固定大小的chunk来存储的,每个chunk通过全局唯一的64位的chunk handle来标识,chunk handle在chunk创建的时候由GFS master分配。GFS chunkserver把文件存储在本地磁盘中,读或写的时候需要指定文件名和字节范围,然后定位到对应的chunk。为了保证数据的可靠性,一个chunk一般会在多台GFS chunkserver上存储,默认为3份,但用户也可以根据自己的需要修改这个值。
3.1.2 GFS master
GFS master管理所有的元数据信息,包括namespaces,访问控制信息,文件到chunk的映射信息,以及chunk的地址信息(即chunk存放在哪台GFS chunkserver上)。
3.1.3 GFS client
GFS client是GFS应用端使用的API接口,client和GFS master交互来获取元数据信息,但是所有和数据相关的信息都是直接和GFS chunkserver来交互的。
3.1.4 Application
Application为使用gfs的应用,应用通过GFS client于gfs后端(GFS master和GFS chunkserver)打交道。
3.2 Single Master
GFS架构中只有单个GFS master,这种架构的好处是设计和实现简单,例如,实现负载均衡时可以利用master上存储的全局的信息来做决策。但是,在这种架构下,要避免的一个问题是,应用读和写请求时,要弱化GFS master的参与度,防止它成为整个系统架构中的瓶颈。
从一个请求的流程来讨论上面的问题。首先,应用把文件名和偏移量信息传递给GFS client,GFS client转换成(文件名,chunk index)信息传递给GFS master,GFS master把(chunk handle, chunk位置信息)返回给客户端,客户端会把这个信息缓存起来,这样,下次再读这个chunk的时候,就不需要去GFS master拉取chunk位置信息了。
另一方面,GFS支持在一个请求中同时读取多个chunk的位置信息,这样更进一步的减少了GFS client和GFS master的交互次数,避免GFS master成为整个系统的瓶颈。
3.3 Chunk Size
对于GFS来说,chunk size的默认大小是64MB,比一般文件系统的要大。
优点
- 可以减少GFS client和GFS master的交互次数,chunk size比较大的时候,多次读可能是一块chunk的数据,这样,可以减少GFS client向GFS master请求chunk位置信息的请求次数。
- 对于同一个chunk,GFS client可以和GFS chunkserver之间保持持久连接,提升读的性能。
- chunk size越大,chunk的metadata的总大小就越小,使得chunk相关的metadata可以存储在GFS master的内存中。
缺点
- chunk size越大时,可能对部分文件来讲只有1个chunk,那么这个时候对该文件的读写就会落到一个GFS chunkserver上,成为热点。
对于热点问题,google给出的解决方案是应用层避免高频地同时读写同一个chunk。还提出了一个可能的解决方案是,GFS client找其他的GFS client来读数据。
64MB应该是google得出的一个比较好的权衡优缺点的经验值。
3.4 Metadata
GFS master存储三种metadata,包括文件和chunk namespace,文件到chunk的映射以及chunk的位置信息。这些metadata都是存储在GFS master的内存中的。对于前两种metadata,还会通过记操作日志的方式持久化存储,操作日志会同步到包括GFS master在内的多台机器上。GFS master不持久化存储chunk的位置信息,每次GFS master重启或者有新的GFS chunkserver加入时,GFS master会要求对应GFS chunkserver把chunk的位置信息汇报给它。
3.4.1 In-Memory Data Structures
使用内存存储metadata的好处是读取metadata速度快,方便GFS master做一些全局扫描metadata相关信息的操作,例如负载均衡等。
但是,以内存存储的的话,需要考虑的是GFS master的内存空间大小是不是整个系统能存储的chunk数量的瓶颈所在。在GFS实际使用过程中,这一般不会成为限制所在,因为GFS中一个64MBchunk的metadata大小不超过64B,并且,对于大部分chunk来讲都是使用的全部的空间的,只有文件的最后一个chunk会存储在部分空间没有使用,因此,GFS master的内存空间在实际上很少会成为限制系统容量的因素。即使真的是现有的存储文件的chunk数量超过了GFS master内存空间大小的限制,也可以通过加内存的方式,来获取内存存储设计带来的性能、可靠性等多种好处。
3.4.2 Chunk Locations
GFS master不持久化存储chunk位置信息的原因是,GFS chunkserver很容易出现宕机,重启等行为,这样GFS master在每次发生这些事件的时候,都要修改持久化存储里面的位置信息的数据。
3.4.3 Operation Log
operation log的作用
- 持久化存储metadata
- 它的存储顺序定义了并行的操作的最终的操作顺序
怎么存
operation log会存储在GFS master和多台远程机器上,只有当operation log在GFS master和多台远程机器都写入成功后,GFS master才会向GFS client返回成功。为了减少operation log在多台机器落盘对吞吐量的影响,可以将一批的operation log形成一个请求,然后写入到GFS master和其他远程机器上。
check point
当operation log达到一定大小时,GFS master会做checkpoint,相当于把内存的B-Tree格式的信息dump到磁盘中。当master需要重启时,可以读最近一次的checkpoint,然后replay它之后的operation log,加快恢复的时间。
做checkpoint的时候,GFS master会先切换到新的operation log,然后开新线程做checkpoint,所以,对新来的请求是基本是不会有影响的。
4. System Interactions
本部分讨论GFS的系统交互流程。
4.1 Leases and Mutation Order
GFS master对后续的数据流程是不做控制的,所以,需要一个机制来保证,所有副本是按照同样的操作顺序写入对应的数据的。GFS采用lease方式来解决这个问题,GFS对一个chunk会选择一个GFS chunkserver,发放lease,称作primary,由primary chunkserver来控制写入的顺序。
Lease的过期时间默认是60s,可以通过心跳信息来续时间,如果一个primary chunkserver是正常状态的话,这个时间一般是无限续下去的。当primary chunkserver和GFS master心跳断了后,GFS master也可以方便的把其他chunk副本所在的chunkserver设置成primary。
4.1.1 Write Control and Data Flow
->string
如上所示,key为row:string, column:string, time:int64, value为string
以一个例子来说明该映射关系,如下图:
如上图所示,表名为WebTable,以URL为row key,网页各方面属性为column name,其中网页内容存储在contents:列中,通过时间戳可以区分列的数据版本。
2.1 Rows
Row key可以是任意的字符串,大小不超过64KB。每次针对单行的操作都是原子操作。
Bigtable按照row key的字典序对数据排序,每张表按照row key的排序范围动态划分。每个划分的row范围称作是tablet,是数据分布和负载均衡的单元。客户端可以根据这个特性,来把需要一起读的数据尽可能的安排在一起。例如,对于WebTable,如果需要同一个域名下的网页尽量放在一起的话,可以把域名maps.google.com/index.html按照row keycom.google.maps/index.html来存储。
2.2 Column Families
Column Key按照column family分组存储,访问控制信息也是按照column family为单元来设置的。一般来讲,期望的是所有存储在column family的列的数据类型是一样的,因为bigtable是按照column family进行压缩的。
在进行列存储前,column family必须要先创建,一旦创建好,任何在此family下的column key都可以使用。bigtable期望的是一张表的column family的schema几乎是不变的,且一张表的column family数量较小(最多几百个),但是,列的数量是无限制的。
Column key的表现形式为family:qualifier,对于family必须是可打印的字符串,对于qualifier可以是任意的字符串。以column faimilyanchor为例,每个column key都代表一个anchor,例如anchor:cnnsi.com。
2.3 Timestamp
Bigtable会对每个单元格的数据存储多个版本,版本按照时间戳排序。Bigtable timestamp是64位整数,可以由bigtable内部生成或者client端指定。
为了方便client指定需要存储多少个版本的数据,bigtable可以针对每个column family来设置,例如可以设定只存储最新的n个版本或者最近n天的数据。
对于WebTable,timestamp为爬取网页内容的时间戳,设定为只存储最新三个版本的数据。
3. API
Bigtable API提供了创建和删除表、column family的API,还提供了设置集群、表、column family元数据的API,例如改变访问控制权限。
写和删除的例子
遍历数据的例子
4. Building Blocks
Bigtable使用了其他的一些系统来构建服务:
- 使用了GFS来存储日志和数据文件
- 集群管理系统来负责分配管理资源,监控机器状态等
4.1 SSTable
Bigtable底层使用SSTable文件格式来存储数据。一个SSTable是存储多个K/V数据,数据按照KEY排序并且不能修改。对SSTable可以执行的操作包括,按照指定Key查找,按照Key Range遍历。
在SSTable内部,包含一些列的block(一般每个block是64KB,但也是可以配置的),在SSTable的尾部存储了block的索引,方便快速查找Key在哪个block内。当SSTable文件打开时,是会把block的索引加载到内存中去的。对于一次查找一般会有一次磁盘开销,先从内存中定位到在哪个block,然后把block从磁盘中读出来。
4.2 Chubby
Bigtable里面另一个依赖比较重的服务是Chubby。Chubby是一个分布式的锁服务,一般五副本冗余存储,其中一个会被选为主,只要五副本中的大多数是正常状态,chubby就可以保持可用。
Chubby提供一个包含目录或文件的命名空间,每个目录或者文件都可以当作是锁服务来使用,对单个文件的读或者写都是原子的。Chubby Client Library提供Chubby文件的缓存,每个Chubby Client和Chubby服务端通过一个session保持链接。一个Client的Session会在其无法在lease过期时间内续约而到期。当一个Client的session到期后,它会丢失所有的锁和handle。Chubby client可以在文件或者目录下注册回调事件,当文件或目录发生变化是会通知相应的client。
在Bigtable中,使用到Chubby的地方如下:
- 发现tablet server和tablet server挂掉
- 存储bigtable schema信息,主要是column family信息,以及存储访问控制信息
备注:如果chubby挂掉或者chubby和bigtable之间通信断掉,那么bigtable服务将不可用。
5. Implementation
Bigtable中有三大组件,包括client,单master和许多的tablet server。可以根据负载的情况,动态的加入或者删除机器。
master的工作
- 分配tablet到tablet server
- 检测tablet server的加入和过期
- 均衡tablet server的负载
- garbage collection GFS中的文件
- schema变更,包括表和column family的创建等
由于master不存储tablet location信息,因此,client基本上从来不会与master通信,master不会成为系统的瓶颈。
tablet server的工作
- 管理一组tablet
- 处理tablet的读写请求
- 分裂过大的tablet
每个Bigtable集群存储多张表,每张表包含多个tablet。初始的时候,一张表只有一个tablet,当表数据量增加时,会自动分裂成多个tablet。
5.1 Tablet Location
tablet location采用三层的存储层次,如下图:
- Chubby file存储Root tablet的location
- Root tablet存储othter MetaData tablet的location,root tablet不能分裂,需要保证三层结构
- 每个Metadata tablet存储一组user tablet的location
Metadata tablet的每行存储user tablet的row range的开始行和结束行等信息。
对于Client端,会缓存tablet location。如果客户端发现它的tablet location为空或者不正确,会从最上层开始查找和比较。对于为空的情况,需要三次网络开销来读取信息;对于不正确的情况,最坏需要六次网络开销,因为可能对于三层结构都出错了,每次都要试一次错,再读一次正确的数据。为了提升性能,client端一次会预取多个tablet的location并缓存。
tablet location信息应该都是存储在tablet server上的。
5.2 Tablet Assignment
master负责跟踪活着的tablet server和tablet到tablet server的分配,包括哪些tablet没有分配。当一个tablet没有被分配,并且一个tablet server可以容纳下该tablet,master给该tablet server发送请求告诉其load该tablet。
问题:这里的sufficient room指的是什么指标?
Chubby用来跟踪tablet server状态
- 当一个tablet server启动的时候,它会在Chubby指定目录创建一个文件,并获取一把锁
- master通过监控目录来发现新加入的tablet server
- tablet server在锁丢失时停止服务
- 当其所创建的文件还存在的情况下,tablet server会尝试重新获取锁
- 如果其创键的文件不存在,tablet server会停止进程
- 当tablet server终止时,会释放锁,然后master可以跟快速的来重新分配tablet
master的工作
master的工作包括两方面
- 检测停止服务的tablet server
- 尽快的重新分配tablet到tablet server
master周期性和tablet server通信来询问其锁的状态,如果是
- tablet server汇报其已经丢失了锁
- master多次重试无法和tablet server通信,接着master尝试和chubby通信,获取该server的文件所,根据结果分为两种情况:第一是master可以获得锁,那么说明tablet server挂掉或者其与Chubby无法通信,那么,master可以确信它无法提供服务了,因此立即删除Chubby上的文件,然后,把这台tablet server上的tablet都设置成未分配状态;第二是master无法获得锁,说明master和Chubby通信有问题,master会停止进程。
问题:master重新分配tablet的时机是? 问题:为什么master不直接和tablet server维持租约? 问题:为什么master不直接看chubby上的锁状态来确定tablet server的状态?有可能tablet server和chubby可以连接,但master和tablet server连不上。
master启动时,需要先检测当前的tablet分配情况,然后才能改变分配情况,启动步骤如下
- 从Chubby获取唯一的
master的锁,防止出现多个master - master扫描Chubby指定目录,发现活的tablet server
- master和活的tablet server通信,来获取它们已经分配了哪些tablet
- master扫描metadata table,去获取所有的tablet,当扫描发现有没有分配的tablet,把它加入到未分配的tablet中
其中有个问题是扫描metadata table之前,需要metadata的tablets都被分配了。因此,在扫描之前,需要先把root tablet加入到未分配的tablet中,这样root table在后面就会被分配了。因为root tablet中,有所有的metadata的tablets的信息,然后可以通过这些信息来确定哪些metadata的tablet未分配,然后把它们分配到相应的tablet server。
tablet发生改变的时机
- tablet创建或删除
- tablet分裂,或者tablet合并
tablet分裂
tablet分裂是由tablet server发起的,tablet最终会把分裂信息写入到metadata table中,然后通知master。为了防止通知丢失,当master让一个tablet server去load刚刚分裂的tablet时,master检测到新的tablet。tablet server会告诉master分裂的情况,因为,tablet会发现master要求load的tablet是几个tablet的和。
master让tablet server去load tablet的时机一般不是启动的时候?还有就是检测到没有分配的时候?
目前猜测master会有后台任务定期的扫描未分配的tablet。
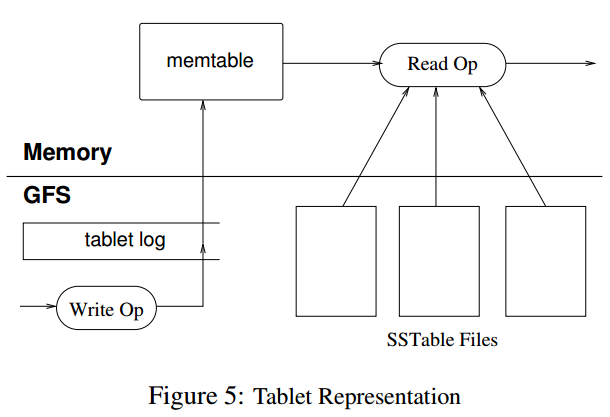
5.3 Tablet Serving
tablet的存储最终持久化到GFS,其中包括SSTable数据和commit log。最近的commit log会在内存中存储,并持久化tablet log中,之前的commit log可能会dump到GFS中,以SSTable来存储。
tablet recovery
读取最近一次dump到SSTable中的commit log,然后再此之上,把之后的commit log的操作replay内存中。
write
写操作首先会检查语法是否出错以及是否有权限写,检查权限通过一个chubby file来获取(通常在client端有cache)。合法的操作就被持久化到commit log中,然后插入到memtable里面。为了优化性能,会采用group commit机制来组合提交多次写操作的log。
read
读操作首先会检查语法是否出错以及是否有权限读。最终读出的数据是一些列的SSTable和Memtable合并后的数据,因为它们都是按照key排序的,合并效率是比较高的。
读写操作可以在tablet合并或者分裂的时候进行。
5.4 Compactions
bigtable中compaction分为minor compaction,merging compaction和major compaction。
minor compaction
当memtable达到一定大小限制时,冻结的memtable会被转换成SSTable,存储到GFS中。
minor compaction的目标主要有
- 减少tablet server的内存使用
- 减少tablet recovery的时间
merging compaction
每次minor compaction都会生成一个新的SSTable。如果minor compaction较多,会生成一批SSTable,每次读操作都会需要合并这些SSTable的数据。为了提升读性能,bigtable限制这些文件的个数,会定时的执行merging compaction,来合并部分SSTable和memtable,然后生成一个新的SSTable。
major compaction
major compaction将所有的SSTable合并成一个SSTable。major和非major的区别在于,major compaction后的SSTable不包含任何的已经删除的数据,而非major compaction有可能会包含。
6. Refinements
本部分讨论一些提升系统性能、可用性和可靠性的方法和技术。
6.1 Locality groups
client可以指定多个column family到一个locality group,每个locality group会单独指定一个SSTable,这样读单个locality group的数据会更高效。例如,在WebTable中page meta放到一个locality group,而content可以放到另一个locality group。这样读page meta的时候,就不需要去读page content信息了。备注:可能的坏处时,如果需要读多个locality group的数据的时候,这样就会比较低效,需要应用控制好locality group的划分,适合业务特征。
另外,locality group中的SSTable可以配置放到内存中,采用延迟加载的方法,一旦放入内存后,下次读SSTable的时候就可以从内存中查找数据了。例如,metadata table的数据被配置成这种方式。
6.2 Compression
按照locality group来进行压缩,client可以配置具体的压缩算法。具体地压缩的时候,对每个SSTable的block来进行压缩的,这样的好处是,读SSTable的数据的时候,不需要解压整个文件。在google应用中,需要client采用两级压缩的方法,先采用Bentley and McIlroy方法压缩长公共字符串,接着采用一个快速压缩算法,按照16KB为块来进行压缩。在WebTable中把同一个host的内容放在一起,可以提升压缩比例,并且,row key的取名也比较重要。
6.3 Caching for read performance
采用两级cache,其中Scan Cache用来存储访问过的K/V对,对重复读某些数据的性能的应用比较友好;Block Cache缓存从GFS中读取的SSTable block,对读附近的数据的应用比较友好。
6.4 Bloom filters
在bigtable中,经常需要从多个SSTable中合并出数据,返回给client。如果SSTable不在内存中,将会有比较多的磁盘I/O。Bloom filter可以帮助过滤掉大部分那些SSTable中没有某行数据的,以减少访问SSTable的次数。
6.5 Commit-log implementation
commit log可以有两种实现方式,第一种是每个tablet一个log文件,第二种是一个tablet server一个log文件。
如果采用第一种方式实现,每个写操作都要去写对应的文件,需要大量的disk seek去写到不同的物理文件中。并且,对于group commit的优化会减弱,只有同一个tablet的才会形成一个group。
采用第二种方式实现会改善上面两种操作的效率,但是对于tablet recovery不友好。当一个tablet server宕机后,其上的tablet会被多个不同的其他tablet server加载上。这些tablet server只需要该tablet server的某些tablet的commit log,而不是需要所有的,解决方案是,先把commit log按照
写日志的时候,有可能会碰到GFS的写操作延迟比较大,例如碰到要写入的副本宕机等情况,bigtable采用的解决方案是,用两个线程来写日志,每个写入自己的文件。同一时刻,只有一个线程在工作,如果当前线程的写入性能比较差,那么切换到另一个进程。
问题:最终的commit log应该是两个线程写入的文件内容去重后合并的结果?
6.6 Speeding up tablet recovery
把一个tablet从某个tablet server A迁移到另一个tablet server B的流程
- A上对该tablet做一次minor compaction,以减少replay log的时间
- A对该tablet停止服务,需要再做一次minor compaction,因为从上次做minor compaction到停止服务期间可能有新的写入操作
- 在B上一次加载这两次minor compaction的内容到内存中
问题:中间停止服务的时间应该是从步骤二开始到步骤三结束,大约时间需要多少?
6.7 Exploiting immutability
对于SSTable,由于SSTable是不可修改的,因此,对于SSTable文件的访问可以并行,无需要进行同步。对于分裂操作,也可以让分裂后的tablet共享原来的SSTable。
对于memtable,采用的是copy on write机制,保证读和写可以并行。即先拷贝一份数据出来,修改后,再写入到memtable中。
对于已删除的数据,是放到SSTable文件的清理来做的,master采用mark-and-sweep机制来清理。
/gfs_write_control.png)
(图片来源:gfs论文)
- GFS client向GFS master请求拥有具有当前chunk的lease的chunkserver信息,以及chunk的其他副本所在的chunkserver的信息,如果当前chunk没有lease,GFS master会分配一个。
- GFS master把primary chunkserver以及其他副本的chunkserver信息返回给client。client会缓存这些信息,只有当primary chunkserver连不上或者lease发生改变后,才需要再向GFS master获取对应的信息。
- client把数据推送给所有包含此chunk的chunkserver,chunkserver收到后会先把数据放到内部的LRU buffer中,当数据被使用或者过期了,才删除掉。注意,这里没有将具体怎么来发送数据,会在下面的Data Flow讲。
- 当所有包含chunk副本的chunkserver都收到了数据,client会给primary发送一个写请求,包含之前写的数据的信息,primary会分配对应的序号给此次的写请求,这样可以保证从多个客户端的并发写请求会得到唯一的操作顺序,保证多个副本的写入数据的顺序是一致的。
- primary转发写请求给所有其他的副本所在的chunkserver(Secondary replica),操作顺序由primary指定。
- Secondary replica写成功后会返回给primary replica。
- Primary replica返回给client。任何副本发生任何错误都会返回给client。
这里,写数据如果发生错误可能会产生不一致的情况,会在consistency model中讨论。
4.2 Data Flow
4.1中第三步的Data Flow采用的是pipe line方式,目标是为了充分利用每台机器的网络带宽。假设一台机器总共有三个副本S1-S3。整个的Data Flow为:
- client选择离它最近的chunkserver S1,开始推送数据
- 当chunkserver S1收到数据后,它会立马转发到离它最近的chunkserver S2
- chunkserver S2收到数据后,会立马转发给离它最近的chunkserver S3
不断重复上述流程,直到所有的chunkserver都收到client的所有数据。
以上述方式来传送B字节数据到R个副本,并假设网络吞吐量为T,机器之间的时延为L,那么,整个数据的传输时间为B/T+RL。
4.3 Atomic Record Appends
Append操作流程和写差不多,主要区别在以下
- client把数据推送到所有副本的最后一个chunk,然后发送写请求到primary
- primary首先检查最后一个chunk的剩余空间是否可以满足当前写请求,如果可以,那么执行写流程,否则,它会把当前的chunk的剩余空间pad起来,然后告诉其他的副本也这么干,最后告诉client这个chunk满了,写入下个chunk。
这里需要讨论的是,如果append操作在部分副本失败的情况下,会发生什么?
例如,写操作要追加到S1-S3,但是,仅仅是S1,S2成功了,S3失败了,GFS client会重试操作,假如第二次成功了,那么S1,S2写了两次,S3写了一次,目前的理解是GFS会先把失败的记录进行padding对齐到primary的记录,然后再继续append。
4.4 Snapshot
Snapshot的整个流程如下:
- client向GFS master发送Snapshot请求
- GFS master收到请求后,会回收所有这次Snapshot涉及到的chunk的lease
- 当所有回收的lease到期后,GFS master写入一条日志,记录这个信息。然后,GFS会在内存中复制一份snapshot涉及到的metadata
当snapshot操作完成后,client写snapshot中涉及到的chunk C的流程如下:
- client向GFS master请求primary chunkserver和其他chunkserver
- GFS master发现chunk C的引用计数超过1,即snapshot和本身。它会向所有有chunk C副本的chunkserver发送创建一个chunk C的拷贝请求,记作是chunk C',这样,把最新数据写入到chunk C'即可。本质上是copy on write。
4.5 Consistency Model
->string
如上所示,key为row:string, column:string, time:int64, value为string
以一个例子来说明该映射关系,如下图:
如上图所示,表名为WebTable,以URL为row key,网页各方面属性为column name,其中网页内容存储在contents:列中,通过时间戳可以区分列的数据版本。
2.1 Rows
Row key可以是任意的字符串,大小不超过64KB。每次针对单行的操作都是原子操作。
Bigtable按照row key的字典序对数据排序,每张表按照row key的排序范围动态划分。每个划分的row范围称作是tablet,是数据分布和负载均衡的单元。客户端可以根据这个特性,来把需要一起读的数据尽可能的安排在一起。例如,对于WebTable,如果需要同一个域名下的网页尽量放在一起的话,可以把域名maps.google.com/index.html按照row keycom.google.maps/index.html来存储。
2.2 Column Families
Column Key按照column family分组存储,访问控制信息也是按照column family为单元来设置的。一般来讲,期望的是所有存储在column family的列的数据类型是一样的,因为bigtable是按照column family进行压缩的。
在进行列存储前,column family必须要先创建,一旦创建好,任何在此family下的column key都可以使用。bigtable期望的是一张表的column family的schema几乎是不变的,且一张表的column family数量较小(最多几百个),但是,列的数量是无限制的。
Column key的表现形式为family:qualifier,对于family必须是可打印的字符串,对于qualifier可以是任意的字符串。以column faimilyanchor为例,每个column key都代表一个anchor,例如anchor:cnnsi.com。
2.3 Timestamp
Bigtable会对每个单元格的数据存储多个版本,版本按照时间戳排序。Bigtable timestamp是64位整数,可以由bigtable内部生成或者client端指定。
为了方便client指定需要存储多少个版本的数据,bigtable可以针对每个column family来设置,例如可以设定只存储最新的n个版本或者最近n天的数据。
对于WebTable,timestamp为爬取网页内容的时间戳,设定为只存储最新三个版本的数据。
3. API
Bigtable API提供了创建和删除表、column family的API,还提供了设置集群、表、column family元数据的API,例如改变访问控制权限。
写和删除的例子
遍历数据的例子
4. Building Blocks
Bigtable使用了其他的一些系统来构建服务:
- 使用了GFS来存储日志和数据文件
- 集群管理系统来负责分配管理资源,监控机器状态等
4.1 SSTable
Bigtable底层使用SSTable文件格式来存储数据。一个SSTable是存储多个K/V数据,数据按照KEY排序并且不能修改。对SSTable可以执行的操作包括,按照指定Key查找,按照Key Range遍历。
在SSTable内部,包含一些列的block(一般每个block是64KB,但也是可以配置的),在SSTable的尾部存储了block的索引,方便快速查找Key在哪个block内。当SSTable文件打开时,是会把block的索引加载到内存中去的。对于一次查找一般会有一次磁盘开销,先从内存中定位到在哪个block,然后把block从磁盘中读出来。
4.2 Chubby
Bigtable里面另一个依赖比较重的服务是Chubby。Chubby是一个分布式的锁服务,一般五副本冗余存储,其中一个会被选为主,只要五副本中的大多数是正常状态,chubby就可以保持可用。
Chubby提供一个包含目录或文件的命名空间,每个目录或者文件都可以当作是锁服务来使用,对单个文件的读或者写都是原子的。Chubby Client Library提供Chubby文件的缓存,每个Chubby Client和Chubby服务端通过一个session保持链接。一个Client的Session会在其无法在lease过期时间内续约而到期。当一个Client的session到期后,它会丢失所有的锁和handle。Chubby client可以在文件或者目录下注册回调事件,当文件或目录发生变化是会通知相应的client。
在Bigtable中,使用到Chubby的地方如下:
- 发现tablet server和tablet server挂掉
- 存储bigtable schema信息,主要是column family信息,以及存储访问控制信息
备注:如果chubby挂掉或者chubby和bigtable之间通信断掉,那么bigtable服务将不可用。
5. Implementation
Bigtable中有三大组件,包括client,单master和许多的tablet server。可以根据负载的情况,动态的加入或者删除机器。
master的工作
- 分配tablet到tablet server
- 检测tablet server的加入和过期
- 均衡tablet server的负载
- garbage collection GFS中的文件
- schema变更,包括表和column family的创建等
由于master不存储tablet location信息,因此,client基本上从来不会与master通信,master不会成为系统的瓶颈。
tablet server的工作
- 管理一组tablet
- 处理tablet的读写请求
- 分裂过大的tablet
每个Bigtable集群存储多张表,每张表包含多个tablet。初始的时候,一张表只有一个tablet,当表数据量增加时,会自动分裂成多个tablet。
5.1 Tablet Location
tablet location采用三层的存储层次,如下图:
- Chubby file存储Root tablet的location
- Root tablet存储othter MetaData tablet的location,root tablet不能分裂,需要保证三层结构
- 每个Metadata tablet存储一组user tablet的location
Metadata tablet的每行存储user tablet的row range的开始行和结束行等信息。
对于Client端,会缓存tablet location。如果客户端发现它的tablet location为空或者不正确,会从最上层开始查找和比较。对于为空的情况,需要三次网络开销来读取信息;对于不正确的情况,最坏需要六次网络开销,因为可能对于三层结构都出错了,每次都要试一次错,再读一次正确的数据。为了提升性能,client端一次会预取多个tablet的location并缓存。
tablet location信息应该都是存储在tablet server上的。
5.2 Tablet Assignment
master负责跟踪活着的tablet server和tablet到tablet server的分配,包括哪些tablet没有分配。当一个tablet没有被分配,并且一个tablet server可以容纳下该tablet,master给该tablet server发送请求告诉其load该tablet。
问题:这里的sufficient room指的是什么指标?
Chubby用来跟踪tablet server状态
- 当一个tablet server启动的时候,它会在Chubby指定目录创建一个文件,并获取一把锁
- master通过监控目录来发现新加入的tablet server
- tablet server在锁丢失时停止服务
- 当其所创建的文件还存在的情况下,tablet server会尝试重新获取锁
- 如果其创键的文件不存在,tablet server会停止进程
- 当tablet server终止时,会释放锁,然后master可以跟快速的来重新分配tablet
master的工作
master的工作包括两方面
- 检测停止服务的tablet server
- 尽快的重新分配tablet到tablet server
master周期性和tablet server通信来询问其锁的状态,如果是
- tablet server汇报其已经丢失了锁
- master多次重试无法和tablet server通信,接着master尝试和chubby通信,获取该server的文件所,根据结果分为两种情况:第一是master可以获得锁,那么说明tablet server挂掉或者其与Chubby无法通信,那么,master可以确信它无法提供服务了,因此立即删除Chubby上的文件,然后,把这台tablet server上的tablet都设置成未分配状态;第二是master无法获得锁,说明master和Chubby通信有问题,master会停止进程。
问题:master重新分配tablet的时机是? 问题:为什么master不直接和tablet server维持租约? 问题:为什么master不直接看chubby上的锁状态来确定tablet server的状态?有可能tablet server和chubby可以连接,但master和tablet server连不上。
master启动时,需要先检测当前的tablet分配情况,然后才能改变分配情况,启动步骤如下
- 从Chubby获取唯一的
master的锁,防止出现多个master - master扫描Chubby指定目录,发现活的tablet server
- master和活的tablet server通信,来获取它们已经分配了哪些tablet
- master扫描metadata table,去获取所有的tablet,当扫描发现有没有分配的tablet,把它加入到未分配的tablet中
其中有个问题是扫描metadata table之前,需要metadata的tablets都被分配了。因此,在扫描之前,需要先把root tablet加入到未分配的tablet中,这样root table在后面就会被分配了。因为root tablet中,有所有的metadata的tablets的信息,然后可以通过这些信息来确定哪些metadata的tablet未分配,然后把它们分配到相应的tablet server。
tablet发生改变的时机
- tablet创建或删除
- tablet分裂,或者tablet合并
tablet分裂
tablet分裂是由tablet server发起的,tablet最终会把分裂信息写入到metadata table中,然后通知master。为了防止通知丢失,当master让一个tablet server去load刚刚分裂的tablet时,master检测到新的tablet。tablet server会告诉master分裂的情况,因为,tablet会发现master要求load的tablet是几个tablet的和。
master让tablet server去load tablet的时机一般不是启动的时候?还有就是检测到没有分配的时候?
目前猜测master会有后台任务定期的扫描未分配的tablet。
5.3 Tablet Serving
tablet的存储最终持久化到GFS,其中包括SSTable数据和commit log。最近的commit log会在内存中存储,并持久化tablet log中,之前的commit log可能会dump到GFS中,以SSTable来存储。
tablet recovery
读取最近一次dump到SSTable中的commit log,然后再此之上,把之后的commit log的操作replay内存中。
write
写操作首先会检查语法是否出错以及是否有权限写,检查权限通过一个chubby file来获取(通常在client端有cache)。合法的操作就被持久化到commit log中,然后插入到memtable里面。为了优化性能,会采用group commit机制来组合提交多次写操作的log。
read
读操作首先会检查语法是否出错以及是否有权限读。最终读出的数据是一些列的SSTable和Memtable合并后的数据,因为它们都是按照key排序的,合并效率是比较高的。
读写操作可以在tablet合并或者分裂的时候进行。
5.4 Compactions
bigtable中compaction分为minor compaction,merging compaction和major compaction。
minor compaction
当memtable达到一定大小限制时,冻结的memtable会被转换成SSTable,存储到GFS中。
minor compaction的目标主要有
- 减少tablet server的内存使用
- 减少tablet recovery的时间
merging compaction
每次minor compaction都会生成一个新的SSTable。如果minor compaction较多,会生成一批SSTable,每次读操作都会需要合并这些SSTable的数据。为了提升读性能,bigtable限制这些文件的个数,会定时的执行merging compaction,来合并部分SSTable和memtable,然后生成一个新的SSTable。
major compaction
major compaction将所有的SSTable合并成一个SSTable。major和非major的区别在于,major compaction后的SSTable不包含任何的已经删除的数据,而非major compaction有可能会包含。
6. Refinements
本部分讨论一些提升系统性能、可用性和可靠性的方法和技术。
6.1 Locality groups
client可以指定多个column family到一个locality group,每个locality group会单独指定一个SSTable,这样读单个locality group的数据会更高效。例如,在WebTable中page meta放到一个locality group,而content可以放到另一个locality group。这样读page meta的时候,就不需要去读page content信息了。备注:可能的坏处时,如果需要读多个locality group的数据的时候,这样就会比较低效,需要应用控制好locality group的划分,适合业务特征。
另外,locality group中的SSTable可以配置放到内存中,采用延迟加载的方法,一旦放入内存后,下次读SSTable的时候就可以从内存中查找数据了。例如,metadata table的数据被配置成这种方式。
6.2 Compression
按照locality group来进行压缩,client可以配置具体的压缩算法。具体地压缩的时候,对每个SSTable的block来进行压缩的,这样的好处是,读SSTable的数据的时候,不需要解压整个文件。在google应用中,需要client采用两级压缩的方法,先采用Bentley and McIlroy方法压缩长公共字符串,接着采用一个快速压缩算法,按照16KB为块来进行压缩。在WebTable中把同一个host的内容放在一起,可以提升压缩比例,并且,row key的取名也比较重要。
6.3 Caching for read performance
采用两级cache,其中Scan Cache用来存储访问过的K/V对,对重复读某些数据的性能的应用比较友好;Block Cache缓存从GFS中读取的SSTable block,对读附近的数据的应用比较友好。
6.4 Bloom filters
在bigtable中,经常需要从多个SSTable中合并出数据,返回给client。如果SSTable不在内存中,将会有比较多的磁盘I/O。Bloom filter可以帮助过滤掉大部分那些SSTable中没有某行数据的,以减少访问SSTable的次数。
6.5 Commit-log implementation
commit log可以有两种实现方式,第一种是每个tablet一个log文件,第二种是一个tablet server一个log文件。
如果采用第一种方式实现,每个写操作都要去写对应的文件,需要大量的disk seek去写到不同的物理文件中。并且,对于group commit的优化会减弱,只有同一个tablet的才会形成一个group。
采用第二种方式实现会改善上面两种操作的效率,但是对于tablet recovery不友好。当一个tablet server宕机后,其上的tablet会被多个不同的其他tablet server加载上。这些tablet server只需要该tablet server的某些tablet的commit log,而不是需要所有的,解决方案是,先把commit log按照
写日志的时候,有可能会碰到GFS的写操作延迟比较大,例如碰到要写入的副本宕机等情况,bigtable采用的解决方案是,用两个线程来写日志,每个写入自己的文件。同一时刻,只有一个线程在工作,如果当前线程的写入性能比较差,那么切换到另一个进程。
问题:最终的commit log应该是两个线程写入的文件内容去重后合并的结果?
6.6 Speeding up tablet recovery
把一个tablet从某个tablet server A迁移到另一个tablet server B的流程
- A上对该tablet做一次minor compaction,以减少replay log的时间
- A对该tablet停止服务,需要再做一次minor compaction,因为从上次做minor compaction到停止服务期间可能有新的写入操作
- 在B上一次加载这两次minor compaction的内容到内存中
问题:中间停止服务的时间应该是从步骤二开始到步骤三结束,大约时间需要多少?
6.7 Exploiting immutability
对于SSTable,由于SSTable是不可修改的,因此,对于SSTable文件的访问可以并行,无需要进行同步。对于分裂操作,也可以让分裂后的tablet共享原来的SSTable。
对于memtable,采用的是copy on write机制,保证读和写可以并行。即先拷贝一份数据出来,修改后,再写入到memtable中。
对于已删除的数据,是放到SSTable文件的清理来做的,master采用mark-and-sweep机制来清理。
/consistency_model.png)
(图片来源:gfs论文)
GFS中consistent、defined的定义如下:
- consistent:所有的客户端都能看到一样的数据,不管它们从哪个副本读取
- defined:当一个文件区域发生操作后,client可以看到刚刚操作的所有数据,那么说这次操作是defined。
下面分析表格中出现的几种情况。
- Write(Serial Success),单个写操作,并且返回成功,那么所有副本都写入了这次操作的数据,因此所有客户端都能看到这次写入的数据,所以,是defined。
- Write(Concurrent Successes),多个写操作,并且返回成功,由于多个客户端写请求发送给priamary后,由primary来决定写的操作顺序,但是,有可能多个写操作可能是有区域重叠的,这样,最终写完成的数据可能是多个写操作数据叠加在一起,所以这种情况是consistent和undefined。
- Write(Failure),写操作失败,则可能有的副本写入了数据,有的没有,所以是inconsistent。
- Record Append(Serial Success and Concurrent Success),由于Record Append可能包含重复数据,因此,是inconsistent,由于整个写入的数据都能看到,所以是defined。
- Record Append(Failure),可能部分副本append成功,部分副本append失败,所以,结果是inconsistent。
GFS用version来标记一个chunkserver挂掉的期间,是否有client进行了write或者append操作。每进行一次write或者append,version会增加。
需要考虑的点是client会缓存chunk的位置信息,有可能其中某些chunkserver已经挂掉又起来了,这个时候chunkserver的数据可能是老的数据,读到的数据是会不一致的。读流程中,好像没有看到要带version信息来读的。这个论文中没看到避免的措施,目前还没有结果。
4.5.1 Implications for Applications
应用层需要采用的机制:用append而不是write,做checkpoint,writing self-validating和self-identifying records。具体地,如下:
- 应用的使用流程是append一个文件,到最终写完后,重命名文件
- 对文件做checkpoint,这样应用只需要关注上次checkpoint时的文件区域到最新文件区域的数据是否是consistent的,如果这期间发生不一致,可以重新做这些操作。
- 对于并行做append的操作,可能会出现重复的数据,GFS client提供去重的功能。
5. Master Operation
GFS master的功能包括,namespace Management, Replica Placement,Chunk Creation,Re-replication and Rebalancing以及Garbage Collection。
5.1 Namespace Management and Locking
每个master操作都需要获得一系列的锁。如果一个操作涉及到/d1/d2/.../dn/leaf,那么需要获得/d1,/d1/d2,/d1/d2/.../dn的读锁,然后,根据操作类型,获得/d1/d2/.../dn/leaf的读锁或者写锁,其中leaf可能是文件或者路径。
一个例子,当/home/user被快照到/save/user的时候,/home/user/foo的创建是被禁止的。
对于快照,需要获得/home和/save的读锁,/home/user和/save/user的写锁。对于创建操作,会获得/home,/home/user的读锁,然后/home/user/foo的写锁。其中,/home/user的锁产生冲突,/home/user/foo创建会被禁止。
这种加锁机制的好处是对于同一个目录下,可以并行的操作文件,例如,同一个目录下并行的创建文件。
5.2 Replica Placement
GFS的Replica Placement的两个目标:最大化数据可靠性和可用性,最大化网络带宽的使用率。因此,把每个chunk的副本分散在不同的机架上,这样一方面,可以抵御机架级的故障,另一方面,可以把读写数据的带宽分配在机架级,重复利用多个机架的带宽。
5.3 Creation, Re-replication, Rebalancing
5.3.1 Chunk Creation
GFS在创建chunk的时候,选择chunkserver时考虑的因素包括:
- 磁盘空间使用率低于平均值的chunkserver
- 限制每台chunkserver的最近的创建chunk的次数,因为创建chunk往往意味着后续需要写大量数据,所以,应该把写流量尽量均摊到每台chunkserver上
- chunk的副本放在处于不同机架的chunkserver上
5.3.2 Chunk Re-replication
当一个chunk的副本数量少于预设定的数量时,需要做复制的操作,例如,chunkserver宕机,副本数据出错,磁盘损坏,或者设定的副本数量增加。
chunk的复制的优先级是按照下面的因素来确定的:
- 丢失两个副本的chunk比丢失一个副本的chunk的复制认为优先级高
- 文件正在使用比文件已被删除的chunk的优先级高
- 阻塞了client进程的chunk的优先级高(这个靠什么方法得到?)
chunk复制的时候,选择新chunkserver要考虑的点:
- 磁盘使用率
- 单个chunkserver的复制个数限制
- 多个副本需要在多个机架
- 集群的复制个数限制
- 限制每个chunkserver的复制网络带宽,通过限制读流量的速率来限制
5.3.3 Rebalancing
周期性地检查副本分布情况,然后调整到更好的磁盘使用情况和负载均衡。GFS master对于新加入的chunkserver,逐渐地迁移副本到上面,防止新chunkserver带宽打满。
5.4 Garbage Collection
在GFS删除一个文件后,并不会马上就对文件物理删除,而是在后面的定期清理的过程中才真正的删除。
具体地,对于一个删除操作,GFS仅仅是写一条日志记录,然后把文件命名成一个对外部不可见的名称,这个名称会包含删除的时间戳。GFS master会定期的扫描,当这些文件存在超过3天后,这些文件会从namespace中删掉,并且内存的中metadata会被删除。
在对chunk namespace的定期扫描时,会扫描到这些文件已经被删除的chunk,然后会把metadata从磁盘中删除。
在与chunkserver的heartbeat的交互过程中,GFS master会把不在metadata中的chunk告诉chunkserver,然后chunkserver就可以删除这些chunk了。
采用这种方式删除的好处:
- 利用心跳方式交互,在一次删除失败后,还可以通过下次心跳继续重试操作
- 删除操作和其他的全局扫描metadata的操作可以放到一起做
坏处:
- 有可能有的应用需要频繁的创建和删除文件,这种延期删除方式会导致磁盘使用率偏高,GFS提供的解决方案是,对一个文件调用删除操作两次,GFS会马上做物理删除操作,释放空间。
5.5 Stale Replication Detection
当一台chunkserver挂掉的时候,有新的写入操作到chunk副本,会导致chunkserve的数据不是最新的。
当master分配lease到一个chunk时,它会更新chunk version number,然后其他的副本都会更新该值。这个操作是在返回给客户端之前完成的,如果有一个chunkserver当前是宕机的,那么它的version number就不会增加。当chunkserver重启后,会汇报它的chunk以及version number,对于version number落后的chunk,master就认为这个chunk的数据是落后的。
GFS master会把落后的chunk当垃圾来清理掉,并且不会把落后的chunkserver的位置信息传给client。
备注:
- GFS master把落后的chunk当作垃圾清理,那么,是否是走re-replication的逻辑来生成新的副本呢?没有,是走立即复制的逻辑。
6. Fault Tolerance and Diagnose
6.1 High Availability
为了实现高可用性,GFS在通过两方面来解决,一是fast recovery,二是replication
6.1.1 Fast Recovery
master和chunkserver都被设计成都能在秒级别重启
6.1.2 Chunk Replications
每个chunk在多个机架上有副本,副本数量由用户来指定。当chunkserver不可用时,GFS master会自动的复制副本,保证副本数量和用户指定的一致。
6.1.3 Master Replication
master的operation log和checkpoint都会复制到多台机器上,要保证这些机器的写都成功了,才认为是成功。只有一台master在来做garbage collection等后台操作。当master挂掉后,它能在很多时间内重启;当master所在的机器挂掉后,监控会在其他具有operation log的机器上重启启动master。
新启动的master只提供读服务,因为可能在挂掉的一瞬间,有些日志记录到primary master上,而没有记录到secondary master上(这里GFS没有具体说同步的流程)。
6.2 Data Integrity
每个chunkserver都会通过checksum来验证数据是否损坏的。
每个chunk被分成多个64KB的block,每个block有32位的checksum,checksum在内存中和磁盘的log中都有记录。
对于读请求,chunkserver会检查读操作所涉及block的所有checksum值是否正确,如果有一个block的checksum不对,那么会报错给client和master。client这时会从其他副本读数据,而master会clone一个新副本,当新副本clone好后,master会删除掉这个checksum出错的副本。
6.3 Diagnose Tools
主要是通过log,包括重要事件的log(chunkserver上下线),RPC请求,RPC响应等。
7. Discussion
本部分主要讨论大规模分布式系统一书上,列出的关于gfs的一些问题,具体如下。
7.1 为什么存储三个副本?而不是两个或者四个?
- 如果存储的是两个副本,挂掉一个副本后,系统的可用性会比较低,例如,如果另一个没有挂掉的副本出现网络问题等,整个系统就不可用了
- 如果存储的是四个副本,成本比较高
7.2 chunk的大小为何选择64MB?这个选择主要基于哪些考虑?
优点
- 可以减少GFS client和GFS master的交互次数,chunk size比较大的时候,多次读可能是一块chunk的数据,这样,可以减少GFS client向GFS master请求chunk位置信息的请求次数。
- 对于同一个chunk,GFS client可以和GFS chunkserver之间保持持久连接,提升读的性能。
- chunk size越大,chunk的metadata的总大小就越小,使得chunk相关的metadata可以存储在GFS master的内存中。
缺点
- chunk size越大时,可能对部分文件来讲只有1个chunk,那么这个时候对该文件的读写就会落到一个GFS chunkserver上,成为热点。
64MB应该是google得出的一个比较好的权衡优缺点的经验值。
7.3 gfs主要支持追加,改写操作比较少,为什么这么设计?如何设计一个仅支持追加操作的文件系统来构建分布式表格系统bigtable?
- 因为追加多,改写少是google根据现有应用需求而确定的
- bigtable的问题等读到bigtable论文再讨论
7.4 为什么要将数据流和控制流分开?如果不分开,如何实现追加流程?
主要是为了更有效地利用网络带宽。把数据流分开,可以更好地优化数据流的网络带宽使用。
如果不分开,需要讨论下。
7.5 gfs有时会出现重复记录或者padding记录,为什么?
padding出现场景:
- last chunk的剩余空间不满足当前写入量大小,需要把last chunk做padding,然后告诉客户端写入下一个chunk
- append操作失败的时候,需要把之前写入失败的副本padding对齐到master
重复记录出现场景:
- append操作部分副本成功,部分失败,然后告诉客户端重试,客户端会在成功的副本上再次append,这样就会有重复记录出现
7.6 lease是什么?在gfs中起到了什么作用?它与心跳有何区别?
lease是gfs master把控制写入顺序的权限下放给chunkserver的机制,以减少gfs master在读写流程中的参与度,防止其成为系统瓶颈。心跳是gfs master检测chunkserver是否可用的标志。
7.7 gfs追加过程中如果出现备副本故障,如何处理?如果出现主副本故障,应该如何处理?
- 对于备副本故障,写入的时候会失败,然后primary会返回错误给client。按照一般的系统设计,client会重试一定次数,发现还是失败,这时候client会把情况告诉给gfs master,gfs master可以检测chunkserver的情况,然后把最新的chunkserver信息同步给client,client端再继续重试。
- 对于主副本故障,写入的时候会失败,client端应该是超时了。client端会继续重试一定次数,发现还是一直超时,那么把情况告诉给gfs master,gfs master发现primary挂掉,会重新grant lease到其他chunkserver,并把情况返回给client。
7.8 gfs master需要存储哪些信息?master的数据结构如何设计?
namespace、文件到chunk的映射以及chunk的位置信息
namespace采用的是B-Tree,对于名称采用前缀压缩的方法,节省空间;(文件名,chunk index)到chunk的映射,可以通过hashmap;chunk到chunk的位置信息,可以用multi_hashmap,因为是一对多的映射。
7.9 假设服务一千万个文件,每个文件1GB,master中存储元数据大概占多少内存?
1GB/64MB = 1024 / 64 = 16。总共需要16 10000000 64 B = 10GB
7.10 master如何实现高可用性?
- metadata中namespace,以及文件到chunk信息持久化,并存储到多台机器
- 对metadata的做checkpoint,保证重启后replay消耗时间比较短,checkpoint可以直接映射到内存使用,不用解析
- 在primary master发生故障的时候,并且无法重启时,会有外部监控将secondary master,并提供读服务。secondary master也会监控chunkserver的状态,然后把primary master的日志replay到内存中
7.11 负载的影响因素有哪些?如何计算一台机器的负载值?
主要是考虑CPU、内存、网络和I/O,但如何综合这些参数并计算还是得看具体的场景,每部分的权重随场景的不同而不同。
7.12 master新建chunk时如何选择chunkserver?如果新机器上线,负载值特别低,如何避免其他chunkserver同时往这台机器上迁移chunk?
如何选择chunkserver
- 磁盘空间使用率低于平均值的chunkserver
- 限制每台chunkserver最近创建chunk的次数,因为创建chunk往往意味着后续需要写入大量数据,所以,应该把写流量均摊到每台chunkserver
- chunk的副本放置于不同机架的chunkserver上
如何避免同时迁移
通过限制单个chunkserver的clone操作的个数,以及clone使用的带宽来限制,即从源chunkserver度数据的频率做控制。
7.13 如果chunkserver下线后过一会重新上线,gfs如何处理?
因为是过一会,所以假设chunk re-replication还没有执行,那么在这期间,可能这台chunkserver上有些chunk的数据已经处于落后状态了,client读数据的时候或者chunkserver定期扫描的时候会把这些状态告诉给master,master告诉上线后的chunkserver从其他机器复制该chunk,然后master会把这个chunk当作是垃圾清理掉。
对于没有落后的chunk副本,可以直接用于使用。
7.14 如何实现分布式文件系统的快照操作?
Snapshot的整个流程如下:
- client向GFS master发送Snapshot请求
- GFS master收到请求后,会回收所有这次Snapshot涉及到的chunk的lease
- 当所有回收的lease到期后,GFS master写入一条日志,记录这个信息。然后,GFS会在内存中复制一份snapshot涉及到的metadata
当snapshot操作完成后,client写snapshot中涉及到的chunk C的流程如下:
- client向GFS master请求primary chunkserver和其他chunkserver
- GFS master发现chunk C的引用计数超过1,即snapshot和本身。它会向所有有chunk C副本的chunkserver发送创建一个chunk C的拷贝请求,记作是chunk C',这样,把最新数据写入到chunk C'即可。本质上是copy on write。
7.15 chunkserver数据结构如何设计?
chunkserver主要是存储64KB block的checksum信息,需要由chunk+offset,能够快速定位到checksum,可以用hashmap。
7.16 磁盘可能出现位翻转错误,chunkserver如何应对?
利用checksum机制,分读和写两种情况来讨论:
- 对于读,要检查所读的所有block的checksum值
- 对于写,分为append和write。对于append,不检查checksum,延迟到读的时候检查,因为append的时候,对于最后一个不完整的block计算checksum时候采用的是增量的计算,即使前面存在错误,也能在后来的读发现。对于overwrite,因为不能采用增量计算,要覆盖checksum,所以,必须要先检查只写入部分数据的checksum是否不一致,否则,数据错误会被隐藏。
7.17 chunkserver重启后可能有一些过期的chunk,master如何能够发现?
chunkserver重启后,会汇报chunk及其version number,master根据version number来判断是否过期。如果过期了,那么会做以下操作:
- 过期的chunk不参与数据读写流程
- master会告诉chunkserver从其他的最新副本里拷贝一份数据
- master将过期的chunk假如garbage collection中
问题:如果chunkserver拷贝数据的过程过程中,之前拷贝的数据备份又发生了变化,然后分为两种情况讨论:
- 如果期间lease没变,那么chunkserver不知道自己拷贝的数据是老的,应该会存在不一致的问题?
- 如果期间lease改变,那么chunkserver因为还不能提供读服务,那么version number应该不会递增,继续保持stable状态,然后再发起拷贝。
1. Introduction
本文是读MapReduce论文的总结。
Google发现有一些应用的计算模型比较简单,但涉及到大量数据,需要成百上千的机器来处理。如何并行化计算、分布数据和处理故障需要复杂的处理呢?MapReduce的出现即为了解决这个问题。通过提供的编程库,用户能轻松地写出处理逻辑,而内部的并行化计算、数据分布等问题由MapReduce来处理,大大简化了用户的编程逻辑。
MapReduce受到lisp等函数式编程语言的启发,发现大部分的计算任务包括两个处理流程:
- map操作:对每条逻辑记录计算Key/Value对
- reduce操作:对Key/Value按照Key进行聚合
接下来,按照如下结构分析MapReduce系统
- Programming Model
- Implementation
- Refinements
2 Programming Model
MapReduce的计算以一组Key/Value对为输入,然后输出一组Key/Value对,用户通过编写Map和Reduce函数来控制处理逻辑。
Map函数把输入转换成一组中间的Key/Value对,MapReduce library会把所有Key的中间结果传递给Reduce函数处理。
Reduce函数接收Key和其对应的一组Value,它的作用就是聚合这些Value,产生最终的结果。Reduce的输入是以迭代器的方式输入,使得MapReduce可以处理数据量比内存大的情况。
2.1 Example
以经典的word count为例,其伪代码为
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Map函数吐出(word, count)的K/V对,Reduce把某个单词的所有的count加起来,最终每个单词吐出一个值。
除了Map和Reduce函数之外,用户还需要指定输入和输出文件名,以及一些可选的调节的参数。
2.2 Types
Map和Reduce函数的操作可以抽象的表示为
map (k1,v2) ======>list(k2,v2)
reduce (k2, list(v2)) ======>list(v2)
如上所示,map函数生成一系列的K/V中间结果,然后reduce对每个key,聚合其value。
2.3 More Examples
Distributed Grep
- 对于map,如果输入的行匹配到相应的pattern,则吐出这行
- 对于reduce,仅仅是把map吐出的行拷贝到输出中
Count of URL Access Frequency
- 对于map,处理web日志,生成(URL, 1)中间结果
- 对于reduce,聚合相同URL的值,生成(URL, total count)结果
Reverse Web-Link Graph
- 对于map,吐出(target, source)中间结果,其中target是被source引用的URL
- 对于reduce,聚合相同target的source,吐出(target, list(source))
Term-Vector per Host
Term Vector指的是一篇文档中的(word, frequency)K/V对。
- 对于map,吐出(hostname, term vector)中间结果
- 对于reduce,聚合相同hostname的term vector,吐出最终(hostname, term vector)
Inverted Index
- 对于map,吐出一系列的(word, document ID)
- 对于reduce,对相同word,按照document ID排序进行聚合,吐出(word, list(document ID))
Distributed Sort
- 对于map,吐出(key, record)中间结果
- 对于reduce,把map的中间结果写入到结果文件中,这里不需要显式地排序,因为MapReduce会自动地排序,方便在reduce的时候进行聚合。
3. Implementation
根据不同的环境,MapReduce的实现可以多种多样,例如,基于共享内存的,基于NUMA多核环境的,以及基于多台机器组成的集群环境的。
Google的环境如下
- 双核X86系统,运行linux系统,2-4GB内存。
- 100M或1000M带宽网卡
- 集群由大量机器组成,故障是常态
- 每台机器使用廉价的IDE磁盘,采用GFS作为底层存储
- 使用一个调度系统来处理用户的任务
3.1 Execution Overview
Map会自动地把输入数据划分成M份,这些数据划分可以并行地被不同机器处理。Reduce按照划分函数划分数据,例如hash(key) mod R,其中R是由用户指定的。下图描述了MapReduce的整个流程,如下
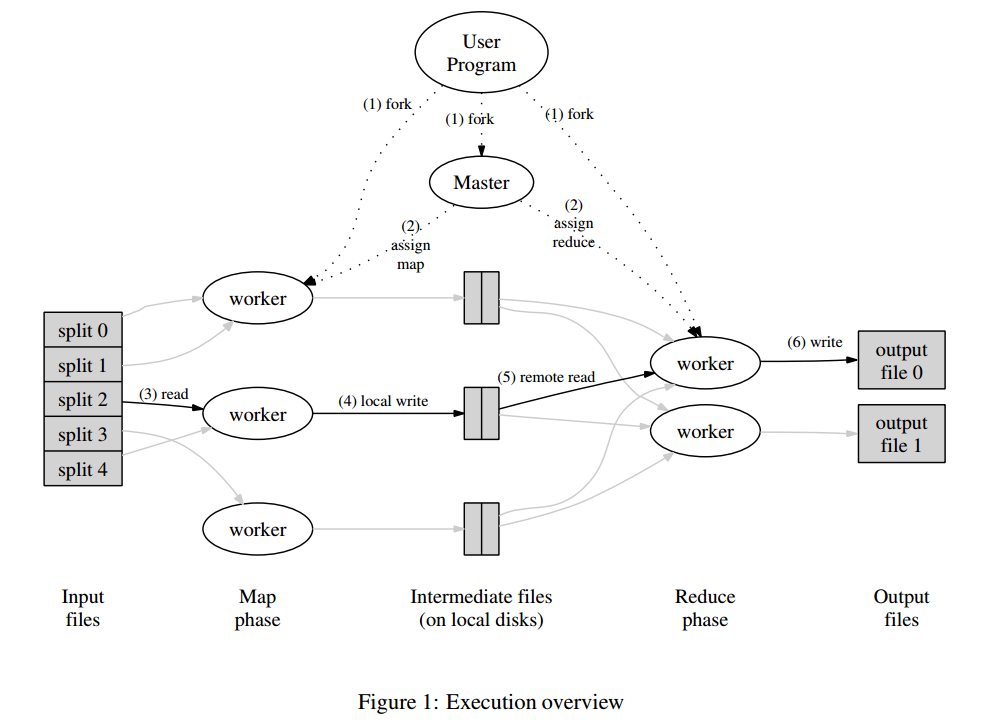
- MapReduce library会把输入文件划分成多个16到64MB大小的分片(大小可以通过参数调节),然后在一组机器上启动程序。
- 其中比较特殊的程序是master,剩下的由master分配任务的程序叫worker。总共有M个map任务和R个reduce任务需要分配,master会选取空闲的worker,然后分配一个map任务或者reduce任务。
- 处理map任务的worker会从输入分片读入数据,解析出输入数据的K/V对,然后传递给Map函数,生成的K/V中间结果会缓存在内存中。
- map任务的中间结果会被周期性地写入到磁盘中,以partition函数来分成R个部分。R个部分的磁盘地址会推送到master,然后由它转发给响应的reduce worker。
- 当reduce worker接收到master发送的地址信息时,它会通过RPC来向map worker读取对应的数据。当reduce worker读取到了所有的数据,它先按照key来排序,方便聚合操作。
- reduce worker遍历排序好的中间结果,对于相同的key,把其所有数据传入到Reduce函数进行处理,生成最终的结果会被追加到结果文件中。
- 当所有的map和reduce任务都完成时,master会唤醒用户程序,然后返回到用户程序空间执行用户代码。
成功执行后,输出结果在R个文件中,通常,用户不需要合并这R个文件,因为,可以把它们作为新的MapReduce处理逻辑的输入数据,或者其它分布式应用的输入数据。
3.2 Master Data Structure
master维护了以下信息
- 对每个map和reduce任务,记录了任务状态,包括idle,in-progress或completed,并且对于非idle状态的任务还记录了worker机器的信息
- 记录了map任务生成R个部分的文件位置信息
3.3 Fault Tolerance
分为两块,worker fault tolerance和master fault tolerance
Worker Failure
master采用ping的方式检测故障,如果一台worker机器在一定时间内没有响应,则认为这台机器故障。
- 对于map任务机器故障,完成了的map任务也需要完全重新执行,因为计算结果是存储在map任务所在机器的本地磁盘上的
当一个map任务开始由A来执行,而后挂掉后由B来执行,所有的为接收改任务数据的reduce任务的机器都会收到新的通知。
- 对于完成了的reduce任务则不需要重新执行,因为结果已经输出到GFS中
Master Failure
可以通过定期的checkpoint来保存状态,master挂掉后,可以回到最近checkpoint所在的状态。
但google没有采用这种方案,因为任务master挂掉概率极小,只需要让应用重试这次操作。
Semantics in the Presence of Failure
当用户提供的Map和Reduce函数的执行结果是确定的,那么最终的执行结果就是确定的。
当用户提供的执行结果不是确定的,那么最终结果也是不确定的,但是每个reduce任务产生的结果都是不确定的某次串行执行的结果。
3.4 Locality
由于输入数据是存储在GFS上的,所以,MapReduce为了减少网络通信,采取了以下优化策略
- 因为GFS是按照64MB的chunk来存储数据的,这样可以把worker按照这个信息调度,尽量是每个worker都起到相应的GFS副本上,这样输入基本上是走本地磁盘
- 如果上面的条件无法满足,那么尽量找一台和GFS副本机器在同一个交换机的机器
3.5 Task Granularity
MapReduce将map任务分成M份,reduce任务分成R份,理想状态M和R的值应该比worker机器大很多,这样有助于负载均衡以及故障恢复。因为当一台机器挂掉后,它的map任务可以分配给很多其他的机器执行。
实际应用中,因为master需要O(M+R)的空间来做调度决策,需要存储O(M*R)的任务产生的结果位置信息,对于每个任务产生的结果位置信息大约每个任务需要一个字节。
通常R的数量是由用户执行的,实际应用中对M的划分是要保证一个分片的数据量大小大约是16-64M,R的期望值是一个比较小的数。典型的M和R的值为 M = 200000,R = 5000,使用2000台worker机器。
3.6 Backup Tasks
通常,在执行过程中,会有少数几台机器的执行特别慢,可能是由于磁盘故障等原因引起的,这些机器会大大地增加任务的执行时间,MapReduce采用的方案是
- 当一个MapReduce操作快执行完成的时候,master会生成正在进行的任务的备份任务。备份任务和源任务做的是同样的事情,只要其中一个任务执行完成,就认为该任务执行完成。
该机制在占有很少的计算资源的情况下,大大缩短了任务的执行时间。
4. Refinements
本节描述了一些提升效率的策略。
4.1 Partitioning Function
map任务的中间结果按照partitioning function分成了R个部分,通常,默认的函数hash(key) mod R可以提供相对均衡的划分。但有时应用需要按照自己的需求的来划分,比如,当Key是URL时,用户可能希望相同host的URL划分到一起,方便处理。这时候,用户可以自己提供partitioning function,例如hash(Hostname(url))。
4.2 Ordering Guarantees
对于reduce任务生成的结果,MapReduce保证其是按照Key排序的,方便reduce worker聚合结果,并且还有两个好处
- 按照key随机读性能较好
- 用户程序需要排序时会比较方便
4.3 Combiner Function
在有些情况下,map任务生成的中间结果中key的重复度很高,会造成对应的reduce任务通信量比较大。例如,word count程序中,可能和the相关的单词量特别大,组成了很多的(the, 1)K/V对,这些都会推送到某个reduce任务,会造成该reduce任务通信量和计算量高于其他的reduce任务。解决的方法是
- 在map任务将数据发送到网络前,通过提供一个
combiner函数,先把数据做聚合,以减少数据在网络上的传输量
4.4 Input and Output Types
MapReduce提供多种读写格式的支持,例如,文件中的偏移和行内容组成K/V对。
用户也可以自定义读写格式的解析,实现对应的接口即可。
4.5 Side-effects
MapReduce允许用户程序生成辅助的输出文件,其原子性依赖于应用的实现。
4.6 Skipping Bad Records
有时候,可能用户程序有bug,导致任务在解析某些记录的时候会崩溃。普通的做法是修复用户程序的bug,但有时候,bug是来自第三方的库,无法修改源码。
MapReduce的做法是通过监控任务进程的segementation violation和bus error信号,一旦发生,把响应的记录发送到master,如果master发现某条记录失败次数大于1,它就会在下次执行的时候跳过该条记录。
4.7 Local Execution
因为Map和Reduce任务是在分布式环境下执行的,要调试它们是非常困难的。MapReduce提供在本机串行化执行MapReduce的接口,方便用户调试。
4.8 Status Information
master把内部的状态通过网页的方式展示出来,例如,计算的进度,包括,多少任务完成了,多少正在执行,输入的字节数,输出的中间结果,最终输出的字节数等;网页还包括每个任务的错误输出和标准输出,用户可以通过这些来判断计算需要的时间等;除此之外,还有worker失败的信息,方便排查问题。
4.9 Counters
MapReduce libaray提供一个counter接口来记录各种事件发生的次数。
例如,word count用户想知道总共处理了多少大写单词,可以按照如下方式统计
Counter* uppercase;
uppercase = GetCounter("uppercase");
map(String name, String contents):
for each word w in contents:
if (IsCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, "1");
master通过ping-pong消息来拉取worker的count信息,当MapReduce操作完成时,count值会返回给用户程序,需要注意的是,重复执行的任务的count只会统计一次。
有些counter是MapReduce libaray内部自动维护的,例如,输入的K/V对数量,输出的K/V对数量等。
Counter机制在有些情况很有用,比如用户希望输入和输出的K/V数量是完全相同的,就可以通过Counter机制来检查。
1. Introduction
本文为读bigtable的总结,分为以下部分:
- Data Model
- API
- Building Blocks
- Implementation
- Refinements
2. Data Model
bigtable本质上是一个K/V存储,其中映射关系为:
(row:string, column:string, time:int64)->string
如上所示,key为row:string, column:string, time:int64, value为string
以一个例子来说明该映射关系,如下图:
如上图所示,表名为WebTable,以URL为row key,网页各方面属性为column name,其中网页内容存储在contents:列中,通过时间戳可以区分列的数据版本。
2.1 Rows
Row key可以是任意的字符串,大小不超过64KB。每次针对单行的操作都是原子操作。
Bigtable按照row key的字典序对数据排序,每张表按照row key的排序范围动态划分。每个划分的row范围称作是tablet,是数据分布和负载均衡的单元。客户端可以根据这个特性,来把需要一起读的数据尽可能的安排在一起。例如,对于WebTable,如果需要同一个域名下的网页尽量放在一起的话,可以把域名maps.google.com/index.html按照row keycom.google.maps/index.html来存储。
2.2 Column Families
Column Key按照column family分组存储,访问控制信息也是按照column family为单元来设置的。一般来讲,期望的是所有存储在column family的列的数据类型是一样的,因为bigtable是按照column family进行压缩的。
在进行列存储前,column family必须要先创建,一旦创建好,任何在此family下的column key都可以使用。bigtable期望的是一张表的column family的schema几乎是不变的,且一张表的column family数量较小(最多几百个),但是,列的数量是无限制的。
Column key的表现形式为family:qualifier,对于family必须是可打印的字符串,对于qualifier可以是任意的字符串。以column faimilyanchor为例,每个column key都代表一个anchor,例如anchor:cnnsi.com。
2.3 Timestamp
Bigtable会对每个单元格的数据存储多个版本,版本按照时间戳排序。Bigtable timestamp是64位整数,可以由bigtable内部生成或者client端指定。
为了方便client指定需要存储多少个版本的数据,bigtable可以针对每个column family来设置,例如可以设定只存储最新的n个版本或者最近n天的数据。
对于WebTable,timestamp为爬取网页内容的时间戳,设定为只存储最新三个版本的数据。
3. API
Bigtable API提供了创建和删除表、column family的API,还提供了设置集群、表、column family元数据的API,例如改变访问控制权限。
写和删除的例子
遍历数据的例子
4. Building Blocks
Bigtable使用了其他的一些系统来构建服务:
- 使用了GFS来存储日志和数据文件
- 集群管理系统来负责分配管理资源,监控机器状态等
4.1 SSTable
Bigtable底层使用SSTable文件格式来存储数据。一个SSTable是存储多个K/V数据,数据按照KEY排序并且不能修改。对SSTable可以执行的操作包括,按照指定Key查找,按照Key Range遍历。
在SSTable内部,包含一些列的block(一般每个block是64KB,但也是可以配置的),在SSTable的尾部存储了block的索引,方便快速查找Key在哪个block内。当SSTable文件打开时,是会把block的索引加载到内存中去的。对于一次查找一般会有一次磁盘开销,先从内存中定位到在哪个block,然后把block从磁盘中读出来。
4.2 Chubby
Bigtable里面另一个依赖比较重的服务是Chubby。Chubby是一个分布式的锁服务,一般五副本冗余存储,其中一个会被选为主,只要五副本中的大多数是正常状态,chubby就可以保持可用。
Chubby提供一个包含目录或文件的命名空间,每个目录或者文件都可以当作是锁服务来使用,对单个文件的读或者写都是原子的。Chubby Client Library提供Chubby文件的缓存,每个Chubby Client和Chubby服务端通过一个session保持链接。一个Client的Session会在其无法在lease过期时间内续约而到期。当一个Client的session到期后,它会丢失所有的锁和handle。Chubby client可以在文件或者目录下注册回调事件,当文件或目录发生变化是会通知相应的client。
在Bigtable中,使用到Chubby的地方如下:
- 发现tablet server和tablet server挂掉
- 存储bigtable schema信息,主要是column family信息,以及存储访问控制信息
备注:如果chubby挂掉或者chubby和bigtable之间通信断掉,那么bigtable服务将不可用。
5. Implementation
Bigtable中有三大组件,包括client,单master和许多的tablet server。可以根据负载的情况,动态的加入或者删除机器。
master的工作
- 分配tablet到tablet server
- 检测tablet server的加入和过期
- 均衡tablet server的负载
- garbage collection GFS中的文件
- schema变更,包括表和column family的创建等
由于master不存储tablet location信息,因此,client基本上从来不会与master通信,master不会成为系统的瓶颈。
tablet server的工作
- 管理一组tablet
- 处理tablet的读写请求
- 分裂过大的tablet
每个Bigtable集群存储多张表,每张表包含多个tablet。初始的时候,一张表只有一个tablet,当表数据量增加时,会自动分裂成多个tablet。
5.1 Tablet Location
tablet location采用三层的存储层次,如下图:
- Chubby file存储Root tablet的location
- Root tablet存储othter MetaData tablet的location,root tablet不能分裂,需要保证三层结构
- 每个Metadata tablet存储一组user tablet的location
Metadata tablet的每行存储user tablet的row range的开始行和结束行等信息。
对于Client端,会缓存tablet location。如果客户端发现它的tablet location为空或者不正确,会从最上层开始查找和比较。对于为空的情况,需要三次网络开销来读取信息;对于不正确的情况,最坏需要六次网络开销,因为可能对于三层结构都出错了,每次都要试一次错,再读一次正确的数据。为了提升性能,client端一次会预取多个tablet的location并缓存。
tablet location信息应该都是存储在tablet server上的。
5.2 Tablet Assignment
master负责跟踪活着的tablet server和tablet到tablet server的分配,包括哪些tablet没有分配。当一个tablet没有被分配,并且一个tablet server可以容纳下该tablet,master给该tablet server发送请求告诉其load该tablet。
问题:这里的sufficient room指的是什么指标?
Chubby用来跟踪tablet server状态
- 当一个tablet server启动的时候,它会在Chubby指定目录创建一个文件,并获取一把锁
- master通过监控目录来发现新加入的tablet server
- tablet server在锁丢失时停止服务
- 当其所创建的文件还存在的情况下,tablet server会尝试重新获取锁
- 如果其创键的文件不存在,tablet server会停止进程
- 当tablet server终止时,会释放锁,然后master可以跟快速的来重新分配tablet
master的工作
master的工作包括两方面
- 检测停止服务的tablet server
- 尽快的重新分配tablet到tablet server
master周期性和tablet server通信来询问其锁的状态,如果是
- tablet server汇报其已经丢失了锁
- master多次重试无法和tablet server通信,接着master尝试和chubby通信,获取该server的文件所,根据结果分为两种情况:第一是master可以获得锁,那么说明tablet server挂掉或者其与Chubby无法通信,那么,master可以确信它无法提供服务了,因此立即删除Chubby上的文件,然后,把这台tablet server上的tablet都设置成未分配状态;第二是master无法获得锁,说明master和Chubby通信有问题,master会停止进程。
问题:master重新分配tablet的时机是? 问题:为什么master不直接和tablet server维持租约? 问题:为什么master不直接看chubby上的锁状态来确定tablet server的状态?有可能tablet server和chubby可以连接,但master和tablet server连不上。
master启动时,需要先检测当前的tablet分配情况,然后才能改变分配情况,启动步骤如下
- 从Chubby获取唯一的
master的锁,防止出现多个master - master扫描Chubby指定目录,发现活的tablet server
- master和活的tablet server通信,来获取它们已经分配了哪些tablet
- master扫描metadata table,去获取所有的tablet,当扫描发现有没有分配的tablet,把它加入到未分配的tablet中
其中有个问题是扫描metadata table之前,需要metadata的tablets都被分配了。因此,在扫描之前,需要先把root tablet加入到未分配的tablet中,这样root table在后面就会被分配了。因为root tablet中,有所有的metadata的tablets的信息,然后可以通过这些信息来确定哪些metadata的tablet未分配,然后把它们分配到相应的tablet server。
tablet发生改变的时机
- tablet创建或删除
- tablet分裂,或者tablet合并
tablet分裂
tablet分裂是由tablet server发起的,tablet最终会把分裂信息写入到metadata table中,然后通知master。为了防止通知丢失,当master让一个tablet server去load刚刚分裂的tablet时,master检测到新的tablet。tablet server会告诉master分裂的情况,因为,tablet会发现master要求load的tablet是几个tablet的和。
master让tablet server去load tablet的时机一般不是启动的时候?还有就是检测到没有分配的时候?
目前猜测master会有后台任务定期的扫描未分配的tablet。
5.3 Tablet Serving
tablet的存储最终持久化到GFS,其中包括SSTable数据和commit log。最近的commit log会在内存中存储,并持久化tablet log中,之前的commit log可能会dump到GFS中,以SSTable来存储。
tablet recovery
读取最近一次dump到SSTable中的commit log,然后再此之上,把之后的commit log的操作replay内存中。
write
写操作首先会检查语法是否出错以及是否有权限写,检查权限通过一个chubby file来获取(通常在client端有cache)。合法的操作就被持久化到commit log中,然后插入到memtable里面。为了优化性能,会采用group commit机制来组合提交多次写操作的log。
read
读操作首先会检查语法是否出错以及是否有权限读。最终读出的数据是一些列的SSTable和Memtable合并后的数据,因为它们都是按照key排序的,合并效率是比较高的。
读写操作可以在tablet合并或者分裂的时候进行。
5.4 Compactions
bigtable中compaction分为minor compaction,merging compaction和major compaction。
minor compaction
当memtable达到一定大小限制时,冻结的memtable会被转换成SSTable,存储到GFS中。
minor compaction的目标主要有
- 减少tablet server的内存使用
- 减少tablet recovery的时间
merging compaction
每次minor compaction都会生成一个新的SSTable。如果minor compaction较多,会生成一批SSTable,每次读操作都会需要合并这些SSTable的数据。为了提升读性能,bigtable限制这些文件的个数,会定时的执行merging compaction,来合并部分SSTable和memtable,然后生成一个新的SSTable。
major compaction
major compaction将所有的SSTable合并成一个SSTable。major和非major的区别在于,major compaction后的SSTable不包含任何的已经删除的数据,而非major compaction有可能会包含。
6. Refinements
本部分讨论一些提升系统性能、可用性和可靠性的方法和技术。
6.1 Locality groups
client可以指定多个column family到一个locality group,每个locality group会单独指定一个SSTable,这样读单个locality group的数据会更高效。例如,在WebTable中page meta放到一个locality group,而content可以放到另一个locality group。这样读page meta的时候,就不需要去读page content信息了。备注:可能的坏处时,如果需要读多个locality group的数据的时候,这样就会比较低效,需要应用控制好locality group的划分,适合业务特征。
另外,locality group中的SSTable可以配置放到内存中,采用延迟加载的方法,一旦放入内存后,下次读SSTable的时候就可以从内存中查找数据了。例如,metadata table的数据被配置成这种方式。
6.2 Compression
按照locality group来进行压缩,client可以配置具体的压缩算法。具体地压缩的时候,对每个SSTable的block来进行压缩的,这样的好处是,读SSTable的数据的时候,不需要解压整个文件。在google应用中,需要client采用两级压缩的方法,先采用Bentley and McIlroy方法压缩长公共字符串,接着采用一个快速压缩算法,按照16KB为块来进行压缩。在WebTable中把同一个host的内容放在一起,可以提升压缩比例,并且,row key的取名也比较重要。
6.3 Caching for read performance
采用两级cache,其中Scan Cache用来存储访问过的K/V对,对重复读某些数据的性能的应用比较友好;Block Cache缓存从GFS中读取的SSTable block,对读附近的数据的应用比较友好。
6.4 Bloom filters
在bigtable中,经常需要从多个SSTable中合并出数据,返回给client。如果SSTable不在内存中,将会有比较多的磁盘I/O。Bloom filter可以帮助过滤掉大部分那些SSTable中没有某行数据的,以减少访问SSTable的次数。
6.5 Commit-log implementation
commit log可以有两种实现方式,第一种是每个tablet一个log文件,第二种是一个tablet server一个log文件。
如果采用第一种方式实现,每个写操作都要去写对应的文件,需要大量的disk seek去写到不同的物理文件中。并且,对于group commit的优化会减弱,只有同一个tablet的才会形成一个group。
采用第二种方式实现会改善上面两种操作的效率,但是对于tablet recovery不友好。当一个tablet server宕机后,其上的tablet会被多个不同的其他tablet server加载上。这些tablet server只需要该tablet server的某些tablet的commit log,而不是需要所有的,解决方案是,先把commit log按照
写日志的时候,有可能会碰到GFS的写操作延迟比较大,例如碰到要写入的副本宕机等情况,bigtable采用的解决方案是,用两个线程来写日志,每个写入自己的文件。同一时刻,只有一个线程在工作,如果当前线程的写入性能比较差,那么切换到另一个进程。
问题:最终的commit log应该是两个线程写入的文件内容去重后合并的结果?
6.6 Speeding up tablet recovery
把一个tablet从某个tablet server A迁移到另一个tablet server B的流程
- A上对该tablet做一次minor compaction,以减少replay log的时间
- A对该tablet停止服务,需要再做一次minor compaction,因为从上次做minor compaction到停止服务期间可能有新的写入操作
- 在B上一次加载这两次minor compaction的内容到内存中
问题:中间停止服务的时间应该是从步骤二开始到步骤三结束,大约时间需要多少?
6.7 Exploiting immutability
对于SSTable,由于SSTable是不可修改的,因此,对于SSTable文件的访问可以并行,无需要进行同步。对于分裂操作,也可以让分裂后的tablet共享原来的SSTable。
对于memtable,采用的是copy on write机制,保证读和写可以并行。即先拷贝一份数据出来,修改后,再写入到memtable中。
对于已删除的数据,是放到SSTable文件的清理来做的,master采用mark-and-sweep机制来清理。
1. Introduction
本文是读google chubby的论文总结。
chubby是一个分布式的锁服务,其设计目标包括两点:
- 使用清晰易懂的语义,为大规模数量的客户端提供服务,并且保证可靠性和可用性
- 吞吐量和存储能力的优先级放在第二位
chubby的使用场景有很多,例如
- GFS用chubby来选举master
- Bigtable用chubby来选举master,发现tablet server等等
对于选择问题,是经典的分布式一致性问题,chubby采用Paxos算法来保证一致性。
2. Design
2.1 Rationale
本节讨论了google为什么以服务的方式来实现chubby,而不是采用Client Paxos Library方式来实现chubby的原因,包括
- 一个应用刚起步的时候负载往往比较小,所以对于可用性的需求比较少,当应用发展到一定规模时,就会在可用性上花费功夫,如果采用Client Paxos Library的方式,对于应用的改动量比较大;而如果采用服务的方式,则需要简单的几条语句就能实现。因此,采用服务方式,是符合应用增长的趋势的需求的。
- 许多客户端使用chubby来进行选主,因此,需要机制来广播结果。chubby通过小文件的读写很方便的实现了这个功能。这个功能也可以用命名服务来实现,但集成到chubby中可以减少客户端依赖的server数量,并且命名服务和锁服务用到的分布式一致性的协议是一样的,所以,没有必要重复造轮子。
- 开发者对于基于锁的接口更熟悉,更容易上手。
- 分布式一致性算法为了保证可用性,需要多副本才能保证高可用性,采用服务的方式,单个客户端也能保证锁服务的可用性。
基于上述的比较,chubby的两个关键设计目标为
- 提供锁服务,而不是client library
- 采用小文件来广播选主的结果,而不是维护另一个服务
基于使用环境的反馈,chubby还有如下设计目标
- 通过chubby文件广播选主结果的服务可能有成千上万个客户端,因此,需要允许这些客户端来监听此文件的变化,最好不需要投入太多的服务器来支撑。
- 在主发生变化的时候,客户端需要及时知道,因此,提供事件通知机制比客户端轮询要更有效。
- 有不少客户端有轮询文件的需求,因此,实现文件缓存是非常有必要的。
- 实现一致性缓存,方便开发者使用。
- 为了安全性,提供访问控制功能。
最重要的一点是,chubby期望开发者使用的是粗粒度的锁服务。
粗粒度的锁服务和细粒度的锁服务的区别如下
- 粗粒度锁一般是很少被获取,一旦有客户端获取锁,占用的时间会比较长,经常以小时或者天为单位;细粒度锁被占用的时间比较短,但是,会被客户端频繁获取。
- 粗粒度锁服务的获取频率和业务的执行频率无关;客户端对粗粒度锁服务的恢复开销比较大,因此,需要在服务端支持高可用性,即锁所在服务器挂掉不会造成客户端失去锁的控制权;临时的锁服务不可用不会造成太多客户端的故障。
- 细粒度锁服务的获取频率和业务的执行频率相关,客户端对细粒度锁服务的恢复开销不大,因此,锁在的服务器挂掉后,一般不恢复客户端获取的锁;临时的锁服务不可用会造成很多客户端故障。
2.2 System structure
chubby的两个关键组件是chubby library和chubby servers(chubby cell),另一个可选的组件是proxy server,将在3.1节讨论。
chubby cell由多台chubby server组成,也称作副本,采用分布式一致性协议选主。副本都会维护数据库的拷贝,但只有主提供读和写服务,其他副本只从主拉取最新的数据。
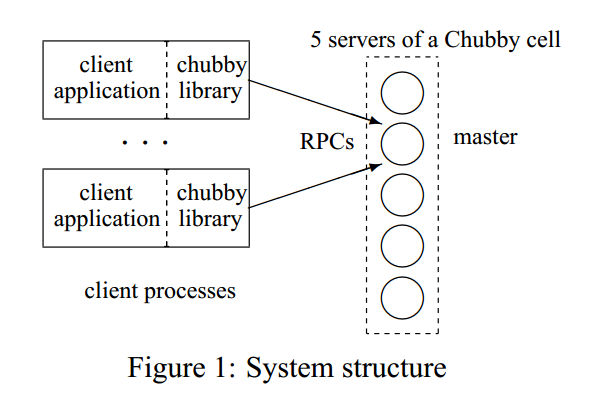
客户端发现主的流程
所有副本的IP信息放在DNS中,客户端通过和DNS列出的服务器通信来获取master地址。如果客户端请求的是一台非master服务器,它会返回master的地址;如果请求的master,则会告知客户端。客户端定位master后,会把所有请求都提交给master,直到它停止响应或者不再是主了。
读写请求
写请求通过一致性协议,需要写入多数派的副本才算写成功。
读请求只能通过master来响应,如果master挂掉,会在秒级别选出新主提供服务。
副本故障
如果某个副本挂掉,并且小时级别内没有恢复,那么采用以下故障恢复流程
- 从资源池中选择一台新机器,在上面安装chubby server,并启动服务。
- 更新DNS表,用新机器的IP地址替换老的。
- 当前的master会定期询问DNS,然后发现新替换的server,然后把新成员更新到数据库里面,这个更新会通过一致性协议同步到其他的副本上。
- 新替换的chubby server也会从master拉取最新的数据库拷贝,可能会基于最新的备份,然后恢复其之后的修改。
2.3 Files, directories, and handles
chubby提供一个类似于UNIX的文件系统接口,一个典型的名称为
ls/foo/wombat/pouch
ls前缀对于所有chubby名称都一样,代表lock service的意思foo是一个chubby cell的名称,DNS中会根据这个名称查找到一台或多台chubby server/wombat/pouch是在chubby cell里面的路径名
chubby的文件系统接口和UNIX不同的地方有
- 为了让不同目录的文件可以由不同的chubby master来提供服务,chubby不允许文件从一个目录移动到另一个目录
- 不维护目录的修改时间
- 文件权限由文件本身的设置有关,跟其目录的权限无关
- 为了更容易缓存文件元数据,系统不暴露最后访问时间给客户端
命名空间中只包含文件和目录,统称为节点(node),节点的特点如下
- 每个节点没有软连接或者硬连接
- 节点可以是永久的或者临时的。临时节点在客户端和chubby server连接断掉之后会自动删除,可以用来标识客户端是否可用
- 每个节点都可以加读/写锁
节点的元数据信息包括控制读的ACL文件名,控制写ACL文件名和改变ACL名称的文件名。除非特别指定,节点在创建的时候会继承父目录的名称。ACL本身也是文件,存储在chubby的ACL目录,文件中存储的是拥有此文件此权限的用户名。例如,一个文件F的写ACL文件名为foo,foo文件中包含一条记录bar,那么用户bar拥有文件F的写权限。
除了ACL相关信息,元数据还包括
- instance number:todo
- content generation number(文件特有),当文件被写入时,会增加
- lock generation number,当锁从空闲到被持有,会增加
- ACL generation number,当节点的ACL文件被写入时,会增加
chubby对客户端会暴露一个64位的文件checksum,方便比较文件是否发生改变。
chubby会为每个打开文件的客户端分配一个handle,其包含的信息有:
- 检查位,用于权限控制
- 序列号,用于标记此handle是否由之前的master生成的
- 打开模式,用于master切换时能够恢复
2.4 Locks and sequencers
每个chubby文件和目录都能获取读和写锁,对于没有获得锁的也能访问/读写目录和文件,这和mutex是一致的。
分布式锁可能会导致由于通信原因导致不一致性,例如
- 客户端1获取锁L,然后发一个请求R,接着挂掉
- 在R还没有达到chubby server之前,另一个客户端2获取锁L,然后做一些操作
- R在经过漫长的网络拥塞后,到了chubby server,这时候,如果响应R的操作请求,可能会导致数据的不一致
chubby采用lock sequencer方式来解决上述问题,具体地如下
- 客户端获取锁之后,马上向chubby server获取sequencer,里面包含锁名称,模式(读/写)以及lock generation number,当客户端的某些操作需要锁来保护时,它需要把sequencer信息也传递给chubby server,这样chubby server会判断sequencer是否还合法,如果不合法,chubby server会拒绝客户端的操作请求。
虽然采用lock sequencer的方式才有效解决问题,但是其在性能上比较差,chubby提供了一种不完美但是减轻由于通信导致的不一致性问题,具体如下
- 对于正常释放的锁,马上可以被其他客户端占用;对于非正常释放的锁,设置一个lock-delay时间,在这个时间段内,其他客户端不能获取锁,目前lock-delay时间设置为1分钟。
2.5 Events
客户端可以在创建handle的时候订阅一些列的事件,在chubby中,可订阅的事件包括
- 文件内容变化:通常用于广播某个服务的地址
- 子节点的新增、删除或修改:todo
- chubby master挂掉:告诉客户端其他事件可能丢失,需要重新扫描
- handle非法:通常说明通信出问题
- 获得锁:可以用来确定主是否被选出来了
- 来自其他客户端的锁冲突请求:允许锁的cache(不太明白)
根据google的经验,后两种事件很少使用到。
2.6 API
客户端通过open函数获得handle,通过close销毁handle。首先来看open操作的使用方式
- 通过节点名称来操作,并且可以提供一系列的选项,包括ACL信息,需要监听的事件,lock-delay等等
close操作会关闭一个handle,后续所有对该handle的操作都是不允许的。
剩下的其他操作都是基于handle来使用的,包括
GetContentsAndStat返回文件内容和元数据信息SetContents写入内容到文件Delete如果某个节点没有孩子节点的话,删除它Acquire,TryAcquire和Release获得和释放锁GetSequencer返回锁的sequencerSetSequencer:设置锁的sequencerCheckSequencer:检查锁的sequencer是否合法
2.7 Caching
为了减少网络流量,客户端会缓存文件内容和元数据信息在一致性的,写直达的内存cache中。cache通过lease机制来维护,通过master来发送invalidation来保持一致性,保证客户端可以看到一致性的chubby state或者报错。
文件和元数据
当文件内容或者元数据发生变化时,修改会阻塞直到master发送给所有缓存了这部分数据的客户端,告知它们废弃此cache。这个机制是放在心跳RPC中实现的,当客户端接收到作废cache的请求时,客户端会写入cache作废的状态,然后再下次心跳的时候返回给master确认消息。修改操作直到master知道所有的客户端都作废了其cache或者让cache过期。
问题:如果这个时候有客户端连不上了,应该怎么处理?
在为收到所有确认作废的消息之前,master会设定此节点是不可放到cache中的,这样不会阻塞读,所有的读请求都会直接到master请求数据。
cache的协议非常简单,当数据发生变化时,使它作废,但从来不更新。发生变化的时候不更新是因为更新效率低,不如需要的时候,再由客户端重新去master拿数据。
handle
chubby也会缓存handle,所以,一旦某个文件在客户端打开过,再次打开是可以直接走cache,而不用通过RPC的。
lock
chubby允许缓存lock,使得客户端占用锁的时间比实际使用时间长。如果有其他客户端需要使用这把锁,可以通过监听锁冲突事件,来及时的释放锁。
2.8 Session and Keep-Alives
session是客户端和chubby server之间的通信机制,通过KeepAlive消息来维持。客户端的handle、锁等在session是合法的情况下,才能保持合法状态。
客户端在首次和master通信的时候建立session,客户端只有在它退出或者session在一分钟内其上没有open的handle和请求时,才会主动地关闭session。
每个session都有lease,lease都有timeout。收到KeepAlive消息后,master通常会阻塞此消息的回复,直到客户端快过期的时候,再返回Keep-Alive消息,告知客户端新的timeout,然后,客户端又会立马发一个Keep-Alive消息,因此,服务端通常都有一个Keep-Alive阻塞。当服务端过载的时候,可能会调大timeout的值。
Keep-Alive还可以用来传递事件和cache invalidation消息,这个时候Keep-Alive是可以不阻塞,在更早的时间返回给客户端的。
客户端本地也维护了一个lease timeout时间,它的timeout与服务端的不同,考虑了Keep-Alive消息的传输时间以及服务端和客户端时钟的不一致。为了保持一致性,要求服务端的时钟不会比客户端的时钟块一个已知的常量级别。
当客户端的lease timeout时间到了,它不确定服务端是否关闭了此session。于是,它先把cache清空并禁用,此时session的状态称作为jeopardy。客户端会再等待45秒,称作是grace period,当客户端在45秒内,收到了master的Keep-Alive消息,那么,客户端会把cache启用,否则,客户端认为session过期了。
当session变成jeopardy状态,客户端会给应用推送jeopardy事件;如果后面session变成正常了,会推送给应用safe事件;当session过期了,会推送expired事件,方便应用来处理各种情况。
2.9 Fail-overs
当master挂掉之后,其内存中关于session,handle,lock的状态都会丢掉,因此,lease timeout计时器也会停止计时,这在maste挂掉情况下是合理的。如果重新选主时间比较短,那么可以在下次客户端session timeout之前完成,那么会一切正常;如果选主时间比较长,但是在grace period之内,客户端会废弃cache内容并禁用cache,等待重新和master连接,如果在grace period之内能连上master,那么可以启用cache。
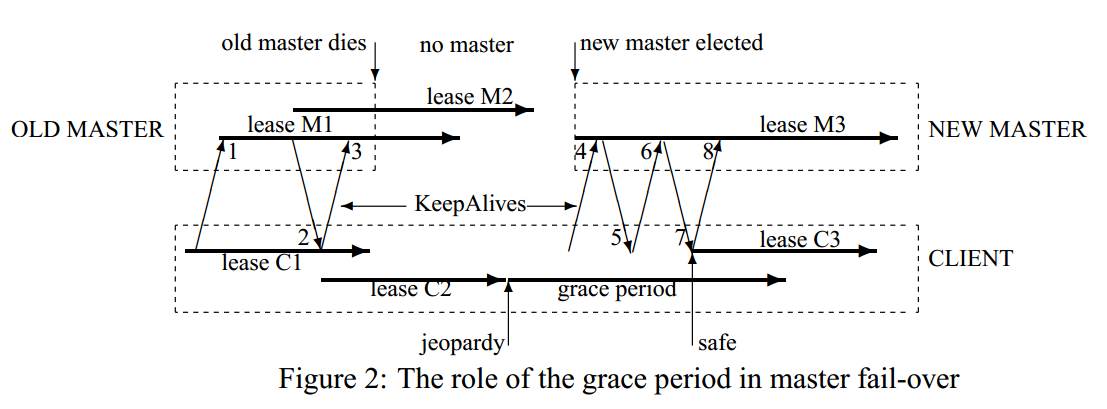
Master的fail-over过程如图2所示,具体流程为
- old master和客户端之间有session M1
- 客户端和old master通过Keep-Alive消息2,把心跳timeout扩展到lease C2
- 在lease C2期间,old master挂掉
- lease C2到期,客户端进入
grace period,等待master的lease - new master选举出来,收到客户端发的Keep-Alive消息4,new master会拒绝这个消息,因为它使用的是old master的epoch number
- 然后客户端重新给new master发Keep-Alive消息6,然后,把客户端的租约扩展到了lease C3
new master恢复和客户端的session状态的流程
为了让应用层对master fail-over无感知,客户端和master一起来协作来构建内存中session的状态。主要通过三部分来完成
- 通过持久化的database,其中包含了session,锁持有以及临时文件的信息
- 通过从客户端获取状态
- 通过保守的估计
具体的流程为
- 选择新的epoch number,当有客户端用old master的epoch number来连接的时候会拒绝
- master可能会响应获取master location的请求
- 从数据库中读取session和锁的信息,然后构建到内存中,seesion的lease将会被扩展到之前的master用到的最大值
- master允许客户端发送Keep-Alive消息,但是不允许其他session相关的操作
- 发送failover事件给客户端,让客户端清空cache,告知应用可能丢失了事件
- master等待每个session确认fail-over事件或者让session过期
- master允许所有的操作
- 如果客户端使用fail-over之前的handle,master会在内存中重新构建;如果重新创建的handle是关闭的,那么master会在内存中记录,表明它不能在这轮master epoch中重新创建。
- 过一段时间,例如,一分钟,master删除没有open handle的临时文件
2.10 Database Implementation
一开始采用Berkeley DB,支持日志的一致性同步,但由于维护比较复杂,后来自己开发简易版的。
2.11 Backup
每隔几个小时,chubby cell把数据库快照写入到GFS中。
2.12 Mirroring
Chubby允许文件集合从一个chubby cell镜像到另一个chubby cell。镜像操作往往很高效,原因有
- chubby file通常很小
- 事件通知机制可以很快让镜像代码在目的chubby cell做相同的操作
如果某个镜像断网了,当网络重新连接时,通过比较checksum来确定期间更新的文件。
通常使用镜像机制来把配置文件拷贝到多个集群。一个特别的chubby cell,global,包含/ls/global/master会把这个子树拷贝到其他chubby cell的ls/cell/slave。global chubby cell的五个副本放在全球五个不同的地方,所以,它的可用性是非常高的。
3. Mechanisms for scaling
todo
4. Use, surprises and design errors
todo